json 转csv 可解放大量的ETL工作,但带数组的json需要特别处理,我使用的亚马逊redshift时已经解决了基本所有的json数据类型预处理,我是通过通用配置表配合json预处理框架实现的.这里不多介绍,只讲一下如果将一堆json数据转为csv数据,如下是只需给定json的jsonpath结构,即可读入json 流出 csv
测试使用的是最多143个key的json数据,数据大小约13540行,jsonpath如下
{
"jsonpaths": [
"$.external_date",
"$.external_time",
"$._id",
"$.uid",
"$.nickname",
"$.box_id",
"$.platform",
"$.coin",
"$.award.realCoin",
"$.award.realIosCoin",
"$.award.id",
"$.award.coin",
"$.award.iosCoin",
"$.award.price",
"$.award.iosPrice",
"$.award.displayPrice",
"$.award.iosDisplayPrice",
"$.award.iosPayId",
"$.award.hide",
"$.award.iosHide",
"$.award_items_1.num",
"$.award_items_1.id",
"$.award_items_1.type",
"$.award_items_1.unit",
"$.award_items_1.coin",
"$.award_items_1.title",
"$.award_items_2.num",
"$.award_items_2.id",
"$.award_items_2.type",
"$.award_items_2.unit",
"$.award_items_2.coin",
"$.award_items_2.title",
"$.award_items_3.num",
"$.award_items_3.id",
"$.award_items_3.type",
"$.award_items_3.unit",
"$.award_items_3.coin",
"$.award_items_3.title",
"$.award_items_4.num",
"$.award_items_4.id",
"$.award_items_4.type",
"$.award_items_4.unit",
"$.award_items_4.coin",
"$.award_items_4.title",
"$.award_items_5.num",
"$.award_items_5.id",
"$.award_items_5.type",
"$.award_items_5.unit",
"$.award_items_5.coin",
"$.award_items_5.title",
"$.award_items_6.num",
"$.award_items_6.id",
"$.award_items_6.type",
"$.award_items_6.unit",
"$.award_items_6.coin",
"$.award_items_6.title",
"$.award_items_7.num",
"$.award_items_7.id",
"$.award_items_7.type",
"$.award_items_7.unit",
"$.award_items_7.coin",
"$.award_items_7.title",
"$.award_items_8.num",
"$.award_items_8.id",
"$.award_items_8.type",
"$.award_items_8.unit",
"$.award_items_8.coin",
"$.award_items_8.title",
"$.award_items_9.num",
"$.award_items_9.id",
"$.award_items_9.type",
"$.award_items_9.unit",
"$.award_items_9.coin",
"$.award_items_9.title",
"$.award_items_10.num",
"$.award_items_10.id",
"$.award_items_10.type",
"$.award_items_10.unit",
"$.award_items_10.coin",
"$.award_items_10.title",
"$.award_items_11.num",
"$.award_items_11.id",
"$.award_items_11.type",
"$.award_items_11.unit",
"$.award_items_11.coin",
"$.award_items_11.title",
"$.award_items_12.num",
"$.award_items_12.id",
"$.award_items_12.type",
"$.award_items_12.unit",
"$.award_items_12.coin",
"$.award_items_12.title",
"$.award_items_13.num",
"$.award_items_13.id",
"$.award_items_13.type",
"$.award_items_13.unit",
"$.award_items_13.coin",
"$.award_items_13.title",
"$.award_items_14.num",
"$.award_items_14.id",
"$.award_items_14.type",
"$.award_items_14.unit",
"$.award_items_14.coin",
"$.award_items_14.title",
"$.award_items_15.num",
"$.award_items_15.id",
"$.award_items_15.type",
"$.award_items_15.unit",
"$.award_items_15.coin",
"$.award_items_15.title",
"$.award_items_16.num",
"$.award_items_16.id",
"$.award_items_16.type",
"$.award_items_16.unit",
"$.award_items_16.coin",
"$.award_items_16.title",
"$.award_items_17.num",
"$.award_items_17.id",
"$.award_items_17.type",
