对于很多做实时计算云平台开发的企业来讲,FlinkSQL 是绕不开的技术,当然在FlinkSQL的实际使用中,也有很多不尽人意之处,最明显的就是FlinkSQL 无法对TTL进行细粒度设置,这将导致我整个作业都依赖于全局TTL,对于一些大状态的作业比(如包含了多流join, 连接,聚合等算子)十分不友好,Taskmanager cpu和内存使用居高不下,对资源要求极高,此分享就教会大家如何使用 SQL HINT 的写法对 FlinkSQL 中的join算子单独设置左右表TTL
第一步: 由于Flink SQL 默认不支持 join /+ OPTIONS('join.ttl.left'='111s') / 这种写法,所以需要修改Flink SQL 的语法语法解析规则,使其允许 join 后使用 HINT OPTINS,若不需修改, 会报如下错:
我的 DQL :
SELECT a.*,b.* FROM
DATA_GEN_01 a
left join /*+ OPTIONS('join.ttl.left'='111s', 'join.ttl.right'='222s') */
DATA_GEN_02 b
on a.f_sequence = b.f_sequence不修改语法解析规则的报错信息: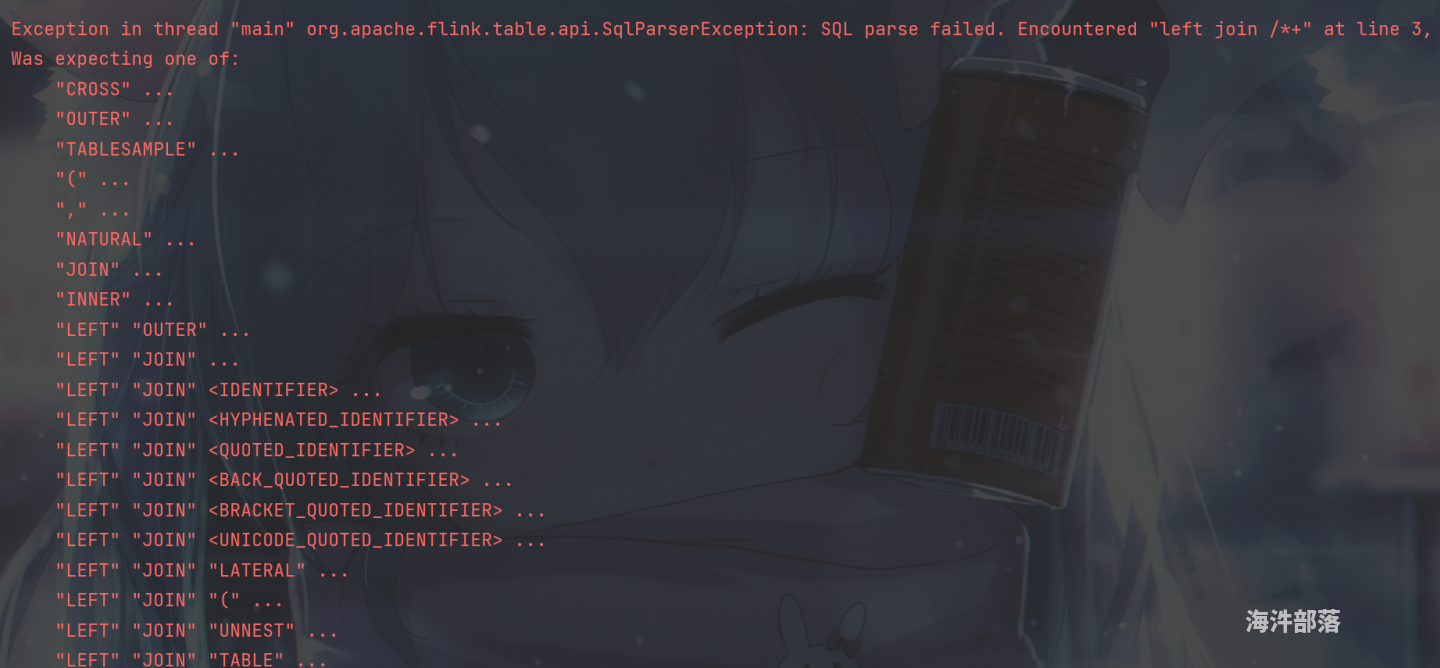
- 首先需要从github拉去源码,打开 flink-sql-parser 工程, 禁用test模块,打包编译也跳过test模块, 再使用 mvn spotless:apply 规范语法格式
- 对Apache Calcite 的 Parser.jj 基础模板文件修改,关于为什么要修改它,读者可以学习一下Apache Calcite框架并了解一下Calcite如何生成AST,也要解一下calcite如何通过FreeMarker及JavaCC自动生成java类,从而灵活构建出符合用户要求的AST抽象语法树,修改Parser.jj的目的是为了生成 org.apache.flink.sql.parser.impl.FlinkSqlParserImpl ,该类是整个Flink进行句法解析的核心类,如果没有Parser.jj 文件也可以直接从hithub/Apache Calcite下载,默认位置是在
- 好了接下来使用文本工具打开Parser.jj 文件,找到 fromClause 句柄,大致在1973行,在jcc的变量区域增加 hints 和 sqlNodeList两个变量,如下图所示:
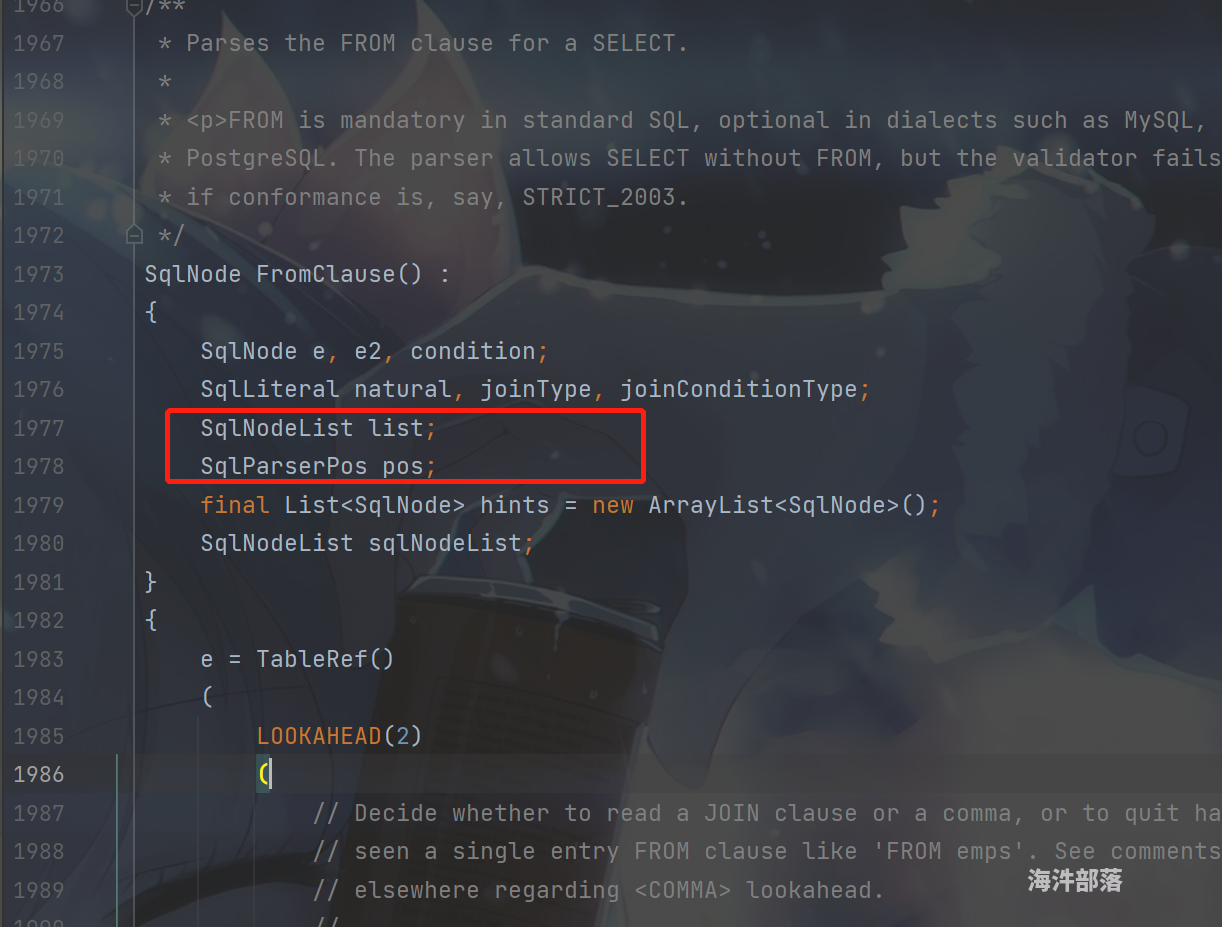
- 在方法体里面增加SQL规则,允许JOIN后写HINT OPTIONS, 其中 CommaSeparatedSqlHint方法是专门处理hint的,然后将处理后的hints 转为 SqlNodeList
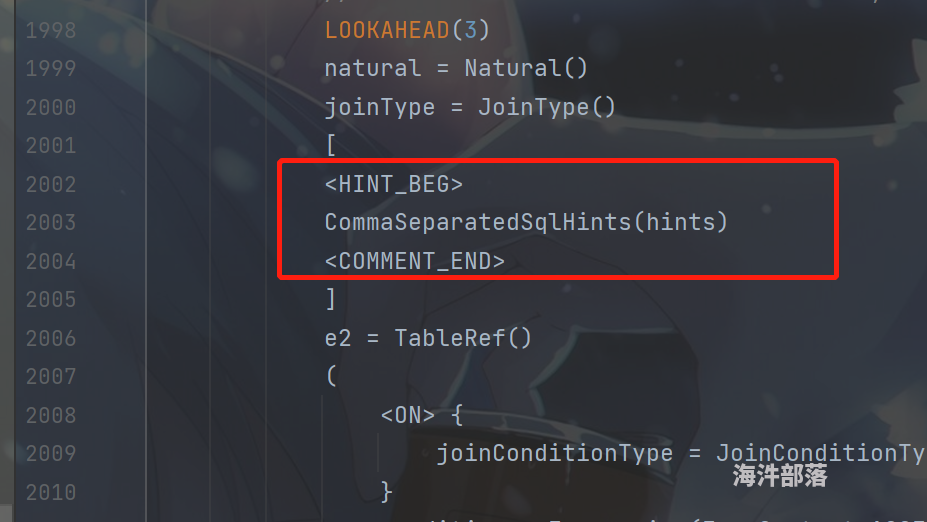
- 将处理后的hints(也就是SqlNodeList) 转为 List 类型并使用一个名字为FlinkSqlJoinWithHints类进行处理,使用该类的时候别忘了在Parser.jj中import该类,该类的主要作用就是讲hints与Join算子的RelNode强绑定,该类具体内容如下:
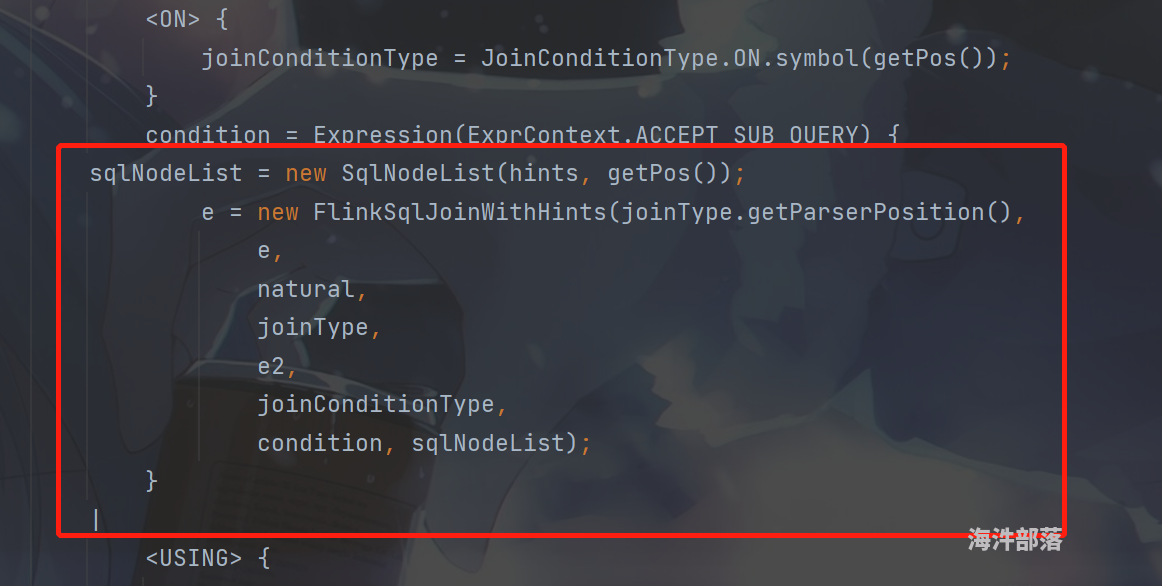
package org.apache.flink.calcite.sql.parser;
import org.apache.calcite.sql.SqlJoin;
import org.apache.calcite.sql.SqlLiteral;
import org.apache.calcite.sql.SqlNode;
import org.apache.calcite.sql.SqlNodeList;
import org.apache.calcite.sql.parser.SqlParserPos;
/** Flink Join with hints. */
public class FlinkSqlJoinWithHints extends SqlJoin {
private final SqlNodeList hints;
/** constructor. */
public FlinkSqlJoinWithHints(
SqlParserPos pos,
SqlNode left,
SqlLiteral natural,
SqlLiteral joinType,
SqlNode right,
SqlLiteral conditionType,
SqlNode condition,
SqlNodeList hints) {
super(pos, left, natural, joinType, right, conditionType, condition);
this.hints = hints;
}
/** get Sql hints. */
public SqlNodeList getHints() {
return hints;
}
}- 一切准备就绪,开始编译flink-sql-parser,需要先安装JavaCC和 FreeMarker 插件,若直接编译,FreeMarker会先先根据 基础的Parser.jj以及 config.fmpp文件以及data和include的文件生成一个Flink版的Parser.jj 文件,这一点就体现出了Apache Calcite框架的魅力:插件化,可插拔,具体想了解calcite如何生成AST(抽象语法树)以及JavaCC编辑机语法规则和原理可以参考 https://liebing.org.cn/collections/calcite/

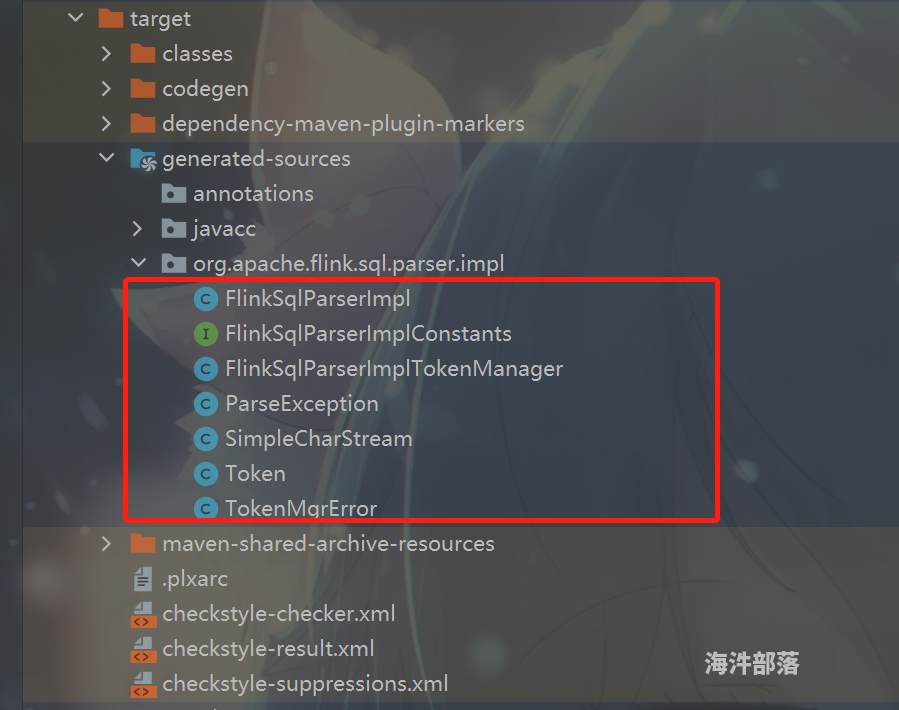
- 编译之后会生成一系列java文件,在target目录下, 其中也包含了我们最想要的FlinkSqlParserImpl.java, 如图:
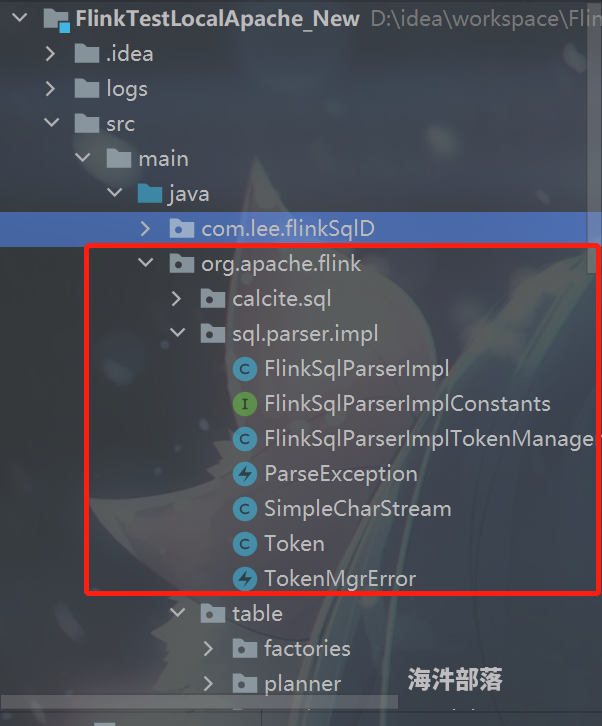
- 将这些新文件替换掉你的CLASSPATH里面本身就已经存在的文件,这里直接在项目里把包名类名写成与二进制jar中的完全一致就行了,java的类加载机制会让用户的代码程序覆盖掉CLASSPATH中的二进制文件代码,参考如图:
-
至此,我们已经完成了Sql解析部分的工作, 可能有读者会问,为什么非要在JOIN后面加HINTS语法呢,为什么不直接在表名后面写HINT,并且表名后写HINT官方也是支持的,我说一下原因:
- 我们的目的将HINTS与JOIN 算子强绑定,如果写在表名后面,那相当于该HINTS就是表属性的配置项,我们并不清楚该表都参与了哪些算子,哪些JOIN算子是我们想要的,自然而然就难以通过JOIN算子设置该表的在当前JOIN算子的TTL
- 若直接写在表名后面,当一个作业有多个JOIN算子时,就需要判断某个JOIN算子状态的左右表具体是哪两张表,再取出该表的HINTS 来设置TTL,这样不但难度较大,而且用户在开发作业时也不好控制这张表具体参与了哪些JOIN算子,哪些算子需要设置多久的TTL, 因此直接将HINT与JOIN算子绑定,该问题就会迎刃而解
-
当SQL解析不再报错了,然后再添加SQLhints校验的逻辑,用于验证用户输入的hints是否符合规范,这里我直接新写了一个scala对象:HintExtractorUtil.scala,读者可以直接将其写在JoinUtil中:
package org.apache.flink.table.planner.utils import org.apache.calcite.plan.RelOptUtil import org.apache.calcite.rel.RelNode import org.apache.calcite.rel.hint.Hintable import org.apache.calcite.sql.SqlExplainLevel import java.util import scala.collection.JavaConverters.{asScalaBufferConverter, mapAsJavaMapConverter} import scala.collection.mutable.ArrayBuffer import scala.util.matching.Regex import scala.xml.dtd.ValidationException object HintExtractorUtil extends Logging { val JOIN_TTL_LEFT: String = InternalConfigOptions.TABLE_EXEC_JOIN_STATE_TTL_LEFT.key() val JOIN_TTL_RIGHT: String = InternalConfigOptions.TABLE_EXEC_JOIN_STATE_TTL_RIGHT.key() // 直接将RelNode Dump 成字符串,然后正则解析 def validateJoinHints(inputNode: RelNode): ArrayBuffer[util.Map[String, String]] = { val planStrings: String = RelOptUtil dumpPlan("", inputNode, false, SqlExplainLevel.EXPPLAN_ATTRIBUTES) LOG.info("dump plan strings : --> \n" + planStrings) val optionsPattern = """options:\{(.+?)\}""".r val keyValuePattern = """([\w\.]+)=([\w\.]+)""".r val optionsContent = optionsPattern.findFirstMatchIn(planStrings) match { case Some(m) => m.group(1) case None => "" } val resultScalaMap = keyValuePattern.findAllIn(optionsContent).matchData.map { case Regex.Groups(key, value) => key -> value }.toMap LOG.info("capture the hint map --> " + resultScalaMap) resultScalaMap .filter(f => f._1.startsWith("join")) .foreach(m => { m._1 match { case JOIN_TTL_LEFT => LOG.info(s"Join option hint: ${m._1} has matched!") case JOIN_TTL_RIGHT => LOG.info(s"Join option hint: ${m._1} has matched!") case _ => throw ValidationException(s"Invalid hint OPTIONS key: '${m._1}'" + s", support OPTIONS are: \n\t\t'$JOIN_TTL_LEFT'\n\t\t'$JOIN_TTL_RIGHT'") } }) ArrayBuffer.empty[util.Map[String, String]] += (resultScalaMap.asJava) } // 递归从calcite:RelNode 解析获得hint, 原始代码 def getJoinHintsOld(inputNode: Any, acceptedHints: ArrayBuffer[util.Map[String, String]]): ArrayBuffer[util.Map[String, String]] = { inputNode match { // LogicalProject, TableSan case nodeWithHints: RelNode with Hintable => if (nodeWithHints.getHints.size() > 0) { nodeWithHints.getHints.forEach(hint => { acceptedHints += hint.kvOptions }) } if (nodeWithHints.getInputs.size() > 0) { nodeWithHints.getInputs.forEach(in => { getJoinHints(in, acceptedHints) }) } acceptedHints // regular RelNode without hints attr case inputRelNode: RelNode => inputRelNode.getInputs.forEach(in => { if (in.getInputs.size() > 0) getJoinHints(in, acceptedHints) }) acceptedHints case _ => throw new UnknownError("Unknown type of class: " + inputNode.getClass) } } // 递归从calcite:RelNode 解析获得hint, 原始代码优化后的代码 def getJoinHints(inputNode: Any, acceptedHints: ArrayBuffer[util.Map[String, String]]): ArrayBuffer[util.Map[String, String]] = { inputNode match { // LogicalProject, TableSan branches case nodeWithHints: RelNode with Hintable => acceptedHints ++= nodeWithHints.getHints.asScala.map(_.kvOptions) nodeWithHints.getInputs.asScala.foreach(getJoinHints(_, acceptedHints)) LOG.info(s"Current RelNode is ${nodeWithHints.getClass.toString}, " + s"current captured Hints : ${nodeWithHints.getHints.toArray().mkString("Array(", ", ", ")")}") acceptedHints // regular RelNode without hints attr branches case inputRelNode: RelNode => inputRelNode.getInputs.asScala.foreach(getJoinHints(_, acceptedHints)) acceptedHints case _ => throw new UnknownError("Unknown type of class: " + inputNode.getClass) } } } class HintExtractorUtil -
