从一个小型的搜索引擎项目来看,Hadoop已经成为今天的主力军。它现在是术语“大数据”的代名词。Hadoop生态系统有许多组件,他们可以增强它并使其具有冲击力。
时下流行的词汇是大数据和Hadoop。我们知道Hadoop有三个组件,即HDFS、MapReduce和Yarn。HDFS代表Hadoop分布式文件系统,Hadoop分布式文件系统用于整个集群中以块的形式在计算机之间存储数据。
MapReduce是一种编程模型,可以用来编写我们的业务逻辑并获取所需的数据。而Yarn是HDFS和Spark、Hbase等其他应用程序之间的接口。我们不知道的是,Hadoop使用了很多其他应用程序有助于其最佳性能和利用率。在本文中,我将概述Hadoop的五大支柱,使其足够强大,可以在大数据上运行。
Pig
这是一个分析大型数据集的平台,其中包括表达数据分析程序的高级语言,以及评估这些程序的基础设施。Pig是一种高级语言,主要处理日志文件等半结构化数据。它支持被称为Pig Latin的语言。
查询规划器将用Pig Latin编写的查询映射,然后将其缩小,然后在Hadoop集群上执行。使用Pig,你可以创建自己的功能来做特殊处理。在简单的MapReduce中,编写表之间的连接是非常困难的。
在Pig中这很容易,因为它最适合连接数据集,排序数据集,过滤数据,按方法分组,更具体地说,可以编写用户定义的函数(UDF)。MapReduce编程模型可以被认为是由三个不同的阶段组成,即处理输入记录,形成相关的记录和处理组到输出。
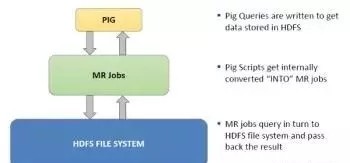
在MapReduce中,前两个步骤由映射器处理,第三步由reducer处理。Pig Latin暴露了从每个阶段执行操作的显式原语。这些原语可以被组合和重新排序。Pig有两种工作模式:本地模式A和Hadoop模式。本地模式使用单个JVM并在本地文件系统上工作,而Hadoop模式或MapReduce模式将Pig Latin呈现为MapReduce作业,并在群集上执行它们。
Hive
Hive是Hadoop的数据仓库。那些不具备Java背景并且知道SQL查询的人,发现在Java中编写MapReduce作业是很困难的。为了解决这个问题,开发了Hive。查询被编写成在后端被编译成MapReduce作业。这加快了这个过程,因为写入查询比写入代码要快。
而且,Hive支持创建表,创建视图,创建索引和DML(如seleect,where子句,group by,order by和join)的DDL。需要记住的一点是,Hive不是RDBMS,它应该用于批处理而不是OLTP。
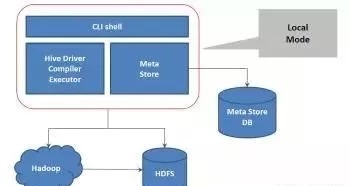
Hive有默认的metastore,它包含表文件的位置,表格定义,存储格式,行格式等。Hive查询被称为HQL(Hive Query Language)。Derby是Hive的默认数据库。
Sqoop
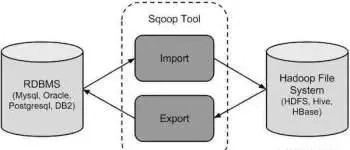
如果您在其他一些RDBMS数据库(如Oracle或MySQL)中有数据,并且现在要转移到使用Hadoop,则必须将数据移动到HDFS;这时Sqoop就派上用场了。Sqoop是一种开放源码工具,用于传统的RDBMS和Hadoop环境之间的数据交互。
使用Sqoop,数据可以从MySQL、PostgreSQL、Oracle、SQL Server或DB2移入HDFS,Hive和HBase,反之亦然。它在业界广泛使用,因为它是您决定从关系数据库迁移到Hadoop生态时使用的第一个Apache产品。
Sqoop有三个步骤。在第一步中,它将请求发送到关系数据库,以返回关于表的元数据信息(元数据是关于关系数据库中的表的数据)。第二步中,Sqoop根据接收到的信息生成Java类,必须在系统中安装Java。 在最后一步,一个jar是由编译的文件构成的。 Sqoop需要有一个主键最好的工作,但不要担心,如果你的表结构本质上没有它, 它会为你创建,但不会影响你的表的元数据结构。
Hbase
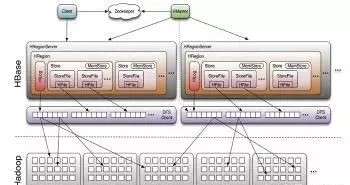
HBase是一个基于HDFS的分布式专栏数据库。 当您需要实时读/写随机访问一个非常大的数据集时,Hadoop应用程序才能使用。 HBase提供了几乎可以使用任何编程语言进行开发的API,非常适合稀疏数据集。
它是用Java编写的,并不强制数据内的关系。 HBase的关键在于它不关心数据类型,在同一列中存储一行中的整数和另一行中的字符串。 它存储一个键值对并存储版本化的数据。 HBase shell是用JRuby(JRE的Ruby实现)封装Java客户端API(即,可以访问Java库)编写的。
HBase以三种不同的模式运行:独立运行(在一台机器上的单个JVM上运行),伪分布式(在一台机器上运行多个JVM)和全分布式(在多台机器上运行多个JVM)。
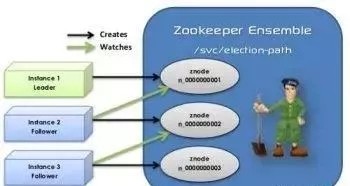
Zookeeper
这是分布式应用程序的分布式协调服务。 Zookeeper解决了集中配置,同步,局部故障,死锁,竞态条件和网络等问题。 它实际上处理Hadoop生态系统中分布式应用程序开发的基本问题,以便开发人员可以专注于功能。 Zookeeper在集群中总是有奇数个节点,因为主节点的选择是通过投票。
Zookeeper拥有领导者,追随者和观察者。 在领导者中,写操作是基于群体,是由追随者承诺。 追随者把这些写的文章转发给领导者。 只有一个领导者可以编写写和提交文件,所有的请求通过追随者来到领导。 如果领导者下台,在追随者之间进行投票选择领导者。 观察者只是观察选票的结果,而不参与投票过程。


