引言:如果一个程序只包含固定数量的且生命期都是已知的对象,那么这是一个非常简单的程序。
其实这句话也挺好理解的,可以把一个程序比作一个家庭一座城市一个省会甚至一个宇宙(emmm)。回归正题,当把一个程序比作一个家庭的时候,家庭成员有父母、小孩、爷爷奶奶,这些就是上面所说的固定数量且生命周期都是已知的对象。那么我们是不是可以想象一下如果一个世界就只有家庭成员的存在,生活每天都是遇到相同的面孔相同的人会不会觉得有点单调了呢!如果再加上朋友、领导、亲戚、陌生人、外卖小哥...是不是世界开始变得丰富起来了。映射到程序也是这样子的 ,简单的程序里并不包含太多对象时就会显得太过于简单。那好办,多加对象让程序丰富起来不就得了,但是当程序中的对象很多时又会迎来新的问题:程序开始难以管理。就像在大青青草原上几个原始部落在一个资源充足的环境下和平相处,但突然有一天不知从哪里迁移过来了一大批人,他们也开始划分自己的领地,形成大大小小的部落,当资源分配不够时就会引发战争。emmm回到正题,程序也是一样的,当程序中的对象太多时就会变得难以管理,那该怎么办呢?别慌,这时就要上我们的正菜了,虐我千百遍我待她如初恋---Java集合!
Java提供了一套相当完整的集合类来解决上述所说的问题:合理管理对象。集合提供了完善的方法来存储对象,你可以使用这些工具来解决数量惊人的问题。(佩~难记得要死/(ㄒoㄒ)/)
来啦!老弟
废话不多说,废话又说了怎么多,我们先来简单认识一下Java的集合👇(混个面熟)
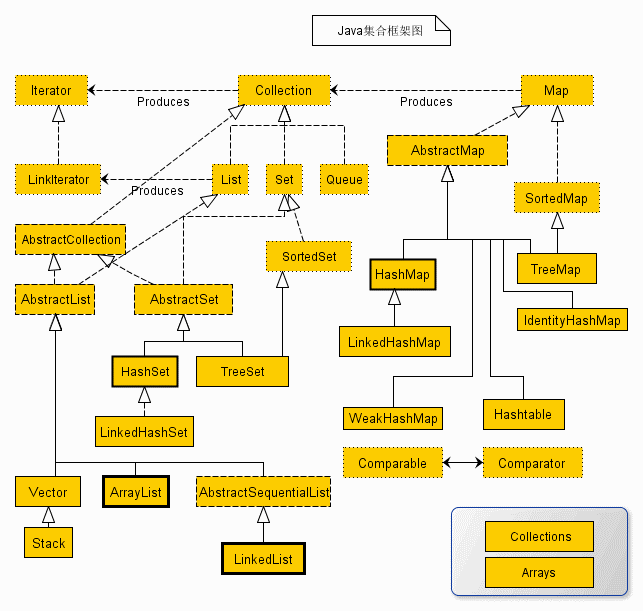
以下纯为本人总结复习使用(因为真的太乱了,没有跟大佬一样总结得很清晰,不过我会努力改进的)
1. java.util.Iterator接口 API:hasNext():boolean、next():E、remove():void
- Iterator接口的remove操作问题,异常抛出ConcurrentModificatException;fail-fast;
- 原理:expectedModCount != ModCount;
- 目的:为了避免将来因为其他线程而修改了集合的元素,导致当前这个操作的数据不正确的风险,干脆fail-fast;
- 而旧版的Enumration就不会快速失败,就有可能数据不一致性
- 所有的Collection系列的集合都包含一个:Iterator iterator() 方法
- 那Iterator接口的实现类在哪里?或者说Collection系列的集合中的iterator()是返回谁(哪个类)的对象?