修改 org.apache.flink.table.planner.utils.InternalConfigOptions, 新增左右表JOIN的ConfigOption:
/* * Licensed to the Apache Software Foundation (ASF) under one * or more contributor license agreements. See the NOTICE file * distributed with this work for additional information * regarding copyright ownership. The ASF licenses this file * to you under the Apache License, Version 2.0 (the * "License"); you may not use this file except in compliance * with the License. You may obtain a copy of the License at * * http://www.apache.org/licenses/LICENSE-2.0 * * Unless required by applicable law or agreed to in writing, software * distributed under the License is distributed on an "AS IS" BASIS, * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. * See the License for the specific language governing permissions and * limitations under the License. */ package org.apache.flink.table.planner.utils; import org.apache.flink.annotation.Experimental; import org.apache.flink.annotation.Internal; import org.apache.flink.configuration.ConfigOption; import org.apache.flink.configuration.ConfigOptions; import java.time.Duration; import static org.apache.flink.configuration.ConfigOptions.key; /** * This class holds internal configuration constants used by Flink's table module. * * <p>NOTE: All option keys in this class must start with "__" and end up with "__", and all options * shouldn't expose to users, all options should erase after plan finished. */ @Internal public class InternalConfigOptions { // org.apache.flink.table.planner.utils.InternalConfigOptions // org.apache.flink.table.planner.utils.InternalConfigOptions public static final ConfigOption<Long> TABLE_QUERY_START_EPOCH_TIME = key("__table.query-start.epoch-time__") .longType() .noDefaultValue() .withDescription( "The config used to save the epoch time at query start, this config will be" + " used by some temporal functions like CURRENT_TIMESTAMP in batch job to make sure" + " these temporal functions has query-start semantics."); public static final ConfigOption<Long> TABLE_QUERY_START_LOCAL_TIME = key("__table.query-start.local-time__") .longType() .noDefaultValue() .withDescription( "The config used to save the local timestamp at query start, the timestamp value is stored" + " as UTC+0 milliseconds since epoch for simplification, this config will be used by" + " some temporal functions like LOCAL_TIMESTAMP in batch job to make sure these" + " temporal functions has query-start semantics."); @Experimental public static final ConfigOption<Boolean> TABLE_EXEC_NON_TEMPORAL_SORT_ENABLED = key("__table.exec.sort.non-temporal.enabled__") .booleanType() .defaultValue(false) .withDescription( "Set whether to enable universal sort for streaming. When false, " + "universal sort can't be used for streaming. Currently, it's " + "used using only for testing, to help verify that streaming " + "SQL can generate the same result (with changelog events) " + "as batch SQL."); // new add : leftTtl and rightTtl public static final ConfigOption<Duration> TABLE_EXEC_JOIN_STATE_TTL_LEFT = ConfigOptions .key("join.ttl.left"). durationType().defaultValue(Duration.ofSeconds(0)) .withDescription("the left table of join ttl, only used by hints of k-v options"); public static final ConfigOption<Duration> TABLE_EXEC_JOIN_STATE_TTL_RIGHT = ConfigOptions. key("join.ttl.right") .durationType() .defaultValue(Duration.ofSeconds(0)) .withDescription("the right table of join ttl, only used by hints of k-v options"); }12.修改plannerBase代码, 在SQL 转为了 modifiedOperations 后将校验规则代码加进去,直接将calciteTree 的根节点的RelNode传入,主要修改的代码块为:
override def translate( modifyOperations: util.List[ModifyOperation]): util.List[Transformation[_]] = { hintInternalHelper(modifyOperations) beforeTranslation() if (modifyOperations.isEmpty) { return List.empty[Transformation[_]] } val relNodes = modifyOperations.map(translateToRel) val optimizedRelNodes = optimize(relNodes) val execGraph = translateToExecNodeGraph(optimizedRelNodes, isCompiled = false) val transformations = translateToPlan(execGraph) afterTranslation() transformations } def hintInternalHelper[T <: Operation](modifyOperations: util.List[T]): Unit = { modifyOperations.stream().forEach(op => { val queryOperation: QueryOperation = op match { case op: ModifyOperation => op.getChild case qo: QueryOperation => qo case _ => throw new ClassCastException("Unknown operation -> " + modifyOperations.getClass) } if (!queryOperation.isInstanceOf[PlannerQueryOperation]) { throw new ClassCastException(s"current Modified Operation[${queryOperation.getClass}] is not the PlannerQueryOperation!") } val calciteTree: RelNode = queryOperation.asInstanceOf[PlannerQueryOperation].getCalciteTree // validate and Obtains hints for hole job HintExtractorUtil.validateJoinHints(calciteTree) }) } -
校验结果如下:

-
在AST抽象语法树生成了之后,会进入 SqlNode 到 RelNode 的转化,我们再自定义一个类 FlinkSqlToRelConverter 继承自 SqlToRelConverter, 主要修改点在于 转换from语句的SqlNode到RelNode的时候会解析Hints, 然后将HINT 绑定到 JOIN 算子的 RelNode 上面,代码比较简单,如下:
package org.apache.flink.calcite.sql.converter; import org.apache.calcite.plan.RelOptCluster; import org.apache.calcite.plan.RelOptTable; import org.apache.calcite.prepare.Prepare; import org.apache.calcite.rel.hint.RelHint; import org.apache.calcite.rel.logical.LogicalJoin; import org.apache.calcite.rel.type.RelDataType; import org.apache.calcite.rel.type.RelDataTypeField; import org.apache.calcite.sql.SqlIdentifier; import org.apache.calcite.sql.SqlNode; import org.apache.calcite.sql.SqlSelect; import org.apache.calcite.sql.SqlUtil; import org.apache.calcite.sql.validate.SqlNameMatcher; import org.apache.calcite.sql.validate.SqlValidator; import org.apache.calcite.sql2rel.SqlRexConvertletTable; import org.apache.calcite.sql2rel.SqlToRelConverter; import org.apache.calcite.util.Static; import org.apache.flink.calcite.sql.parser.FlinkSqlJoinWithHints; import scala.collection.Traversable; import scala.collection.TraversableOnce; import scala.runtime.BoxedUnit; import scala.runtime.BoxesRunTime; import scala.runtime.NonLocalReturnControl; import java.util.List; public class FlinkSqlToRelConverter extends SqlToRelConverter { private final Config config; private final SqlValidator validator; public FlinkSqlToRelConverter(RelOptTable.ViewExpander viewExpander, SqlValidator validator, Prepare.CatalogReader catalogReader, RelOptCluster cluster, SqlRexConvertletTable convertletTable, Config config) { super(viewExpander, validator, catalogReader, cluster, convertletTable, config); this.config = config; this.validator = validator; } public void convertFrom(final Blackboard bb, final SqlNode from, final List<String> fieldNames) { super.convertFrom(bb, from, fieldNames); if (from instanceof FlinkSqlJoinWithHints && bb.root instanceof LogicalJoin) { List<RelHint> hints = SqlUtil.getRelHint(this.config.getHintStrategyTable(), ((FlinkSqlJoinWithHints) from).getHints()); bb.root = ((LogicalJoin) bb.root).withHints(hints); } } }sqlToRelConverter 的实例化工作主要是在 FlinkPlannerImpl 类中,这里由于我们用的是 FlinkSqlToRelConverter, 因此需要修改 createSqlToRelConverter 方法:
private def createSqlToRelConverter(sqlValidator: SqlValidator): SqlToRelConverter = { new FlinkSqlToRelConverter( createToRelContext(), sqlValidator, sqlValidator.getCatalogReader.unwrap(classOf[CalciteCatalogReader]), cluster, convertletTable, sqlToRelConverterConfig) } -
当转换为RelNode 完成了,我们的Hints 也转为了 RelHint 对象,实际上还是RelNode, 接下来就到了 RelNode 到 逻辑执行计划的转换阶段,再次之前,需要先进入optimize方法对RelNode进行优化,这里使用的Calcite基于代价优化的火山引擎(阿里开发),在优化阶段,会对每个RelNode都进行11中规则的耗时预计算,期间会频繁调用GET方法来获取JOIN时的HINT,最终再生成一个FlinkLogicalJoin的RelNode对象,,因此我们需要将 FlinkLogicalJoin 中的Hints信息同步到其父类(JOIN)中去,否则在优化后的逻辑执行计划中会丢失HINTS信息,这里不再赘述,直接看如何修改FlinkLogicalJoin:
package org.apache.flink.table.planner.plan.nodes.logical import org.apache.flink.table.planner.plan.nodes.FlinkConventions import org.apache.calcite.plan._ import org.apache.calcite.rel.RelNode import org.apache.calcite.rel.convert.ConverterRule import org.apache.calcite.rel.core.{CorrelationId, Join, JoinRelType} import org.apache.calcite.rel.hint.RelHint import org.apache.calcite.rel.logical.LogicalJoin import org.apache.calcite.rel.metadata.RelMetadataQuery import org.apache.calcite.rex.RexNode import org.apache.flink.calcite.shaded.com.google.common.collect.ImmutableList import java.util.Collections import scala.collection.JavaConversions._ class FlinkLogicalJoin( cluster: RelOptCluster, traitSet: RelTraitSet, hints: ImmutableList[RelHint], left: RelNode, right: RelNode, condition: RexNode, joinType: JoinRelType) extends Join( cluster, traitSet, // 1.16版本支持了select后面的hint写法, 需要将所有join和select的所有hint合并再传递给父类 hints ++= Collections.emptyList[RelHint](), left, right, condition, Set.empty[CorrelationId], joinType) with FlinkLogicalRel { override def copy( traitSet: RelTraitSet, conditionExpr: RexNode, left: RelNode, right: RelNode, joinType: JoinRelType, semiJoinDone: Boolean): Join = { new FlinkLogicalJoin(cluster, traitSet, hints, left, right, conditionExpr, joinType) } override def computeSelfCost(planner: RelOptPlanner, mq: RelMetadataQuery): RelOptCost = { val leftRowCnt = mq.getRowCount(getLeft) val leftRowSize = mq.getAverageRowSize(getLeft) val rightRowCnt = mq.getRowCount(getRight) joinType match { case JoinRelType.SEMI | JoinRelType.ANTI => val rightRowSize = mq.getAverageRowSize(getRight) val ioCost = (leftRowCnt * leftRowSize) + (rightRowCnt * rightRowSize) val cpuCost = leftRowCnt + rightRowCnt val rowCnt = leftRowCnt + rightRowCnt planner.getCostFactory.makeCost(rowCnt, cpuCost, ioCost) case _ => val cpuCost = leftRowCnt + rightRowCnt val ioCost = (leftRowCnt * leftRowSize) + rightRowCnt planner.getCostFactory.makeCost(leftRowCnt, cpuCost, ioCost) } } } /** Support all joins. */ private class FlinkLogicalJoinConverter extends ConverterRule( classOf[LogicalJoin], Convention.NONE, FlinkConventions.LOGICAL, "FlinkLogicalJoinConverter") { override def convert(rel: RelNode): RelNode = { val join = rel.asInstanceOf[LogicalJoin] val hints = join.getHints val newLeft = RelOptRule.convert(join.getLeft, FlinkConventions.LOGICAL) val newRight = RelOptRule.convert(join.getRight, FlinkConventions.LOGICAL) FlinkLogicalJoin.create(newLeft, newRight, hints, join.getCondition, join.getJoinType) } } object FlinkLogicalJoin { val CONVERTER: ConverterRule = new FlinkLogicalJoinConverter def create( left: RelNode, right: RelNode, hints: ImmutableList[RelHint], conditionExpr: RexNode, joinType: JoinRelType): FlinkLogicalJoin = { val cluster = left.getCluster val traitSet = cluster.traitSetOf(FlinkConventions.LOGICAL).simplify() new FlinkLogicalJoin(cluster, traitSet, hints, left, right, conditionExpr, joinType) } } -
由于 FlinkLogicalJoin.scala中修改了构造器,所以用到该类其他类也要做相应的修改,这里需要 RelTimeIndicatorConverter的visitJoin方法:
private RelNode visitJoin(FlinkLogicalJoin join) { RelNode newLeft = join.getLeft().accept(this); RelNode newRight = join.getRight().accept(this); int leftFieldCount = newLeft.getRowType().getFieldCount(); // temporal table join if (TemporalJoinUtil.satisfyTemporalJoin(join, newLeft, newRight)) { RelNode rewrittenTemporalJoin = join.copy( join.getTraitSet(), join.getCondition(), newLeft, newRight, join.getJoinType(), join.isSemiJoinDone()); // Materialize all of the time attributes from the right side of temporal join Set<Integer> rightIndices = IntStream.range(0, newRight.getRowType().getFieldCount()) .mapToObj(startIdx -> leftFieldCount + startIdx) .collect(Collectors.toSet()); return createCalcToMaterializeTimeIndicators(rewrittenTemporalJoin, rightIndices); } else { if (JoinUtil.satisfyRegularJoin(join, newLeft, newRight)) { // materialize time attribute fields of regular join's inputs newLeft = materializeTimeIndicators(newLeft); newRight = materializeTimeIndicators(newRight); } List<RelDataTypeField> leftRightFields = new ArrayList<>(); leftRightFields.addAll(newLeft.getRowType().getFieldList()); leftRightFields.addAll(newRight.getRowType().getFieldList()); RexNode newCondition = join.getCondition() .accept( new RexShuttle() { @Override public RexNode visitInputRef(RexInputRef inputRef) { if (isTimeIndicatorType(inputRef.getType())) { return RexInputRef.of( inputRef.getIndex(), leftRightFields); } else { return super.visitInputRef(inputRef); } } }); // 在此处添加table 的 hints options, return FlinkLogicalJoin.create(newLeft, newRight, join.getHints(), newCondition, join.getJoinType()); } } - 接下来,将优化后的逻辑执行计划转为物理执行计划,这里的JOIN代码体现在 FlinkLogicalJoin 到 FlinkPhysicalJoin的转换,在 StreamPhysicalJoinRuleBase 中完成了初始化工作,在 StreamPhysicalJoinRule 中完成 FlinkPhysicalJoin 实例化工作, 我们需要将HINT信息传递给 FlinkPhysicalJoin, 首先,需要先修改 StreamPhysicalJoinRule, 修改部分的代码如下:
override protected def transform( join: FlinkLogicalJoin, leftInput: FlinkRelNode, leftConversion: RelNode => RelNode, rightInput: FlinkRelNode, rightConversion: RelNode => RelNode, providedTraitSet: RelTraitSet): FlinkRelNode = { new StreamPhysicalJoin( join.getCluster, providedTraitSet, join.getHints, leftConversion(leftInput), rightConversion(rightInput), join.getCondition, join.getJoinType) } -
接下来修改 StreamPhysicalJoin,这是JOIN算子如何进行物理执行的总控类,修改的要点主要是捕获HINTS信息,将其传递给 StreamExecJoin, 直接参考代码:
/* * Licensed to the Apache Software Foundation (ASF) under one * or more contributor license agreements. See the NOTICE file * distributed with this work for additional information * regarding copyright ownership. The ASF licenses this file * to you under the Apache License, Version 2.0 (the * "License"); you may not use this file except in compliance * with the License. You may obtain a copy of the License at * * http://www.apache.org/licenses/LICENSE-2.0 * * Unless required by applicable law or agreed to in writing, software * distributed under the License is distributed on an "AS IS" BASIS, * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. * See the License for the specific language governing permissions and * limitations under the License. */ package org.apache.flink.table.planner.plan.nodes.physical.stream import org.apache.flink.table.planner.calcite.FlinkTypeFactory import org.apache.flink.table.planner.plan.metadata.FlinkRelMetadataQuery import org.apache.flink.table.planner.plan.nodes.exec.{ExecNode, InputProperty} import org.apache.flink.table.planner.plan.nodes.exec.stream.StreamExecJoin import org.apache.flink.table.planner.plan.nodes.physical.common.CommonPhysicalJoin import org.apache.flink.table.planner.plan.utils.JoinUtil import org.apache.flink.table.planner.utils.ShortcutUtils.unwrapTableConfig import org.apache.flink.table.runtime.typeutils.InternalTypeInfo import org.apache.calcite.plan._ import org.apache.calcite.rel.{RelNode, RelWriter} import org.apache.calcite.rel.core.{Join, JoinRelType} import org.apache.calcite.rel.hint.RelHint import org.apache.calcite.rel.metadata.RelMetadataQuery import org.apache.calcite.rex.RexNode import org.apache.flink.calcite.shaded.com.google.common.collect.ImmutableList import org.apache.flink.configuration.{ConfigOption, ReadableConfig} import org.apache.flink.table.api.config.ExecutionConfigOptions import org.apache.flink.table.planner.utils.{HintExtractorUtil, InternalConfigOptions} import java.time.Duration import java.util import scala.collection.JavaConversions._ import scala.runtime.NonLocalReturnControl /** * Stream physical RelNode for regular [[Join]]. * * Regular joins are the most generic type of join in which any new records or changes to either * side of the join input are visible and are affecting the whole join result. */ class StreamPhysicalJoin( cluster: RelOptCluster, traitSet: RelTraitSet, hints: ImmutableList[RelHint], leftRel: RelNode, rightRel: RelNode, condition: RexNode, joinType: JoinRelType) extends CommonPhysicalJoin(cluster, traitSet, leftRel, rightRel, condition, joinType) with StreamPhysicalRel { /** * This is mainly used in `FlinkChangelogModeInferenceProgram.SatisfyUpdateKindTraitVisitor`. If * the unique key of input contains join key, then it can support ignoring UPDATE_BEFORE. * Otherwise, it can't ignore UPDATE_BEFORE. For example, if the input schema is [id, name, cnt] * with the unique key (id). The join key is (id, name), then an insert and update on the id: * * +I(1001, Tim, 10) * -U(1001, Tim, 10) +U(1001, Timo, 11) * * If the UPDATE_BEFORE is ignored, the `+I(1001, Tim, 10)` record in join will never be * retracted. Therefore, if we want to ignore UPDATE_BEFORE, the unique key must contain join key. * * @see * FlinkChangelogModeInferenceProgram */ def inputUniqueKeyContainsJoinKey(inputOrdinal: Int): Boolean = { val input = getInput(inputOrdinal) val joinKeys = if (inputOrdinal == 0) joinSpec.getLeftKeys else joinSpec.getRightKeys val inputUniqueKeys = getUniqueKeys(input, joinKeys) if (inputUniqueKeys != null) { inputUniqueKeys.exists(uniqueKey => joinKeys.forall(uniqueKey.contains(_))) } else { false } } override def requireWatermark: Boolean = false override def copy( traitSet: RelTraitSet, conditionExpr: RexNode, left: RelNode, right: RelNode, joinType: JoinRelType, semiJoinDone: Boolean): Join = { new StreamPhysicalJoin(cluster, traitSet, hints, left, right, conditionExpr, joinType) } override def explainTerms(pw: RelWriter): RelWriter = { super .explainTerms(pw) .item( "leftInputSpec", JoinUtil.analyzeJoinInput( InternalTypeInfo.of(FlinkTypeFactory.toLogicalRowType(left.getRowType)), joinSpec.getLeftKeys, getUniqueKeys(left, joinSpec.getLeftKeys)) ) .item( "rightInputSpec", JoinUtil.analyzeJoinInput( InternalTypeInfo.of(FlinkTypeFactory.toLogicalRowType(right.getRowType)), joinSpec.getRightKeys, getUniqueKeys(right, joinSpec.getRightKeys)) ) } private def getUniqueKeys(input: RelNode, keys: Array[Int]): List[Array[Int]] = { val upsertKeys = FlinkRelMetadataQuery .reuseOrCreate(cluster.getMetadataQuery) .getUpsertKeysInKeyGroupRange(input, keys) if (upsertKeys == null || upsertKeys.isEmpty) { List.empty } else { upsertKeys.map(_.asList.map(_.intValue).toArray).toList } } override def computeSelfCost(planner: RelOptPlanner, metadata: RelMetadataQuery): RelOptCost = { val elementRate = 100.0d * 2 // two input stream planner.getCostFactory.makeCost(elementRate, elementRate, 0) } /** * todo * 是 */ override def translateToExecNode(): ExecNode[_] = { new StreamExecJoin( unwrapTableConfig(this), joinSpec, getUniqueKeys(left, joinSpec.getLeftKeys), getUniqueKeys(right, joinSpec.getRightKeys), InputProperty.DEFAULT, InputProperty.DEFAULT, FlinkTypeFactory.toLogicalRowType(getRowType), getRelDetailedDescription, getStateTimeToLive(unwrapTableConfig(this), InternalConfigOptions.TABLE_EXEC_JOIN_STATE_TTL_LEFT), getStateTimeToLive(unwrapTableConfig(this), InternalConfigOptions.TABLE_EXEC_JOIN_STATE_TTL_RIGHT) ) } /** * created by lijun */ def getStateTimeToLive(readableConf: ReadableConfig, configOption: ConfigOption[Duration]): Duration = { var ttlSeconds: Duration = Duration.ofSeconds(0) try { this.hints.forEach(hint => { val options: util.Map[String, String] = hint.kvOptions if (hint.kvOptions.containsKey(configOption.key())) ttlSeconds = Duration.ofSeconds(options.get(configOption.key()).toLowerCase.replaceAll("s", "").toInt) else ttlSeconds = readableConf.get(ExecutionConfigOptions.IDLE_STATE_RETENTION) }) } catch { case exp: NonLocalReturnControl[_] => if (exp.key != AnyRef) throw exp ttlSeconds = exp.value.asInstanceOf[Duration] } ttlSeconds } } -
然后进入到 flink的JobExecGraph的 transformations 构建阶段,这里指的是 StreamExecJoin 类,我们在此类中将捕获到的HINTS信息再次传递给具体的JOIN算子(StreamingJoinOperator),StreamExecJoin的修改后代码如下:
/* * Licensed to the Apache Software Foundation (ASF) under one * or more contributor license agreements. See the NOTICE file * distributed with this work for additional information * regarding copyright ownership. The ASF licenses this file * to you under the Apache License, Version 2.0 (the * "License"); you may not use this file except in compliance * with the License. You may obtain a copy of the License at * * http://www.apache.org/licenses/LICENSE-2.0 * * Unless required by applicable law or agreed to in writing, software * distributed under the License is distributed on an "AS IS" BASIS, * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. * See the License for the specific language governing permissions and * limitations under the License. * */ package org.apache.flink.table.planner.plan.nodes.exec.stream; import com.lee.flinkSqlD.client.Client; import org.apache.flink.FlinkVersion; import org.apache.flink.api.dag.Transformation; import org.apache.flink.configuration.ReadableConfig; import org.apache.flink.streaming.api.transformations.TwoInputTransformation; import org.apache.flink.table.data.RowData; import org.apache.flink.table.planner.delegation.PlannerBase; import org.apache.flink.table.planner.plan.nodes.exec.ExecEdge; import org.apache.flink.table.planner.plan.nodes.exec.ExecNodeBase; import org.apache.flink.table.planner.plan.nodes.exec.ExecNodeConfig; import org.apache.flink.table.planner.plan.nodes.exec.ExecNodeContext; import org.apache.flink.table.planner.plan.nodes.exec.ExecNodeMetadata; import org.apache.flink.table.planner.plan.nodes.exec.InputProperty; import org.apache.flink.table.planner.plan.nodes.exec.SingleTransformationTranslator; import org.apache.flink.table.planner.plan.nodes.exec.spec.JoinSpec; import org.apache.flink.table.planner.plan.nodes.exec.utils.ExecNodeUtil; import org.apache.flink.table.planner.plan.utils.JoinUtil; import org.apache.flink.table.planner.plan.utils.KeySelectorUtil; import org.apache.flink.table.runtime.generated.GeneratedJoinCondition; import org.apache.flink.table.runtime.keyselector.RowDataKeySelector; import org.apache.flink.table.runtime.operators.join.FlinkJoinType; import org.apache.flink.table.runtime.operators.join.stream.AbstractStreamingJoinOperator; import org.apache.flink.table.runtime.operators.join.stream.StreamingJoinOperator; import org.apache.flink.table.runtime.operators.join.stream.StreamingSemiAntiJoinOperator; import org.apache.flink.table.runtime.operators.join.stream.state.JoinInputSideSpec; import org.apache.flink.table.runtime.typeutils.InternalTypeInfo; import org.apache.flink.table.types.logical.RowType; import org.apache.flink.shaded.guava30.com.google.common.collect.Lists; import org.apache.flink.shaded.jackson2.com.fasterxml.jackson.annotation.JsonCreator; import org.apache.flink.shaded.jackson2.com.fasterxml.jackson.annotation.JsonProperty; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import java.time.Duration; import java.util.List; import static org.apache.flink.util.Preconditions.checkArgument; import static org.apache.flink.util.Preconditions.checkNotNull; /** * {@link StreamExecNode} for regular Joins. * * <p>Regular joins are the most generic type of join in which any new records or changes to either * side of the join input are visible and are affecting the whole join result. */ @ExecNodeMetadata( name = "stream-exec-join", version = 1, producedTransformations = StreamExecJoin.JOIN_TRANSFORMATION, minPlanVersion = FlinkVersion.v1_15, minStateVersion = FlinkVersion.v1_15) public class StreamExecJoin extends ExecNodeBase<RowData> implements StreamExecNode<RowData>, SingleTransformationTranslator<RowData> { private static final Logger LOGGER = LoggerFactory.getLogger(StreamExecJoin.class); public static final String JOIN_TRANSFORMATION = "join"; public static final String FIELD_NAME_JOIN_SPEC = "joinSpec"; public static final String FIELD_NAME_LEFT_UNIQUE_KEYS = "leftUniqueKeys"; public static final String FIELD_NAME_RIGHT_UNIQUE_KEYS = "rightUniqueKeys"; public static final String FILED_NAME_LEFT_STATE_RETENTION_TIME = "leftStateRetentionTime"; public static final String FILED_NAME_RIGHT_STATE_RETENTION_TIME = "rightStateRetentionTime"; @JsonProperty(FIELD_NAME_JOIN_SPEC) private final JoinSpec joinSpec; @JsonProperty(FIELD_NAME_LEFT_UNIQUE_KEYS) private final List<int[]> leftUniqueKeys; @JsonProperty(FIELD_NAME_RIGHT_UNIQUE_KEYS) private final