关于 “” 的搜索结果, 共 2422 条
北京求职
by
 牛牛
牛牛
https://www.hainiubl.com/topics/395?
2023-06-23
⋅
6266
⋅
0
⋅
1

技术牛逼也要懂点社交:数据科学家公司生存指南 TOP30 秘诀
by
 海牛龙龙
海牛龙龙
https://www.hainiubl.com/topics/396?
2018-01-31
⋅
6682
⋅
1
⋅
2
数据科学家老司机的30个经验之谈,教你如何在公司内获得认同,带你绕过他们曾经踩过的坑。
作为一名数据科学家,即便你技术再牛逼,不懂职场社交也会成为你晋升之路上的天花板。
为此,我们创建了一份能够确保数据科学团队获得成功的秘诀top 30榜单。不管你的数据科...
读取 hbase 数据乱码?
by
 陌上花开
陌上花开
https://www.hainiubl.com/topics/397?
2018-02-01
⋅
8189
⋅
0
⋅
11

两种方式都会乱码
kettle 是做什么的呢?平时工作中
by
 ling775000
ling775000
https://www.hainiubl.com/topics/398?
2018-02-01
⋅
6323
⋅
0
⋅
4
网上看了解释比较晕
spark-submit ?
by
 maxy
maxy
https://www.hainiubl.com/topics/399?
2018-02-02
⋅
5921
⋅
0
⋅
7
同样的脚本, 同一个环境, 提交 spark任务时:
--master yarn-cluster \ 这个模式提交失败, 报错
Diagnostics: Exception from container-launch.
Container id: container_1517482621865_0004_02_000001
Exit code: 15
--master yarn-client \ 这个模式...
大数据平台开发是不是 java 后台也要搞呢?
by
ling775000
https://www.hainiubl.com/topics/401?
2018-02-05
⋅
4322
⋅
0
⋅
1
还是说只做数据清洗,ETL而已? 他这个平台开发什么意思呢?
spark 通过 Phoenix 读取 hbase 数据的问题?
by
陌上花开
https://www.hainiubl.com/topics/402?
2018-02-05
⋅
5080
⋅
0
⋅
3
版本:spark 2.2.0
Phoenix : 4.9.0
hbase :1.1.12
报错:

请问 1T 左右的数量 用 MapReduce 跑 job 数设置为多少合适呢?
by
ling775000
https://www.hainiubl.com/topics/403?
2018-02-05
⋅
5367
⋅
0
⋅
10
机器有20台左右
shell 脚本?
by
maxy
https://www.hainiubl.com/topics/404?
2018-02-05
⋅
4148
⋅
0
⋅
1
```
for i in `cat features|awk -F ' ' '{print$1}'`;
do
#echo $i
nn =$(echo cat train.name|grep $i);
echo $nn
done
这个 for 给 nn 赋值有问题。 麻烦看一下
```
oraceln 能在数据库里面查到数据但是无法获取元数据?
by
 auldlangsynezh
auldlangsynezh
https://www.hainiubl.com/topics/405?
2018-02-05
⋅
3883
⋅
0
⋅
2
?
用 sparkstreaming 消费kafka的数据,怎么将数据写入到hdfs的输入流,采用追加的方式写入?
by
 歌唱祖国
歌唱祖国
https://www.hainiubl.com/topics/406?
2018-02-07
⋅
7723
⋅
0
⋅
3
用sparkstreaming消费kafka的数据,怎么将数据写入到hdfs的输入流,采用追加的方式写入?具体能用哪个方法?能否上个code demo?请教大神
kafka 启动消费者, 一直报这个,请问是个怎么情况,怎么解决?如图
by
歌唱祖国
https://www.hainiubl.com/topics/407?
2018-02-07
⋅
5098
⋅
0
⋅
6
kafka启动消费者, 一直报这个,请问是个怎么情况,怎么解决?如图
hbase 插入数据一直卡住的问题?
by
 DDDH
DDDH
https://www.hainiubl.com/topics/408?
