大数据技术之Doris
Doris简介
1.1 Doris介绍
Apache Doris最早诞生于2008年,最初只为解决百度凤巢报表的专用系统。在08年那个时候数据存储和计算成熟的开源产品非常少,Hbase的导入性能只有大约2000条/秒,在这种不能满足业务的背景下,doris1诞生了,并且跟随百度凤巢系统一起正式上线。
Apache Doris是一个现代化的MPP分析性数据库产品。仅需要亚秒级响应时间即可获得查询结果,有效地支持实时数据分析。Apache Doris可以满足多种数据分析需求,例如固定历史报表,实时数据分析。
https://baijiahao.baidu.com/s?id=1633669902039812353&wfr=spider&for=pc编译
(1)系统依赖,安装依赖
GCC 5.3.1+, Oracle JDK 1.8+, Python 2.7+, Apache Maven 3.5+, CMake 3.11+
root@doris1:/opt/software# apt-get -y update
root@doris1:/opt/software# apt-get install build-essential openjdk-11-jdk maven cmake byacc flex automake libtool-bin bison binutils-dev libiberty-dev zip unzip libncurses5-dev(2)上传apache-doris-0.12.0-incubating-src.tar.gz,并进行解压
root@doris1:/opt/software# tar -zxvf apache-doris-0.12.0-incubating-src.tar.gz -C /opt/module/
root@doris1:/opt/software# cd /opt/module/apache-doris-0.12.0-incubating-src/(3)进入到第三方文件夹下,创建src,上传第三方所需tar包
root@doris1:/opt/module/apache-doris-0.12.0-incubating-src# cd thirdparty/
root@doris1:/opt/module/apache-doris-0.12.0-incubating-src/thirdparty# mkdir src
(4)ubuntu默认换环境dash,切回bash
root@doris1:ls -al /bin/sh
root@doris1:/opt/module/apache-doris-0.12.0-incubating-src# dpkg-reconfigure dash
选择no(5)配置JAVA_HOME
root@doris1:/opt/module/apache-doris-0.12.0-incubating-src# vim /etc/profile
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64/
export PATH=${JAVA_HOME}/bin:$PATH
root@doris1:/opt/module/apache-doris-0.12.0-incubating-src# source /etc/profile(6)配置maven阿里云镜像
root@doris1:/opt/module/apache-doris-0.12.0-incubating-src# sh build.sh 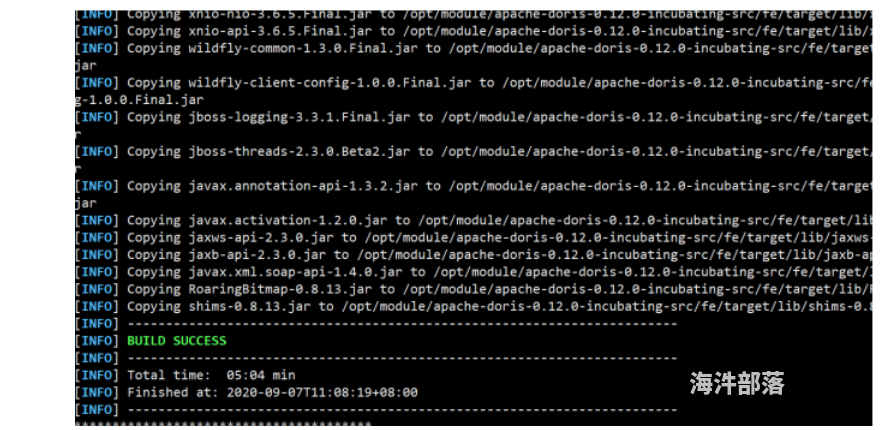
(7)编译成功后,/output目录下产生相应文件

安装
3.1软硬件需求
(1)linux操作系统要求
| linux系统 | 版本 |
|---|---|
| Centos | 7.1及以上 |
| Ubuntu | 16.04及以上 |
(2)软件需求
| 软件 | 版本 |
|---|---|
| Java | 1.8及以上 |
| GCC | 4.8.2及以上 |
(3)开发测试环境
| 模块 | CPU | 内存 | 磁盘 | 网络 | 实例数量 |
|---|---|---|---|---|---|
| Frontend | 8核+ | 8GB | SSD 或 SATA,10GB+ * | 千兆网卡 | 1 |
| Backend | 8核+ | 16GB | SSD 或 SATA,50GB+ * | 千兆网卡 | 1-3* |
(4)生产环境
| 模块 | CPU | 内存 | 磁盘 | 网络 | 实例数量 |
|---|---|---|---|---|---|
| Frontend | 16核+ | 64GB | SSD 或 SATA,100GB+ * | 万兆网卡 | 1-5* |
| Backend | 16核+ | 64GB | SSD 或 SATA,100GB+ * | 万兆网卡 | 10-100* |
(5)默认端口
| 实例名称 | 端口名称 | 默认端口 | 通讯方向 | 说明 |
|---|---|---|---|---|
| BE | be_prot | 9060 | FE-->BE | BE 上 thrift server 的端口,用于接收来自 FE 的请求 |
| BE | webserver_port | 8040 | BE<-->FE | BE上的http server端口 |
| BE | heartbeat_service_port | 9050 | FE-->BE | BE上心跳服务端口,用于接收来自FE的心跳 |
| BE | brpc_prot* | 8060 | FE<-->BE,BE<-->BE | BE上的brpc端口,用于BE之间通信 |
| FE | http_port | 8030 | FE<-->FE,用户 | FE上的http_server端口 |
| FE | rpc_port | 9020 | BE-->FE,FE<-->FE | FE上thirt server端口号 |
| FE | query_port | 9030 | 用户 | FE上的mysql server端口 |
| FE | edit_log_port | 9010 | FE<-->FE | FE上bdbje之间通信用的端口 |
| Broker | broker_ipc_port | 8000 | FE-->BROKER BE-->BROKER | Broker上的thrift server,用于接收请求 |
注:
1.FE的磁盘主要用于存储元数据,包括日志,和image。通常几百MB到几个GB不等
2.BE的磁盘主要用于存储用户数据,总磁盘空间按用户总数据量*3(3份副本)计算,然后再预留额外40%的空间用作后台compaction以及一些中间数据的存放。
3.一台机器上可以部署多个BE实例,但只能部署一个FE。如果需要3副本数据,那么至少三台机器各部署一个BE实例。
4.FE角色分为Follower和Observer,(Leader为Follwer中选举出来的一种角色)
5.FE节点至少为1个。当部署1个Follower和1个Observer时,可以实现高可用HA
6.Follower的数量必须为奇数,Observer数量随意
7.根据官网描述,以往经验,当集群可用性要求很高,可以部署3个Follower和1-3个Observer。如果是离线业务,建议部署1个Follower和1-3个Observer
8.Broker部署,Broker是用于访问外部数据源hdfs进程。通常每台机器上部署一个broker实例即可。3.2集群部署
| Dors1 | Dors2 | Dors3 |
|---|---|---|
| FE(LEADER) | FE(FOLLOWER) | FE(OBSERVER) |
| BE | BE | BE |
| BROKER | BROKER | BROKER |
(1)准备三台机器,配置对应域名
root@doris1:~# vim /etc/hosts
172.26.16.60 doris1 doris1
172.26.16.61 doris2 doris2
172.26.16.62 doris3 doris3
root@doris1:~# scp /etc/hosts doris2:/etc
root@doris1:~# scp /etc/hosts doris3:/etc(2)安装jdk
root@doris1:~# apt-get -y update
root@doris1:~# apt-get install openjdk-11-jdk
root@doris1:~# vim /etc/profile
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64/
export PATH=${JAVA_HOME}/bin:$PATH
root@doris1:~# source /etc/profile
root@doris2:~# apt-get -y update
root@doris2:~# apt-get install openjdk-11-jdk
root@doris3:~# apt-get -y update
root@doris3:~# apt-get install openjdk-11-jdk
root@doris1:~# scp /etc/profile doris2:/etc/
root@doris1:~# scp /etc/profile doris3:/etc/
root@doris2:~# source /etc/profile(2)ubuntu默认换环境dash,切回bash,其他两台机器也是一样进行更改
root@doris1:~# ls -al /bin/sh
root@doris1:~# dpkg-reconfigure dash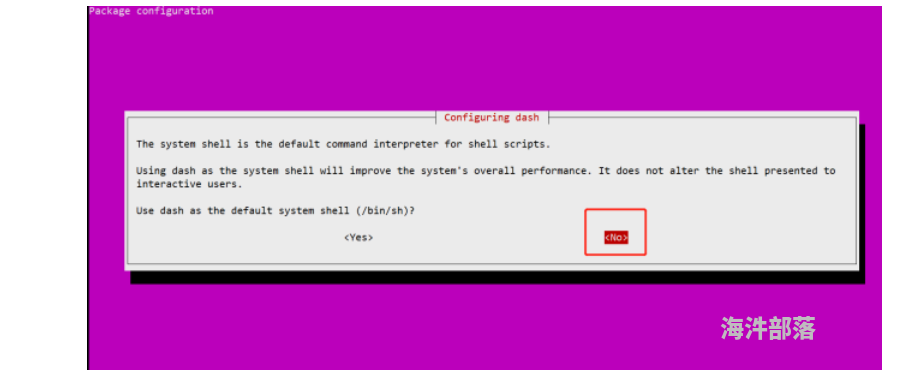
(4)手动部署,配置FE,上传编译后的doris,并进行配置
root@doris1:~# mkdir /opt/module
root@doris2:~# mkdir /opt/module
root@doris3:~# mkdir /opt/module
root@doris1:~# cd /opt/module/
root@doris1:/opt/module# scp -r doris doris2:/opt/module
root@doris1:/opt/module# scp -r doris doris3:/opt/module
root@doris1:/opt/module# cd doris/fe/conf/
root@doris1:/opt/module/doris/fe/conf# vim fe.conf
meta_dir = /opt/module/doris-meta
root@doris1:/opt/module/doris/fe/conf# mkdir /opt/module/doris-meta
root@doris1:/opt/module/doris/fe/conf# cd ..