"$.award_items_17.unit",
"$.award_items_17.coin",
"$.award_items_17.title",
"$.award_items_18.num",
"$.award_items_18.id",
"$.award_items_18.type",
"$.award_items_18.unit",
"$.award_items_18.coin",
"$.award_items_18.title",
"$.award_items_19.num",
"$.award_items_19.id",
"$.award_items_19.type",
"$.award_items_19.unit",
"$.award_items_19.coin",
"$.award_items_19.title",
"$.award_items_20.num",
"$.award_items_20.id",
"$.award_items_20.type",
"$.award_items_20.unit",
"$.award_items_20.coin",
"$.award_items_20.title",
"$.date",
"$.timestamp",
"$.created_at.$date"
]
}第一种方式是使用 python的第三方库jsonpath 进行解析并写入:代码如下:
# encoding:utf-8
import io
import json
import arrow
import os
from jsonpath import jsonpath
BUFF_SIZE = 3000
BUFF_LIST = []
# 将list数据写入本地
def batch_to_local(batch_list, local_obs_path):
with open(local_obs_path, "a", encoding='utf-8') as f:
# 批量序列化
f.write('\n'.join(batch_list))
f.write('\n')
def jsonToCsv(jsonpathPath, jsonDataPath, oPath, sep=','):
global BUFF_LIST
jpDictArr = json.loads(io.open(jsonpathPath, "r", encoding='UTF-8').read())['jsonpaths']
# 判断文件是否存在
dir_path = oPath[:oPath.rindex('/')]
if not os.path.exists(dir_path):
print("create directory...")
os.makedirs(dir_path)
# 写入本地如果文件存在 则删除
if os.path.exists(oPath):
print("file already exists,removed ..")
os.remove(oPath)
print("writing...")
# 获得json数据
for line in io.open(jsonDataPath):
oList = []
for j in jpDictArr:
sV = jsonpath(json.loads(line), expr=j)
# 对号入座
if sV:
oList.append(str(sV[0]).strip(sep))
else:
oList.append('')
# 写入
BUFF_LIST.append(sep.join(oList))
if len(BUFF_LIST) == BUFF_SIZE:
batch_to_local(BUFF_LIST, oPath)
BUFF_LIST = []
if len(BUFF_LIST) > 0:
batch_to_local(BUFF_LIST, oPath)
BUFF_LIST = []
if __name__ == '__main__':
sT = arrow.now().timestamp
jsonToCsv('user_charge_box_log_jsonpath.json', '2021-08-14', 'D:/leeston/leeston/ML-BigData/JSON/jsonToCsv.csv')
print('cost : {} seconds !!'.format(arrow.now().timestamp - sT))本地测试转换耗时: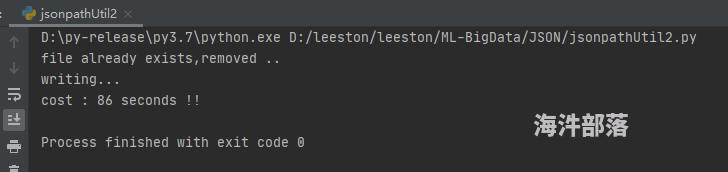
第二种,手写实现jsonpath解析json数据:
# encoding:utf-8
import io
import json
import arrow
import os
BUFF_SIZE = 3000
BUFF_LIST = []
# 将list数据写入本地
def batch_to_local(batch_list, local_obs_path):
with open(local_obs_path, "a", encoding='utf-8') as f:
# 批量序列化
f.write('\n'.join(batch_list))
f.write('\n')
# 递归实现jsonpath 解析
def getDtaByKeyPath(keyStr, jsonDict, kLen=0):
kL = keyStr.strip('.').split('.')
if kLen < len(kL):
if kL[kLen] in jsonDict:
return getDtaByKeyPath(keyStr, jsonDict[kL[kLen]], kLen + 1)
if kLen == 0:
return {}
else:
return jsonDict
def jsonToCsv(jsonpathPath, jsonDataPath, oPath, sep=','):
global BUFF_LIST
jpDictArr = json.loads(io.open(jsonpathPath, "r", encoding='UTF-8').read())['jsonpaths']
# 判断文件是否存在
dir_path = oPath[:oPath.rindex('/')]
if not os.path.exists(dir_path):
print("create directory...")
os.makedirs(dir_path)
# 写入本地如果文件存在 则删除
if os.path.exists(oPath):
print("file already exists,removed ..")
os.remove(oPath)
print("writing...")
