上代码:(伪责任链模式)
代码结构如下: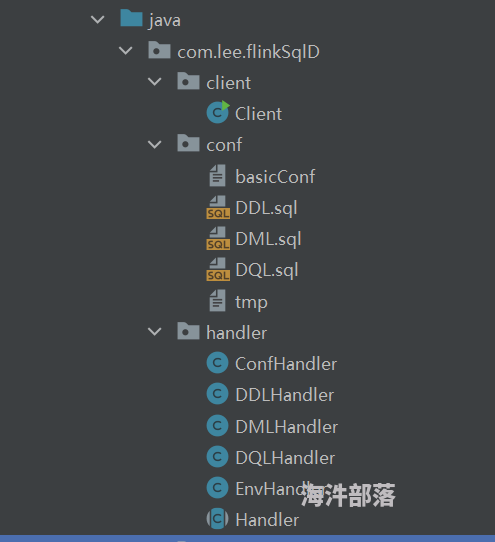
maven: 由于最近在研究JDBC连接器源码已经BinaryRowData 和 GenericRowData转换的源码,依赖有多余, 不需要这些依赖的可以自行删除
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<log4j.version>2.17.1</log4j.version>
<slf4j.version>1.7.32</slf4j.version>
<flink.version>1.15.1</flink.version>
<project.version>1.15.1</project.version>
<postgres.version>42.2.10</postgres.version>
<oracle.version>19.3.0.0</oracle.version>
<otj-pg-embedded.version>0.13.4</otj-pg-embedded.version>
</properties>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-runtime-web</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- Flink 应用程序缺少 JSON 格式的 deserialization connector。
在 Flink 中使用 JSON 格式的 deserialization,需要在应用程序依赖中包含 flink-json 依赖,您可以在 pom.xml 文件中添加以下依赖:-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-json</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.kafka/kafka-clients -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.4.0</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.70</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.30</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.30</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-to-slf4j</artifactId>
<version>2.14.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/com.amazon.redshift/redshift-jdbc42 -->
<dependency>
<groupId>com.amazon.redshift</groupId>
<artifactId>redshift-jdbc42</artifactId>
<version>2.1.0.1</version>
</dependency>
<!--连接postGre需要的依赖-->
<!-- <dependency>-->
<!-- <groupId>org.apache.flink</groupId>-->
<!-- <artifactId>flink-sql-client</artifactId>-->
<!-- <version>${flink.version}</version>-->
<!-- </dependency>-->
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-connector-jdbc -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc</artifactId>
<version>${flink.version}</version>
<!-- <scope>provided</scope>-->
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-common</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-csv</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
<version>42.3.1</version>
</dependency>
<!--rocksdb相关依赖-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-statebackend-rocksdb</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.rocksdb</groupId>
<artifactId>rocksdbjni</artifactId>
<version>5.18.4</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.4</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>org.apache.avro</groupId>
<artifactId>avro</artifactId>
<version>1.10.2</version>
</dependency>
<dependency>
<groupId>org.apache.avro</groupId>
<artifactId>avro-compiler</artifactId>
<version>1.10.2</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13.2</version>
<scope>test</scope>
</dependency>
<!--如下是FLink的JDBC连接器需要引入的依赖-->
<!-- Postgres -->
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
<version>${postgres.version}</version>
<!-- <scope>provided</scope>-->
</dependency>
<!-- Oracle -->
<dependency>
<groupId>com.oracle.database.jdbc</groupId>
<artifactId>ojdbc8</artifactId>
<version>${oracle.version}</version>
<!-- <scope>provided</scope>-->
</dependency>
<!-- MySQL tests -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.27</version>
<!-- <scope>test</scope>-->
</dependency>
Handler :
// 父类
public abstract class Handler {
protected Handler nextHandler;
protected StreamTableEnvironment tableEnv;
protected ArrayList<Object> arrayList;
protected Configuration conf;
public Handler() {
arrayList = new ArrayList<>();
}
public Handler setNextHandler(Handler nextHandler) {
this.nextHandler = nextHandler;
return this;
}
public abstract void handle(Handler subHandler);
public void handle() throws Exception {
throw new Exception("SubHandler Handle Failed!");
}
}ConfHandler:
public class ConfHandler extends Handler {
private final String confPath;
public ConfHandler(String confPath) {
this.confPath = confPath;
}
@Override
public void handle(Handler subHandler) {
System.out.println(" ================ ConfHandler ================ ");
// PropertyConfigurator.configure("src/main/resources/log4j.properties");
if (null == subHandler.conf) {
subHandler.conf = new Configuration();
}
subHandler.conf.setString("rest.port", "9101");
subHandler.conf.set(RestOptions.BIND_PORT, "9101");
subHandler.conf.set(WebOptions.LOG_PATH, "logs/FlinkTestLocal.log");
subHandler.conf.setString(ConfigConstants.TASK_MANAGER_LOG_PATH_KEY, "logs/taskManager.log");
for (String line : Objects.requireNonNull(Objects.requireNonNull(FileUtil.LoadFile(this.confPath)).replaceAll("hdfs:///", "file:///D:/")).trim().split("\n", -1)) {
if (!line.startsWith("%flink")
&& !line.startsWith("flink.execution.ars")
&& !line.startsWith("flink.udf.jars")
&& !line.startsWith("yarn")
&& !line.startsWith("execution.checkpointing")
&& line.trim().length() > 0) {
String[] split = line.split("\\s+");
String confKey = split[0];
String confValue = line.substring(confKey.length()).trim();
subHandler.conf.setString(confKey, confValue);
}
}
// 添加的默认配置信息
subHandler.conf.setString(" ", "");
if (null != this.nextHandler) this.nextHandler.handle(subHandler);
}
@Override
public void handle() throws Exception {
this.handle(this);
}
}EnvHandler:
public class EnvHandler extends Handler {
private final String envMode;
public EnvHandler(String envMode) {
this.envMode = envMode;
}
@Override
public void handle(Handler subHandler) {
if (this.envMode.equals("stream")) {
System.out.println("=============== =StreamEnvHandler ================= ");
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(subHandler.conf);
subHandler.tableEnv = StreamTableEnvironment.create(env);
} else if (this.envMode.equals("table")) {
System.out.println("================ TableEnvHandler ================= ");
Configuration sConf = new Configuration();
System.out.println(" [------ your steamEnv configuration ------] ");
for (Map.Entry<String, String> userConf : subHandler.conf.toMap().entrySet()) {
if (!userConf.getKey().startsWith("table") && userConf.getKey().trim().length() > 0) {
sConf.setString(userConf.getKey(), userConf.getValue());
