- 多线程查找文件脚本: 课输入参数控制线程数,默认为1
#!/usr/bin/env python # -*- coding: utf-8 -*-
import os
import sys
import argparse
import traceback
import threading
from concurrent.futures import ThreadPoolExecutor, as_completed
def listAllFiles(dP, fK):
if os.path.isdir(dP):
files = list(os.listdir(dP))
if len(files) > 0:
for b in files:
listAllFiles(dP + '/' + b, fK)
else:
if dP[dP.rindex('/'):].__contains__(fK):
print('[{}]: --> '.format(threading.current_thread().getName()) + dP)
def submit_one_thread(task_func, *params):
return eval('''threadPool.submit(task_func, {})'''.format("'" + "','".join(list(params))+"'"))
def run():
if search_path and os.path.isdir(search_path):
try:
for da in os.listdir(search_path):
task_list.append(submit_one_thread(listAllFiles, search_path + da, keyword))
if len(task_list) < thread:
print("[WARN] thread num is {} but only {} thread works !".format(thread, len(task_list)))
for _ in as_completed(task_list):
pass
except Exception:
traceback.print_exc()
os.system('python ' + sys.argv[0] + ' -h')
sys.exit(0)
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('-p', '--path', metavar='\b', type=str, default=None,
help='The searching path scale you need input.. eg : /data/')
parser.add_argument('-k', '--keyword', type=str, metavar='\b', default=None,
help='The searching keyword that filename contains in... eg: lee')
parser.add_argument('-t', '--thread', type=int, metavar='\b', default=1,
help='how many thread that you need... eg: lee')
args, _ = parser.parse_known_args()
try:
search_path, keyword, thread, task_list = args.path.replace('\\', '/'), args.keyword, args.thread, []
except Exception:
os.system('python ' + sys.argv[0] + ' -h')
sys.exit(0)
threadPool = ThreadPoolExecutor(max_workers=thread, thread_name_prefix="Thread")
'''
多线程的方式执行文件查找
'''
run()
可以输入三个参数,第一个是要从哪个目录查询,第二个是要查询的文件名关键字,第三个是线程数,默认为1个线程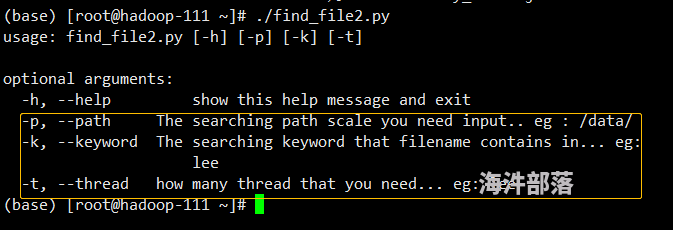
比如我要查询 / 下面带hadoop 的文件,并指定10个线程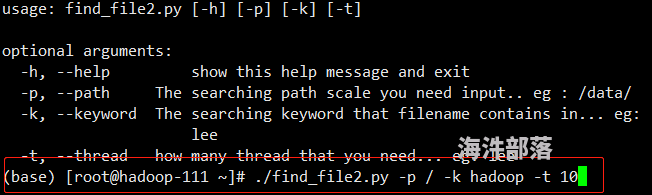
结果如下:
- 第二个脚本,查询当前目录下的文件中,里面包含了什么关键字,返回该文件名:
#!/bin/bash
base_path=$(cd "$(dirname "$0")"; pwd)
res=`ls $base_path`
res2=''
function get_py_location(){
for i in $res;
do
if [ -f "$i" ]; then
res2=`cat $base_path/$i | grep -i "$1"`
if [ '' != "$res2" ]; then
# echo -e "\033[31m 红色字 \033[0m"
echo -e "\n\n\t\033[31m关键词: $1\t脚本位置: $base_path/$i\033[0m\n\n"
echo "$res2"
fi
fi
done
}
if [ $# -eq 0 ]; then
echo "请传入参数:参数是关键词 如 finance_realtime_report"
fi
if [ $# -eq 1 ]; then
get_py_location $1 | grep -v "\.log" | grep -E "\.py|\.groovy|\.java|\.sh" | grep '关键词'
fi
参数只有一个 为内容包含的关键字,效果如下:
补充第二个脚本,python版,功能更强
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import os
import sys
