问题:之前在我们学习kafka的时候,如果传输的对象是非基本数据类型,一般情况是并没有实现外部序列化类,我们在解决的时候是采用了java的序列化框架(ObjectInput/outputStream) 来实现的序列化,但是这样的效率会很低,如果kafka的吞吐量相当大的时候,对象序列化问题可能会成为一个瓶颈,这时候我们就需要用到google 提供的 protobuf序列化,protobuf序列化效率相当高 仅次于spark的 kyro序列化,是我们进行kafka 通信的的理想选择
如何搭建一个自己的protobuf序列化框架呢?
导入相关pom依赖:
<!--protobuff 序列化 相关包-->
<dependency>
<groupId>com.dyuproject.protostuff</groupId>
<artifactId>protostuff-runtime</artifactId>
<version>1.0.8</version>
</dependency>
<dependency>
<groupId>com.dyuproject.protostuff</groupId>
<artifactId>protostuff-core</artifactId>
<version>1.0.8</version>
</dependency>1.我们自定义一个java 类并提供get/set/toString方法,作为我们afka的消息传入协议,如下
(一定要实现序列化接口,否则不可不可序列化)
import java.io.Serializable;
public class Leeston implements Serializable {
public Leeston(String msg) {
this.msg = msg;
}
public Leeston() {}
private String msg ;
public String getMsg() {
return msg;
}
public void setMsg(String msg) {
this.msg = msg;
}
@Override
public String toString() {
return "Leeston{" +
"msg='" + msg + '\'' +
'}';
}
}-
创建一个SchemaCache 类对象,该类最主要作用就是获得我们java bean的 schema 对象,因为我们只有拿到了schema 对象,才能进行 protobuf的序列化和反序列化操作:
因为要保证序列化和反序列时的shema对象为同一个对象,因此一条消息时该类对象必须只存在一个,所以我们使用了单例模式,这里使用的是java的双检锁的单例模式,同时也需要使用volatile关键字来修饰我们的单例对象:import com.dyuproject.protostuff.Schema; import com.dyuproject.protostuff.runtime.RuntimeSchema; import com.google.common.cache.Cache; import com.google.common.cache.CacheBuilder; import java.util.concurrent.Callable; import java.util.concurrent.ExecutionException; import java.util.concurrent.TimeUnit; public class SchemaCache { /** * 用volatile修饰的变量,线程在每次使用变量的时候,都会读取变量修改后的最的值。 * volatile很容易被误用,其实它主要目的是用来进行原子性操作。 */ private volatile static SchemaCache instance; // 构造方法私有化,不允许外界创建对象 private SchemaCache() {} // 不需要 new 直接得到对象,使用了双检锁来实现 static SchemaCache getInstance() { if (instance == null) { synchronized (SchemaCache.class) { if (instance == null) { instance = new SchemaCache(); } } } return instance; } //缓存设定 过期时间:10分钟 private Cache<Class<?>, Schema<?>> cache = CacheBuilder .newBuilder() .maximumSize(1024).expireAfterWrite(10, TimeUnit.MINUTES).build(); // 获取cls类对象的schema的核心方法 public Schema get(final Class cls) { // 先从 cache get Callable<? extends Schema<?>> valueLoader = new Callable<Schema<?>>() { public Schema<?> call() throws Exception { return RuntimeSchema.createFrom(cls); } }; try { return cache.get(cls, valueLoader); } catch (ExecutionException e) { e.printStackTrace(); } // 如果是出现了异常 就直接返回null return null; } }3.接下来,需要写一个protobuf工具类,该工具类主要是实现3个功能,获得我们的shema对象,序列化方法以及反序列方法,主要注意点是我们的流对象需要Closer进行注册才能使用,代码如下:
import com.dyuproject.protostuff.LinkedBuffer; import com.dyuproject.protostuff.ProtobufIOUtil; import com.dyuproject.protostuff.Schema; import com.google.common.io.Closer; import org.objenesis.ObjenesisStd; import java.io.ByteArrayInputStream; import java.io.ByteArrayOutputStream; import java.io.IOException; // protobuff 序列化工具类 public class ProtobuffCodecUtil { // 该方法主要是注册我们的输入输出流,否则不能被ProtobufIOUtil识别 private static Closer closer = Closer.create(); // 序列化方法 public byte[] protoSerialize(Object object){ // 用linkedBuffer 来创建缓冲对象 LinkedBuffer buffer = LinkedBuffer.allocate(LinkedBuffer.DEFAULT_BUFFER_SIZE); // 创建类对象 Class cls = object.getClass(); ByteArrayOutputStream bos = new ByteArrayOutputStream(); closer.register(bos); Schema schema = getSchema(cls); try{ ProtobufIOUtil.writeTo(bos,object,schema,buffer); byte[] bytesResult = bos.toByteArray(); return bytesResult; }catch (Exception e){ e.printStackTrace(); }finally { try { closer.close(); bos.close(); } catch (IOException e) { e.printStackTrace(); } } return null; } // 该方法 private Schema getSchema(Class cls){ // 创建单例对象,然后再得到cls 类对象的 schema 返回 return SchemaCache.getInstance().get(cls); } // 反序列化 public Object protoDeSerialize(byte[] byteArr, Class<Leeston> leestonClass){ // 拿到二进制输入流 ByteArrayInputStream bis = new ByteArrayInputStream(byteArr); // 注册 closer.register(bis); // 通过 类对象获得 valueLoader 再获得该类对象的schema Schema schema = getSchema(leestonClass); ObjenesisStd objenesisStd = new ObjenesisStd(); // 使用 objenesisStd通过反射对象, 也可以用传统的反射机制创建对象, 如: Leeston leeston = leestonClass.newInstance() Object leeston = objenesisStd.newInstance(leestonClass); try { ProtobufIOUtil.mergeFrom(bis, leeston, schema); } catch (IOException e) { // 如果类对象匹配不上 抛出非法参数异常 throw new IllegalArgumentException(e); }finally { try { closer.close(); bis.close(); } catch (IOException e) { e.printStackTrace(); } } return leeston; } }4.接下来就是要定义外部的序列化和反序列化类了,注意:【为了让代码更为简洁】 我们定义了一个中间适配器LeeAdaptor来统一接收那些父类中不需要重写的方法:
序列化方法:public class LeestonSerializer extends LeeAdaptor implements Serializer<Leeston> { private ProtobuffCodecUtil codecUtil = new ProtobuffCodecUtil(); // LeeAdaptor 里配置了我们不需要用到的方法 @Override public byte[] serialize(String topic, Leeston data) { return codecUtil.protoSerialize(data); } }反序列化方法:
public class LeestonDeSerializer extends LeeAdaptor implements Deserializer<Leeston> { private ProtobuffCodecUtil codecUtil = new ProtobuffCodecUtil(); @Override public Leeston deserialize(String topic, byte[] data) { Object decode = codecUtil.protoDeSerialize(data,Leeston.class); // 强转为我们自己的 java bean 类型 return (Leeston)decode; } }还有我们的自定义Adaptor ,用于接收那些不需要重写的父类方法:
/** * 用不到的方法全部在这里进行配置 */ public class LeeAdaptor { public void configure(Map<String, ?> configs, boolean isKey) { } public void close() { } }下面为scala的kafka的测试代码:使用的分配模式并自定义了消费分区,每次拉取100ms数据消费,根据消费类型,只消费0分区数据,而我们传输的消息只有msg的后缀为偶数时才被分配到0分区;老师讲过我就不再详解拉!
import java.util import java.util.Properties import org.apache.kafka.clients.consumer.{ConsumerRecords, KafkaConsumer} import org.apache.kafka.clients.producer.{KafkaProducer, Partitioner, ProducerRecord} import org.apache.kafka.common.{Cluster, TopicPartition} import org.apache.kafka.common.serialization.{StringDeserializer, StringSerializer} import scala.actors.Actor /** * 低级API的使用 */ class HainiuKafkaSerAndDeserProducer extends Actor { var producer: KafkaProducer[String, Leeston] = _ var topic: String = _ def this(topic: String) = { this() this.topic = topic val props = new Properties() // broker 地址 props.put("bootstrap.servers", "s1.hadoop:9092,s2.hadoop:9092,s3.hadoop:9092,s4.hadoop:9092,s5.hadoop:9092,s6.hadoop:9092,s7.hadoop:9092,s8.hadoop:9092") // topic props.put("key.serializer", classOf[StringSerializer].getName) // 传递的信息序列化 props.put("value.serializer", classOf[LeestonSerializer].getName) // 生产的时候指定分区 加载我们的配置 props.put("partitioner.class", classOf[MyPartitioner].getName) producer = new KafkaProducer[String, Leeston](props) } override def act = { Thread.sleep(6000) var num: Int = 1 while (true) { val data = new Leeston("hainiu_" + num) System.out.println("send:" + data) // 发送到kafka this.producer.send(new ProducerRecord[String, Leeston](this.topic, data)) num += 1 if (num > 10) { num = 0 } Thread.sleep(3000) } } } } // 定义消费者线程 class HainiuKafkaSerAndDeserConsumer extends Actor { var topic: String = _ var kafkaConsumer: KafkaConsumer[String, Leeston] = _ def this(topic: String) { this() this.topic = topic val pro = new Properties() pro.put("bootstrap.servers", "s1.hadoop:9092,s2.hadoop:9092,s3.hadoop:9092,s4.hadoop:9092,s5.hadoop:9092,s6.hadoop:9092,s7.hadoop:9092,s8.hadoop:9092") pro.put("group.id", "group28") pro.put("auto.offset.reset", "latest") // 设置自动提交 pro.put("enable.auto.commit", "true") // 设置提交间隔时间 pro.put("auto.commit.interval.ms", "1000") pro.put("key.deserializer", classOf[StringDeserializer].getName) // 