System.out.println(userConf.getKey() + "=" + userConf.getValue());
}
}
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(sConf);
ExecutionConfig executionConfig = env.getConfig();
HashMap<Object, Object> configProp = (HashMap) JSONObject.parseObject(JSONObject.toJSONString(executionConfig), Map.class);
System.out.println("\n [====== Total steamEnv configuration ====]\n ");
for (Map.Entry<Object, Object> entry : configProp.entrySet())
System.out.println(entry.getKey() + " -----> " + entry.getValue());
EnvironmentSettings settings = EnvironmentSettings.newInstance()
//.useBlinkPlanner()
.inStreamingMode().build();
subHandler.tableEnv = StreamTableEnvironment.create(env, settings);
TableConfig config = subHandler.tableEnv.getConfig();
config.setLocalTimeZone(ZoneId.of("Asia/Shanghai"));
config.setSqlDialect(SqlDialect.DEFAULT);
Configuration tConf = config.getConfiguration();
System.out.println(" [------ your tableEnv configuration ------] ");
for (Map.Entry<String, String> userConf : subHandler.conf.toMap().entrySet()) {
if (userConf.getKey().startsWith("table") && userConf.getKey().trim().length() > 0) {
tConf.setString(userConf.getKey(), userConf.getValue());
System.out.println(userConf.getKey() + "=" + userConf.getValue());
}
}
System.out.println("\n [====== Total tableEnv configuration ====]\n");
for (Map.Entry<String, String> entry : subHandler.conf.toMap().entrySet()) {
if (entry.getKey().trim().length() > 0)
System.out.println(entry.getKey() + " -----> " + entry.getValue());
}
} else {
System.out.println("wrong stream mode!");
System.exit(-2);
}
if (null != this.nextHandler) this.nextHandler.handle(subHandler);
}
@Override
public void handle() throws Exception {
this.handle(this);
}
}
DDLHandler:
public class DDLHandler extends Handler {
private String ddlPath;
public DDLHandler(String ddlPath) {
this.ddlPath = ddlPath;
}
@Override
public void handle(Handler subHandler) {
System.out.println("================== DDLHandler =====================");
for (String ddlLine : Objects.requireNonNull(Objects.requireNonNull(FileUtil.LoadFile(ddlPath))
.replaceAll("\";'", "\001"))
.trim().split(";")) {
if (ddlLine.trim().length() > 0
&& !ddlLine.trim().startsWith("%flink")
&& !ddlLine.trim().toUpperCase().startsWith("DROP")
) {
System.out.println("------------------------------------------");
System.out.println(ddlLine.replaceAll("\001", "\";'"));
String tarSql = ddlLine.replaceAll("\001", "\";'").trim();
if (tarSql.endsWith(";"))
subHandler.tableEnv.executeSql(tarSql.substring(0, tarSql.length() - 1)).print();
else
subHandler.tableEnv.executeSql(tarSql).print();
}
}
if (null != this.nextHandler) this.nextHandler.handle(subHandler);
}
@Override
public void handle() throws Exception {
this.handle(this);
}
}DMLHandler:
public class DMLHandler extends Handler {
private String dmlPath;
public DMLHandler(String dmlPath) {
this.dmlPath = dmlPath;
}
@Override
public void handle(Handler subHandler) {
System.out.println("================== DMLHandler =====================");
for (String line : Objects.requireNonNull(Objects.requireNonNull(FileUtil.LoadFile(dmlPath))
.replaceAll("\";'", "\001"))
.trim().split(";")) {
if (line.trim().length() > 0
&& !line.trim().startsWith("%flink")
&& !line.trim().toUpperCase().startsWith("DROP")
) {
System.out.println("------------------------------------------");
System.out.println(line.replaceAll("\001", "\";'"));
subHandler.tableEnv.executeSql(line.replaceAll("\001", "\";'")).print();
}
}
if (null != this.nextHandler) this.nextHandler.handle(subHandler);
}
@Override
public void handle() throws Exception {
this.handle(this);
}
}DQLHandler:
public class DQLHandler extends Handler {
private String dqlPath;
public DQLHandler(String dqlPath) {
this.dqlPath = dqlPath;
}
@Override
public void handle(Handler subHandler) {
System.out.println("================== DQLHandler =====================");
for (String line : Objects.requireNonNull(Objects.requireNonNull(FileUtil.LoadFile(dqlPath))
.replaceAll("\";'", "\001"))
.trim().split(";")) {
if (line.trim().length() > 0
&& !line.trim().startsWith("%flink")
&& !line.trim().toUpperCase().startsWith("DROP")
) {
System.out.println("------------------------------------------");
// TableResult result = subHandler.tableEnv.executeSql(line.replaceAll("\001", "\";'"));
Table table = subHandler.tableEnv.sqlQuery(line.replaceAll("\001", "\";'"));
table.printExplain();
TableResult result = table.execute();
System.out.println("SCHEMA:" + result.getResolvedSchema().getColumnDataTypes());
System.out.println("SCHEMA FOR JSON: " + JSONObject.toJSONString(result.getResolvedSchema().getColumnDataTypes()));
System.out.println("ResultKind: " + result.getResultKind());
System.out.println("ResolvedSchema: " + result.getResolvedSchema());
result.print();
}
}
if (null != this.nextHandler) this.nextHandler.handle(subHandler);
}
@Override
public void handle() throws Exception {
this.handle(this);
}
}conf 文件夹下需要配置对应的 配置:
- Flink env 及 tableEnv 相关的配置:basicConf: 如下简单示例
component_id 10001 jobmanager.memory.process.size 2048m taskmanager.memory.process.size 10240m taskmanager.numOfTaskSlots 1 table.exec.resource.default-parallelism 1 table.exec.state.ttl 6000 execution.checkpointing.interval 600000 execution.checkpointing.min-pause 780000 state.backend rocksdb state.backend.incremental true state.checkpoints.dir hdfs:///flink/checkpoints/10001FlinkSQL中用到的DDL建表语句:DDL.sql:示例
由于SQL 中存在反引号 `所以会有影响
DROP TABLE if EXISTS LEE_KAFKA_01;
CREATE TABLE LEE_KAFKA_01
(
col1 VARCHAR,
col2 VARCHAR,
col3 VARCHAR,
col4 timestamp(3),
WATERMARK FOR col4 AS col4 - INTERVAL '0' SECOND
) WITH (
'connector' = 'kafka',
'topic' = 'TEST-01',
'properties.bootstrap.servers' = 'localhost:9092',
'properties.group.id' = 'lee-group-1',
'format' = 'json',
'json.fail-on-missing-field' = 'true'
);
DROP TABLE if EXISTS LEE_KAFKA_02;
CREATE TABLE LEE_KAFKA_02
(
f_sequence INT,
f_random INT,
f_random_str STRING,
ts AS localtimestamp,
WATERMARK FOR ts AS ts
) WITH (
'connector' = 'datagen',
'rows-per-second' = '1000',
