Spark Streaming 模块是对于 Spark Core 的一个扩展,目的是为了以高吞吐量,并且容错的方式处理持续性的数据流。目前 Spark Streaming 支持的外部数据源有 Flume、 Kafka、Twitter、ZeroMQ、TCP Socket 等。Kafka 是一个分布式的,高吞吐量,易于扩展地基于主题发布/订阅的消息系统。这里我们将Kafka作为流式计算的数据源实现流式计算。Spark Streaming获取Kafka数据的两种方式:Receiver的方式Direct的方式。
基于Receiver的方式,是通过Receiver从Kfaka获取数据。Receiver方是使用Kafka的高层次Consumer API来实现的。Receiver从Kafka中获取的数据都是存储在Spark Executor的内存中的,然后Spark启动job来处理这些数据。在默认的配置下,这种方式可能会因为底层的失败而丢失数据。如果要启用高可靠机制,让数据零丢失,就必须启用Spark Streaming的预写日志机制(Write Ahead Log,WAL)。该机制会同步地将接收到的Kafka数据写入分布式文件系统(比如HDFS)上的预写日志中,这样会造成一定的系统开销,但是也保证不了一条数据只处理一次。主要过程我们可以看看下面的图: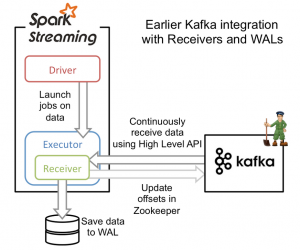
Direct的方式,没有使用Receiver,是使用Kakfa的简单API(Simple Consumer API)获取数据,Spark Streaming自己就负责追踪消费的offset,并保存在checkpoint中。这样就能保证这个过程是同步的,因此可以保证数据是消费一次且仅处理一次。Direct的方式简化了并行读取,不需要创建多个DStream再进行union操作,可以实现Kafka partition和RDD partition之间一一对应。Direct的方式不需要开启预写日志机制,减少了写入开销。主要过程我们可以看看下面的图:

从上图可以看出Direct的方式,不再更新zookeeper中的offset,这造成了kafka中监控到的offset和Spark Streaming消费的offset不一致,但是我们可以自己实现offset的更新回写。
我们使用Spark Streaming实现特殊事件数据的发现与转存。具体说就是向Kafka发布字符串消息,Spark Streaming从Kafka相应topic读取数据实时处理,发现消息中包含”bad_event“字符串的消息就认为是特殊事件消息,将特殊事件消息再写到Kafka的另一个topic供后续服务处理。下面的例子使用Direct的方式与kafka集成。
开发环境:
- spark 2.0
- jdk 1.8
- kafka 0.10
maven 依赖:
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.11</artifactId>
<scope>provided</scope>
</dependency>java 版代码:
package tech.hainiu.spark.stream;
import java.util.Arrays;
import java.util.HashMap;
import java.util.HashSet;
import java.util.Map;
import java.util.Properties;
import java.util.Set;
import java.util.concurrent.atomic.AtomicReference;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.apache.spark.SparkConf;
import org.apache.spark.broadcast.Broadcast;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import org.apache.spark.streaming.kafka010.HasOffsetRanges;
import org.apache.spark.streaming.kafka010.KafkaUtils;
import org.apache.spark.streaming.kafka010.LocationStrategies;
import org.apache.spark.streaming.kafka010.OffsetRange;
import org.apache.spark.streaming.kafka010.Subscribe;
/**
*
*/
public class MonitorEvent {
public static void main(String[] args) throws InterruptedException {
if (args.length < 2) {
System.err.println("Usage:<brokers> <topics>");
System.exit(-1);
}
String brokers = args[0];
String topics = args[1];
SparkConf sc = new SparkConf().setAppName("MonitorEvent");
JavaStreamingContext jsc = new JavaStreamingContext(sc, Durations.seconds(5));
Set<String> topicsSet = new HashSet<>(Arrays.asList(topics.split(",")));
Map<String, Object> kafkaParams = new HashMap<>();
kafkaParams.put("bootstrap.servers", brokers);
kafkaParams.put("key.deserializer", StringDeserializer.class);
kafkaParams.put("value.deserializer", StringDeserializer.class);
kafkaParams.put("auto.offset.reset", "latest");
kafkaParams.put("group.id", "MonitorEventGroup");
Properties producerConfigs = new Properties();
producerConfigs.put("bootstrap.servers", brokers);
producerConfigs.put("key.serializer", "org.apache.kafka.common.serialization.IntegerSerializer");