List<int[]> rightUniqueKeys; @JsonProperty(FILED_NAME_LEFT_STATE_RETENTION_TIME) private long leftTtl; @JsonProperty(FILED_NAME_RIGHT_STATE_RETENTION_TIME) private long rightTtl; public StreamExecJoin( ReadableConfig tableConfig, JoinSpec joinSpec, List<int[]> leftUniqueKeys, List<int[]> rightUniqueKeys, InputProperty leftInputProperty, InputProperty rightInputProperty, RowType outputType, String description, Duration leftRetentionTime, Duration rightRetentionTime ) { this( ExecNodeContext.newNodeId(), ExecNodeContext.newContext(StreamExecJoin.class), ExecNodeContext.newPersistedConfig(StreamExecJoin.class, tableConfig), joinSpec, leftUniqueKeys, rightUniqueKeys, Lists.newArrayList(leftInputProperty, rightInputProperty), outputType, description, leftRetentionTime.toMillis(), rightRetentionTime.toMillis()); } @JsonCreator public StreamExecJoin( @JsonProperty(FIELD_NAME_ID) int id, @JsonProperty(FIELD_NAME_TYPE) ExecNodeContext context, @JsonProperty(FIELD_NAME_CONFIGURATION) ReadableConfig persistedConfig, @JsonProperty(FIELD_NAME_JOIN_SPEC) JoinSpec joinSpec, @JsonProperty(FIELD_NAME_LEFT_UNIQUE_KEYS) List<int[]> leftUniqueKeys, @JsonProperty(FIELD_NAME_RIGHT_UNIQUE_KEYS) List<int[]> rightUniqueKeys, @JsonProperty(FIELD_NAME_INPUT_PROPERTIES) List<InputProperty> inputProperties, @JsonProperty(FIELD_NAME_OUTPUT_TYPE) RowType outputType, @JsonProperty(FIELD_NAME_DESCRIPTION) String description, @JsonProperty(FILED_NAME_LEFT_STATE_RETENTION_TIME) long leftTtl, @JsonProperty(FILED_NAME_RIGHT_STATE_RETENTION_TIME) long rightTtl) { super(id, context, persistedConfig, inputProperties, outputType, description); checkArgument(inputProperties.size() == 2); this.joinSpec = checkNotNull(joinSpec); this.leftUniqueKeys = leftUniqueKeys; this.rightUniqueKeys = rightUniqueKeys; this.leftTtl = leftTtl; this.rightTtl = rightTtl; } @Override @SuppressWarnings("unchecked") protected Transformation<RowData> translateToPlanInternal( PlannerBase planner, ExecNodeConfig config) { final ExecEdge leftInputEdge = getInputEdges().get(0); final ExecEdge rightInputEdge = getInputEdges().get(1); final Transformation<RowData> leftTransform = (Transformation<RowData>) leftInputEdge.translateToPlan(planner); final Transformation<RowData> rightTransform = (Transformation<RowData>) rightInputEdge.translateToPlan(planner); final RowType leftType = (RowType) leftInputEdge.getOutputType(); final RowType rightType = (RowType) rightInputEdge.getOutputType(); JoinUtil.validateJoinSpec(joinSpec, leftType, rightType, true); final int[] leftJoinKey = joinSpec.getLeftKeys(); final int[] rightJoinKey = joinSpec.getRightKeys(); final InternalTypeInfo<RowData> leftTypeInfo = InternalTypeInfo.of(leftType); final JoinInputSideSpec leftInputSpec = JoinUtil.analyzeJoinInput(leftTypeInfo, leftJoinKey, leftUniqueKeys); final InternalTypeInfo<RowData> rightTypeInfo = InternalTypeInfo.of(rightType); final JoinInputSideSpec rightInputSpec = JoinUtil.analyzeJoinInput(rightTypeInfo, rightJoinKey, rightUniqueKeys); GeneratedJoinCondition generatedCondition = JoinUtil.generateConditionFunction( config.getTableConfig(), joinSpec, leftType, rightType); long minRetentionTime = config.getStateRetentionTime(); AbstractStreamingJoinOperator operator; FlinkJoinType joinType = joinSpec.getJoinType(); if (joinType == FlinkJoinType.ANTI || joinType == FlinkJoinType.SEMI) { operator = new StreamingSemiAntiJoinOperator( joinType == FlinkJoinType.ANTI, leftTypeInfo, rightTypeInfo, generatedCondition, leftInputSpec, rightInputSpec, joinSpec.getFilterNulls(), minRetentionTime); } else { boolean leftIsOuter = joinType == FlinkJoinType.LEFT || joinType == FlinkJoinType.FULL; boolean rightIsOuter = joinType == FlinkJoinType.RIGHT || joinType == FlinkJoinType.FULL; LOGGER.debug("============ READY TO APPLY TTL: LEFT TABLE: {}, RIGHT TABLE: {} ==============", leftTtl, rightTtl); operator = new StreamingJoinOperator( leftTypeInfo, rightTypeInfo, generatedCondition, leftInputSpec, rightInputSpec, leftIsOuter, rightIsOuter, joinSpec.getFilterNulls(), minRetentionTime, leftTtl, rightTtl); } final RowType returnType = (RowType) getOutputType(); final TwoInputTransformation<RowData, RowData, RowData> transform = ExecNodeUtil.createTwoInputTransformation( leftTransform, rightTransform, createTransformationMeta(JOIN_TRANSFORMATION, config), operator, InternalTypeInfo.of(returnType), leftTransform.getParallelism()); // set KeyType and Selector for state RowDataKeySelector leftSelect = KeySelectorUtil.getRowDataSelector(leftJoinKey, leftTypeInfo); RowDataKeySelector rightSelect = KeySelectorUtil.getRowDataSelector(rightJoinKey, rightTypeInfo); transform.setStateKeySelectors(leftSelect, rightSelect); transform.setStateKeyType(leftSelect.getProducedType()); return transform; } }18.接下来进入到了真正的算子执行逻辑里面,这里是 StreamingJoinOperator, 该类中,我们需要将得到的HINTS中的TTL信息传递给状态视图(JoinRecordStateViews 和 OuterJoinRecordStateViews),在状态视图中进行TTL的初始化设置, 其中 JoinRecordStateViews 表示非OUTER表对应的状态视图,比如 t1 left join t2, 这里的t1就是outer表,t2就是非outer表, StreamingJoinOperator 修改后的代码如下:
/* * Licensed to the Apache Software Foundation (ASF) under one * or more contributor license agreements. See the NOTICE file * distributed with this work for additional information * regarding copyright ownership. The ASF licenses this file * to you under the Apache License, Version 2.0 (the * "License"); you may not use this file except in compliance * with the License. You may obtain a copy of the License at * * http://www.apache.org/licenses/LICENSE-2.0 * * Unless required by applicable law or agreed to in writing, software * distributed under the License is distributed on an "AS IS" BASIS, * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. * See the License for the specific language governing permissions and * limitations under the License. */ package org.apache.flink.table.runtime.operators.join.stream; import org.apache.flink.streaming.runtime.streamrecord.StreamRecord; import org.apache.flink.table.data.GenericRowData; import org.apache.flink.table.data.RowData; import org.apache.flink.table.data.util.RowDataUtil; import org.apache.flink.table.data.utils.JoinedRowData; import