项目背景
Cloudera 开发的分布式日志收集系统 Flume,是 hadoop 周边组件之一。其可以实时的将分布在不同节点、机器上的日志收集到 hdfs 中。Flume 初始的发行版本目前被统称为 Flume OG(original generation),属于 cloudera。但随着 FLume 功能的扩展,Flume OG 代码工程臃肿、核心组件设计不合理、核心配置不标准等缺点暴露出来,尤其是在 Flume OG 的最后一个发行版本 0.94.0 中,日志传输不稳定的现象尤为严重。为了解决这些问题,2011 年 10 月 22 号,cloudera 完成了 Flume-728,对 Flume 进行了里程碑式的改动:重构核心组件、核心配置以及代码架构,重构后的版本统称为 Flume NG(next generation);改动的另一原因是将 Flume 纳入 apache 旗下,cloudera Flume 改名为 Apache Flume。经过架构重构后,Flume NG更像是一个轻量的小工具,非常简单,容易适应各种方式日志收集,并支持failover和负载均衡。
- 官方网站:http://flume.apache.org/
- 用户文档:http://flume.apache.org/FlumeUserGuide.html
- 开发文档:http://flume.apache.org/FlumeDeveloperGuide.html
核心概念
- Event:一个数据单元,带有一个可选的消息头,可以对应你的一条数据记录或一行数据日志。
- Flow:Event从源点到达目的点的迁移的抽象,对应一条数据流程,定义你的数据从哪里到哪里
- Source:产生数据Event的源头,通过轮训或事件机制获悉Event,然后将Event传递给Channel,可以多个source对应一个或多个Channel
- Sink:从Channel中读取并移除Event,做相应的处理或转发,一个Sink对应一个Channel
- Channel:中转Event的一个临时存储,可以理解为 Source和Sink的解藕,多对多
- Agent:一个独立java进程一个内嵌 Flume 的应用进程,包含组件Source、Channel、Sink
简单概括讲,数据采集就像引流工程,将源头的水引到需要的地方。中间需要铺设管道,三通(多条分叉口),将水提供给最终用户。Flume 给你提供了"水管"/"三通"/"水龙头",你的水到底怎么流,有你的流程定义决定。
简单应用场景说明: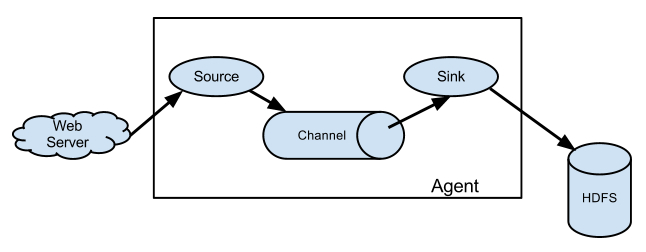
这是一个简单的应用场景,将web server产生的日志通过收集到 hdfs中。实现这需求方法很多,但使用Flume只需要定义个配置,启动一个agent即可实现。
定义一个流程文件 test.conf
#表示注释
# Define source, channel, sink
#wa 是agent的名字 tail_source时source名字,wa_channel 是channel名字
#wa_sink1 是sink名字
wa.sources = tail_source
wa.channels = wa_channel
wa.sinks = wa_sink1
# Configure channel
wa.channels.wa_channel.type = memory
wa.channels.wa_channel.capacity = 10000000
wa.channels.wa_channel.transactionCapacity = 10000
# Define and configure source
wa.sources.tail_source.channels = wa_channel
wa.sources.tail_source.type = exec
wa.sources.tail_source.command = tail -F /data/weblogs/access.log
wa.sources.tail_source.batchSize = 100
# Define and configure sink
wa.sinks.hdfs_sink.type = hdfs
fs.sinks.hdfs_sink.channel = fs_channel
wa.sinks.hdfs_sink.hdfs.path = hdfs://hadoop-master:9000/flume/%Y%m%d/%H
wa.sinks.hdfs_sink.hdfs.filePrefix = web-
wa.sinks.hdfs_sink.hdfs.fileSuffix = .log
wa.sinks.hdfs_sink.hdfs.inUsePrefix =_
wa.sinks.hdfs_sink.hdfs.inUseSuffix =.tmp
wa.sinks.hdfs_sink.hdfs.rollSize = 0
wa.sinks.hdfs_sink.hdfs.rollCount = 0
wa.sinks.hdfs_sink.hdfs.rollInterval = 300
wa.sinks.hdfs_sink.hdfs.writeFormat = Text
wa.sinks.hdfs_sink.hdfs.fileType = DataStream
wa.sinks.hdfs_sink.hdfs.batchSize = 6000
wa.sinks.hdfs_sink.hdfs.callTimeout = 60000
运行命令启动agent就可以了
bin/flume-ng agent -c ./conf -f ./test.conf -n wa &不用写一行代码实现web server日志收集,是不是简单?