# 获得json数据
for line in io.open(jsonDataPath):
oList = []
for j in jpDictArr:
sV = getDtaByKeyPath(j.strip('.$'), json.loads(line.strip('\n')))
# 对号入座
if sV == {}:
oList.append('')
else:
oList.append(str(sV).strip(sep))
# 写入
BUFF_LIST.append(sep.join(oList))
if len(BUFF_LIST) == BUFF_SIZE:
batch_to_local(BUFF_LIST, oPath)
BUFF_LIST = []
if len(BUFF_LIST) > 0:
batch_to_local(BUFF_LIST, oPath)
BUFF_LIST = []
if __name__ == '__main__':
sT = arrow.now().timestamp
jsonToCsv('user_charge_box_log_jsonpath.json', '2021-08-14', 'D:/leeston/leeston/ML-BigData/JSON/jsonToCsv2.csv')
print('cost : {} seconds !!'.format(arrow.now().timestamp - sT))转换耗时: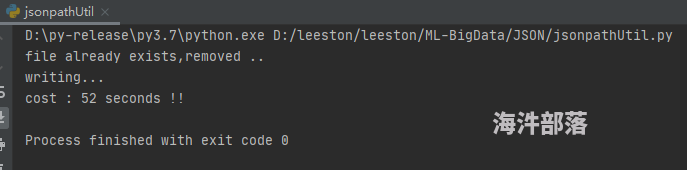
原始json: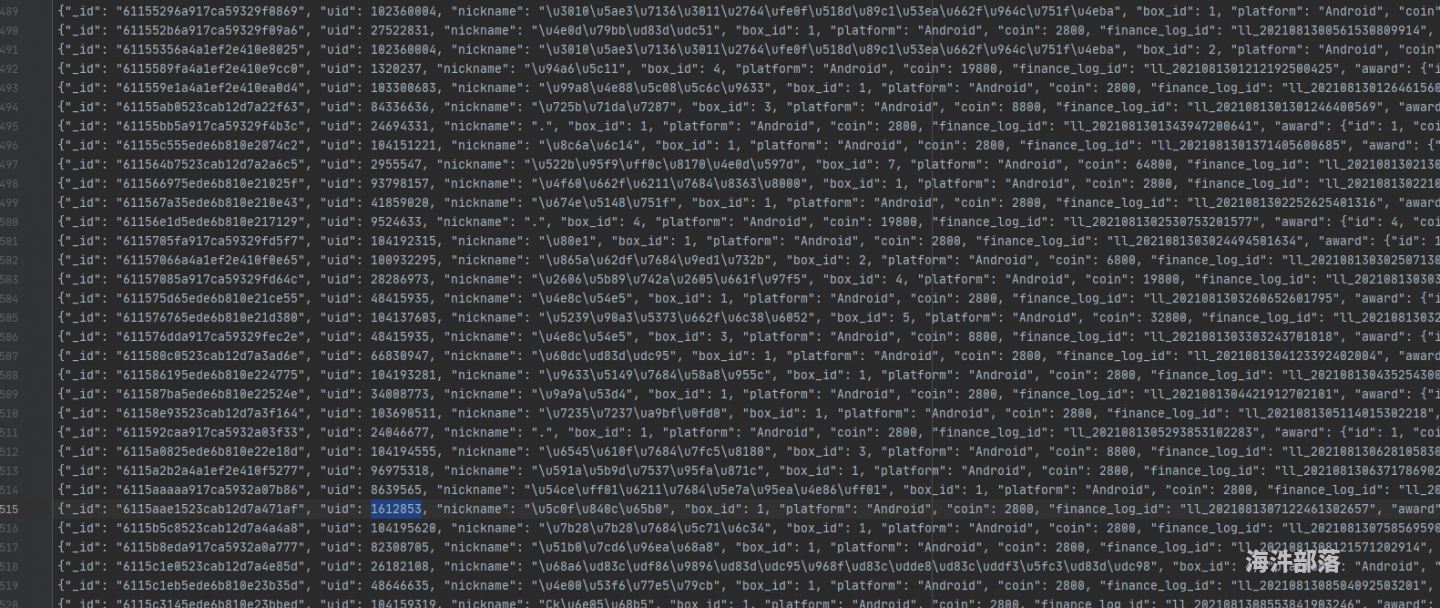
转换为csv后:
由上诉可见,手写实现效率明显高于第三方API
我用的数仓是 亚马逊的REDSHIFT ,支持通过jsonpath直接copy数据到RDB,最近考虑使用华为高斯db ,但与其销售人员沟通中发现他们竟然不支持json格式直接入库!我的数仓400张表全部是json格式直接入库的,这点让我很难接受,如果不支持jsonpath 就意味着每张表都要写代码处理,这样的繁琐的ETL过程跟流水线上的工人有何区别,在我看来,所有的ETL工作都能通过配置简单的配置用统一框架处理,因此,我觉得json转csv的过程还是很有必要的,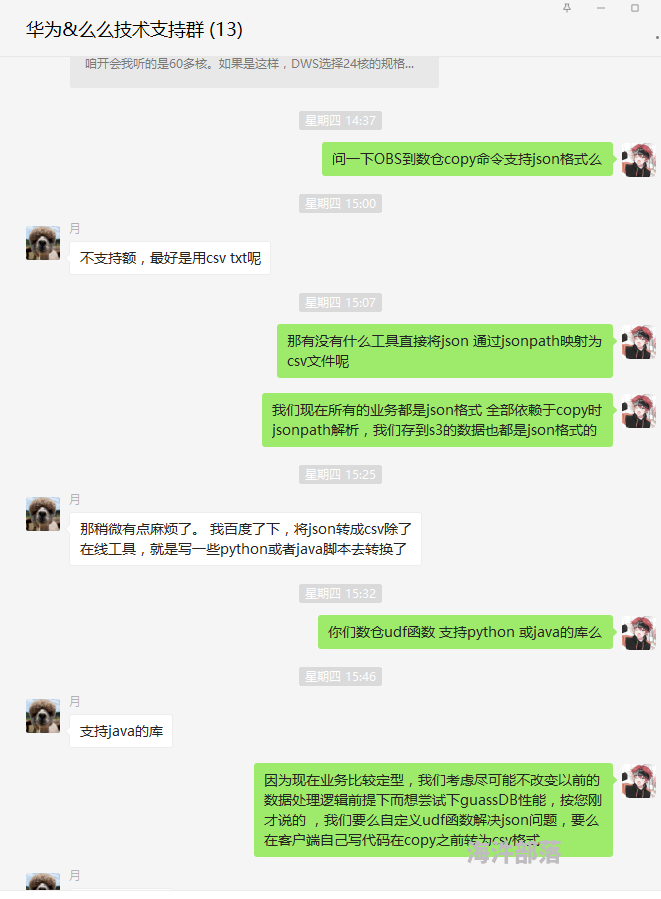
如何快速获取一个json表的jsonpath呢?代码如下
from __future__ import print_function
import json
def dict_generator(indict, pre=None):