'fields.f_sequence.kind' = 'sequence',
'fields.f_sequence.start' = '1',
'fields.f_sequence.end' = '1000000',
'fields.f_random.min' = '10',
'fields.f_random.max' = '100',
'fields.f_random_str.length' = '10'
);
DROP TABLE if EXISTS LEE_KAFKA_022;
CREATE TABLE LEE_KAFKA_022
(
f_sequence INT,
f_random INT,
f_random_str STRING,
ts AS localtimestamp,
WATERMARK FOR ts AS ts
) WITH (
'connector' = 'datagen',
'rows-per-second' = '1000',
'fields.f_sequence.kind' = 'sequence',
'fields.f_sequence.start' = '1',
-- 事先把序列加载到内存中,才能起任务序列越长,越耗时
'fields.f_sequence.end' = '1000000',
'fields.f_random.min' = '10',
'fields.f_random.max' = '100',
'fields.f_random_str.length' = '10'
)
;
DROP TABLE if EXISTS LEE_KAFKA_03;
CREATE TABLE LEE_KAFKA_03
(
col1 VARCHAR,
col2 VARCHAR,
col3 VARCHAR,
col4 timestamp(3)
) WITH (
'connector' = 'kafka',
'topic' = 'TEST-01',
'properties.bootstrap.servers' = 'localhost:9092',
'properties.group.id' = 'lee-group-1',
'format' = 'json',
'json.fail-on-missing-field' = 'true'
);
CREATE TABLE finance_log
(
_id varchar(128),
user_id varchar(128),
cny double precision,
coin bigint,
via varchar(128),
rid varchar(128),
session_nick_name varchar(1024),
session_id varchar(128),
remark varchar(128),
returncoin bigint,
to_id varchar(128),
transfer_ratio varchar(128),
amount varchar(128),
qd varchar(128),timestamp Timestamp(3),
en_mobile varchar(128)
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:postgresql://XXXXX.XXXXXX.XX-XXXX-1.redshift.amazonaws.com.cn:5439/XXXXX',
'table-name' = 'DB.YOUR_TABLE',
'driver' = 'org.postgresql.Driver',
'username' = 'USERNAME',
'password' = 'XXXXXXX'
);
CREATE TABLE blackhole_table
(
_id VARCHAR(100),
user_id VARCHAR(100),
cny DOUBLE PRECISION,
coin BIGINT,
via VARCHAR(100),
rid VARCHAR(100),
session_nick_name VARCHAR(100),
session_id VARCHAR(100),
remark VARCHAR(100),
returncoin BIGINT,
to_id VARCHAR(100),
transfer_ratio VARCHAR(100),
amount VARCHAR(100),
qd VARCHAR(100),timestamp TIMESTAMP,
en_mobile VARCHAR(100)
) WITH (
'connector' = 'blackhole'
);
Flink SQL 的 DML语句:DML.sql 示例
```roomsql
INSERT INTO blackhole_table
select b.* from
(SELECT 'id_' || CAST(FLOOR(RAND() * 10000) AS VARCHAR) AS _id,
'user_' || CAST(FLOOR(RAND() * 10000) AS VARCHAR) AS user_id,
FLOOR(RAND() * 1000) AS cny,
cast(FLOOR(RAND() * 1000) as bigint) AS coin,
'via_' || CAST(FLOOR(RAND() * 100) AS VARCHAR) AS via,
'rid_' || CAST(FLOOR(RAND() * 100) AS VARCHAR) AS rid,
'nickname_' || CAST(FLOOR(RAND() * 10000) AS VARCHAR) AS session_nick_name,
'session_' || CAST(FLOOR(RAND() * 100) AS VARCHAR) AS session_id,
'remark_' || CAST(FLOOR(RAND() * 100) AS VARCHAR) AS remark,
CAST(FLOOR(RAND() * 1000) AS BIGINT) AS returncoin,
'to_' || CAST(FLOOR(RAND() * 100) AS VARCHAR) AS to_id,
'ratio_' || CAST(FLOOR(RAND() * 100) AS VARCHAR) AS transfer_ratio,
CAST(FLOOR(RAND() * 1000) AS VARCHAR) || ' USD' AS amount,
'qd_' || CAST(FLOOR(RAND() * 100) AS VARCHAR) AS qd,
-- TO_TIMESTAMP(FROM_UNIXTIME(numeric_col))
localtimestamp AS `timestamp`,
'mobile_' || CAST(FLOOR(RAND() * 10000) AS VARCHAR) AS en_mobile
FROM LEE_KAFKA_02) a left join
(SELECT 'id_' || CAST(FLOOR(RAND() * 10000) AS VARCHAR) AS _id,
'user_' || CAST(FLOOR(RAND() * 10000) AS VARCHAR) AS user_id,
FLOOR(RAND() * 1000) AS cny,
cast(FLOOR(RAND() * 1000) as bigint) AS coin,
'via_' || CAST(FLOOR(RAND() * 100) AS VARCHAR) AS via,
'rid_' || CAST(FLOOR(RAND() * 100) AS VARCHAR) AS rid,
'nickname_' || CAST(FLOOR(RAND() * 10000) AS VARCHAR) AS session_nick_name,
'session_' || CAST(FLOOR(RAND() * 100) AS VARCHAR) AS session_id,
'remark_' || CAST(FLOOR(RAND() * 100) AS VARCHAR) AS remark,
CAST(FLOOR(RAND() * 1000)AS BIGINT) AS returncoin,
'to_' || CAST(FLOOR(RAND() * 100) AS VARCHAR) AS to_id,
'ratio_' || CAST(FLOOR(RAND() * 100) AS VARCHAR) AS transfer_ratio,
CAST(FLOOR(RAND() * 1000) AS VARCHAR) || ' USD' AS amount,
'qd_' || CAST(FLOOR(RAND() * 100) AS VARCHAR) AS qd,
localtimestamp AS `timestamp`,
'mobile_' || CAST(FLOOR(RAND() * 10000) AS VARCHAR) AS en_mobile
FROM LEE_KAFKA_022) b
on 1=1
and a.`timestamp` BETWEEN b.`timestamp` - INTERVAL '20' SECOND and b.`timestamp` + INTERVAL '10' SECOND
UNION ALL
select b.* from
(SELECT 'id_' || CAST(FLOOR(RAND() * 10000) AS VARCHAR) AS _id,
'user_' || CAST(FLOOR(RAND() * 10000) AS VARCHAR) AS user_id,
FLOOR(RAND() * 1000) AS cny,
cast(FLOOR(RAND() * 1000) as bigint) AS coin,
'via_' || CAST(FLOOR(RAND() * 100) AS VARCHAR) AS via,
'rid_' || CAST(FLOOR(RAND() * 100) AS VARCHAR) AS rid,
'nickname_' || CAST(FLOOR(RAND() * 10000) AS VARCHAR) AS session_nick_name,
'session_' || CAST(FLOOR(RAND() * 100) AS VARCHAR) AS session_id,
'remark_' || CAST(FLOOR(RAND() * 100) AS VARCHAR) AS remark,
CAST(FLOOR(RAND() * 1000) AS BIGINT) AS returncoin,
'to_' || CAST(FLOOR(RAND() * 100) AS VARCHAR) AS to_id,
'ratio_' || CAST(FLOOR(RAND() * 100) AS VARCHAR) AS transfer_ratio,
CAST(FLOOR(RAND() * 1000) AS VARCHAR) || ' USD' AS amount,
'qd_' || CAST(FLOOR(RAND() * 100) AS VARCHAR) AS qd,
-- TO_TIMESTAMP(FROM_UNIXTIME(numeric_col))
localtimestamp AS `timestamp`,
'mobile_' || CAST(FLOOR(RAND() * 10000) AS VARCHAR) AS en_mobile
FROM LEE_KAFKA_022) a left join
(SELECT 'id_' || CAST(FLOOR(RAND() * 10000) AS VARCHAR) AS _id,
'user_' || CAST(FLOOR(RAND() * 10000) AS VARCHAR) AS user_id,
FLOOR(RAND() * 1000) AS cny,
cast(FLOOR(RAND() * 1000) as bigint) AS coin,
'via_' || CAST(FLOOR(RAND() * 100) AS VARCHAR) AS via,
'rid_' || CAST(FLOOR(RAND() * 100) AS VARCHAR) AS rid,
'nickname_' || CAST(FLOOR(RAND() * 10000) AS VARCHAR) AS session_nick_name,
'session_' || CAST(FLOOR(RAND() * 100) AS VARCHAR) AS session_id,
'remark_' || CAST(FLOOR(RAND() * 100) AS VARCHAR) AS remark,
CAST(FLOOR(RAND() * 1000)AS BIGINT) AS returncoin,
'to_' || CAST(FLOOR(RAND() * 100) AS VARCHAR) AS to_id,
'ratio_' || CAST(FLOOR(RAND() * 100) AS VARCHAR) AS transfer_ratio,
CAST(FLOOR(RAND() * 1000) AS VARCHAR) || ' USD' AS amount,
'qd_' || CAST(FLOOR(RAND() * 100) AS VARCHAR) AS qd,
localtimestamp AS `timestamp`,
'mobile_' || CAST(FLOOR(RAND() * 10000) AS VARCHAR) AS en_mobile
