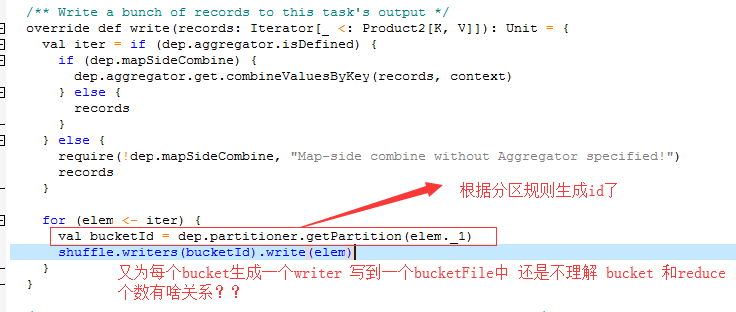
网上说shuffleMapTask 创建会根据Reducer的数量创建出相应的bucket (每个shuffleMapTask都会为每个reducetask 创建一个bucket文件) 也就是说 最终的小文件数量是 MR
我想问一下一定是有MR个文件吗???(不考虑consolidation机制,不考虑其他因素 )
我自己理解的如下:
首先bucketId 是由hashPartitioner 通过对map的key与Partition数量取余算的(0-numPartition-1)
也就是说有多少个bucket是由数据决定的 换言之一个map可以产出0 - (numPartition-1)不等的bucket数量 那网上说
shuffleMapTask 创建会根据Reducer的数量创建出相应的bucket 有多少个Reducer 就创建多少个bucket 这种说法应该怎么理解???
PS:表述的可能不是很清楚望请见谅