pre = pre[:] if pre else []
if isinstance(indict, dict):
for key, value in indict.items():
if isinstance(value, dict):
if len(value) == 0:
yield pre + [key, '{}']
else:
for d in dict_generator(value, pre + [key]):
yield d
elif isinstance(value, list):
if len(value) == 0:
yield pre + [key, '[]']
else:
for v in value:
for d in dict_generator(v, pre + [key]):
yield d
elif isinstance(value, tuple):
if len(value) == 0:
yield pre + [key, '()']
else:
for v in value:
for d in dict_generator(v, pre + [key]):
yield d
else:
yield pre + [key, value]
else:
yield indict
def jsonpath(sValue, res=''):
for i in dict_generator(sValue):
key = '.'.join(i[0:-1])
line = ' ' + '"$.' + key + '",'
res += line
path = res.replace(',', ',\n')[0:-2]
jsonpath = '''{
"jsonpaths": [
''' + path + '''
]
}
'''
print(jsonpath)
# 递归计算varchar值
def get_varchar_size(l_str, step=1):
l_len = len(l_str.encode('utf-8'))
if 128 > l_len:
return 128
elif 128 <= l_len <= 65535:
if 2 ** step > l_len:
return 2 ** step
if 2 ** step == l_len and 2 ** (step + 1) <= 65535:
return 2 ** (step + 1)
if 2 ** step < l_len:
return get_varchar_size(l_str, step + 1)
else:
raise Exception('超出最大值!')