root@doris1:/opt/module/doris/fe# sh bin/start_fe.sh --daemon
root@doris1:/opt/module/doris/fe# jps
15878 PaloFe
15983 Jps(5)部署BE节点,storage_root_path配置存储目录,可以用;来指定多个目录,每个目录后可以跟逗号,指定大小默认GB
root@doris1:/opt/module/doris/fe# cd ..
root@doris1:/opt/module/doris# cd be/conf/
root@doris1:/opt/module/doris/be/conf# vim be.conf
storage_root_path = /opt/module/doris_storage1,10;/opt/module/doris_storage2
root@doris1:/opt/module/doris/be/conf# mkdir /opt/module/doris_storage1
root@doris1:/opt/module/doris/be/conf# mkdir /opt/module/doris_storage2
root@doris2:~# cd /opt/module/doris/be/conf/
root@doris2:/opt/module/doris/be/conf# vim be.conf
storage_root_path = /opt/module/doris_storage1,10;/opt/module/doris_storage2
root@doris2:/opt/module/doris/be/conf# mkdir /opt/module/doris_storage1
root@doris2:/opt/module/doris/be/conf# mkdir /opt/module/doris_storage2
root@doris3:~# cd /opt/module/doris/be/conf/
root@doris3:/opt/module/doris/be/conf# vim be.conf
storage_root_path = /opt/module/doris_storage1,10;/opt/module/doris_storage2
root@doris3:/opt/module/doris/be/conf# mkdir /opt/module/doris_storage1
root@doris3:/opt/module/doris/be/conf# mkdir /opt/module/doris_storage2(6)安装mysql客户端,上传所需离线包
root@doris1:/opt/software# dpkg -i mysql-common_5.7.31-1ubuntu18.04_amd64.deb
root@doris1:/opt/software# dpkg -i mysql-community-client_5.7.31-1ubuntu18.04_amd64.deb
root@doris1:/opt/software# dpkg -i mysql-community-client-dbgsym_5.7.31-1ubuntu18.04_amd64.deb
root@doris1:/opt/software# dpkg -i mysql-community-client-dbgsym_5.7.31-1ubuntu18.04_amd64.deb
root@doris1:/opt/software# dpkg -i libmysqlclient20-dbgsym_5.7.31-1ubuntu18.04_amd64.deb
root@doris1:/opt/software# dpkg -i libmysqlclient-dev_5.7.31-1ubuntu18.04_amd64.deb
root@doris1:/opt/software# dpkg -i mysql-client_5.7.31-1ubuntu18.04_amd64.deb(7)安装mysql客户端后,使用客户端访问doris pe节点
root@doris1:/opt/software# mysql -hdoris1 -P 9030 -uroot(8)登录后添加be节点,port为be上的heartbeat_service_port端口,默认9050
mysql> ALTER SYSTEM ADD BACKEND "doris1:9050";
mysql> ALTER SYSTEM ADD BACKEND "doris2:9050";
mysql> ALTER SYSTEM ADD BACKEND "doris3:9050";(9)启动be节点
root@doris1:~# cd /opt/module/doris/be/
root@doris1:/opt/module/doris/be# sh bin/start_be.sh --daemon
root@doris2:~# cd /opt/module/doris/be/
root@doris2:/opt/module/doris/be# sh bin/start_be.sh --daemon
root@doris3:~# cd /opt/module/doris/be/
root@doris3:/opt/module/doris/be# sh bin/start_be.sh --daemon (10)通过mysql客户端,检测be节点状态,alive必须为true
root@doris1:/opt/software# mysql -hdoris1 -P 9030 -uroot
mysql> SHOW PROC '/backends';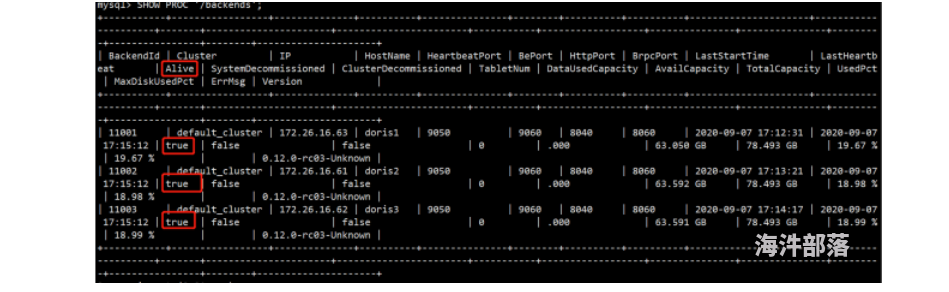
(11)可选,非必须部署,部署FS_BROKER,BROKER以插件的形式,独立与Doris的部署,建议每个PE和BE节点都部署一个Broker,Broker是用于访问外部数据源的进程,默认是HDSF。上传编译好的hdfs_broker。
root@doris1:/opt/module# scp -r apache_hdfs_broker/ doris2:/opt/module
root@doris1:/opt/module# scp -r apache_hdfs_broker/ doris3:/opt/module
root@doris1:/opt/module/apache_hdfs_broker# sh bin/start_broker.sh --daemon
root@doris2:/opt/module/apache_hdfs_broker# sh bin/start_broker.sh --daemon
root@doris3:/opt/module/apache_hdfs_broker# sh bin/start_broker.sh --daemon(12)使用mysql客户端访问pe,添加broker节点
