看了很多文章,但是大多数都只是告诉你这四个参数是什么作用。
唯有16年的Spark Summit大会上Top 5 Mistakes When Writing Apache Spark Applications演讲专题提到了一种计算方法(固定executor-cores为5,每太理解为什么他说超过5 hdfs 的thoughout会降低)并手把手的教了怎么计算。但是我实际测试过程中效果并不好。(见下图,程序很简单就是读取数据存入hdfs as parquet file,没有多余操作。当时所有节点也基本空闲,没有其他业务运作)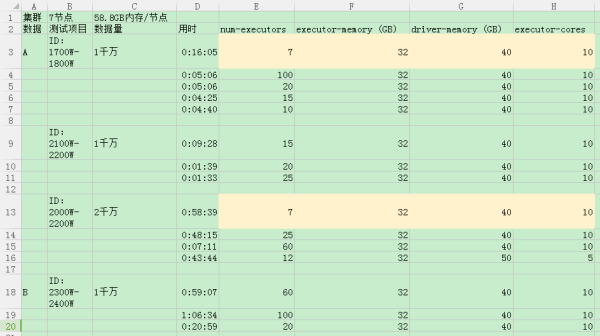
Spark submit 调参是不是玄学?(我后来一次出现过一千万量级数据我使用了第20排那个配比,并没有达到20分钟的效果,用了一小时)
如果不是玄学,它们的配比确实能明显影响到运作效率,是否有什么教程能够明确展示几个参数见得关系和影响?(类似上述演讲中的计算方式)