FROM LEE_KAFKA_02) b
on 1=1
and a.`timestamp` BETWEEN b.`timestamp` - INTERVAL '20' SECOND and b.`timestamp` + INTERVAL '10' SECONDFlink SQL 的 DQL语句:DQL.sql示例:
SELECT distinct *
FROM (
SELECT DISTINCT *, ROW_NUMBER() OVER (PARTITION BY window_start, window_end ORDER BY localtimestamp DESC) as rownum
FROM (
SELECT window_start,
window_end,
f_random,
LAST_VALUE(f_sequence) as s_last,
MAX(localtimestamp) m_localtimestamp,
COUNT(*) as cnt_total,
COUNT(DISTINCT localtimestamp) time_dis_count
FROM TABLE(
TUMBLE(TABLE LEE_KAFKA_02, DESCRIPTOR(ts), INTERVAL '10' SECONDS)
)
GROUP BY window_start, window_end, f_random
order by m_localtimestamp desc -- UPDATETIMEOUT 10 MINUTE -- 算子级别的 TTL 设置
)
) a
left join LEE_KAFKA_01 b
on cast(a.f_random as varchar) = b.col1
and a.m_localtimestamp
between col4 - interval '1' hour and col4 + interval '1' hour
WHERE rownum < 10; -- 取出以 window_start, window_end, f_random 分组的最新的10条数据, KAFKA 表没数据 随便关联的,b表没数据,反压是正常现象用户启动类: client.java 示例:
注意:本地测试时,需要指定conf文件夹的位置到环境变量CONF_FILE_DIR中,DQL 和 DML 不可同时使用,webWU端口号是:9101
/**
* Created by Lijun at 2023/02/17
*/
public class Client {
private static final Logger LOGGER = LoggerFactory.getLogger(Client.class);
public static void main(String[] args) throws Exception {
LOGGER.info("------------------START---------------------");
//新增默认配置
System.out.println("准备删除文件...");
FileUtil.deleteFolder(new File("logs"));
// System.exit(-11);
// flinkWebUI 的地址为 9101
if(null == System.getenv("CONF_FILE_DIR")){
System.err.println("环境变量:[CONF_FILE_DIR]未配置, 程序退出!");
LOGGER.error("can not find the conf dir, please set in your Env!");
System.exit(-2);
}
String confDir = System.getenv("CONF_FILE_DIR");
EnvHandler envHandler = new EnvHandler("table");
ConfHandler confHandler = new ConfHandler(confDir + "/basicConf");
DDLHandler ddlHandler = new DDLHandler(confDir + "/DDL.sql");
DMLHandler dmlHandler = new DMLHandler(confDir + "/DML.sql");
DQLHandler dqlHandler = new DQLHandler(confDir + "/DQL.sql");
// dml 语句时使用
confHandler.setNextHandler(envHandler.setNextHandler(ddlHandler.setNextHandler(dmlHandler))).handle();
// dql 语句时使用
// confHandler.setNextHandler(envHandler.setNextHandler(ddlHandler.setNextHandler(dqlHandler))).handle();
}
}
log4j.properties 配置: 添加了jobmanager 和 taskmanager 的不同log位置输出:
# Root logger option,file ?????????,root??
log4j.rootLogger=INFO, file
# Direct log messages to stdout
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.Target=System.out
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss,SSS} %-5p %-60c %x - %m%n
# Reduce Noise
log4j.logger.org.apache.flink=INFO
log4j.logger.org.apache.flink.util.ShutdownHookUtil=ERROR
log4j.logger.org.apache.flink.runtime.entrypoint.ClusterEntrypoint=INFO
log4j.logger.org.apache.flink.runtime.rest.RestServerEndpoint=INFO
log4j.logger.org.apache.flink.runtime.dispatcher.DispatcherRestEndpoint=INFO
log4j.logger.org.apache.flink.runtime.rest.handler.legacy.metrics.MetricFetcher=INFO
log4j.logger.org.apache.flink.runtime.resourcemanager.slotmanager.SlotManager=INFO
log4j.logger.org.apache.flink.runtime.metrics.dump.QueryableStateUtils=INFO
log4j.logger.org.apache.flink.runtime.metrics.MetricRegistry=INFO
log4j.logger.org.apache.flink.runtime.rpc.akka.AkkaRpcService=INFO
# Disable Metrics for now
log4j.logger.org.apache.flink.metrics=ERROR
# Error file appender
log4j.appender.file=org.apache.log4j.RollingFileAppender
log4j.appender.file.File=logs/FlinkTestLocal.log
log4j.appender.file.MaxFileSize=100MB
log4j.appender.file.MaxBackupIndex=1
log4j.appender.file.layout=org.apache.log4j.PatternLayout
log4j.appender.file.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss.SSS} %-5p %-60c %x - %m%n
log4j.logger.akka=WARN
log4j.logger.org.apache.kafka=INFO
log4j.logger.org.apache.hadoop=WARN
log4j.logger.org.apache.zookeeper=WARN
# Suppress the irrelevant (wrong) warnings from the Netty channel handler
log4j.logger.org.apache.flink.shaded.akka.org.jboss.netty.channel.DefaultChannelPipeline=ERROR, console
# define yourself taskmanager appender
log4j.logger.org.apache.flink.runtime.taskmanager=INFO, LeeTaskManager
# Define the file appender for handler logger
log4j.appender.LeeTaskManager=org.apache.log4j.RollingFileAppender
log4j.appender.LeeTaskManager.File=logs/taskManager.log
log4j.appender.LeeTaskManager.MaxFileSize=10MB
log4j.appender.LeeTaskManager.MaxBackupIndex=10
log4j.appender.LeeTaskManager.layout=org.apache.log4j.PatternLayout
log4j.appender.LeeTaskManager.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss,SSS} %-5p %-60c %x - %m%nutil 工具类:(删除LOG时使用)
public class FileUtil {
public static void deleteFolder(File folder) {
if (folder.isDirectory()) {
File[] files = folder.listFiles();
if (files != null) {
for (File file : files) {
deleteFolder(file);
}
}
}
try {
if (!folder.delete()) {
System.err.println("Failed to delete " + folder.getAbsolutePath());
}
} catch (Exception e) {
System.err.println("Failed to delete " + folder.getAbsolutePath() + ": " + e.getMessage());
e.printStackTrace();
}
}
public static String LoadFile(String filePath) {
filePath = filePath.replaceAll("\\\\", "/");
try {
InputStream inputStream = !filePath.contains("/") ? FileUtil.class.getClassLoader().getResourceAsStream(filePath)
: Files.newInputStream(Paths.get(filePath));
ByteArrayOutputStream bots = new ByteArrayOutputStream();
int _byte;
while (true) {
assert inputStream != null;
if ((_byte = inputStream.read()) == -1) break;
bots.write(_byte);
}
String res = bots.toString();
bots.close();
inputStream.close();
return res;
} catch (
Exception e) {
e.printStackTrace();
return null;
}
}
public static void deleteFile(File file) {
if (!file.exists()) {
return;
}
File[] files = file.listFiles();
if (file.isFile()) {
file.delete();
return;
}
if (files.length == 0) {
file.delete();
} else {
for (File value : files) {
if (value.isDirectory()) {
deleteFile(value);
value.delete();
} else {
value.delete();
}
}
file.delete();
}
}
}配置好并运行client.java启动你的作业:我以一个DQL作业为实例:控制台打印如下: (工具类中删除LOG的方法有点问题哦,你可以自行修改)
com.lee.flinkSqlD.client.Client
准备删除文件...