之所以简单是因为Flume提供了大量现成 source,channel和sink组件。
当然真正的生产环境不会这么简单,要考虑的问题会很多,下面我们看看Flume已经提供的现成组件。
核心组件
Source
应用产生数据的方式和场景很多,Flume也提供了大量Source组件方便实现场景对接,当然没有满足你要求的source,你可以自己写代码定制化。
对现有系统改动最小的使用方式是数据文件方式对接,基本可以实现无缝接入,不需要对现有程序进行任何改动。对于直接读取文件 Source,有几种方式:
- ExecSource: 以运行 Linux 命令的方式,持续的输出最新的数据,如 tail -F 文件名 指令,在这种方式下,取的文件名必须是指定的。 ExecSource 可以实现对日志的实时收集,但是存在Flume不运行或者指令执行出错时,将无法收集到日志数据,无法保证日志数据的完整性。
- TailDirSource:java实现的 "tail exec source",监控一组文件,实现记录处理文件位置功能,实现重启不丢数据
- SpoolSource: 监测配置的目录下新增的文件,并将文件中的数据读取出来。需要注意两点:拷贝到 spool 目录下的文件不可以再打开编辑;spool 目录下不可包含相应的子目录。
| 类型 | 说明 | 应用场景 |
|---|---|---|
| Avro Source | 支持Avro协议(实际上是Avro RPC),内置支持 | agent提供RPC接口,可以通过RPC client发送数据 |
| Thrift Source | 支持Thrift协议,内置支持 | agent提供RPC接口,可以通过RPC client发送数据 |
| Exec Source | 基于Unix的command在标准输出上生产数据 | 通过管道形式收集终端数据 |
| TailDirSource | java实现的 "tail exec source" | 可以记录出来位置,重启不丢数据 |
| JMS Source | 从JMS系统(消息、主题)中读取数据 | |
| Spooling Directory Source | 监控指定目录内数据变更 | 可以使用以分钟的方式分割文件,趋近于实时 |
| Twitter 1% firehose Source | 通过API持续下载Twitter数据,试验性质 | |
| Netcat Source | 监控某个端口,将流经端口的每一个文本行数据作为Event输入 | |
| Sequence Generator Source | 序列生成器数据源,生产序列数据 | 每个event是一个id |
| Syslog Sources | 读取syslog数据,产生Event,支持UDP和TCP两种协议 | |
| HTTP Source | 基于HTTP POST或GET方式的数据源,支持JSON、BLOB表示形式 | 客户端通过http接口向source发送数据 |
| Legacy Sources | 兼容老的Flume OG中Source(0.9.x版本) |
Channel
Flume Channel 支持的类型:
| 类型 | 说明 |
|---|---|
| Memory Channel | Event数据存储在内存中 |
| JDBC Channel | Event数据存储在持久化存储中,当前Flume Channel内置支持Derby |
| File Channel | Event数据存储在磁盘文件中 |
| Spillable Memory Channel | Event数据存储在内存中和磁盘上,当内存队列满了,会持久化到磁盘文件(当前试验性的,不建议生产环境使用) |
| Pseudo Transaction Channel | 测试用途 |
| Custom Channel | 自定义Channel实现 |
MemoryChannel 可以实现高速的吞吐,但是无法保证数据的完整性。异常退出或宕机会丢数据
FileChannel保证数据的完整性与一致性。在具体配置FileChannel时,建议FileChannel设置的目录和程序日志文件保存的目录设成不同的磁盘,以便提高效率。
File Channel 是一个持久化的隧道(channel),它持久化所有的事件,并将其存储到磁盘中。因此,即使 Java 虚拟机当掉,或者操作系统崩溃或重启,再或者事件没有在管道中成功地传递到下一个代理(agent),这一切都不会造成数据丢失。Memory Channel 是一个不稳定的隧道,其原因是由于它在内存中存储所有事件。如果 java 进程死掉,任何存储在内存的事件将会丢失。另外,内存的空间收到 RAM大小的限制,而 File Channel 这方面是它的优势,只要磁盘空间足够,它就可以将所有事件数据存储到磁盘上。如果想综合两者可以尝试 Spillable Memory Channel,但有丢数据可能,多少由设置的memory capacity 大小决定。