root@doris1:/opt/module/apache_hdfs_broker# mysql -hdoris1 -P 9030 -uroot
mysql> ALTER SYSTEM ADD BROKER broker_name "doris1:8000","doris2:8000","doris3:8000";(13)查看Broker状态
mysql> SHOW PROC "/brokers";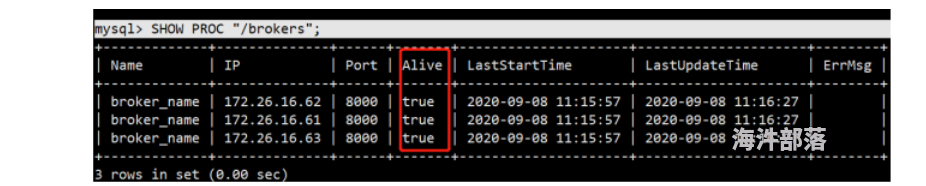
3.3扩容和缩容
(1)使用mysql登录客户端后,可以使用sql命令查看FE状态,目前就一台FE
root@doris1:/opt/module/apache_hdfs_broker# mysql -hdoris1 -P 9030 -uroot
mysql> SHOW PROC '/frontends';
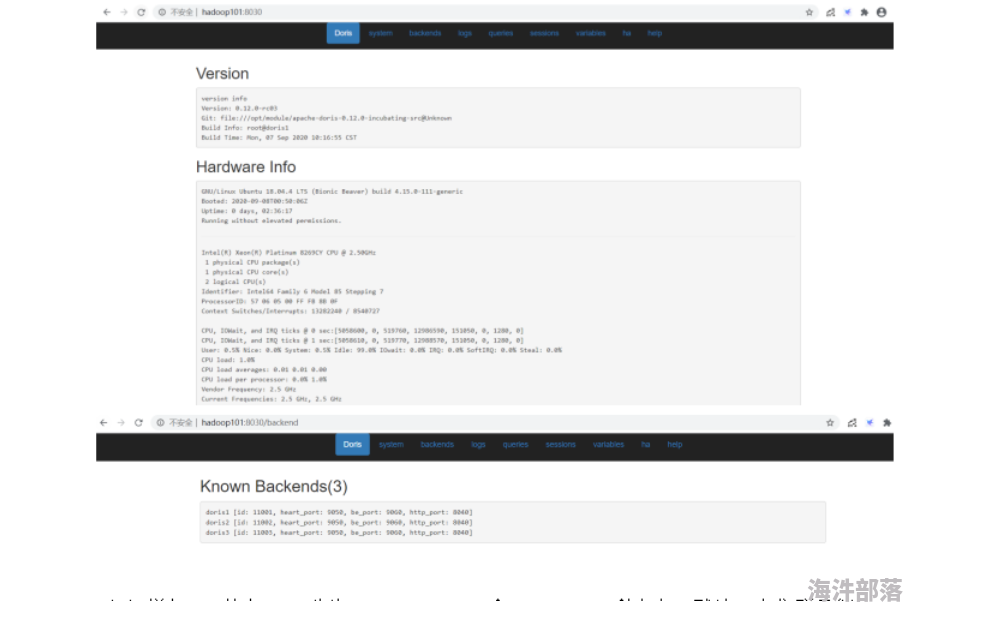
(2)也可以通过页面访问进行监控,访问8030,账户为root,密码默认为空不用填写
(3)增加FE节点,FE分为Leader,Follower和Observer三种角色。默认一个集群只能有一个Leader,可以有多个Follower和Observer.其中Leader和Follower组成一个Paxos选择组,如果Leader宕机,则剩下的Follower会成为Leader,保证HA。Observer是负责同步Leader数据的不参与选举。如果只部署一个FE,则FE默认就是Leader。
(4)在doris2再部署一台FE,doris3上部署Observer。--helper参数指定leader地址和端口号
mysql> ALTER SYSTEM ADD FOLLOWER "doris2:9010";
mysql> ALTER SYSTEM ADD OBSERVER "doris3:9010";
root@doris2:/opt/module/doris/fe# mkdir /opt/module/doris/fe/doris-meta
root@doris2:/opt/module/doris/fe# sh bin/start_fe.sh --helper doris1:9010 --daemon
root@doris3:/opt/module/doris/fe# mkdir /opt/module/doris/fe/doris-meta
root@doris3:/opt/module/doris/fe# sh bin/start_fe.sh --helper doris1:9010 --daemon(5)全部启动完毕后,再通过mysql客户端,查看FE状况
mysql> SHOW PROC '/frontends';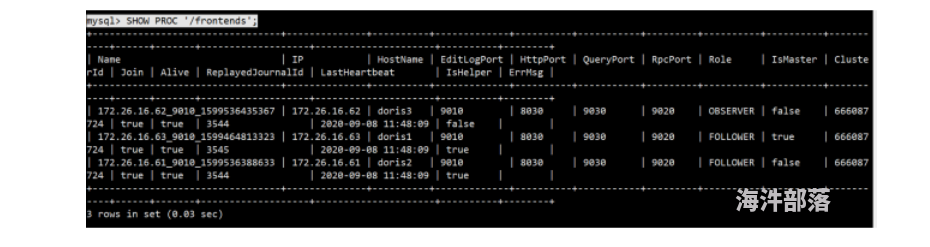
(6)增加BE节点,就像上面安装一样在mysql客户端,使用ALTER SYSTEM ADD BACKEND语句即可,相对应删除BE节点,使用ALTER SYSTEM DECOMMISSION BACKEND "be_host:be_heartbeat_service_port";)
使用
4.1创建用户
(1)创建test用户
root@doris1:~# mysql -hdoris1 -P 9030 -uroot
mysql> create user 'test' identified by 'test';(2)创建完了就可以使用test用户登录了
mysql> exit;
root@doris1:~# mysql -hdoris1 -P 9030 -utest -ptest4.2建表
(1)创建数据库
mysql> create database test_db;(2)权限赋予
--将tes_db数据库授权给test用户,这样test用户就有tetst库的读写权限了
mysql> grant all on test_dn to test;(3)建表
--建表,首先切换数据库
mysql> use test_db;4.2.1字段类型
| TINYINT | 1字节 | 范围:-2^7 + 1 ~ 2^7 - 1 |
|---|---|---|
| SMALLINT | 2字节 | 范围:-2^15 + 1 ~ 2^15 - 1 |
| BIGINT | 8字节 | 范围:-2^63 + 1 ~ 2^63 - 1 |
| LARGEINT | 16字节 | 范围:-2^127 + 1 ~ 2^127 - 1 |
| FLOAT | 4字节 | 支持科学计数法 |
| DOUBLE | 12字节 | 支持科学计数法 |
| DECIMAL[(precision, scale)] | 16字节 | 保证精度的小数类型。默认是 DECIMAL(10, 0)precision: 1 ~ 27scale: 0 ~ 9其中整数部分为 1 ~ 18不支持科学计数法 |
| DATE | 3字节 | 范围:0000-01-01 ~ 9999-12-31 |
| DATETIME | 8字节 | 范围:0000-01-01 00:00:00 ~ 9999-12-31 23:59:59 |
| CHAR[(length)] | 定长字符串。长度范围:1 ~ 255。默认为1 | |
| VARCHAR[(length)] | 变长字符串。长度范围:1 ~ 65533 | |
| HLL | 1~16385个字节 | hll列类型,不需要指定长度和默认值、长度根据数据的聚合程度系统内控制,并且HLL列只能通过配套的hll_union_agg、Hll_cardinality、hll_hash进行查询或使用 |
| BITMAP | bitmap列类型,不需要指定长度和默认值。表示整型的集合,元素最大支持到2^64 - 1 | |
| agg_type | 聚合类型,如果不指定,则该列为 key 列。否则,该列为 value 列 | SUM、MAX、MIN、REPLACE |
分区
Doris支持单分区和复合分区两种建表方式。
在复合分区中:
第一级称为Partition,即分区。用户指定某一维度列做为分区列(当前只支持整型和时间类型的列),并指定每个分区的取值范围。
第二级称为Distribution,即分桶。用户可以指定一个或多个维度列以及桶数进行HASH分布。
#以下场景推荐使用复合分区
1.有时间维或类似带有有序值的维度,可以以这类维度列作为分区列。分区粒度可以根据导入频次、分区数据量等进行评估。
2.历史数据删除需求:如有删除历史数据的需求(比如仅保留最近N天的数据)。使用复合分区,可以通过删除历史分区来达到目的。也可以通过在指定分区内发送DELETE于禁进行删除。
3.解决数据倾斜的问题:每个分区可以单独指定分桶数量。如按天分区,当每天的数据量差异很大的时,可以通过指定分区的分桶数,合理规划不同分区的数据,分桶列建议选择区分度大的列。
用户也可以不是用复合分区,仅使用单分区。则数据只做HASH分布。创建单分区表