def create_table(sValue, table_name, is_written=True, res=''):
for i in dict_generator(sValue):
key = '.'.join(i[0:-1])
v = i[len(i) - 1]
old_column = key.split('.')
# print(sValue[key])
if len(old_column) >= 2:
# column = (old_column[-2] + '_' + old_column[-1]).replace('$', '')
column = '_'.join(old_column).replace('$', '')
if column == '_id_oid':
column = '_id'
if column == 'created_at_date':
column = 'created_at'
# 打散后的长度只有1时直接替换 $
else:
column = key.split('.')[-1].replace('$', '')
# 先给个默认的大小
new_column = column + ' ' + 'varchar(128)' + ','
# varchar 类型重新计算,链接给出256
if type(v) == str:
if str(v).lower().__contains__('.jpg') or str(v).lower().__contains__('.png'):
new_column = column + ' ' + 'varchar(256)' + ','
else:
new_column = column + ' ' + 'varchar({})'.format(get_varchar_size(v)) + ','
if type(v) == int:
if v >= 1000000000 or v <= -1000000000:
new_column = column + ' ' + 'bigint' + ','
else:
new_column = column + ' ' + 'integer' + ','
if type(v) == float:
new_column = column + ' ' + 'float' + ','
if type(v) == bool:
new_column = column + ' ' + 'boolean' + ','
if column == 'external_date':
new_column = column + ' ' + 'varchar(16)' + ','
if column == 'external_time' or column == 'created_at':
new_column = column + ' ' + 'varchar(32)' + ','
if column in ('user_id', 'room_id', 'star_id', 'uid', 'broker_id', 'host_id', 'invite_id'):
new_column = column + ' ' + 'integer' + ','
res += new_column
# 对res操作
# pre = 'pre_buffer|'
# pre_date_time = 'external_time varchar(32),external_date varchar(16),'
# res = pre + res
# res = res.replace(pre_date_time, '').replace(pre, 'external_date varchar(16),external_time varchar(32),')
columns = res.replace(',', ',\n')[0:-2]
table_sql = '''
DROP TABLE IF EXISTS {table_name} CASCADE;
CREATE TABLE {table_name}
(
{columns}
) diststyle even;
GRANT ALL ON {table_name} TO group data_write;
GRANT SELECT ON {table_name} TO group data_read;
'''
table_sql = table_sql.format(columns=columns, table_name=table_name)
print(table_sql)
# if is_written:
# with open(file_par_path + '\\{table_name}_sql.txt'.format(table_name=table_name),
# 'w') as f:
# f.write(table_sql)
# return table_sql
def comment_table(sValue, table_name):
res = "COMMENT ON TABLE %s IS '一一';" % table_name
for i in dict_generator(sValue):
key = '.'.join(i[0:-1])
old_clomn = key.split('.')