================ ConfHandler ================
Failed to delete D:\workspace\FlinkTestLocalApache\FlinkTestLocalApache\logs\FlinkTestLocal.log
Failed to delete D:\workspace\FlinkTestLocalApache\FlinkTestLocalApache\logs\taskManager.log
Failed to delete D:\workspace\FlinkTestLocalApache\FlinkTestLocalApache\logs
================ TableEnvHandler =================
[------ your steamEnv configuration ------]
taskmanager.memory.process.size=10240m
component_id=10001
web.log.path=logs/FlinkTestLocal.log
state.backend.incremental=true
jobmanager.memory.process.size=2048m
rest.port=9101
taskmanager.log.path=logs/taskManager.log
rest.bind-port=9101
state.backend=rocksdb
taskmanager.numOfTaskSlots=1
state.checkpoints.dir=file:///D:/flink/checkpoints/10001
[====== Total steamEnv configuration ====]
autoWatermarkInterval -----> 200
globalJobParameters -----> {}
maxParallelism -----> -1
parallelism -----> 12
numberOfExecutionRetries -----> -1
taskCancellationInterval -----> -1
defaultKryoSerializerClasses -----> {}
latencyTrackingInterval -----> 0
taskCancellationTimeout -----> -1
registeredPojoTypes -----> []
forceAvroEnabled -----> false
registeredKryoTypes -----> []
dynamicGraph -----> false
latencyTrackingConfigured -----> false
executionRetryDelay -----> 10000
forceKryoEnabled -----> false
registeredTypesWithKryoSerializers -----> {}
executionMode -----> PIPELINED
closureCleanerEnabled -----> true
autoTypeRegistrationDisabled -----> false
defaultKryoSerializers -----> {}
closureCleanerLevel -----> RECURSIVE
registeredTypesWithKryoSerializerClasses -----> {}
materializationMaxAllowedFailures -----> 3
periodicMaterializeIntervalMillis -----> 600000
defaultInputDependencyConstraint -----> ANY
restartStrategy -----> {"description":"Cluster level default restart strategy"}
objectReuseEnabled -----> false
useSnapshotCompression -----> false
[------ your tableEnv configuration ------]
table.exec.resource.default-parallelism=1
table.exec.state.ttl=6000
[====== Total tableEnv configuration ====]
taskmanager.memory.process.size -----> 10240m
component_id -----> 10001
web.log.path -----> logs/FlinkTestLocal.log
table.exec.resource.default-parallelism -----> 1
state.backend.incremental -----> true
jobmanager.memory.process.size -----> 2048m
rest.port -----> 9101
taskmanager.log.path -----> logs/taskManager.log
table.exec.state.ttl -----> 6000
rest.bind-port -----> 9101
state.backend -----> rocksdb
taskmanager.numOfTaskSlots -----> 1
state.checkpoints.dir -----> file:///D:/flink/checkpoints/10001
================== DDLHandler =====================
------------------------------------------
CREATE TABLE LEE_KAFKA_01
(
col1 VARCHAR,
col2 VARCHAR,
col3 VARCHAR,
col4 timestamp(3),
WATERMARK FOR col4 AS col4 - INTERVAL '0' SECOND
) WITH (
'connector' = 'kafka',
'topic' = 'TEST-01',
'properties.bootstrap.servers' = 'localhost:9092',
'properties.group.id' = 'lee-group-1',
'format' = 'json',
'json.fail-on-missing-field' = 'true'
)
OK
------------------------------------------
CREATE TABLE LEE_KAFKA_02
(
f_sequence INT,
f_random INT,
f_random_str STRING,
ts AS localtimestamp,
WATERMARK FOR ts AS ts
) WITH (
'connector' = 'datagen',
'rows-per-second' = '1000',
'fields.f_sequence.kind' = 'sequence',
'fields.f_sequence.start' = '1',
'fields.f_sequence.end' = '1000000',
'fields.f_random.min' = '10',
'fields.f_random.max' = '100',
'fields.f_random_str.length' = '10'
)
OK
------------------------------------------
CREATE TABLE LEE_KAFKA_022
(
f_sequence INT,
f_random INT,
f_random_str STRING,
ts AS localtimestamp,
WATERMARK FOR ts AS ts
) WITH (
'connector' = 'datagen',
'rows-per-second' = '1000',
'fields.f_sequence.kind' = 'sequence',
'fields.f_sequence.start' = '1',
-- 事先把序列加载到内存中,才能起任务序列越长,越耗时
'fields.f_sequence.end' = '1000000',
'fields.f_random.min' = '10',
'fields.f_random.max' = '100',
'fields.f_random_str.length' = '10'
)
OK
------------------------------------------
CREATE TABLE LEE_KAFKA_03
(
col1 VARCHAR,
col2 VARCHAR,
col3 VARCHAR,
col4 timestamp(3)
) WITH (
'connector' = 'kafka',
'topic' = 'TEST-01',
'properties.bootstrap.servers' = 'localhost:9092',
'properties.group.id' = 'lee-group-1',
'format' = 'json',
'json.fail-on-missing-field' = 'true'
)
OK
------------------------------------------
CREATE TABLE finance_log
(
_id varchar(128),
user_id varchar(128),
cny double precision,
coin bigint,
via varchar(128),
rid varchar(128),
session_nick_name varchar(1024),