CREATE TABLE student
(
id INT,
name VARCHAR(50),
age INT,
count BIGINT SUM DEFAULT '0'
)
AGGREGATE KEY (id,name,age)
DISTRIBUTED BY HASH(id) buckets 10
PROPERTIES("replication_num" = "1");建立一张student表。分桶列为id,桶数为10,副本数为1。
创建复合分区表
CREATE TABLE student2
(
dt DATE,
id INT,
name VARCHAR(50),
age INT,
count BIGINT SUM DEFAULT '0'
)
AGGREGATE KEY (dt,id,name,age)
PARTITION BY RANGE(dt)
(
PARTITION p202007 VALUES LESS THAN ('2020-08-01'),
PARTITION p202008 VALUES LESS THAN ('2020-09-01'),
PARTITION p202009 VALUES LESS THAN ('2020-10-01')
)
DISTRIBUTED BY HASH(id) buckets 10
PROPERTIES("replication_num" = "1");创建student2表,使用dt字段作为分区列,并且创建3个分区发,分别是:
P202007 范围值是是小于2020-08-01的数据
P202008 范围值是2020-08-01到2020-08-31的数据
P202009 范围值是2020-09-01到2020-09-30的数据
数据模型
Doris数据模型上目前分为三种 AGGREGATE KEY, UNIQUE KEY, DUPLICATE KEY。三种模型都是按KEY进行排序1 .AGGREGATE KEY
AGGREGATE KEY相同时,新旧记录将会进行聚合操作,目前支持SUM,MIN,MAX,REPLACE。
AGGREGATE KEY模型可以提前聚合数据,适合报表和多维度业务。(1)建表
CREATE TABLE site_visit
(
siteid INT,
city SMALLINT,
username VARCHAR(32),
pv BIGINT SUM DEFAULT '0'
)
AGGREGATE KEY(siteid, city, username)
DISTRIBUTED BY HASH(siteid) BUCKETS 10;(2)插入2条数据
mysql> insert into site_visit values(1,1,'name1',10);
mysql> insert into site_visit values(1,1,'name1',20);(3)查看结果
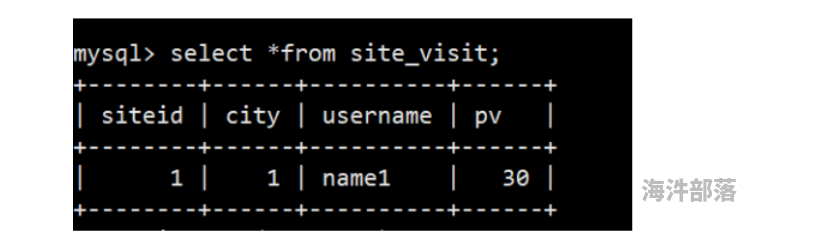
2 .UNIQUE KEY
UNIQUE KEY相同时,新记录覆盖旧记录。目前UNIQUE KEY和AGGREGATE KEY的REPLACE聚合方法一致。适用于有更新需求的业务。
(1)建表
CREATE TABLE sales_order
(
orderid BIGINT,
status TINYINT,
username VARCHAR(32),
amount BIGINT DEFAULT '0'
)
UNIQUE KEY(orderid)
DISTRIBUTED BY HASH(orderid) BUCKETS 10;(2)插入2条数据
mysql> insert into sales_order values(1,1,'name1',100);
mysql> insert into sales_order values(1,1,'name1',200);(3)查询
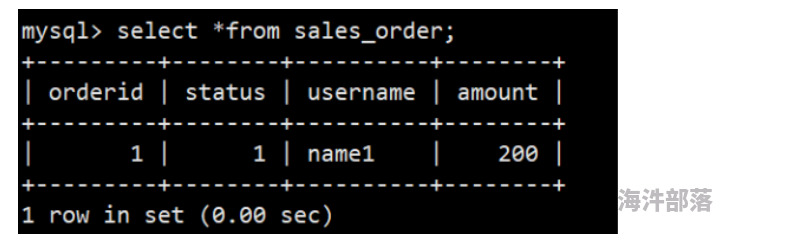
3. DUPLICATE KEY
只指定排序列,相同的行并不会合并。适用于数据无需提前聚合的分析业务。
(1)建表
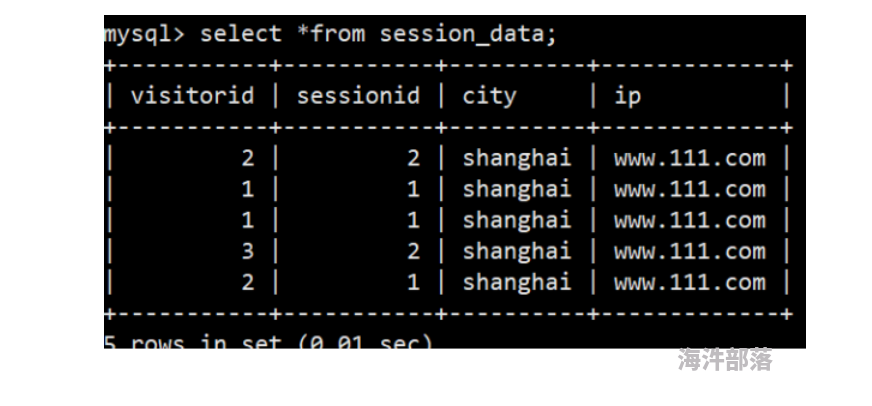
CREATE TABLE session_data
(
visitorid SMALLINT,
sessionid BIGINT,
city CHAR(20),
ip varchar(32)
)
DUPLICATE KEY(visitorid, sessionid)
DISTRIBUTED BY HASH(sessionid, visitorid) BUCKETS 10;(2)插入数据
mysql> insert into session_data values(1,1,'shanghai','www.111.com');
mysql> insert into session_data values(1,1,'shanghai','www.111.com');
mysql> insert into session_data values(3,2,'shanghai','www.111.com');
mysql> insert into session_data values(2,2,'shanghai','www.111.com');
mysql> insert into session_data values(2,1,'shanghai','www.111.com');(3)查询
Rollup
Rollup可以理解为表的一个物化索引结构。Rollup可以调整列的顺序以增加前缀索引的命中率,也可以减少key列以增加数据的聚合度。
(1)以session_data为例添加Rollup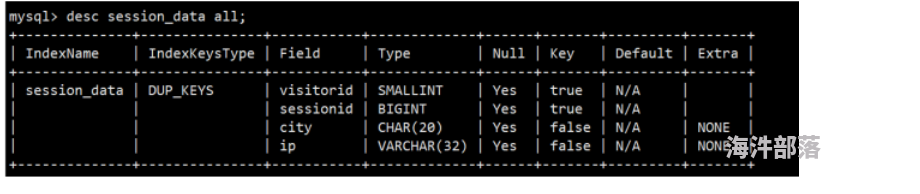
(2)比如我经常需要看某个城市的ip数,那么可以建立一个只有ip和city的rollup
mysql> alter table session_data add rollup rollup_city_ip(city,ip);(3)创建完毕后,再次查看表结构
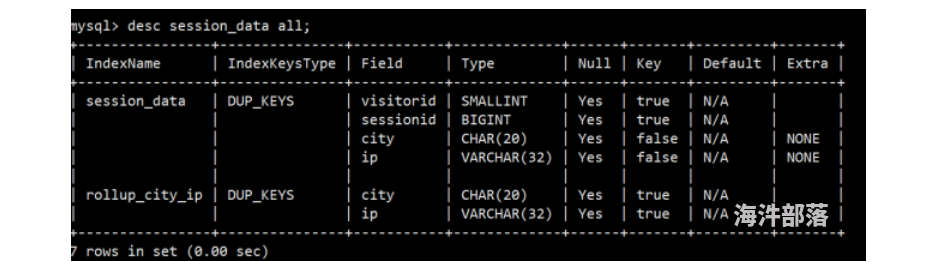
(4)然后可以通过explain查看执行计划,是否使用到了rollup
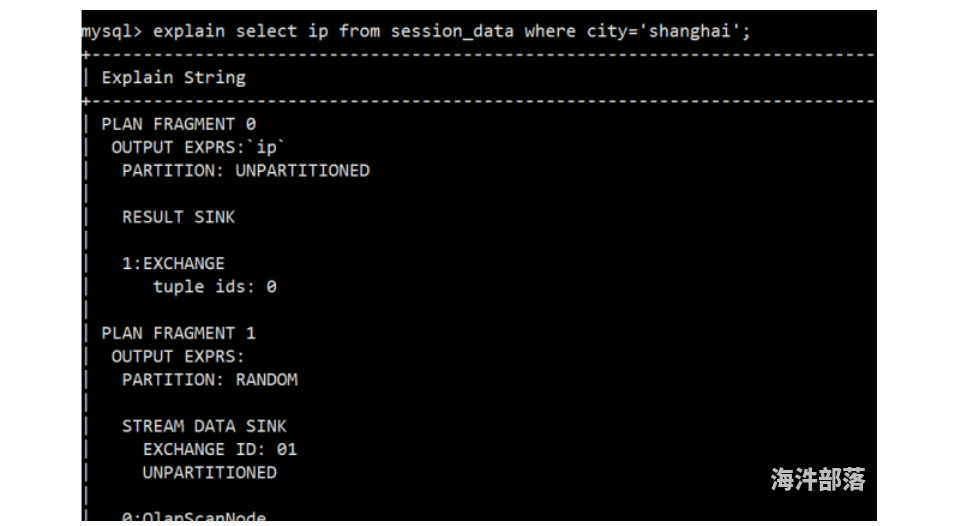
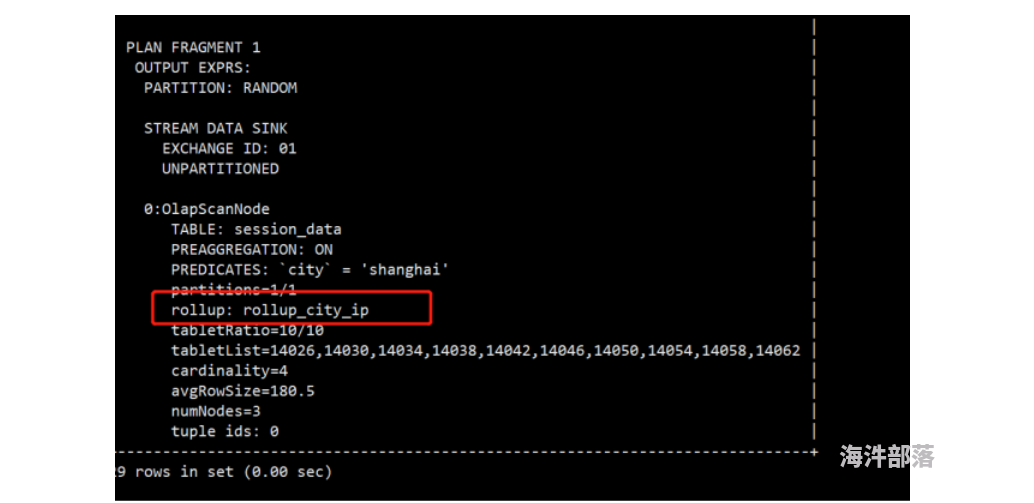
4.3数据导入
为适配不同的数据导入需求,Doris系统提供5种不同的导入方式。每种导入方式支持不同的数据源,存在不同的方式(异步、同步)
(1)Broker load
通过Broker进程访问并读取外部数据源(HDFS)导入Doris。用户通过MySql协议提交导入作业后,异步执行。通过show load命令查看导入结果。
(2)Stream load
用户通过HTTP协议提交请求并携带原始数据创建导入。主要用于快速将本地文件或数据流中的数据导入到Doris。导入命令同步返回导入结果。
(3)Insert