producerConfigs.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
final Broadcast<Properties> producerConfigsBroadcast = jsc.sparkContext().broadcast(producerConfigs);
final Broadcast<String> topicBroadcast = jsc.sparkContext().broadcast("event_out");
// 创建Direct方式的Stream
JavaInputDStream<ConsumerRecord<String, String>> messages = KafkaUtils.createDirectStream(jsc,
LocationStrategies.PreferConsistent(), new Subscribe<String, String>(topicsSet, kafkaParams, new HashMap<TopicPartition,Long>()));
final AtomicReference<OffsetRange[]> offsetRanges = new AtomicReference<>();
messages.transform(rdd -> {
OffsetRange[] offsets = ((HasOffsetRanges) rdd.rdd()).offsetRanges();
offsetRanges.set(offsets);
return rdd;
}).map(r -> r.value())
.filter(s -> s.indexOf("bad_event") >= 0 )// 是否包含特殊消息标记
.foreachRDD(rdd -> {
rdd.foreachPartition(f -> {
// 将挑选出的特殊消息存入kafka
KafkaProducer<Integer, String> producer = new KafkaProducer<Integer,String>(producerConfigsBroadcast.getValue());
f.forEachRemaining(t -> producer.send(new ProducerRecord<Integer,String>(topicBroadcast.getValue(),t.hashCode(),t)));
producer.close();
});
for (OffsetRange o : offsetRanges.get()) {
System.out.println(o.topic() + " " + o.partition() + " " + o.fromOffset() + " " + o.untilOffset());
}
});
// 启动计算
jsc.start();
jsc.awaitTermination();
}
}
使用maven 打包生成:stream-project-1.0.0.jar
操作执行:
启动执行控制台producer用于产生测试消息:
/usr/local/kafka/bin/kafka-console-producer.sh --broker-list 172.18.0.10:9092 --topic event_in启动执行控制台consumer观察产生的特殊消息:
/usr/local/kafka/bin/kafka-console-consumer.sh --zookeeper zookeeper.hadoop --topic event_out启动Spark应用:
/usr/local/spark/bin/spark-submit --class tech.hainiu.spark.stream.MonitorEvent --master local[6] --jars ./spark-streaming-kafka-0-10_2.11-2.0.0.jar,./kafka-clients-0.10.0.0.jar ./stream-project-1.0.0.jar 172.18.0.10:9092 event_in
16/09/24 09:02:12 INFO utils.AppInfoParser: Kafka version : 0.10.0.0
16/09/24 09:02:12 INFO utils.AppInfoParser: Kafka commitId : b8642491e78c5a13
16/09/24 09:02:12 INFO producer.KafkaProducer: Closing the Kafka producer with timeoutMillis = 9223372036854775807 ms.
16/09/24 09:02:12 INFO executor.Executor: Finished task 0.0 in stage 1.0 (TID 1). 756 bytes result sent to driver
16/09/24 09:02:12 INFO scheduler.TaskSetManager: Finished task 0.0 in stage 1.0 (TID 1) in 123 ms on localhost (1/1)
16/09/24 09:02:12 INFO scheduler.DAGScheduler: ResultStage 1 (foreachPartition at MonitorEvent.java:77) finished in 0.126 s
16/09/24 09:02:12 INFO scheduler.TaskSchedulerImpl: Removed TaskSet 1.0, whose tasks have all completed, from pool
16/09/24 09:02:12 INFO scheduler.DAGScheduler: Job 1 finished: foreachPartition at MonitorEvent.java:77, took 0.238274 s
....
16/09/24 09:02:15 INFO utils.AppInfoParser: Kafka version : 0.10.0.0
16/09/24 09:02:15 INFO utils.AppInfoParser: Kafka commitId : b8642491e78c5a13
16/09/24 09:02:15 INFO producer.KafkaProducer: Closing the Kafka producer with timeoutMillis = 9223372036854775807 ms.