import argparse
import traceback
import threading
import io
from concurrent.futures import ThreadPoolExecutor, as_completed
total_c = 0
def listAllFiles(dP):
if os.path.isdir(dP):
files = list(os.listdir(dP))
if len(files) > 0:
for b in files:
listAllFiles(dP + '/' + b)
else:
global total_c
total_c += 1
if os.stat(dP).st_size < size * 1024 and not str(dP).endswith('jar') and not str(dP).endswith('pyc') \
and not str(dP).endswith('pyo'):
catRes = os.popen(
"cat -n '{path}' | grep '{content}' | awk '{{print $1}}'".format(path=dP, content=content)).read()
if catRes.strip() != '':
print('[{}]: -> find "{}" in ‖ {} ‖ at line: {}'.format(threading.current_thread().getName(),
content, dP,
','.join(catRes.strip().split('\n'))))
def readFile(filePath, contentKey, fileSize):
if os.stat(filePath).st_size < fileSize:
find, counter = False, 1
for row in io.open(filePath):
if str(row).__contains__(contentKey):
find, counter = True, counter
if not find:
counter += 1
return find, counter
def submit_one_thread(task_func, *params):
return eval('''threadPool.submit(task_func, {})'''.format("'" + "','".join(list(params)) + "'"))
def run():
if search_path and os.path.isdir(search_path):
try:
task_list = []
for da in os.listdir(search_path):
task_list.append(submit_one_thread(listAllFiles, str(search_path).rstrip('/') + '/' + da))
if len(task_list) < thread:
print("[WARN] thread num is {} but only {} thread works !".format(thread, len(task_list)))
for _ in as_completed(task_list):
pass
except Exception:
traceback.print_exc()
os.system('python ' + sys.argv[0] + ' -h')
sys.exit(0)
print('search file total: {}'.format(total_c))
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('-p', '--path', metavar='\b', type=str, default=None,
help='The searching path scale you need input.. eg : /data/')
parser.add_argument('-c', '--content', type=str, metavar='\b', default=None,
help='The content that you want find. eg: stars')
parser.add_argument('-t', '--thread', type=int, metavar='\b', default=1,
help='how many thread that you need... eg: 2')
parser.add_argument('-s', '--size', type=int, metavar='\b', default=1024,
help='file size limit in KiBytes, default 1024 kb )... eg: 100')
args, _ = parser.parse_known_args()
try:
search_path, content, thread, size = args.path.replace('\\', '/'), args.content, args.thread, args.size
except Exception:
os.system('python ' + sys.argv[0] + ' -h')
sys.exit(0)
threadPool = ThreadPoolExecutor(max_workers=thread, thread_name_prefix="SearchThread")
run()
效果: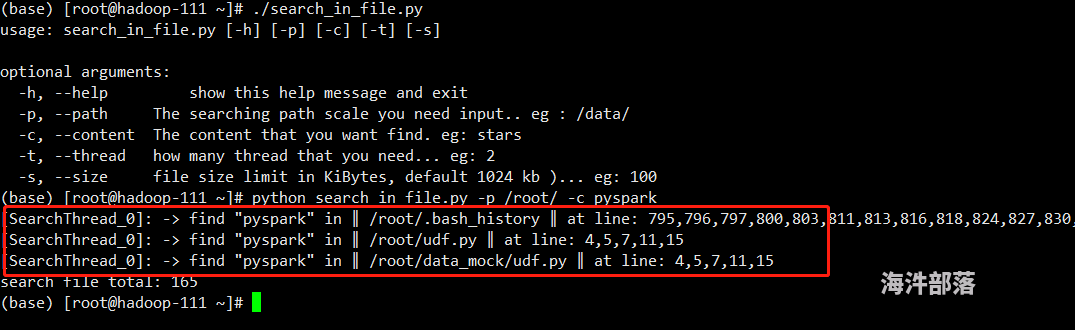
总结: 这两个脚本在工作中非常实用,第一个脚本是优化了find 命令的用法,第二个脚本很适合再大量脚本的文件夹中找到包含了某些代码块的脚本有哪些,我经常会用它来查询一些有相关依赖的脚本。


