1. 多个reducer实现整体排序
先观察数据情况,根据数据的分布去设计partitioner
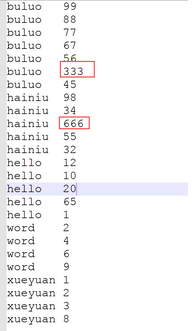
这组数据中大于100的只有2个,大部分数据还是在小于100的区间,所以就拿100当个分界点
去算0到100之间的数取分区ID的方法,先找临界点。算法是(100/reducer个数) + 1
然后用输入的key与分区临界点相除取整,最后算出输入的key属于那个分区ID
当输入key大于100时把数据分到最后一分区里。
如果有2个reducer yixia
yixia
以下内容回帖刷新可见………………
回复帖子,然后刷新页面即可查看隐藏内容
版权声明:原创作品,允许转载,转载时务必以超链接的形式表明出处和作者信息。否则将追究法律责任。来自海汼部落-青牛,http://hainiubl.com/topics/97