16/09/24 09:02:15 INFO executor.Executor: Finished task 0.0 in stage 2.0 (TID 2). 843 bytes result sent to driver
16/09/24 09:02:15 INFO scheduler.DAGScheduler: ResultStage 2 (foreachPartition at MonitorEvent.java:77) finished in 0.074 s
16/09/24 09:02:15 INFO scheduler.DAGScheduler: Job 2 finished: foreachPartition at MonitorEvent.java:77, took 0.104896 s
event_in 0 18 18
16/09/24 09:02:15 INFO scheduler.JobScheduler: Finished job streaming job 1474707735000 ms.0 from job set of time 1474707735000 ms
16/09/24 09:02:15 INFO scheduler.JobScheduler: Total delay: 0.176 s for time 1474707735000 ms (execution: 0.111 s)
16/09/24 09:02:15 INFO rdd.MapPartitionsRDD: Removing RDD 5 from persistence list
16/09/24 09:02:15 INFO storage.BlockManager: Removing RDD 5
16/09/24 09:02:20 INFO utils.AppInfoParser: Kafka version : 0.10.0.0
16/09/24 09:02:20 INFO utils.AppInfoParser: Kafka commitId : b8642491e78c5a13
16/09/24 09:02:20 INFO producer.KafkaProducer: Closing the Kafka producer with timeoutMillis = 9223372036854775807 ms.
16/09/24 09:02:20 INFO executor.Executor: Finished task 0.0 in stage 3.0 (TID 3). 756 bytes result sent to driver
16/09/24 09:02:20 INFO scheduler.TaskSetManager: Finished task 0.0 in stage 3.0 (TID 3) in 98 ms on localhost (1/1)
16/09/24 09:02:20 INFO scheduler.DAGScheduler: ResultStage 3 (foreachPartition at MonitorEvent.java:77) finished in 0.091 s
16/09/24 09:02:20 INFO scheduler.DAGScheduler: Job 3 finished: foreachPartition at MonitorEvent.java:77, took 0.174838 s
event_in 0 18 18
16/09/24 09:02:20 INFO scheduler.TaskSchedulerImpl: Removed TaskSet 3.0, whose tasks have all completed, from pool
16/09/24 09:02:20 INFO scheduler.JobScheduler: Finished job streaming job 1474707740000 ms.0 from job set of time 1474707740000 ms
16/09/24 09:02:20 INFO scheduler.JobScheduler: Total delay: 0.248 s for time 1474707740000 ms (execution: 0.180 s)
16/09/24 09:02:20 INFO rdd.MapPartitionsRDD: Removing RDD 8 from persistence list
16/09/24 09:02:20 INFO rdd.MapPartitionsRDD: Removing RDD 7 from persistence list
我这里设置的Duration 是5秒,所以基本上 5秒一次执行。在producer端随意输入信息:
myevent
test_event
bad_event
is a event
send event
bad_event观察日志变化:
16/09/24 09:02:35 INFO utils.AppInfoParser: Kafka version : 0.10.0.0
16/09/24 09:02:35 INFO utils.AppInfoParser: Kafka commitId : b8642491e78c5a13
16/09/24 09:02:35 INFO kafka010.CachedKafkaConsumer: Initial fetch for spark-executor-MonitorEventGroup event_in 0 18
16/09/24 09:02:35 INFO internals.AbstractCoordinator: Discovered coordinator 172.18.0.10:9092 (id: 2147483646 rack: null) for group spark-executor-MonitorEventGroup.
16/09/24 09:02:35 INFO producer.KafkaProducer: Closing the Kafka producer with timeoutMillis = 9223372036854775807 ms.
16/09/24 09:02:35 INFO executor.Executor: Finished task 0.0 in stage 6.0 (TID 6). 756 bytes result sent to driver
16/09/24 09:02:35 INFO scheduler.TaskSetManager: Finished task 0.0 in stage 6.0 (TID 6) in 258 ms on localhost (1/1)
16/09/24 09:02:35 INFO scheduler.TaskSchedulerImpl: Removed TaskSet 6.0, whose tasks have all completed, from pool
16/09/24 09:02:35 INFO scheduler.DAGScheduler: ResultStage 6 (foreachPartition at MonitorEvent.java:77) finished in 0.257 s
16/09/24 09:02:35 INFO scheduler.DAGScheduler: Job 6 finished: foreachPartition at MonitorEvent.java:77, took 0.329645 s
event_in 0 18 20 <=======offset有变化
16/09/24 09:02:35 INFO scheduler.JobScheduler: Finished job streaming job 1474707755000 ms.0 from job set of time 1474707755000 ms
event_out consumer终端也有信息输出:
bad_event
bad_event这时退出spark stream这个应用再次启动,发现offset是恢复到上一次处理的offset。随着Direct方式 API的稳定,Direct的方式还是值得研究和使用的。