- ArrayList:内部有一个内部类,class Itr implements Iterator接口
- Vector:内部也有一个内部类,class Itr implements Iterator接口
- LinkedList:内部也有一个内部类,class Itr implements Iterator接口,还有ListItr implements ListIterator接口
- 所以总结:每一种Collection系列集合的实现类中都有一个内部类实现了Iterator接口
- 那为什么要这么做呢?
- 这个Iterator接口对象的作用是用于遍历,迭代集合中的元素,设计为内部类的好处就是内部类可以方便的直接访问集合类内部的成员
- 比如:公交车上有售票员,遍历乘客收钱;火车上有乘务员,遍历乘客检查车票;飞机上有空姐,遍历乘客检查安全。即每一个集合类的迭代器只为当前的集合类服务!
2. ArrayList动态数组
- 1) 初始化大小
- 如果JDK1.8时new ArrayList(),发现数组初始化为一个DEFAULTCAPACITY_EMPTY_ELEMENTDATA,长度为0的空数组。
- 如果JDK1.7时new ArrayList(),发现数组初始化为一个EMPTY_ELEMENTDATA,长度为0的空数组
- 如果JDK1.6时new ArrayList(),发现数组直接初始化一个长度为10的Object[ ]
- 2)添加元素时,如果数组满了,如何扩容?
- JDK1.7和JDK1.8时,因为一开始是空数组,那么第一次扩展为长度10的数组,然后不够了,再扩为原来的1.5倍
- 3)删除元素时,数组会不会缩小?
- 不会
- 在移动完元素位置后,会把之前最后一个元素设为null,原因:为了失去掉这个引用,便于GC回收!
- 但是像ArrayList有一个trimToSize()可以调整数组大小
3. Set接口。Set的实现类底层实现都是new 相对于的Map实现类,用Map的Key存值。所以一般来说Set就是Map!
- HashSet:内部实现是HashMap。add()添加到HashSet的元素是作为HashMap的key,所有的value共享一个Object类型的常量对象PRESENT
- LinkedHashSet:内部实现是LinkedHashMap。add()添加到LinkedHashSet的元素是作为LinkedHashMap的key,所有的value共享同一个Object类型的常量对象PRESENT
- TreeSet:内部实现是TreeMap。add()添加到TreeSet的元素是作为TreeMap的key,所有的value共享同一个Objcet类型的常量对象PRESENT
4. LinkedList
- 1)内部实现:单向链表。记录Node first和Node last;
- 2)add(xx)。默认添加到链表的尾部linkLast(xx);
- 3)add(int index, xx); 先判断插入点的下标是在链表的左半边还是右半边,根据判断循环从头或从尾开始。找到需要插入点的下标元素,然后开始互换pre和next引用,完成插入操作。
- 4)remove(xx); 被删除的元素的前一个和后一个元素进行pre和next引用,完成操作后把被删除的元素的pre和next都设置为null,然后再把存的数据也设为null,这样被删除的元素就完全成为垃圾对象了!
5. JDK1.7以及之前的HashMap的底层实现是 数组+单向链表
- 1)数组的存储类型
- Map.Entry<K, V>接口的类型,HashMap.Entry<K, V>内部类类型,实现了Map.Entry。并且自身添加多了一个Entry<K, V> next 成员,方便形成链表!
- 2)为什么有链表
- 计算每一对映射关系的key的hash值,然后根据hash值在计算出index后决定存到table数组[index]
- 情况一:每个key的hash值一样,但是equals不一样---> index相同
- 情况二:每个key的hash值不一样,equals也不一样,但是通过公式运算后-->index相同
- 结论:那么table[index]中无法存放两个对象,所以只能设计为链表的结构,把他们串起来
- 3)数组的初始化长度是多少
- 初始化长度默认为16
- 如果手动指定的数组长度,那么也必须是2的n次方,如果不是会自动纠正为2的n次方(为了key的hash值在计算index时不会超过(数组的长度-1))
- 4)数组是否会扩容
- 会
- 那为什么扩容?因为如果不扩容,会导致链表会变得很长,那么它的查询效率,添加的效率整体就会降低
- 5)那什么情况下会扩容?