org.apache.flink.table.planner.plan.nodes.exec.stream.StreamExecJoin; import org.apache.flink.table.runtime.generated.GeneratedJoinCondition; import org.apache.flink.table.runtime.operators.join.stream.state.JoinInputSideSpec; import org.apache.flink.table.runtime.operators.join.stream.state.JoinRecordStateView; import org.apache.flink.table.runtime.operators.join.stream.state.JoinRecordStateViews; import org.apache.flink.table.runtime.operators.join.stream.state.OuterJoinRecordStateView; import org.apache.flink.table.runtime.operators.join.stream.state.OuterJoinRecordStateViews; import org.apache.flink.table.runtime.typeutils.InternalTypeInfo; import org.apache.flink.types.RowKind; import org.slf4j.Logger; import org.slf4j.LoggerFactory; import java.security.acl.LastOwnerException; /** * Streaming unbounded Join operator which supports INNER/LEFT/RIGHT/FULL JOIN. */ public class StreamingJoinOperator extends AbstractStreamingJoinOperator { private static final long serialVersionUID = -376944622236540545L; private static final Logger LOGGER = LoggerFactory.getLogger(StreamingJoinOperator.class); // whether left side is outer side, e.g. left is outer but right is not when LEFT OUTER JOIN private final boolean leftIsOuter; // whether right side is outer side, e.g. right is outer but left is not when RIGHT OUTER JOIN private final boolean rightIsOuter; private transient JoinedRowData outRow; private transient RowData leftNullRow; private transient RowData rightNullRow; // left join state private transient JoinRecordStateView leftRecordStateView; // right join state private transient JoinRecordStateView rightRecordStateView; public StreamingJoinOperator( InternalTypeInfo<RowData> leftType, InternalTypeInfo<RowData> rightType, GeneratedJoinCondition generatedJoinCondition, JoinInputSideSpec leftInputSideSpec, JoinInputSideSpec rightInputSideSpec, boolean leftIsOuter, boolean rightIsOuter, boolean[] filterNullKeys, long defaultTtl, long leftTtl, long rightTtl) { super( leftType, rightType, generatedJoinCondition, leftInputSideSpec, rightInputSideSpec, filterNullKeys, defaultTtl, leftTtl, rightTtl); this.leftIsOuter = leftIsOuter; this.rightIsOuter = rightIsOuter; } @Override public void open() throws Exception { super.open(); this.outRow = new JoinedRowData(); this.leftNullRow = new GenericRowData(leftType.toRowSize()); this.rightNullRow = new GenericRowData(rightType.toRowSize()); LOGGER.info("\n\n=================================================================================================\n" + "============ TTL OF LEFT TABLE: {}, TTL OF RIGHT TABLE: {} ==============" + "\n=================================================================================================\n", leftTtl, rightTtl); // initialize states if (leftIsOuter) { this.leftRecordStateView = OuterJoinRecordStateViews.create( getRuntimeContext(), "left-records", leftInputSideSpec, leftType, leftTtl); } else { this.leftRecordStateView = JoinRecordStateViews.create( getRuntimeContext(), "left-records", leftInputSideSpec, leftType, leftTtl); } if (rightIsOuter) { this.rightRecordStateView = OuterJoinRecordStateViews.create( getRuntimeContext(), "right-records", rightInputSideSpec, rightType, rightTtl); } else { this.rightRecordStateView = JoinRecordStateViews.create( getRuntimeContext(), "right-records", rightInputSideSpec, rightType, rightTtl); } } @Override public void processElement1(StreamRecord<RowData> element) throws Exception { processElement(element.getValue(), leftRecordStateView, rightRecordStateView, true); } @Override public void processElement2(StreamRecord<RowData> element) throws Exception { processElement(element.getValue(), rightRecordStateView, leftRecordStateView, false); } /** * Process an input element and output incremental joined records, retraction messages will be * sent in some scenarios. * * <p>Following is the pseudo code to describe the core logic of this method. The logic of this * method is too complex, so we provide the pseudo code to help understand the logic. We should * keep sync the following pseudo code with the real logic of the method. * * <p>Note: "+I" represents "INSERT", "-D" represents "DELETE", "+U" represents "UPDATE_AFTER", * "-U" represents "UPDATE_BEFORE". We forward input RowKind if it is inner join, otherwise, we * always send insert and delete for simplification. We can optimize this to send -U & +U * instead of D & I in the future (see FLINK-17337). They are equivalent in this join case. It * may need some refactoring if we want to send -U & +U, so we still keep -D & +I for now for * simplification. See {@code * FlinkChangelogModeInferenceProgram.SatisfyModifyKindSetTraitVisitor}. * * <pre> * if input record is accumulate * | if input side is outer * | | if there is no matched rows on the other side, send +I[record+null], state.add(record, 0) * | | if there are matched rows on the other side * | | | if other side is outer * | | | | if the matched num in the matched rows == 0, send -D[null+other] * | | | | if the matched num in the matched rows > 0, skip * | | | | otherState.update(other, old + 1) * | | | endif * | | | send +I[record+other]s, state.add(record, other.size) * | | endif * | endif * | if input side not outer * | | state.add(record) * | | if there is no matched rows on the other side, skip * | | if there are matched rows on the other side * | | | if other side is outer * | | | | if the matched num in the matched rows == 0, send -D[null+other] * | | | | if the matched num in the matched rows > 0, skip * | | | | otherState.update(other, old + 1) * | | | | send +I[record+other]s * | | | else * | | | | send +I/+U[record+other]s (using input RowKind) * | | | endif * | | endif * | endif * endif * * if input record is retract * | state.retract(record) * | if there is no matched rows on the other side * | | if input side is outer, send -D[record+null] * | endif * | if there are matched rows on the other side, send -D[record+other]s if outer, send -D/-U[record+other]s if inner. * | | if other side is outer * | | | if the matched num in the matched rows == 0, this should