类似MySql中的insert语句,Doris提供insert into tbl select ...;的方式从Doris的表中读取数据并导入到另一张表。或者通过insert into tbl values(...);的方式插入单条数据
(4)Multi load
用户可以通过HTTP协议提交多个导入作业。Multi Load可以保证多个导入作业的原子生效
(5)Routine load
用户通过MySql协议提交例行导入作业,生成一个常住线程,不间断的从数据源(如Kafka)中读取数据并导入Doris中。1.Broker Load
Broker load是一个导入的异步方式,支持的数据源取决于Broker进程支持的数据源。
适用场景:(1)源数据在Broker可以访问的存储系统中,如HDFS
(2)数据量在几十到百GB级别
基本原理:用户在提交导入任务后,FE(Doris系统的元数据和调度节点)会生成相应的PLAN(导入执行计划,BE会执行导入计划将输入导入Doris中)并根据BE(Doris系统的计算和存储节点)的个数和文件的大小,将Plan分给多个BE执行,每个BE导入一部分数据。BE在执行过程中会从Broker拉取数据,在对数据转换之后导入系统。所有BE均完成导入,由FE最终决定是否导入是否成功。(1)启动hdfs集群

[root@hadoop101 ~]# /opt/module/apache-zookeeper-3.5.7-bin/bin/zkServer.sh start
[root@hadoop102 ~]# /opt/module/apache-zookeeper-3.5.7-bin/bin/zkServer.sh start
[root@hadoop103 ~]# /opt/module/apache-zookeeper-3.5.7-bin/bin/zkServer.sh start
[root@hadoop101 ~]# start-all.sh
[root@hadoop102 ~]# mr-jobhistory-daemon.sh start historyserver
[root@hadoop102 ~]# start-history-server.sh 
(2)进入到hive创建student_tmp表,虽然官网提示说支持列式存储,但测试发现并不支持,会提示一下错误
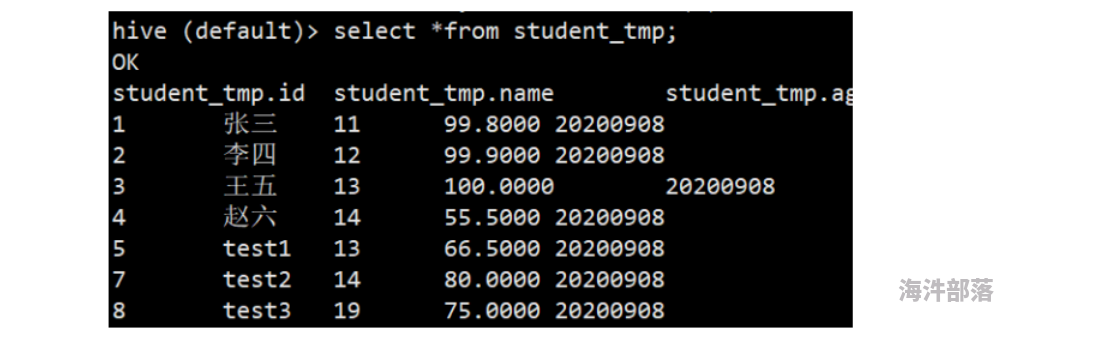
所以在hive表里创建行式存储表
[root@hadoop101 ~]# hive
create table student_tmp_h(
id int,
name string,
age int,
score decimal(10,4))
partitioned by (
`dt` string)
row format delimited fields terminated by '\t';(3)插入数据
hive (default)> set hive.exec.dynamic.partition=true;
hive (default)> set hive.exec.dynamic.partition.mode=nonstrict;
insert into student_tmp_h values(1,'张三',11,99.8,20200908),(2,'李四',12,99.9,20200908),(3,'王五',13,100,20200908),
(4,'赵六',14,55.5,20200908),(5,'test1',13,66.5,20200908),(7,'test2',14,80,20200908),(8,'test3',19,75,20200908);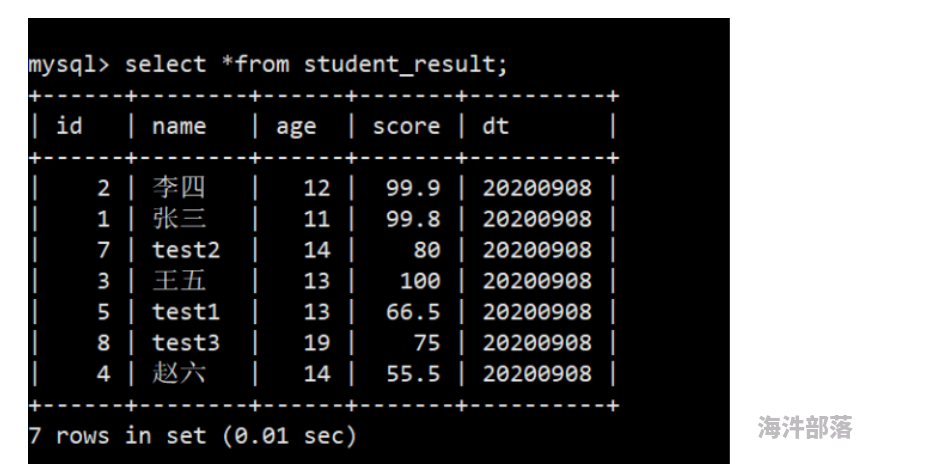
(4)修改doris1,doris2,doris3的hosts文件,添加hadoop101,hadoop102,hadoop103
root@doris1:~# vim /etc/hosts
172.26.16.63 doris1 doris1
172.26.16.61 doris2 doris2
172.26.16.62 doris3 doris3
172.26.16.41 hadoop101 hadoop101
172.26.16.39 hadoop102 hadoop102
172.26.16.40 hadoop103 hadoop103
root@doris1:~# scp /etc/hosts doris2:/etc
root@doris1:~# scp /etc/hosts doris3:/etc(5)将hadoop集群的配置文件复制到doris集群的broker上
[root@hadoop101 ~]# cd /opt/module/hadoop-3.1.3/etc/hadoop/
[root@hadoop101 hadoop]# scp hdfs-site.xml 172.26.16.63:/opt/software/
root@doris1:~# cd /opt/software/
root@doris1:/opt/software# cp hdfs-site.xml /opt/module/apache_hdfs_broker/conf/
root@doris1:/opt/software# scp hdfs-site.xml doris2:/opt/module/apache_hdfs_broker/conf/
root@doris1:/opt/software# scp hdfs-site.xml doris3:/opt/module/apache_hdfs_broker/conf/(6)使用mysql客户端登录doris创建对应表student_result
root@doris1:~# mysql -hdoris1 -P 9030 -uroot
mysql> use test_db;
create table student_result
(
id int ,
name varchar(50),
age int ,
score decimal(10,4),
dt varchar(20)
)
DUPLICATE KEY(id)
DISTRIBUTED BY HASH(id) BUCKETS 10;(7)编写导入语句,dt是分区列,在数据块读不到所以使用固定值
LOAD LABEL test_db.student_result_h_2
(
DATA INFILE("hdfs://mycluster/user/hive/warehouse/student_tmp_h/dt=20200908/*")
INTO TABLE student_result
COLUMNS TERMINATED BY "\t"
(co1,co2,co3,co4)
set(
id=co1,
name=co2,
age=co3,
score=co4,
dt='20200908'
)
)
WITH BROKER "broker_name"
(
"dfs.nameservices"="mycluster",