if len(old_clomn) >= 2:
clomn = (old_clomn[-2] + '_' + old_clomn[-1]).replace('$', '')
else:
clomn = key.split('.')[-1].replace('$', '')
comment = 'COMMENT ON COLUMN %s.' % table_name + clomn + " IS '一一一';"
res += comment
comments = res.replace(';', ';\n')[0:-1]
print(comments)
jsonStr = '''
{
"_id" : "99889550_69443035",
"check_point" : 1628524800000,
"counts" : {
"STAR" : 1
},
"created_at" : 1625915379264,
"expire_at" : 1628438400000,
"levels" : {
"STAR" : {
"level" : 1,
"remain" : -1,
"expire_at" : 1628438400000
}
},
"star" : 99889550,
"start" : 1625846400000,
"timestamp" : 1625915379264,
"uid" : 69443035,
"totals" : {
"STAR" : 1
}
}
def getJsonpathAndCreateTable(tbname):
sValue = json.loads(jsonStr)
# 生成jsonpath
print('---' * 40)
jsonpath(sValue)
print('---' * 40)
# 生成建表语句
create_table(sValue, tbname)
print('---' * 40)
# 生成表备注信息
comment_table(sValue, tbname)
print('---' * 40)
if __name__ == "__main__":
table_name = 'bd_test.leaveroom_es'
getJsonpathAndCreateTable(table_name)上诉代码代码不但给出了获得jsonpath的方式,还给出了jsonpath对应的数据库表的建表语句
问题一: 如果我的mongoDB json中带有很多数组 怎么处理呢?类似如下一条数据
{
"_id": "6116978aa4a1ef2e4114b603",
"user_id": 68929288,
"nick_name": "打鱼打到死",
"room_id": 2912313,
"game_name": "open_egg",
"prop_id": 3,
"prop_name": "金锤子",
"prop_num": 10,
"prop_cost_coin": 500,
"prop_cost_coin_original": 500,
"ran_type": 0,
"ran": {
"gifts": [{
"giftType": "bag",
"giftName": "黄金麦克风",
"giftId": 591,
"giftNum": 1,
"giftPicUrl": "https://img.sumeme.com/58/2/1537252271290.jpg",
"giftCoinPrice": 20,
"beginRate": 0,
"endRate": 6350,
"rewardCoin": false,
"currRadio": 0,
"nextRadio": 0,
"neadBegin": false
},
{
"giftType": "bag",
"giftName": "守护之心",
"giftId": 938,
"giftNum": 1,
"giftPicUrl": "https://img.sumeme.com/17/1/1597321030225.png",
"giftCoinPrice": 500,
"beginRate": 6350,
"endRate": 9600,
"rewardCoin": false,
"currRadio": 0,
"nextRadio": 0,
"neadBegin": false
},
{
"giftType": "bag",
"giftName": "为爱打CALL",
"giftId": 934,
"giftNum": 1,
"giftPicUrl": "https://img.sumeme.com/10/2/1597320560842.png",
"giftCoinPrice": 2000,