2018-02-07
⋅
6053
⋅
0
⋅
3
这是我的代码:
https://paste.ubuntu.com/26534996/
出现的问题就是一直卡在put方法处,不知道为啥,运行很长一段时间报错,下面是错误的信息。
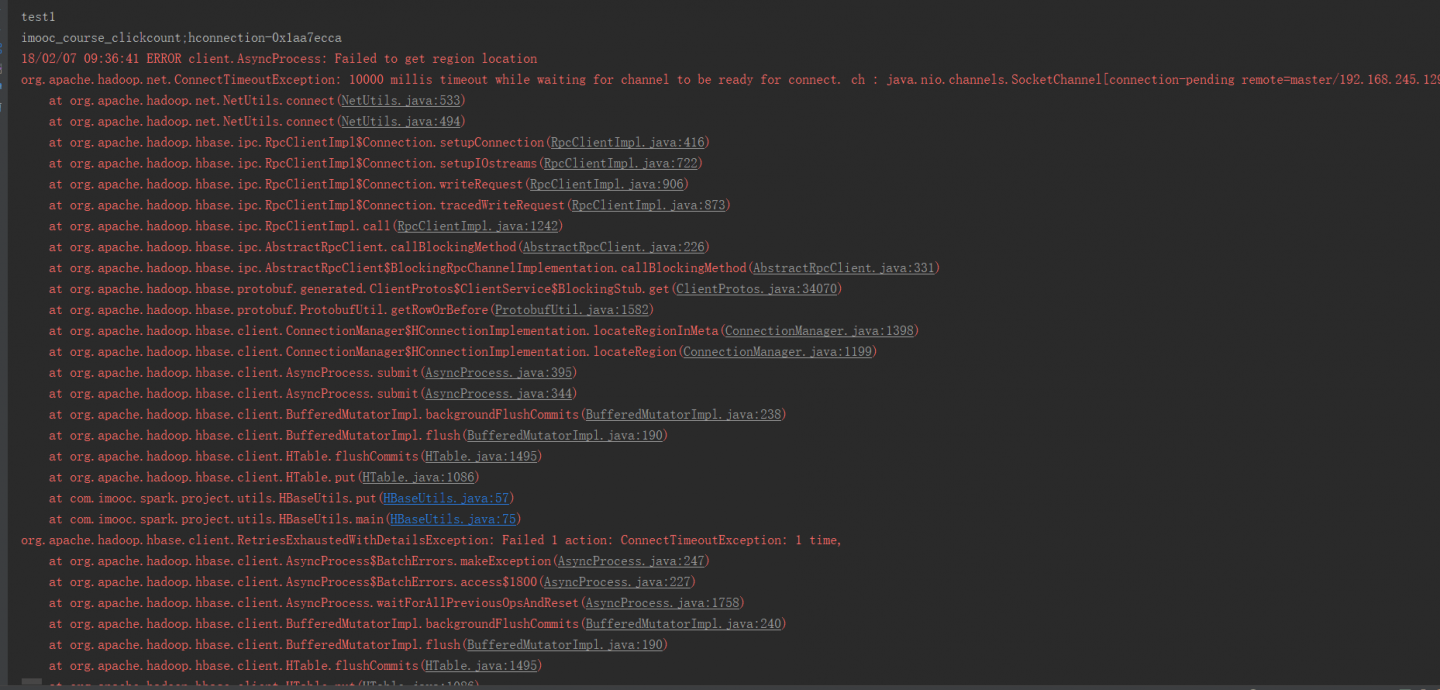
我搭的虚拟机装的centos,端口2181和...
hbase 数据插入 阻塞 入库数据入不进去?
by
ruiqi
https://www.hainiubl.com/topics/409?
2018-02-08
⋅
5768
⋅
0
⋅
1
请问一下,我们在操作hbase的时候使用的是批量数据入库Put的方法 没有使用mapreduce ,这个put的方法 ,在数据插入一部分后就阻塞了 ,我们只能把表清除后 把,数据才能继续插入 。hbase日志也没有报错。
wordcount 之 stage 划分?
by
xiaolin93
https://www.hainiubl.com/topics/410?
2018-02-08
⋅
4131
⋅
1
⋅
2
val spark = SparkSession
.builder()
.master("local")
.appName("testtt")
.getOrCreate()
val path ="C:/1/a.txt"
val sc = spark.sparkContext
val c: Array[(String, Int)] = sc.textFile(path)
.flatMap(_.spl...
spark ml ?
by
maxy
https://www.hainiubl.com/topics/411?
2018-02-09
⋅
3999
⋅
0
⋅
2
在进行 ml 学习的时候, 对特征的提取用 什么方法比较好(用java做) ? github上的 chisq自己感觉不是很好用,大牛 们指点一下。
spark 通过 Phoenix 读取 hbase 数据的问题?
by
陌上花开
https://www.hainiubl.com/topics/414?
2018-02-09
⋅
4840
⋅
0
⋅
3
代码:
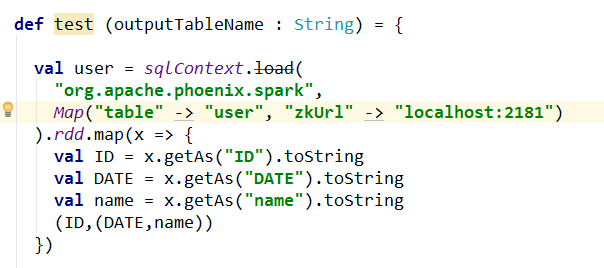
报错:

是什么问题?怎么解决?
spark 整合 hive,sparkSQL 为什么调不到 hive 中的表?
by
 菜鸟程序狗
菜鸟程序狗
https://www.hainiubl.com/topics/415?
