@NEMOlv 我这个可以呀,你再试试
12核 16G
@NEMOlv 可以的,正式桌面自己配置内存和CPU就好了,还支持生成镜像保存你写的代码
@NEMOlv 之前的临时桌面配置高,后来上线正式桌面了,那个配置就降低了
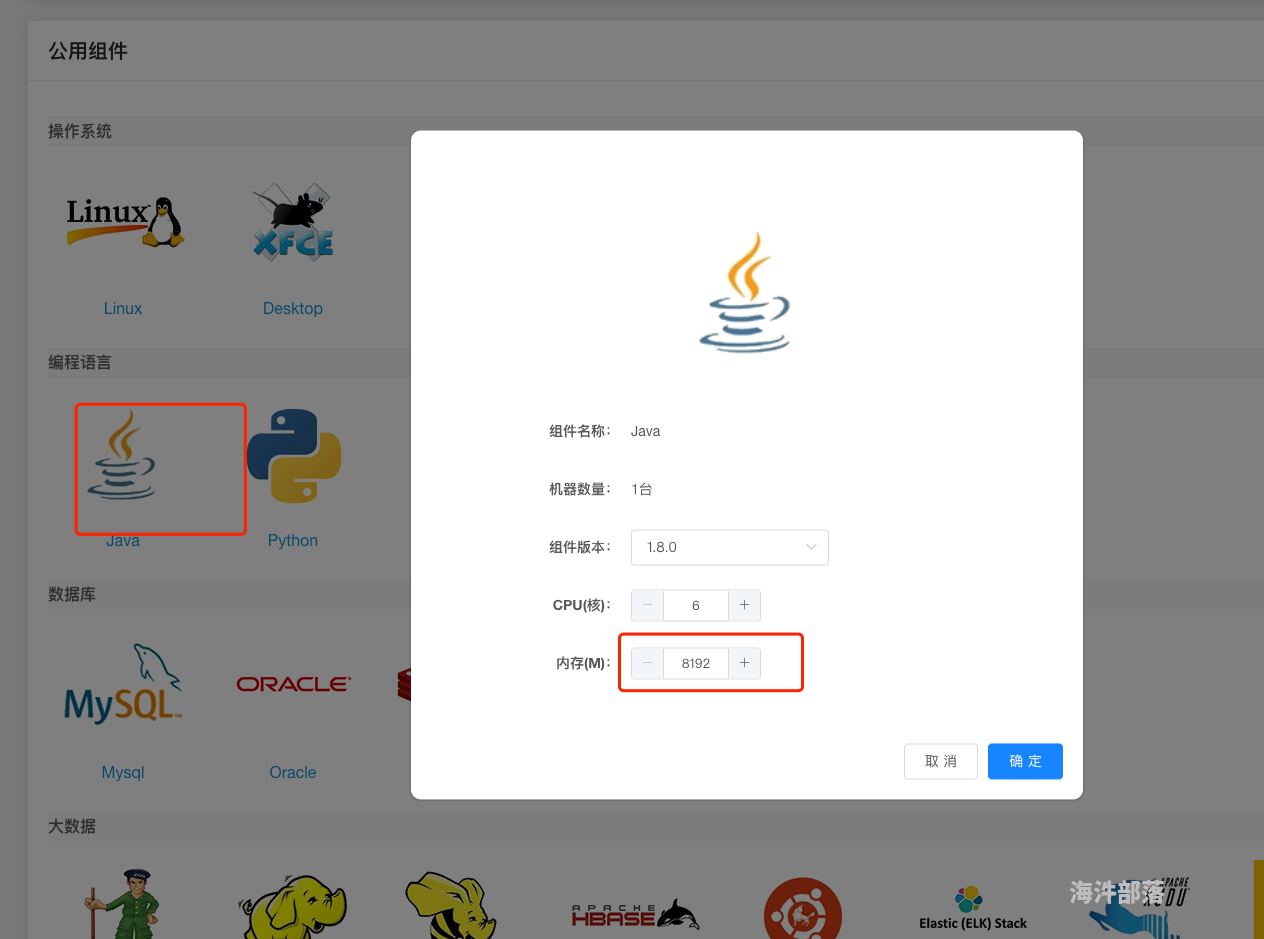
不在要临时桌面写代码,那个内存是固定的,你可以自己选择java组件然后修改内存去写代码
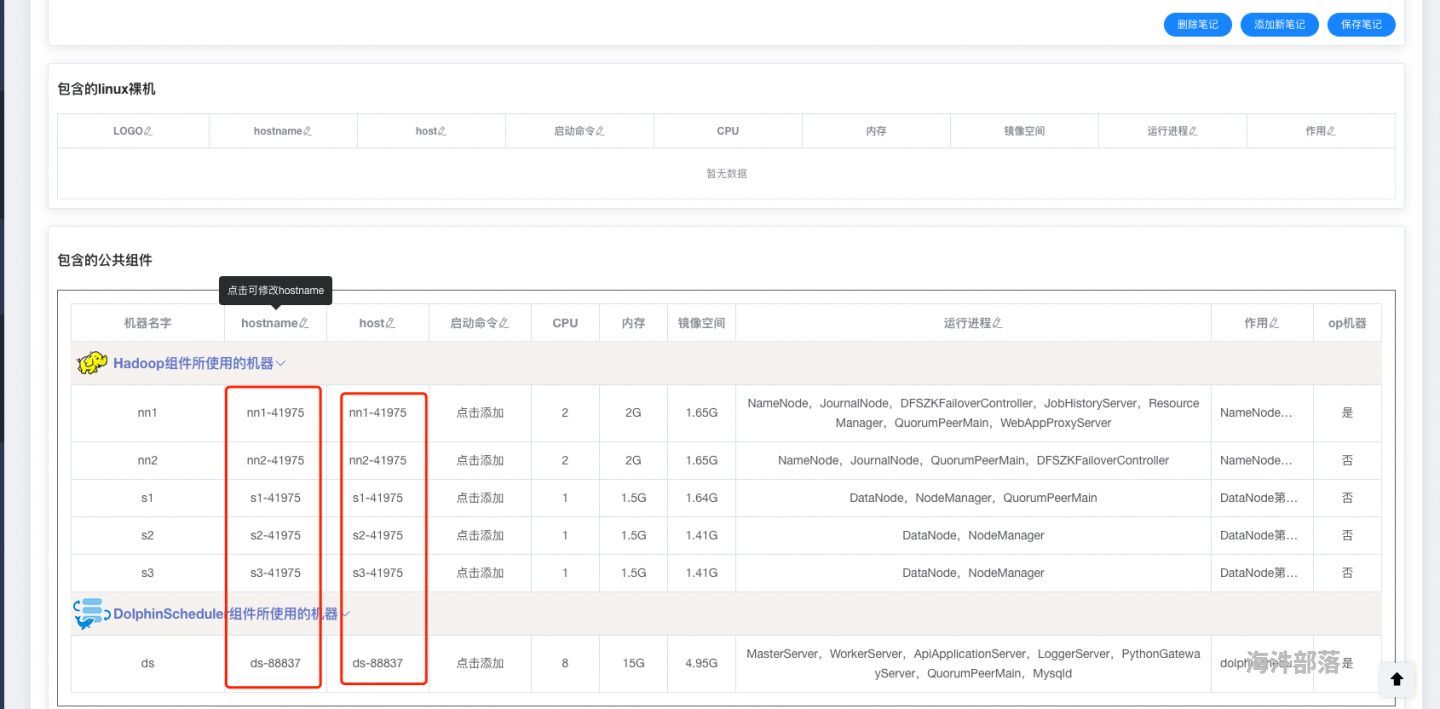
把.hadoop去了,只留nn1
@kkone 你对应的机器设置成什么host镜像启动的时候该机器就给你使用什么host,host要与hadoop配置文件中的匹配不然启动会报错
发现不对应可以打开镜像详情点击修改
可以,1个月之后上线
能,但是很慢,你至少需要30核 60G内存
@Arturo 看样子是老粉了,欢迎介绍其它人一起来用
用我们的VPN客户端,需要付费,价格参考这里http://www.hainiubl.com/topics/76255
http://www.hainiubl.com/topics/76283
@被遗忘的十七 而且spark优化必须从java底层考虑