"dfs.ha.namenodes.mycluster"="nn1,nn2,nn3",
"dfs.namenode.rpc-address.mycluster.nn1"= "hadoop101:8020",
"dfs.namenode.rpc-address.mycluster.nn2"= "hadoop102:8020",
"dfs.namenode.rpc-address.mycluster.nn3"="hadoop103:8020",
"dfs.client.failover.proxy.provider.mycluster"="org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider"
)(8)导入成功后,查询doris数据
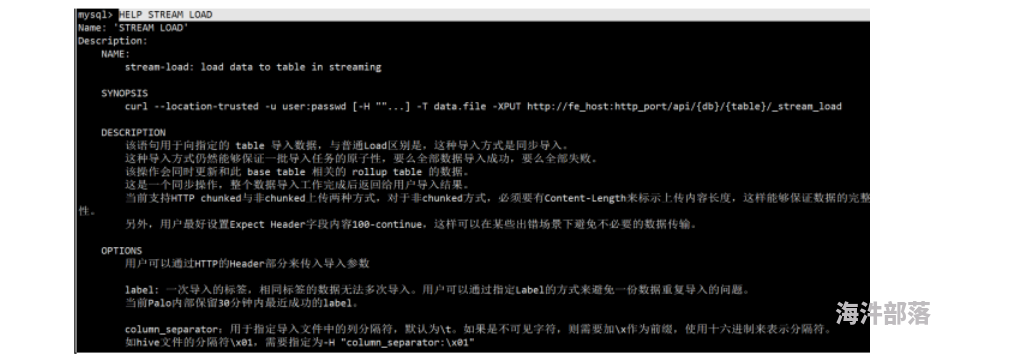
2.Stream Load
Stream Load是一个同步的导入方式,用户通过发送HTTP协议将本地文件或数据流导入到Doris中,Stream load同步执行导入并返回结果。用户可以直接通过返回判断导入是否成功。
#具体帮助使用HELP STREAM LOAD 查看
(1)创建csv文件
(2)将csv上传到集群

(3)通过命令将csv数据导入到doris,-H指定参数,column_separator指定分割符,-T指定数据源文件。
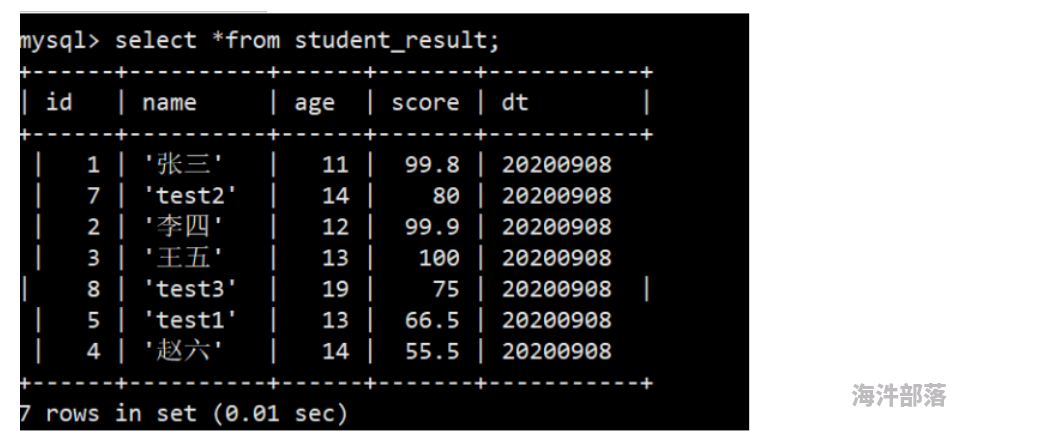
root@doris1:/opt# curl --location-trusted -u root -H "label:123" -H"column_separator:," -T 1.csv -X PUT http://doris1:8030/api/test_db/student_result/_stream_load(4)查看对应表,导入成功
3.Routine Load
例行导入功能为用户提供了一种自动从指定数据源进行数据导入的功能。
当前仅支持Kafka系统进行例行导入。
使用限制:
1.支持无认证的Kafka访问,以及通过SSL方式认证的Kafka集群
2.仅支持kafka0.10.0.0 及以上版本先安装好zookeeper和kafka,创建topic,并往topic里灌一批数据
root@doris1:~# /opt/module/kafka_2.11-2.4.0/bin/kafka-topics.sh --zookeeper doris1:2181/kafka_2.4 --create --replication-factor 2 --partitions 3 --topic test(1)编写java生产者代码,王test topic灌一批测试数据
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
public class TestProducer {
public static void main(String[] args) {
Properties props = new Properties();
props.put("bootstrap.servers", "doris1:9092,doris2:9092,doris3:9092");
props.put("acks", "-1");
props.put("batch.size", "16384");
props.put("linger.ms", "10");
props.put("buffer.memory", "33554432");
props.put("key.serializer",
"org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer",
"org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(props);
for (int i = 0; i < 100000; i++) {
producer.send(new ProducerRecord<String,String>("test2",i+"\tname"+i+"\t18"));
}
producer.flush();
producer.close();
}
}(2)在doris中创建对应表
create table student_kafka
(
id int,
name varchar(50),
age int
)
DUPLICATE KEY(id)
DISTRIBUTED BY HASH(id) BUCKETS 10;(3)创建导入作业,desired_concurrent_number指定并行度
CREATE ROUTINE LOAD test_db.kafka_test ON student_kafka
PROPERTIES
(
"desired_concurrent_number"="3",
"strict_mode" = "false"
)
FROM KAFKA
(
"kafka_broker_list"= "doris1:9092,doris2:9092,doris:9092",
"kafka_topic" = "test2",
"property.group.id"="test_group_2",
"property.kafka_default_offsets" = "OFFSET_BEGINNING",
"property.enable.auto.commit"="false"
);(4)创建完作业导入作业后查询doris
4.4动态分区
动态分区是在Doris0.12版本加入的功能。旨在对表级别的分区实现生命周期管理(TTL),减少用户的使用负担。
目前实现了动态添加分区及动态删除分区的功能
原理:
在某些场景下,用户会将表按照天进行分区划分,每天定时执行例行任务,这时需要使用方手动管理分区,否则可能由于使用方没有创建数据导致失败这给使用方带来额外的维护成本。
在实现方式上,FE会启动一个后台子线程,根据fe.conf中dynamic_partition_enable及dynamic_partition_check_interval_seconds参数决定线程是否启动以及该线程的调度频率。每次调度时,会在注册表中读取动态分区表的属性。(1)参数
| dynamic_partition.enable | 是否开启动态分区特性,可指定true或false,默认为true |
|---|---|
| dynamic_partition.time_unit | 动态分区调度的单位,可指定day,week,month。当指定day时格式为yyyyMMDD。当指定week时格式为yyyy_ww,表示属于这一年的第几周。当指定为month时,格式为yyyyMM |
| dynamic_partition.start | 动态分区的开始时间,以当天为准,超过该时间范围的分区将会被删除,如果不填写默认值为Interger.Min_VALUE 即-2147483648 |