设置反序列化类,该类维护了我们传输对象,实现了反序列化 pro.put("value.deserializer", classOf[LeestonDeSerializer].getName) // 加载我们的配置文件 kafkaConsumer = new KafkaConsumer(pro) // 设置分配方式为assign,指定消费0分区! this.kafkaConsumer.assign(java.util.Arrays.asList(new TopicPartition(topic, 0))) } override def act(): Unit = { //具体消费行动! while (true) { // 这是拿一次性取东西的时间 val records: ConsumerRecords[String, Leeston] = this.kafkaConsumer.poll(100) // // 将scala的集合转为java集合 import scala.collection.convert.wrapAll._ records.foreach(record => { val data: Leeston = record.value() val topicName: String = record.topic() val partitionId: Int = record.partition() val offset: Long = record.offset() println(s"data:${data},topic:${topicName}, partition:${partitionId}, offset:${offset}") }) Thread.sleep(1000) } } } // producer 发送时,不用采用轮训方式,可以自定义分区 class MyPartitioner extends Partitioner { // o key o1 value //topic: String, key: scala.Any, keyBytes: Array[Byte], value: scala.Any, valueBytes: Array[Byte], cluster: Cluster override def partition(s: String, o: Any, bytes: Array[Byte], o1: Any, bytes1: Array[Byte], cluster: Cluster): Int = { val data: Leeston = o1.asInstanceOf[Leeston] val MSG: String = data.getMsg // 将要发送的消息分区! val num: Int = MSG.split("_")(1).toInt // 将 1,3,5,7,9 发送分区 1 分区 2,4,6,8,0 发送 0 分区! if (num % 2 == 0) 0 else 1 } override def close(): Unit = { } override def configure(map: util.Map[String, _]): Unit = { } }上述代码中设定外部序列化类的也可不用再prop 中设置,可以再我们创建KafkaProducer 和 KafkaConsumer对象的时候进行指定:
// 生产者传递的信息序列化类设置 props.put("key.serializer", classOf[StringSerializer].getName) props.put("value.serializer", classOf[LeestonSerializer].getName) producer = new KafkaProducer[String, Leeston](props) //上述代码可替换为如下代码: producer = new KafkaProducer[String, Leeston](props, new StringSerializer, new LeestonSerializer) // 消费者中也可以设置: pro.put("key.deserializer", classOf[StringDeserializer].getName) // 设置反序列化类,该类维护了我们传输对象,实现了反序列化 pro.put("value.deserializer", classOf[LeestonDeSerializer].getName) kafkaConsumer = new KafkaConsumer(pro) // 上面可用如下代码替换: kafkaConsumer = new KafkaConsumer(pro, new StringDeserializer, new LeestonDeSerializer)连接公司集群启动生产者和消费者:(最好新建一个topic ,避免传输异常)
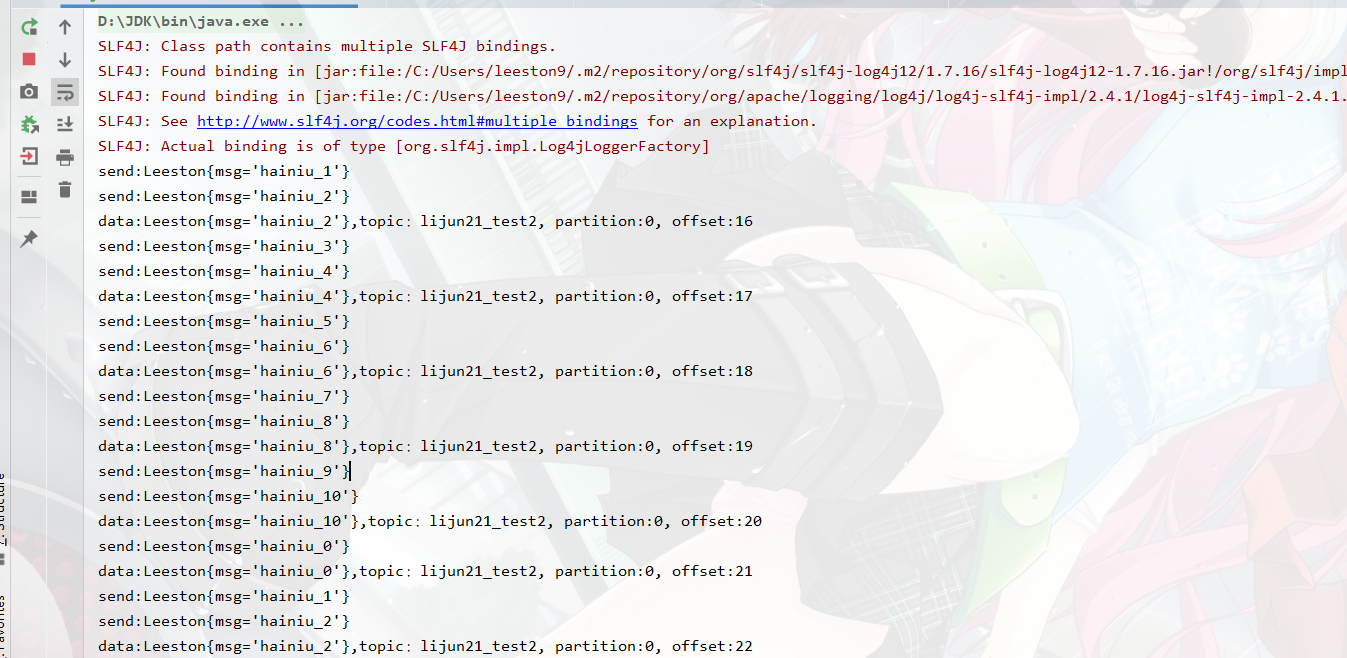
object HainiuKafkaSerAndDeserDemo { def main(args: Array[String]): Unit = { new HainiuKafkaSerAndDeserProducer("lijun21_test2").start() new HainiuKafkaSerAndDeserConsumer("lijun21_test2").start() }查看输出结果:
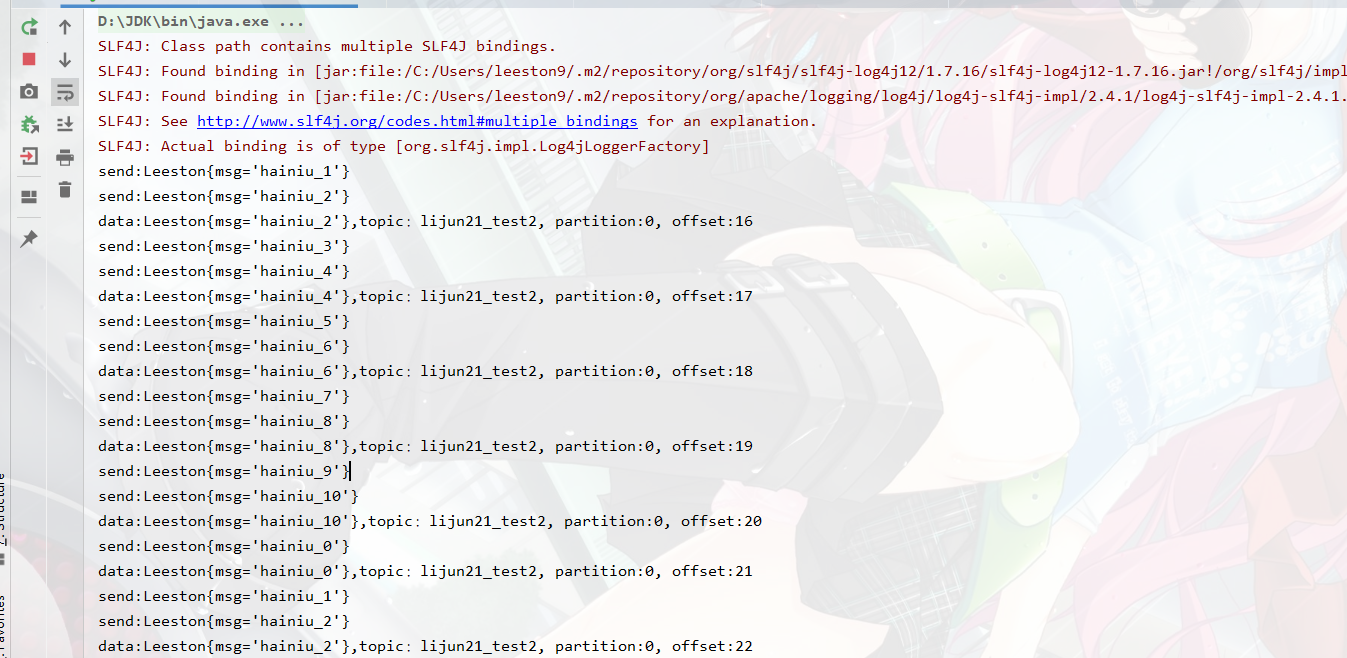
总结: protobuf序列化代码看起来比较麻烦,但写过一次后下次再使用就只需要修改极少部分代码,非常方便!