Sink
Sink在设置存储数据时,可以向文件系统、数据库、hadoop存数据,在日志数据较少时,可以将数据存储在文件系中,并且设定一定的时间间隔保存数据。在日志数据较多时,可以将相应的日志数据存储到Hadoop中,便于日后进行相应的数据分析。
Flume Sink支持的类型
| 类型 | 说明 |
|---|---|
| HDFS Sink | 数据写入HDFS |
| Logger Sink | 数据写入日志文件 |
| Avro Sink | 数据被转换成Avro Event,然后发送到配置的RPC端口上 |
| Thrift Sink | 数据被转换成Thrift Event,然后发送到配置的RPC端口上 |
| IRC Sink | 数据在IRC上进行回放 |
| File Roll Sink | 存储数据到本地文件系统 |
| Null Sink | 丢弃到所有数据 |
| HBase Sink | 数据写入HBase数据库 |
| Morphline Solr Sink | 数据发送到Solr搜索服务器(集群) |
| ElasticSearch Sink | 数据发送到Elastic Search搜索服务器(集群) |
| Kite Dataset Sink | 写数据到Kite Dataset,试验性质的 |
| Custom Sink | 自定义Sink实现 |
详细配置参数可以参考官方文档,在这不一一列举
拦截器
| Flume中的拦截器(interceptor),Source读取events发送到Channel的时候,在events header中加入一些有用的信息,或者对events的内容进行过滤,完成初步的数据清洗. | 类型 | 说明 |
|---|---|---|
| Timestamp Interceptor | 增加时间戳header,后续组件可能会用,比如hdfsSink,默认header名字:timestamp | |
| Host Interceptor | 增加数据源的ip或者主机,默认header名字:host | |
| Static Interceptor | 加入固定header,自定义key,value | |
| UUID Interceptor | 生成uuid加入header | |
| Morphline Interceptor | 使用Morphline对event数据做转换, | |
| Search and Replace Interceptor | 将events中的正则匹配到的内容做相应的替换 | |
| Regex Filtering Interceptor | 使用正则表达式过滤原始events中的内容 | |
| Regex Extractor Interceptor | 使用正则表达式抽取原始events中的内容,并将该内容加入events header中 |
agent_t1.sources.s1.interceptors = i1 i2 i3 i4
agent_t1.sources.s1.interceptors.i1.type = host #增加hostheader
agent_t1.sources.s1.interceptors.i2.type = timestamp #增加时间戳
#增加固定header
agent_t1.sources.s1.interceptors.i3.type = static
agent_t1.sources.s1.interceptors.i3.preserveExisting = true
agent_t1.sources.s1.interceptors.i3.key = my_key
agent_t1.sources.s1.interceptors.i3.value = my_value
#数据替换,将b替换成 a
agent_t1.sources.s1.interceptors.i4.type = search_replace
agent_t1.sources.s1.interceptors.i4.searchPattern = [b]+
agent_t1.sources.s1.interceptors.i4.replaceString = a
流程文件格式
#定义agent的 source,channel,sink列表
#<XXXX> 表示自定义的agent/source/sink名字
#多个用空格分开
<Agent>.sources = <Source>
<Agent>.sinks = <Sink>
<Agent>.channels = <Channel1> <Channel2>
# set channel for source
<Agent>.sources.<Source>.channels = <Channel1> <Channel2> ...