"beginRate": 9600,
"endRate": 9785,
"rewardCoin": false,
"currRadio": 0,
"nextRadio": 0,
"neadBegin": false
},
{
"giftType": "bag",
"giftName": "love",
"giftId": 939,
"giftNum": 1,
"giftPicUrl": "https://img.sumeme.com/58/2/1597321299386.png",
"giftCoinPrice": 5000,
"beginRate": 9785,
"endRate": 9935,
"rewardCoin": false,
"currRadio": 0,
"nextRadio": 0,
"neadBegin": false
}
]
},
"gifts": [{
"giftType": "bag",
"giftName": "守护之心",
"giftId": 938,
"giftNum": 6,
"giftPicUrl": "https://img.sumeme.com/17/1/1597321030225.png",
"giftCoinPrice": 500,
"beginRate": 6350,
"endRate": 9600,
"rewardCoin": false,
"currRadio": 0,
"nextRadio": 0,
"neadBegin": false
},
{
"giftType": "bag",
"giftName": "黄金麦克风",
"giftId": 591,
"giftNum": 4,
"giftPicUrl": "https://img.sumeme.com/58/2/1537252271290.jpg",
"giftCoinPrice": 20,
"beginRate": 0,
"endRate": 6350,
"rewardCoin": false,
"currRadio": 0,
"nextRadio": 0,
"neadBegin": false
}
],
"reason": "",
"trade_id": "68929288_1628870538974",
"timestamp": 1628870538976
}答: 此时我们就考虑每一个带json数组的key ,将这个json先进行预处理,转为不带数组的json,可以将其转为一行json
或者将其转为多行json,这些转换方法 早已被我写入了通用框架处理,只需要简单的配置即可,json预处理转换后的结果大致如下:
{
"_id": {
"$oid": "611696e65ede6b810e352ac3"
},
"user_id": 29569297,
"nick_name": "\u767d\u5ad6\u8bd7\u8bd7\u306e\u5c0f\u4e09\u90ce",
"room_id": 69562193,
"game_name": "open_egg",
"prop_id": 1,
"prop_name": "\u94dc\u9524\u5b50",
"prop_num": 10,
"prop_cost_coin": 100,
"prop_cost_coin_original": 100,
"ran_type": 0,
"ran": {},
"reason": "",
"trade_id": "29569297_1628870374522",
"timestamp": 1628870374523,
"external_time": "2021-08-13 23:59:34",
"external_date": "2021-08-13",
"ran_gifts_1": {
"giftType": "bag",
"giftName": "\u73ab\u7470",
"giftId": 6,
"giftNum": 1,
"giftPicUrl": "https://img.sumeme.com/18/2/1537434791634.jpg",
"giftCoinPrice": 10,
"beginRate": 0,
"endRate": 6000,
"rewardCoin": false,
"currRadio": 0,
"nextRadio": 0,
"neadBegin": false
},
"ran_gifts_2": {
"giftType": "bag",
"giftName": "\u597d\u559c\u6b22\u4f60",
"giftId": 995,
"giftNum": 1,
"giftPicUrl": "https://img.sumeme.com/5/5/1548215050437.jpg",
