各位大佬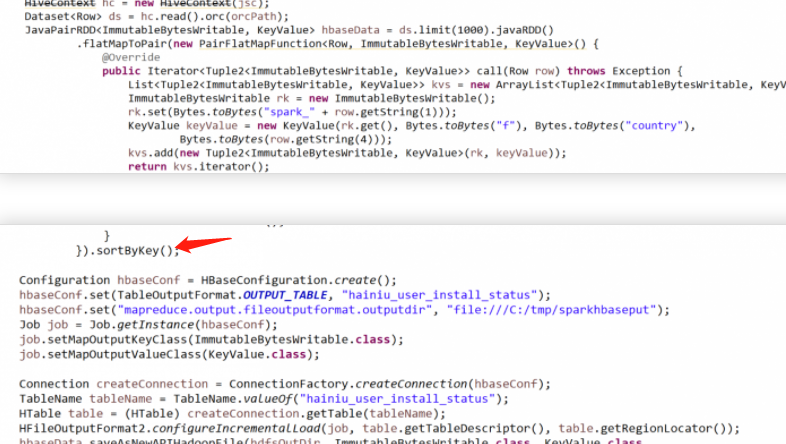
我报出错误如下
java.io.IOException: Added a key not lexically larger than previous. Current cell = 11000031219513/info:csd/1530512610263/Put/vlen=15/seqid=0, lastCell = 11000031219513/info:sfzh/1530512610263/Put/vlen=18/seqid=0
我用的是跟你一样的方法 sortbykey 排序,数据量是5000w
关于 spark 写 hbase 用 bulkload 方式的问题?
而且这是hbase的数据查询出来再存储到另一张表,不存在数据重复的情况
成为第一个点赞的人吧 
作者:魏超

魏超 的其他话题
分类下其他主题
QQ群1:551936262


关注海牛部落大数据技术社区