never happen! * | | | if the matched num in the matched rows == 1, send +I[null+other] * | | | if the matched num in the matched rows > 1, skip * | | | otherState.update(other, old - 1) * | | endif * | endif * endif * </pre> * * @param input the input element * @param inputSideStateView state of input side * @param otherSideStateView state of other side * @param inputIsLeft whether input side is left side */ private void processElement( RowData input, JoinRecordStateView inputSideStateView, JoinRecordStateView otherSideStateView, boolean inputIsLeft) throws Exception { boolean inputIsOuter = inputIsLeft ? leftIsOuter : rightIsOuter; boolean otherIsOuter = inputIsLeft ? rightIsOuter : leftIsOuter; boolean isAccumulateMsg = RowDataUtil.isAccumulateMsg(input); RowKind inputRowKind = input.getRowKind(); input.setRowKind(RowKind.INSERT); // erase RowKind for later state updating AssociatedRecords associatedRecords = AssociatedRecords.of(input, inputIsLeft, otherSideStateView, joinCondition); if (isAccumulateMsg) { // record is accumulate if (inputIsOuter) { // input side is outer OuterJoinRecordStateView inputSideOuterStateView = (OuterJoinRecordStateView) inputSideStateView; if (associatedRecords.isEmpty()) { // there is no matched rows on the other side // send +I[record+null] outRow.setRowKind(RowKind.INSERT); outputNullPadding(input, inputIsLeft); // state.add(record, 0) inputSideOuterStateView.addRecord(input, 0); } else { // there are matched rows on the other side if (otherIsOuter) { // other side is outer OuterJoinRecordStateView otherSideOuterStateView = (OuterJoinRecordStateView) otherSideStateView; for (OuterRecord outerRecord : associatedRecords.getOuterRecords()) { RowData other = outerRecord.record; // if the matched num in the matched rows == 0 if (outerRecord.numOfAssociations == 0) { // send -D[null+other] outRow.setRowKind(RowKind.DELETE); outputNullPadding(other, !inputIsLeft); } // ignore matched number > 0 // otherState.update(other, old + 1) otherSideOuterStateView.updateNumOfAssociations( other, outerRecord.numOfAssociations + 1); } } // send +I[record+other]s outRow.setRowKind(RowKind.INSERT); for (RowData other : associatedRecords.getRecords()) { output(input, other, inputIsLeft); } // state.add(record, other.size) inputSideOuterStateView.addRecord(input, associatedRecords.size()); } } else { // input side not outer // state.add(record) inputSideStateView.addRecord(input); if (!associatedRecords.isEmpty()) { // if there are matched rows on the other side if (otherIsOuter) { // if other side is outer OuterJoinRecordStateView otherSideOuterStateView = (OuterJoinRecordStateView) otherSideStateView; for (OuterRecord outerRecord : associatedRecords.getOuterRecords()) { if (outerRecord.numOfAssociations == 0) { // if the matched num in the matched rows == 0 // send -D[null+other] outRow.setRowKind(RowKind.DELETE); outputNullPadding(outerRecord.record, !inputIsLeft); } // otherState.update(other, old + 1) otherSideOuterStateView.updateNumOfAssociations( outerRecord.record, outerRecord.numOfAssociations + 1); } // send +I[record+other]s outRow.setRowKind(RowKind.INSERT); } else { // send +I/+U[record+other]s (using input RowKind) outRow.setRowKind(inputRowKind); } for (RowData other : associatedRecords.getRecords()) { output(input, other, inputIsLeft); } } // skip when there is no matched rows on the other side } } else { // input record is retract // state.retract(record) inputSideStateView.retractRecord(input); if (associatedRecords.isEmpty()) { // there is no matched rows on the other side if (inputIsOuter) { // input side is outer // send -D[record+null] outRow.setRowKind(RowKind.DELETE); outputNullPadding(input, inputIsLeft); } // nothing to do when input side is not outer } else { // there are matched rows on the other side if (inputIsOuter) { // send -D[record+other]s outRow.setRowKind(RowKind.DELETE); } else { // send -D/-U[record+other]s (using input RowKind) outRow.setRowKind(inputRowKind); } for (RowData other : associatedRecords.getRecords()) { output(input, other, inputIsLeft); } // if other side is outer if (otherIsOuter) { OuterJoinRecordStateView otherSideOuterStateView = (OuterJoinRecordStateView) otherSideStateView; for (OuterRecord outerRecord : associatedRecords.getOuterRecords()) { if (outerRecord.numOfAssociations == 1) { // send +I[null+other] outRow.setRowKind(RowKind.INSERT); outputNullPadding(outerRecord.record, !inputIsLeft); } // nothing else to do when number of associations > 1 // otherState.update(other, old - 1) otherSideOuterStateView.updateNumOfAssociations( outerRecord.record, outerRecord.numOfAssociations - 1); } } } } } // ------------------------------------------------------------------------------------- private void output(RowData inputRow, RowData otherRow, boolean inputIsLeft) { if (inputIsLeft) { outRow.replace(inputRow, otherRow); } else { outRow.replace(otherRow, inputRow); } collector.collect(outRow); } private void outputNullPadding(RowData row, boolean isLeft) { if (isLeft) { outRow.replace(row, rightNullRow); } else { outRow.replace(leftNullRow, row); } collector.collect(outRow); } }状态视图的 create 方法将传入的时间(retentionTime)设置为TTL,如下图:

而且能看到 Flink在Join算子的TTL策略是 OnCreateAndWrite,说明了JOIN 算子不存在状态不老化的问题,英明啊~
说明:如果左右表都没设置ttl,那么前面的 StreamPhysicalJoin类就会使用 table.exec.state.ttl 参数的值来作为 TTL, 如果 table.exec.state.ttl 也没有设置,则就状态永不过期了。
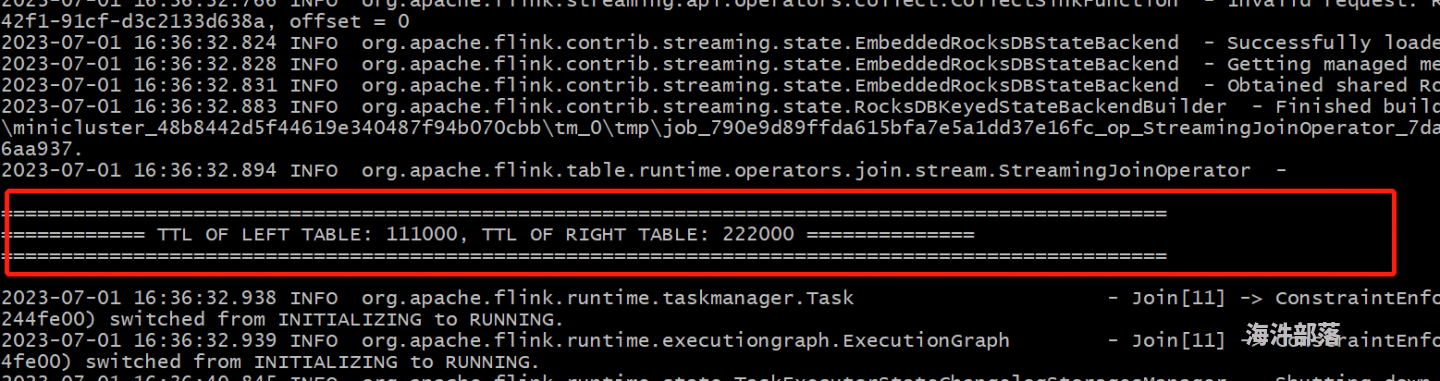
示例: 我的作业设置了JOIN算子的左表TTL是 111s, 右表的ttl是 222s,SELECT a.*,b.* FROM DATA_GEN_01 a left join /*+ OPTIONS('join.ttl.left'='111s', 'join.ttl.right'='222s') */ DATA_GEN_02 b on a.f_sequence = b.f_sequence从日志输出来看,已经设置生效了
示例2: 作业中不设置右表ttl, 而我设置了全局ttl,具体如下:SELECT a.*,b.* FROM DATA_GEN_01 a left join /*+ OPTIONS('join.ttl.left'='111s') */ DATA_GEN_02 b on a.f_sequence = b.f_sequence这是我的整个作业的一些配置信息
JOIN的ttl是左表为设置的值,右表为整个作业的ttl设置的值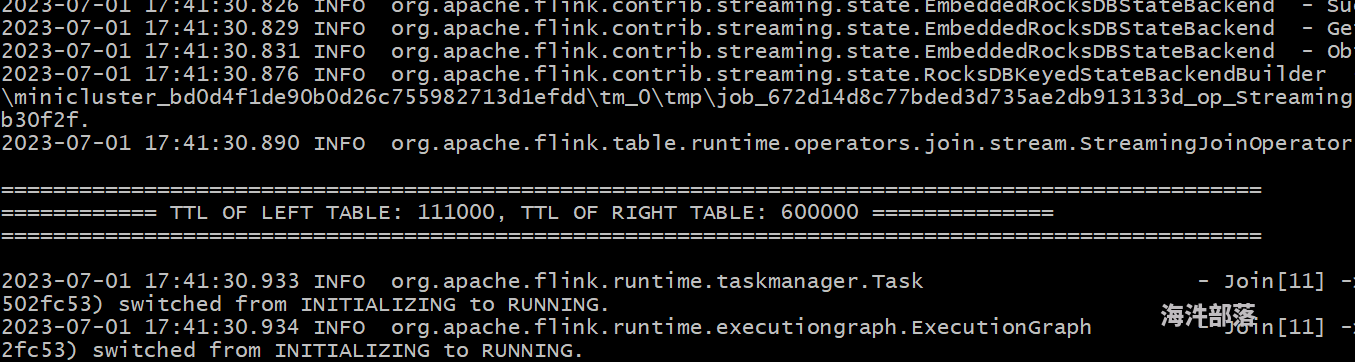
真实测试:
设置左表TTL 为 86400s, 右表 ttl 为 30s, 如图:
先发射一条左表数据,再发射一条右表数据,再发射一条左表数据,发现最后一条数据超过30s,状态过期了,关联不上了,如图:
至此,整个 join 算子的ttl设置过程算子完成了,中间省略了很多 Planner 代码的讲解,整个过程下来比较简单明了,如果我需要对聚合算子也加上细粒度TTL,是否也能通过该方法实现呢?
总结:版权所有,非本人允许不得用于商业用途,谢谢~