| dynamic_partition.end | 动态分区的结束时间,以当天为基准,会提前创建N个单位的分区范围 |
| dynamic_partition.prefix | 动态创建的分区名前缀 |
| dynamic_partition.buckets | 动态创建的分区所对应分桶数量 |
(2)使用
(1)开启动态分区功能,可以在fe.conf中设置dynamic_partition_enable=true,也可以使用命令进行修改。使用命令进行修改,并dynamic_partition_check_interval_seconds调度时间设置为5秒,意思就是每过5秒根据配置刷新分区。我这里做测试设置为5秒,真实场景可以设置为12小时。
root@doris1:/opt/module# curl --location-trusted -u root:123456 -XGET http://doris1:8030/api/_set_config?dynamic_partition_enable=true
root@doris1:/opt/module# curl --location-trusted -u root:123456 -XGET http://doris1:8030/api/_set_config?dynamic_partition_check_interval_seconds=5
mysql> ADMIN SET FRONTEND CONFIG ("dynamic_partition_enable" = "true");
mysql> ADMIN SET FRONTEND CONFIG ("dynamic_partition_check_interval_seconds"="5");(2)创建一张调度单位为天,不删除历史分区的动态分区表
create table student_dynamic_partition1
(id int,
time date,
name varchar(50),
age int
)
duplicate key(id,time)
PARTITION BY RANGE(time)()
DISTRIBUTED BY HASH(id) buckets 10
PROPERTIES(
"dynamic_partition.enable" = "true",
"dynamic_partition.time_unit" = "DAY",
"dynamic_partition.end" = "3",
"dynamic_partition.prefix" = "p",
"dynamic_partition.buckets" = "10",
"replication_num" = "1"
);(3)查看分区表情况SHOW DYNAMIC PARTITION TABLES,更新最后调度时间

(4)插入测试数据,可以全部成功
mysql> insert into student_dynamic_partition1 values(1,'2020-09-10 11:00:00','name1',18);
mysql> insert into student_dynamic_partition1 values(1,'2020-09-11 11:00:00','name1',18);
mysql> insert into student_dynamic_partition1 values(1,'2020-09-12 11:00:00','name1',18);(5)使用命令查看表下的所有分区show partitions from student_dynamic_partition1;
4.5数据导出
数据导出是Doris提供的一种将数据导出的功能。该功能可以将用户指定的表或分区的数据以文本的格式,通过Broker进程导出到远端存储上,如HDFS/BOS等。
(1)启动hadoop集群
(2)执行导出计划
export table student_dynamic_partition1
partition(p20200910,p20200911,p20200912,p20200913)
to "hdfs://mycluster/user/atguigu"
WITH BROKER "broker_name"
(
"dfs.nameservices"="mycluster",
"dfs.ha.namenodes.mycluster"="nn1,nn2,nn3",
"dfs.namenode.rpc-address.mycluster.nn1"= "hadoop101:8020",
"dfs.namenode.rpc-address.mycluster.nn2"= "hadoop102:8020",
"dfs.namenode.rpc-address.mycluster.nn3"="hadoop103:8020",
"dfs.client.failover.proxy.provider.mycluster"="org.apache.hadoop.hdfs.server.namenode.ha.Conf iguredFailoverProxyProvider"
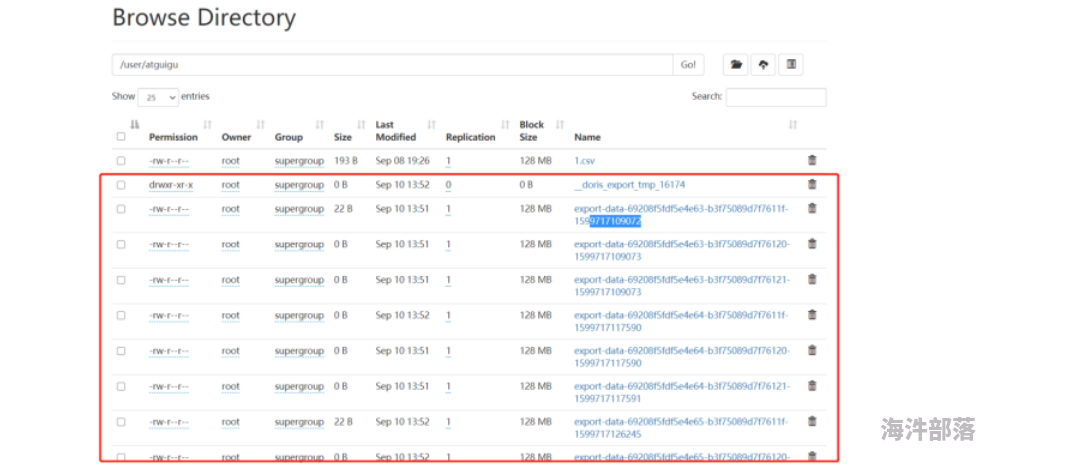
);(3)导出之后查看hdfs对应路径,会多出许多文件
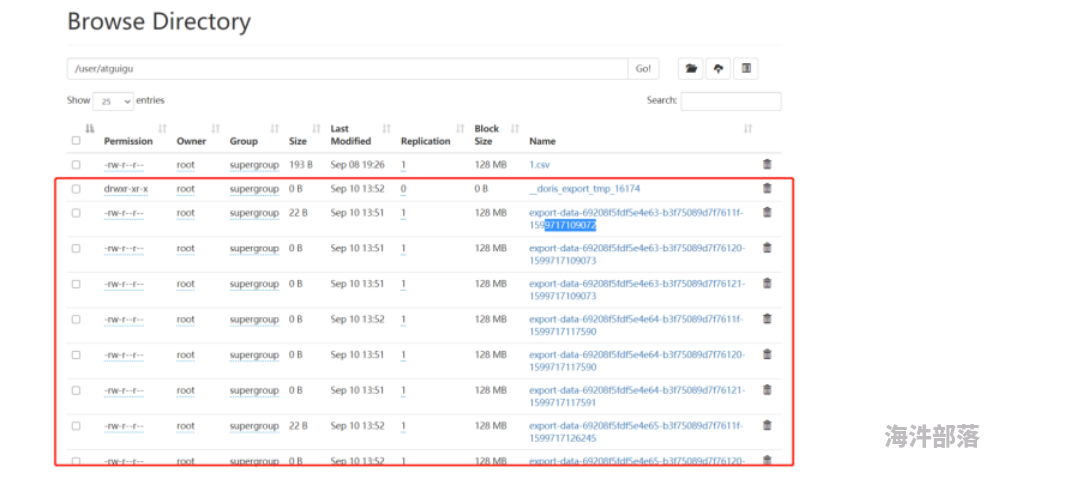
(4)使用命令查看有数据的文件内容,就是简单的文本内容
[root@hadoop101 apache-hive-3.1.2-bin]# hadoop dfs -cat /user/atguigu/export-data-69208f5fdf5e4e63-b3f75089d7f7611f-1599717109072![Uploading file...]()
4.6 SQL函数
(1)查看函数名
mysql> show builtin functions in test_db;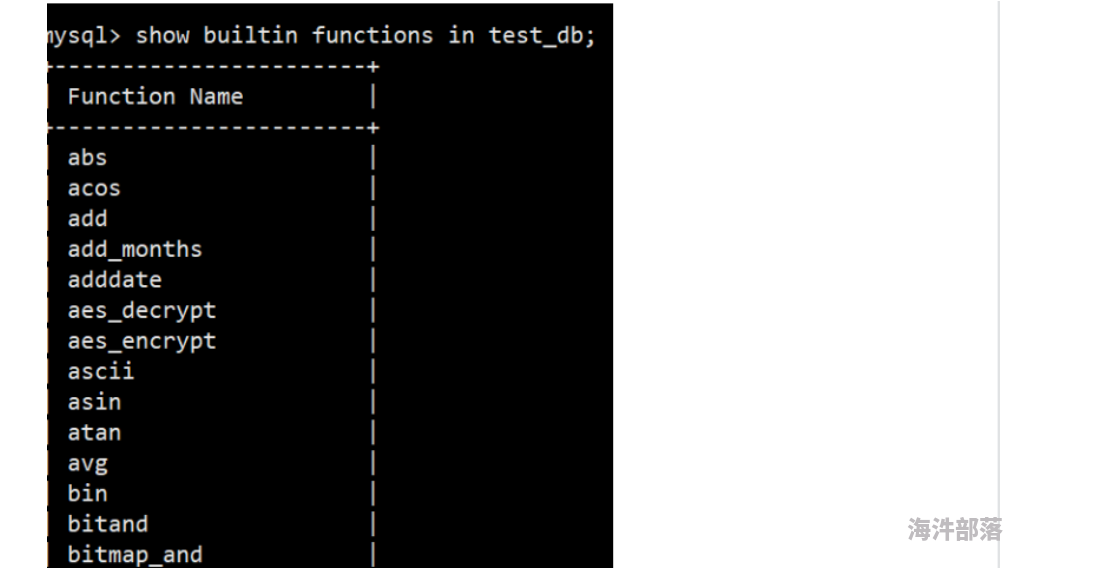
(2)查看函数具体信息,比如查看year函数具体信息
mysql> show full builtin functions in test_db like 'year';![Uploading file...]()
(3)官网地址
4.7代码操作
<!-- 声明构建信息 -->
<build>
<plugins>
<!-- 该插件用于将Scala代码编译成class文件 -->
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>4.4.0</version>
<executions>
<execution>
<!-- 声明绑定到maven的compile阶段 -->
<goals>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.0.0</version>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build><dependencies>