# set channel for sink
<Agent>.sinks.<Sink>.channel = <Channel1>
#someProperty 为特定组件定义的属性
# properties for sources
<Agent>.sources.<Source>.<someProperty> = <someValue>
# properties for channels
<Agent>.channel.<Channel>.<someProperty> = <someValue>
# properties for sinks
<Agent>.sources.<Sink>.<someProperty> = <someValue>
典型应用场景
下面,根据官网文档,我们展示几种Flow Pipeline,各自适应于什么样的应用场景:
多个 agent 顺序连接:
可以将多个Agent顺序连接起来,将最初的数据源经过收集,存储到最终的存储系统中。这是最简单的情况,一般情况下,应该控制这种顺序连接的Agent的数量,因为数据流经的路径变长了,如果不考虑failover的话,出现故障将影响整个Flow上的Agent收集服务。
多个Agent的数据汇聚到同一个Agent:
这种情况应用的场景比较多,比如要收集Web网站的用户行为日志,Web网站为了可用性使用的负载均衡的集群模式,每个节点都产生用户行为日志,可以为每个节点都配置一个Agent来单独收集日志数据,然后多个Agent将数据最终汇聚到一个用来存储数据存储系统,如HDFS上。
多路(Multiplexing)Agent
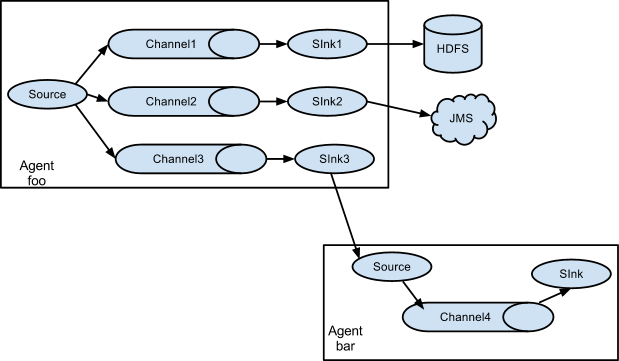
这种模式,有两种方式,一种是用来复制(Replication),另一种是用来分流(Multiplexing)。Replication方式,可以将最前端的数据源复制多份,分别传递到多个channel中,每个channel接收到的数据都是相同的。
Multiplexing 可以支持 按照header分配流量,官方文档的例子
实现按照header state的不同取值分配流量,default为默认
# list the sources, sinks and channels in the agent
agent_foo.sources = avro-AppSrv-source1
agent_foo.sinks = hdfs-Cluster1-sink1 avro-forward-sink2
agent_foo.channels = mem-channel-1 file-channel-2
# set channels for source
agent_foo.sources.avro-AppSrv-source1.channels = mem-channel-1 file-channel-2
# set channel for sinks
agent_foo.sinks.hdfs-Cluster1-sink1.channel = mem-channel-1
agent_foo.sinks.avro-forward-sink2.channel = file-channel-2
# channel selector configuration
agent_foo.sources.avro-AppSrv-source1.selector.type = multiplexing
agent_foo.sources.avro-AppSrv-source1.selector.header = State
agent_foo.sources.avro-AppSrv-source1.selector.mapping.CA = mem-channel-1