"giftCoinPrice": 100,
"beginRate": 6000,
"endRate": 9340,
"rewardCoin": false,
"currRadio": 0,
"nextRadio": 0,
"neadBegin": false
},
"ran_gifts_3": {
"giftType": "bag",
"giftName": "\u5b88\u62a4\u4e4b\u5fc3",
"giftId": 938,
"giftNum": 1,
"giftPicUrl": "https://img.sumeme.com/17/1/1597321030225.png",
"giftCoinPrice": 500,
"beginRate": 9340,
"endRate": 9915,
"rewardCoin": false,
"currRadio": 0,
"nextRadio": 0,
"neadBegin": false
},
"ran_gifts_4": {
"giftType": "bag",
"giftName": "\u4e3a\u7231\u6253CALL",
"giftId": 934,
"giftNum": 1,
"giftPicUrl": "https://img.sumeme.com/10/2/1597320560842.png",
"giftCoinPrice": 2000,
"beginRate": 9915,
"endRate": 9970,
"rewardCoin": false,
"currRadio": 0,
"nextRadio": 0,
"neadBegin": false
},
"gifts_1": {
"giftType": "bag",
"giftName": "\u597d\u559c\u6b22\u4f60",
"giftId": 995,
"giftNum": 4,
"giftPicUrl": "https://img.sumeme.com/5/5/1548215050437.jpg",
"giftCoinPrice": 100,
"beginRate": 6000,
"endRate": 9340,
"rewardCoin": false,
"currRadio": 0,
"nextRadio": 0,
"neadBegin": false
},
"gifts_2": {
"giftType": "bag",
"giftName": "\u73ab\u7470",
"giftId": 6,
"giftNum": 6,
"giftPicUrl": "https://img.sumeme.com/18/2/1537434791634.jpg",
"giftCoinPrice": 10,
"beginRate": 0,
"endRate": 6000,
"rewardCoin": false,
"currRadio": 0,
"nextRadio": 0,
"neadBegin": false
}
}上诉是将带数组的json进行预处理,转为一行json,这样就能直接进行csv转换了,对应的表结构大概如下: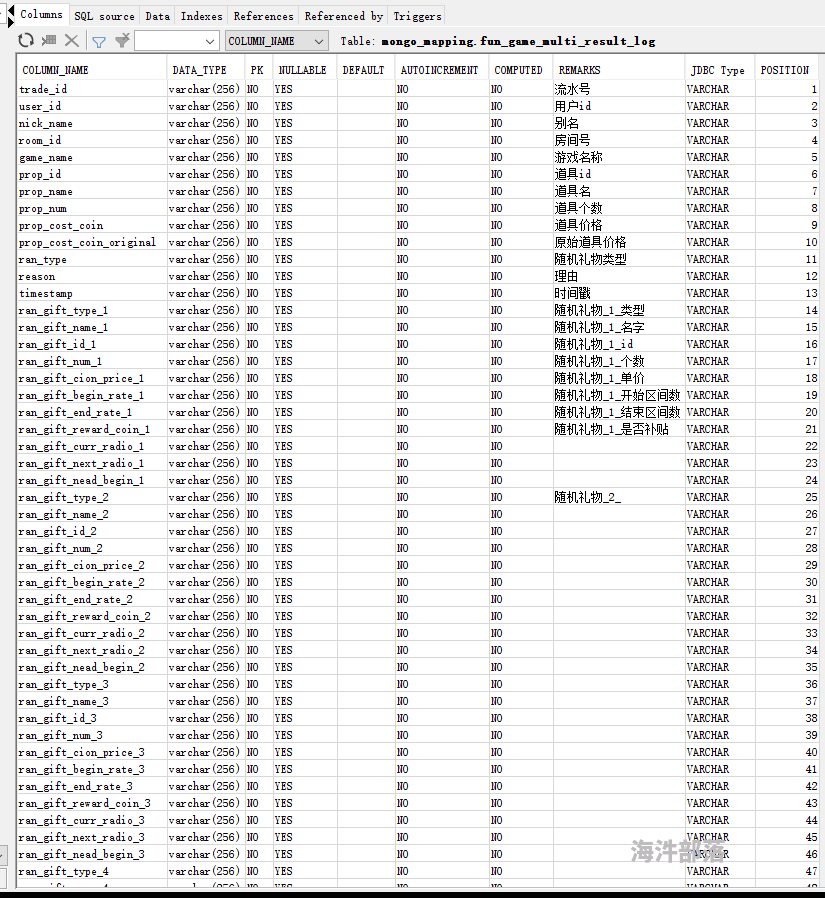
问题二: 上诉一直提到通用处理框架将json进行预处理,转为不带数组的json ,那通用框架到底是什么 怎么进行预处理的呢,其实我用的是redshift,支持copy json数据直接入库,我的通用处理框架不但可以解析带json数组的json,而且还能顺便上传到 AWS S3 (一种亚马逊OBS)并入库,从ODS层json数据到数仓,仅仅需要简单的配置即可,通用处理脚本大致如下(其中一种,这里我仅展示下么么交友数据处理框架):略
由于篇幅有限,代码过长,我就不贴预处理配置框架的代码逻辑了
总结:如果您是一名刚入职场的信任,领导信任您,把后端mongoDB的数据都交给你处理,那您面对一张张麻头皮表,您会优先想到用jsonpath处理么?还是说直接写代码进行遍历、get 硬钢每张表?市面上的json扁平化函数基本都是转多行处理并且面对有多个内嵌关系的json数组处理显得极为鸡肋,不建议盲目使用,实在无法处理的复杂表,可以写代码单独处理较为方便,因此,我们时刻要秉持奥卡姆剃刀原则,将问题最简化才是真正的摸鱼之道。
当然如果这几行代码真的对您有帮助,还是希望您能够优先使用集群资源进行转换,可直接写hadoop-streming,或者mapreduce,如果您能使用spark或者flink更佳,如果您非要在本地进行可以选择用多线程处理,可以让一个线程处理一张mongoDB表,这样效率就会很高,当然前提要确保您的本地盘是SSD.



