我们查询的数据有点多 ,在查询的时候遇到的一些问题 想请教下 :
- 首先 如果我们在spark 中 使用scan 查询 hbase 表 没有设置 startRow 和stopRow ,程序看是扫描了很多结果,但是 有的数据该有查询结果的,但是 从查询出来的数据来看 丢失了
- 然后我们在程序中设置了scan的startRow 和stopRow 但是看日志查询的结果 不是 想要的结果 。查询看图
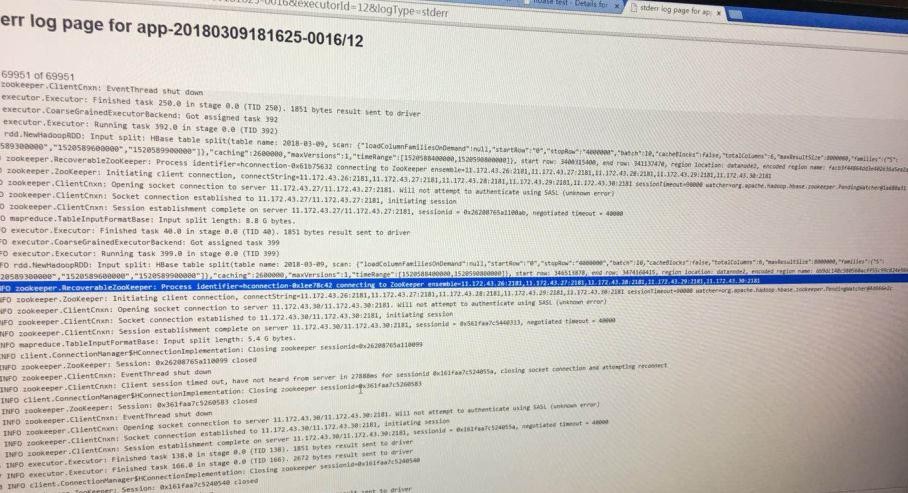
我们查询的数据有点多 ,在查询的时候遇到的一些问题 想请教下 :

你startRow和stopRow是怎么设置的?数据怎么能丢,除非设置了过期时间


关注海牛部落大数据技术社区