agent_foo.sources.avro-AppSrv-source1.selector.mapping.AZ = file-channel-2
agent_foo.sources.avro-AppSrv-source1.selector.mapping.NY = mem-channel-1 file-channel-2
agent_foo.sources.avro-AppSrv-source1.selector.default = mem-channel-1
实现load balance功能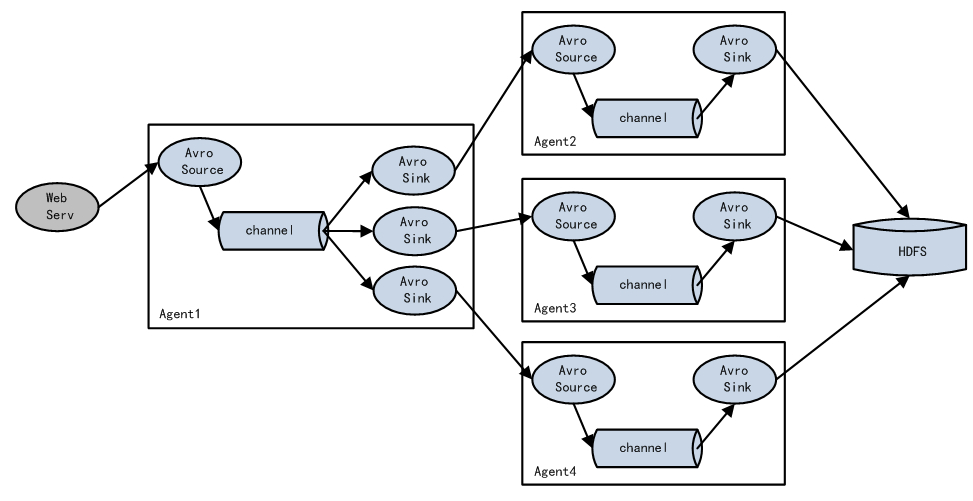
Load balancing Sink Processor能够实现load balance功能,就是将sink分组,按照特定算法选择sink分配流量,目前支持 random 和 round_robin。
a1.sinkgroups = g1
a1.sinkgroups.g1.sinks = k1 k2 k3
a1.sinkgroups.g1.processor.type = load_balance
a1.sinkgroups.g1.processor.backoff = true
a1.sinkgroups.g1.processor.selector = random上面配置现实图例流程,理论上k1,k2,k3各占三分之一流量,相应流量对应 agent2,agent3,agent4
实现failover能
Failover Sink Processor能够实现failover功能,具体流程类似load balance,但是内部处理机制与load balance完全不同:Failover Sink Processor维护一个优先级Sink组件列表,只要有一个Sink组件可用,Event就被传递到下一个组件。简单说就是将sink分组,每组只有一个可用,如果可用的sink变成不可以,由其它同组sink接替,整体sink选择按照配置的优先级决定。
a1.sinkgroups = g1
a1.sinkgroups.g1.sinks = k1 k2
a1.sinkgroups.g1.processor.type = failover
a1.sinkgroups.g1.processor.priority.k1 = 5
a1.sinkgroups.g1.processor.priority.k2 = 10
a1.sinkgroups.g1.processor.maxpenalty = 10000优先使用k2,k2异常后启用k1
load_balance 和 failover 配置的注意事项
- load_balance sink 和failover sink不能共享,一个sink只能有一个角色
Flume根据sinkgroups顺序的解析配置文件,然后把sink放到变量名为Map当中,每个sink只能使用一次,如果sink在前面某个sinkgroups已经使用,那么就会在该sinkgroups中删除这个sink。failover可以做失败转移,如果因为加载顺序的问题,导致failover的Sink已经被占用,failover会造成配置在failover中的sink都能接收数据的假象,其实只是在剩余的sink中实施failover策略(后面源码分析 loadSinkGroups) - 优先级相同的sink节点在failover中只会有一个生效,看源码可以很容易的发现,因为Failover中live的Sink存放在TreeMap中,用优先级作为key,同等优先级的Sink只能保存一个。
- load_balance配置中的Sink都可以接收数据。
- load_balance根据均衡策略接收数据。
总结
Flmue 提供了常用的组件,通过组件组合,利用loader_balance,failover 等机制实现 可扩展的,稳定的,可恢复的数据收集和传输通道。