session_id varchar(128),
remark varchar(128),
returncoin bigint,
to_id varchar(128),
transfer_ratio varchar(128),
amount varchar(128),
qd varchar(128),
`timestamp` Timestamp(3),
en_mobile varchar(128)
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:postgresql://xxxx-xxxx.xxx.cn-north-1.redshift.amazonaws.com.cn:5439/xxx',
'table-name' = 'xxx.xx',
'driver' = 'org.postgresql.Driver',
'username' = 'xxx',
'password' = 'xxx'
)
OK
------------------------------------------
CREATE TABLE blackhole_table
(
_id VARCHAR(100),
user_id VARCHAR(100),
cny DOUBLE PRECISION,
coin BIGINT,
via VARCHAR(100),
rid VARCHAR(100),
session_nick_name VARCHAR(100),
session_id VARCHAR(100),
remark VARCHAR(100),
returncoin BIGINT,
to_id VARCHAR(100),
transfer_ratio VARCHAR(100),
amount VARCHAR(100),
qd VARCHAR(100),
`timestamp` TIMESTAMP,
en_mobile VARCHAR(100)
) WITH (
'connector' = 'blackhole'
)
OK
================== DQLHandler =====================
------------------------------------------
== Abstract Syntax Tree ==
LogicalAggregate(group=[{0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11}])
+- LogicalProject(window_start=[$0], window_end=[$1], f_random=[$2], s_last=[$3], m_localtimestamp=[$4], cnt_total=[$5], time_dis_count=[$6], rownum=[$7], col1=[$8], col2=[$9], col3=[$10], col4=[$11])
+- LogicalFilter(condition=[<($7, 10)])
+- LogicalProject(window_start=[$0], window_end=[$1], f_random=[$2], s_last=[$3], m_localtimestamp=[$4], cnt_total=[$5], time_dis_count=[$6], rownum=[$7], col1=[$9], col2=[$10], col3=[$11], col4=[$12])
+- LogicalJoin(condition=[AND(=($8, $9), >=($4, -($12, 3600000:INTERVAL HOUR)), <=($4, +($12, 3600000:INTERVAL HOUR)))], joinType=[left])
:- LogicalProject(window_start=[$0], window_end=[$1], f_random=[$2], s_last=[$3], m_localtimestamp=[$4], cnt_total=[$5], time_dis_count=[$6], rownum=[ROW_NUMBER() OVER (PARTITION BY $0, $1 ORDER BY LOCALTIMESTAMP DESC NULLS LAST)], f_random0=[CAST($2):VARCHAR(2147483647) CHARACTER SET "UTF-16LE"])
: +- LogicalAggregate(group=[{0, 1, 2}], s_last=[LAST_VALUE($3)], m_localtimestamp=[MAX($4)], cnt_total=[COUNT()], time_dis_count=[COUNT(DISTINCT $4)])
: +- LogicalProject(window_start=[$4], window_end=[$5], f_random=[$1], f_sequence=[$0], $f4=[LOCALTIMESTAMP])
: +- LogicalTableFunctionScan(invocation=[TUMBLE($3, DESCRIPTOR($3), 10000:INTERVAL SECOND)], rowType=[RecordType(INTEGER f_sequence, INTEGER f_random, VARCHAR(2147483647) f_random_str, TIMESTAMP(3) *ROWTIME* ts, TIMESTAMP(3) window_start, TIMESTAMP(3) window_end, TIMESTAMP(3) *ROWTIME* window_time)])
: +- LogicalProject(f_sequence=[$0], f_random=[$1], f_random_str=[$2], ts=[$3])
: +- LogicalWatermarkAssigner(rowtime=[ts], watermark=[$3])
: +- LogicalProject(f_sequence=[$0], f_random=[$1], f_random_str=[$2], ts=[LOCALTIMESTAMP])
: +- LogicalTableScan(table=[[default_catalog, default_database, LEE_KAFKA_02]])
+- LogicalWatermarkAssigner(rowtime=[col4], watermark=[-($3, 0:INTERVAL SECOND)])
+- LogicalTableScan(table=[[default_catalog, default_database, LEE_KAFKA_01]])
== Optimized Physical Plan ==
GroupAggregate(groupBy=[window_start, window_end, f_random, s_last, m_localtimestamp, cnt_total, time_dis_count, rownum, col1, col2, col3, col4], select=[window_start, window_end, f_random, s_last, m_localtimestamp, cnt_total, time_dis_count, rownum, col1, col2, col3, col4])
+- Exchange(distribution=[hash[window_start, window_end, f_random, s_last, m_localtimestamp, cnt_total, time_dis_count, rownum, col1, col2, col3, col4]])
+- Calc(select=[window_start, window_end, f_random, s_last, m_localtimestamp, cnt_total, time_dis_count, $7 AS rownum, col1, col2, col3, col4])
+- Join(joinType=[LeftOuterJoin], where=[AND(=($8, col1), >=(m_localtimestamp, -(col4, 3600000:INTERVAL HOUR)), <=(m_localtimestamp, +(col4, 3600000:INTERVAL HOUR)))], select=[window_start, window_end, f_random, s_last, m_localtimestamp, cnt_total, time_dis_count, $7, $8, col1, col2, col3, col4], leftInputSpec=[HasUniqueKey], rightInputSpec=[NoUniqueKey])
:- Exchange(distribution=[hash[$8]])
: +- Calc(select=[window_start, window_end, f_random, s_last, m_localtimestamp, cnt_total, time_dis_count, $7_0 AS $7, $8])
: +- WindowRank(window=[TUMBLE(win_start=[window_start], win_end=[window_end], size=[10 s])], rankType=[ROW_NUMBER], rankRange=[rankStart=1, rankEnd=9], partitionBy=[], orderBy=[$7 DESC], select=[window_start, window_end, f_random, s_last, m_localtimestamp, cnt_total, time_dis_count, $7, $8, $7_0])