<!-- Spark的依赖引入 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.4.5</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.4.5</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.11</artifactId>
<version>2.4.5</version>
</dependency>
<!-- 引入Scala -->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.11.8</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.47</version>
</dependency>
<!-- https://mvnrepository.com/artifact/mysql/mysql-connector-java -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.46</version>
</dependency>
</dependencies>1.读取表数据
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
object TestReadDoris {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setAppName("testReadDoris").setMaster("local[*]")
val sparkSession = SparkSession.builder().config(sparkConf).getOrCreate()
val df=sparkSession.read.format("jdbc")
.option("url","jdbc:mysql://doris1:9030/test_db")
.option("user","root")
.option("password","123456")
.option("dbtable","student_dynamic_partition1")
.load()
df.show()
}
}2.写数据
import java.util.Properties
import org.apache.spark.SparkConf
import org.apache.spark.sql.{SaveMode, SparkSession}
object TestWriteDoris {
def main(args: Array[String]): Unit = {
val sparkConf = new SparkConf().setAppName("testWirteDoris").setMaster("local[*]")
val sparkSession = SparkSession.builder().config(sparkConf).getOrCreate()
val df = sparkSession.createDataFrame(Array((1, "2020-09-13", "testName1", 18), (1, "2020-09-13", "testName2", 18), (1, "2020-09-13", "testName3", 18)))
.toDF("id", "time", "name", "age")
val prop = new Properties()
prop.setProperty("user", "root")
prop.setProperty("password", "123456")
df.write.mode(SaveMode.Append).jdbc("jdbc:mysql://doris1:9030/test_db", "student_dynamic_partition1", prop)
}
}4.8 Colocation Join
Colocation Join是在Doris0.9版本引入的功能,旨在为Join查询提供本性优化,来减少数据在节点上的传输耗时,加速查询。
原理:
Colocation Join功能,是将一组拥有CGS 的表组成一个CG。保证这些表对应的数据分片会落在同一个be节点上,那么使得两表再进行join的时候,可以通过本地数据进行直接join,减少数据在节点之间的网络传输时间。
使用限制:
(1)建表时两张表的分桶列和数量需要完全一致,并且桶的个数也需要一致。
(2)副本数,两张表的所有分区的副本数需要一致
(1)使用,建两张表,分桶列都为int类型,且桶的个数都是8个。两张表的副本数都为默认副本数。
CREATE TABLE `tbl1` (
`k1` date NOT NULL COMMENT "",
`k2` int(11) NOT NULL COMMENT "",
`v1` int(11) SUM NOT NULL COMMENT ""
) ENGINE=OLAP
AGGREGATE KEY(`k1`, `k2`)
PARTITION BY RANGE(`k1`)
(
PARTITION p1 VALUES LESS THAN ('2019-05-31'),
PARTITION p2 VALUES LESS THAN ('2019-06-30')
)
DISTRIBUTED BY HASH(`k2`) BUCKETS 8
PROPERTIES (
"colocate_with" = "group1"
);
------
CREATE TABLE `tbl2` (
`k1` datetime NOT NULL COMMENT "",
`k2` int(11) NOT NULL COMMENT "",
`v1` double SUM NOT NULL COMMENT ""
) ENGINE=OLAP
AGGREGATE KEY(`k1`, `k2`)
DISTRIBUTED BY HASH(`k2`) BUCKETS 8
PROPERTIES (
"colocate_with" = "group1"
);(2)编写查询语句,并查看执行计划,HASH JOIN处colocate 显示为true,代表优化成功。
mysql> explain SELECT * FROM tbl1 INNER JOIN tbl2 ON (tbl1.k2 = tbl2.k2);5.监控和报警
Doris可以使用Prometheus和Granfana进行监控和采集。
Doris的监控数据通过FE和BE的http接口向外暴露。监控数据以key-value的文本形式对外展现。每个key还可能有不同的Label加以区分。当用户搭建好Doris后,可以在浏览器,通过以下接口访问监控数据
Frontend: fe_host:fe_http_port/metrics
Backend: be_host:be_web_server_port/metrics