- 有一个变量threshold阈值来判断是否需要扩容
- 当这个threshold达到临界值时,就会考虑扩容,还要看当前添加(key,value)时是否table[index] == null,如果table[index] != null那么就会扩容,如果table[index] == null,那么本次就不先扩容
- DEFAULT_LOAD_FACTOR:默认加载因子0.75
- threshold = table.length 0.75; 第一次为16 0.75 = 12,当我们size达到12时就会考虑扩容
- 扩容到原来的2倍
- 6)index如何计算
- 拿到一个key的hash值之后,如何计算[index]
- key时null,固定位置[index] = [0]
- 第一步,先用Key的hashCode值通过hash(key)函数得到一个比较分散的“hash值"
- 第二步,再根据"hash值"与table.length做运算得到index:hash & (table.length - 1) 按位与 确保index再[0,length-1]范围内
- 拿到一个key的hash值之后,如何计算[index]
- 7)如何避免key不可重复的,换句话说,如果key重复了,会怎么办?
- 如果key相同(hash和equals都相同),那么我们会替换key对应的旧value
- key相同:先判断hash值,如果hash值相同,判断key的地址或equals是否相同
- 8)新的(key, value)添加到table[index]后,发现table[index]不为空,怎么连接的?
- (key,value)是作为table[index]的头,原来下面的元素作为我的next
6. JDK1.8的HashMap:底层实现(数组 + 单向链表/红黑树)
+ 1)为什么要从JDK1.8之前的链表设计,修改为链表或红黑树的设计?
+ 当某个链表比较长的时候,查询效率还是会降低(可以看红黑树是个啥东西就明白了!)
+ 为了提高查询效率,那么把table[index]下面的链表做调整
+ 如果table[index]的链表的节点的个数比较少(8个或以内)就保持链表
+ 如果超过8个,那么就要考虑把链表转为一颗红黑树
+ 源码:TREEIFY_THRESHOLD = 8;树化阈值,从链表转为红黑树的临界值
+ 2)那什么时候树化呢?
+ table[index]下的结点树一达到8个就树化嘛?(当然不是)↓
+ 如果table[index]的结点数量已经达到8个了,还要判断table.length是否达到64,如果没有达到64,先扩容数组
+ 如(每次添加都是添加到同一个链表下的):
+ 8个->9个 length从16->32; 9个->10个 length 从 32->64;10个->11个length已经到达64,table[index]就从Node类型转为TreeNode类型,说明树化了
+ MIN_TREEIFY_CAPACITY:最小树化容量64(树化的阈值)
+ 3)那树化了还会变回链表嘛?什么时候树-->链表呢?
+ 当删除同一个桶下的树结点时,这棵树的结点个数少于6时,会反树化,会回链表
+ UNTREEIFY_THRESHOLD = 6;反树化阈值
+ 为什么又要变回链表呢?因为树的结构太复杂,当结点少了之后,用链表会更高效率
+ 4)put添加的过程是什么样子的?
+ (1)[index]的计算问题
+ 第一步:用key的hash值调用hash()函数,干扰hash值,使得(key,value)能够更加均匀的分布在table数组中(hash()函数是1.7版本的优化点)
+ 第二部:hash值 & table.length-1,这样计算出的index保证了在[0, length-1]范围内
+ (2)数组的扩容问题
+ 第一种情况:当某个桶table[index]下的链表个数达到8个时,并且table.length < 64,那么就会扩容数组
+ 第二种情况:size >= threshold,并且table[index] != null,就会将数组扩容至原来的**2倍**,同时计算加载因子扩容2倍: threshold = length.length * loadFator(加载因子默认值时DEFAULT_LOAD_FACTOR:0.75)
+ (3)当把(key,value)添加到链表中时,JDK1.8是在链表的尾部添加进去的(JDK1.7是头部添加)