: +- Exchange(distribution=[single])
: +- Calc(select=[window_start, window_end, f_random, s_last, m_localtimestamp, cnt_total, time_dis_count, LOCALTIMESTAMP() AS $7, CAST(f_random AS VARCHAR(2147483647) CHARACTER SET "UTF-16LE") AS $8])
: +- WindowAggregate(groupBy=[f_random], window=[TUMBLE(time_col=[ts], size=[10 s])], select=[f_random, LAST_VALUE(f_sequence) AS s_last, MAX($f4) AS m_localtimestamp, COUNT(*) AS cnt_total, COUNT(DISTINCT $f4) AS time_dis_count, start('w$) AS window_start, end('w$) AS window_end])
: +- Exchange(distribution=[hash[f_random]])
: +- Calc(select=[f_random, f_sequence, LOCALTIMESTAMP() AS $f4, ts])
: +- WatermarkAssigner(rowtime=[ts], watermark=[ts])
: +- Calc(select=[f_sequence, f_random, LOCALTIMESTAMP() AS ts])
: +- TableSourceScan(table=[[default_catalog, default_database, LEE_KAFKA_02]], fields=[f_sequence, f_random, f_random_str])
+- Exchange(distribution=[hash[col1]])
+- Calc(select=[col1, col2, col3, CAST(col4 AS TIMESTAMP(3)) AS col4])
+- TableSourceScan(table=[[default_catalog, default_database, LEE_KAFKA_01, watermark=[-(col4, 0:INTERVAL SECOND)]]], fields=[col1, col2, col3, col4])
== Optimized Execution Plan ==
GroupAggregate(groupBy=[window_start, window_end, f_random, s_last, m_localtimestamp, cnt_total, time_dis_count, rownum, col1, col2, col3, col4], select=[window_start, window_end, f_random, s_last, m_localtimestamp, cnt_total, time_dis_count, rownum, col1, col2, col3, col4])
+- Exchange(distribution=[hash[window_start, window_end, f_random, s_last, m_localtimestamp, cnt_total, time_dis_count, rownum, col1, col2, col3, col4]])
+- Calc(select=[window_start, window_end, f_random, s_last, m_localtimestamp, cnt_total, time_dis_count, $7 AS rownum, col1, col2, col3, col4])
+- Join(joinType=[LeftOuterJoin], where=[(($8 = col1) AND (m_localtimestamp >= (col4 - 3600000:INTERVAL HOUR)) AND (m_localtimestamp <= (col4 + 3600000:INTERVAL HOUR)))], select=[window_start, window_end, f_random, s_last, m_localtimestamp, cnt_total, time_dis_count, $7, $8, col1, col2, col3, col4], leftInputSpec=[HasUniqueKey], rightInputSpec=[NoUniqueKey])
:- Exchange(distribution=[hash[$8]])
: +- Calc(select=[window_start, window_end, f_random, s_last, m_localtimestamp, cnt_total, time_dis_count, $7_0 AS $7, $8])
: +- WindowRank(window=[TUMBLE(win_start=[window_start], win_end=[window_end], size=[10 s])], rankType=[ROW_NUMBER], rankRange=[rankStart=1, rankEnd=9], partitionBy=[], orderBy=[$7 DESC], select=[window_start, window_end, f_random, s_last, m_localtimestamp, cnt_total, time_dis_count, $7, $8, $7_0])
: +- Exchange(distribution=[single])
: +- Calc(select=[window_start, window_end, f_random, s_last, m_localtimestamp, cnt_total, time_dis_count, LOCALTIMESTAMP() AS $7, CAST(f_random AS VARCHAR(2147483647)) AS $8])
: +- WindowAggregate(groupBy=[f_random], window=[TUMBLE(time_col=[ts], size=[10 s])], select=[f_random, LAST_VALUE(f_sequence) AS s_last, MAX($f4) AS m_localtimestamp, COUNT(*) AS cnt_total, COUNT(DISTINCT $f4) AS time_dis_count, start('w$) AS window_start, end('w$) AS window_end])
: +- Exchange(distribution=[hash[f_random]])
: +- Calc(select=[f_random, f_sequence, LOCALTIMESTAMP() AS $f4, ts])
: +- WatermarkAssigner(rowtime=[ts], watermark=[ts])
: +- Calc(select=[f_sequence, f_random, LOCALTIMESTAMP() AS ts])
: +- TableSourceScan(table=[[default_catalog, default_database, LEE_KAFKA_02]], fields=[f_sequence, f_random, f_random_str])
+- Exchange(distribution=[hash[col1]])
+- Calc(select=[col1, col2, col3, CAST(col4 AS TIMESTAMP(3)) AS col4])
+- TableSourceScan(table=[[default_catalog, default_database, LEE_KAFKA_01, watermark=[-(col4, 0:INTERVAL SECOND)]]], fields=[col1, col2, col3, col4])
SCHEMA:[TIMESTAMP(3) NOT NULL, TIMESTAMP(3) NOT NULL, INT, INT, TIMESTAMP(3) NOT NULL, BIGINT NOT NULL, BIGINT NOT NULL, BIGINT NOT NULL, STRING, STRING, STRING, TIMESTAMP(3) *ROWTIME*]
SCHEMA FOR JSON: [{"children":[],"conversionClass":"java.time.LocalDateTime","logicalType":{"children":[],"defaultConversion":"java.time.LocalDateTime","kind":"REGULAR","nullable":false,"precision":3,"typeRoot":"TIMESTAMP_WITHOUT_TIME_ZONE"}},{"children":[],"conversionClass":"java.time.LocalDateTime","logicalType":{"children":[],"defaultConversion":"java.time.LocalDateTime","kind":"REGULAR","nullable":false,"precision":3,"typeRoot":"TIMESTAMP_WITHOUT_TIME_ZONE"}},{"children":[],"conversionClass":"java.lang.Integer","logicalType":{"children":[],"defaultConversion":"java.lang.Integer","nullable":true,"typeRoot":"INTEGER"}},{"children":[],"conversionClass":"java.lang.Integer","logicalType":{"children":[],"defaultConversion":"java.lang.Integer","nullable":true,"typeRoot":"INTEGER"}},{"children":[],"conversionClass":"java.time.LocalDateTime","logicalType":{"children":[],"defaultConversion":"java.time.LocalDateTime","kind":"REGULAR","nullable":false,"precision":3,"typeRoot":"TIMESTAMP_WITHOUT_TIME_ZONE"}},{"children":[],"conversionClass":"java.lang.Long","logicalType":{"children":[],"defaultConversion":"java.lang.Long","nullable":false,"typeRoot":"BIGINT"}},{"children":[],"conversionClass":"java.lang.Long","logicalType":{"children":[],"defaultConversion":"java.lang.Long","nullable":false,"typeRoot":"BIGINT"}},{"children":[],"conversionClass":"java.lang.Long","logicalType":{"children":[],"defaultConversion":"java.lang.Long","nullable":false,"typeRoot":"BIGINT"}},{"children":[],"conversionClass":"java.lang.String","logicalType":{"children":[],"defaultConversion":"java.lang.String","length":2147483647,"nullable":true,"typeRoot":"VARCHAR"}},{"children":[],"conversionClass":"java.lang.String","logicalType":{"children":[],"defaultConversion":"java.lang.String","length":2147483647,"nullable":true,"typeRoot":"VARCHAR"}},{"children":[],"conversionClass":"java.lang.String","logicalType":{"children":[],"defaultConversion":"java.lang.String","length":2147483647,"nullable":true,"typeRoot":"VARCHAR"}},{"children":[],"conversionClass":"java.time.LocalDateTime","logicalType":{"children":[],"defaultConversion":"java.time.LocalDateTime","kind":"ROWTIME","nullable":true,"precision":3,"typeRoot":"TIMESTAMP_WITHOUT_TIME_ZONE"}}]
ResultKind: SUCCESS_WITH_CONTENT
ResolvedSchema: (
`window_start` TIMESTAMP(3) NOT NULL,
`window_end` TIMESTAMP(3) NOT NULL,
`f_random` INT,
`s_last` INT,
`m_localtimestamp` TIMESTAMP(3) NOT NULL,
`cnt_total` BIGINT NOT NULL,
`time_dis_count` BIGINT NOT NULL,
`rownum` BIGINT NOT NULL,
`col1` STRING,
`col2` STRING,
`col3` STRING,
`col4` TIMESTAMP(3) *ROWTIME*
)
+----+-------------------------+-------------------------+-------------+-------------+-------------------------+----------------------+----------------------+----------------------+--------------------------------+--------------------------------+--------------------------------+-------------------------+
| op | window_start | window_end | f_random | s_last | m_localtimestamp | cnt_total | time_dis_count | rownum | col1 | col2 | col3 | col4 |
+----+-------------------------+-------------------------+-------------+-------------+-------------------------+----------------------+----------------------+----------------------+--------------------------------+--------------------------------+--------------------------------+-------------------------+
| +I | 2023-03-04 21:21:00.000 | 2023-03-04 21:21:10.000 | 79 | 8824 | 2023-03-04 21:21:09.202 | 94 | 27 | 1 | <NULL> | <NULL> | <NULL> | <NULL> |
| +I | 2023-03-04 21:21:00.000 | 2023-03-04 21:21:10.000 | 48 | 8925 | 2023-03-04 21:21:09.202 | 85 | 25 | 2 | <NULL> | <NULL> | <NULL> | <NULL> |
| +I | 2023-03-04 21:21:00.000 | 2023-03-04 21:21:10.000 | 91 | 8910 | 2023-03-04 21:21:09.202 | 112 | 35 | 3 | <NULL> | <NULL> | <NULL> | <NULL> |
| +I | 2023-03-04 21:21:00.000 | 2023-03-04 21:21:10.000 | 98 | 8885 | 2023-03-04 21:21:09.202 | 91 | 32 | 4 | <NULL> | <NULL> | <NULL> | <NULL> |
| +I | 2023-03-04 21:21:00.000 | 2023-03-04 21:21:10.000 | 52 | 8997 | 2023-03-04 21:21:09.202 | 99 | 35 | 5 | <NULL> | <NULL> | <NULL> | <NULL> |
| +I | 2023-03-04 21:21:00.000 | 2023-03-04 21:21:10.000 | 95 | 8988 | 2023-03-04 21:21:09.202 | 93 | 34 | 6 | <NULL> | <NULL> | <NULL> | <NULL> |
| +I | 2023-03-04 21:21:00.000 | 2023-03-04 21:21:10.000 | 29 | 8948 | 2023-03-04 21:21:09.202 | 96 | 34 | 7 | <NULL> | <NULL> | <NULL> | <NULL> |
| +I | 2023-03-04 21:21:00.000 | 2023-03-04 21:21:10.000 | 64 | 8947 | 2023-03-04 21:21:09.202 | 98 | 32 | 8 | <NULL> | <NULL> | <NULL> | <NULL> |
| +I | 2023-03-04 21:21:00.000 | 2023-03-04 21:21:10.000 | 24 | 8977 | 2023-03-04 21:21:09.202 | 88 | 30 | 9 | <NULL> | <NULL> | <NULL> | <NULL> |查看WEBUI: localhost:9101, 测试和生产环境不能用 localEnv 创建env 对象

总节, 如果需要开发多个的SQL作业,只需要写 conf 文件下下的 basicConf, DDL , DML 或者 DQL 就行了,代码不需要动!控制台输出结果截图如下: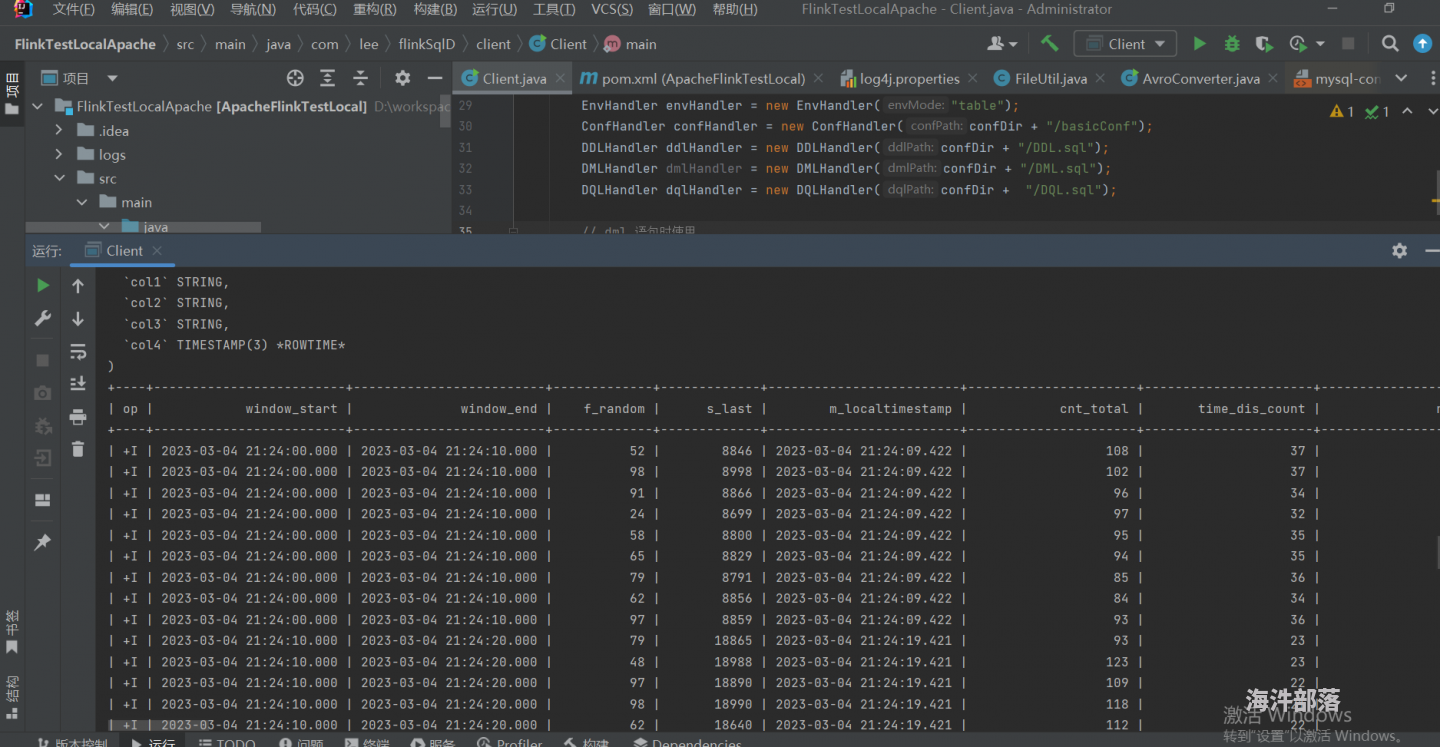
完毕,学废了请收藏把,让你的 SQL 开发如此简单