2018-02-11
⋅
6796
⋅
0
⋅
2
集群上spark版本2.1.0整合hive1.1.0,本地调用sparkSQL的sql()方法为什么只有一张default表,但是在集群中直接用spark-shell却可以打印出存在的表???
spark 整合 kafka idea 本地测试报错,spark 版本 1.6.1 ,kafka 版本 kafka_2.10-0.8.2.2。这两个版本是不是不兼容?
by
朱威
https://www.hainiubl.com/topics/416?
2018-02-22
⋅
6119
⋅
0
⋅
1
```
Exception in thread "pool-24-thread-1" java.lang.UnsatisfiedLinkError: org.apache.hadoop.util.NativeCrc32.nativeComputeChunkedSumsByteArray(II[BI[BIILjava/lang/String;JZ)V
at org.apache.hadoop.util.NativeCrc32.nativeComputeChunkedSumsByteArray...
请问如何设置 kafka 的偏移量,采用 DStream 时没设置偏移量,每次启动从新消费,存在重复消费?
by
歌唱祖国
https://www.hainiubl.com/topics/418?
2018-02-22
⋅
5675
⋅
0
⋅
4
**请问如何设置kafka的偏移量,采用DStream时没设置偏移量,每次启动从新消费,存在重复消费?**
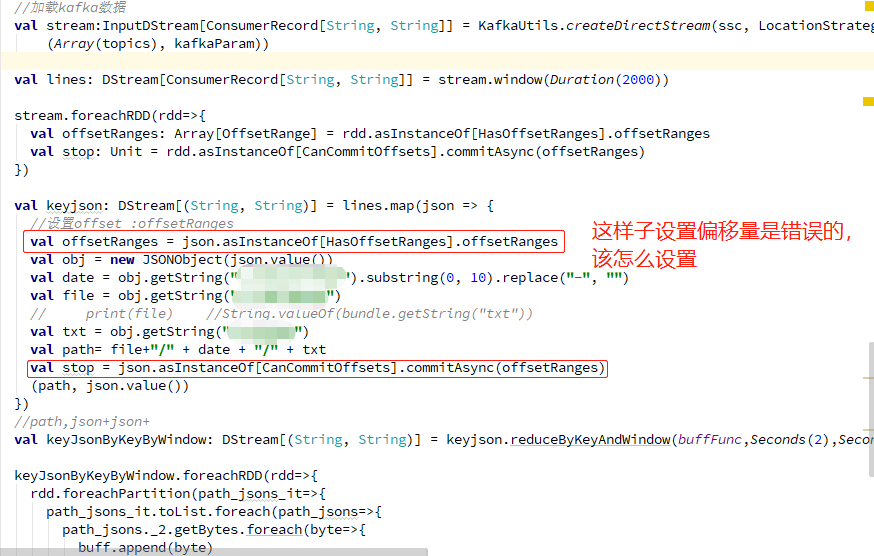
**为什么只有stream.foreachRDD { rdd => val offsetRanges = rdd.asInstanceOf[HasOffse...
eclpise 有某个项目 ctrl 不能进去类?
by
auldlangsynezh
https://www.hainiubl.com/topics/419?
2018-02-22
⋅
3859
⋅
1
⋅
2
正常情况应该是这样的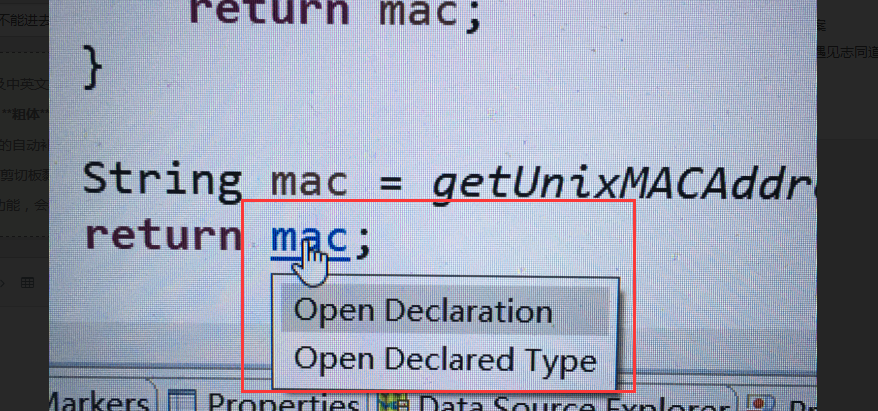
spark 大量数据读写问题?
by
ruiqi
https://www.hainiubl.com/topics/420?
2018-02-22
⋅
5582
⋅
1
⋅
9
我们数据存储用的hbase ,然后 key 最多可能有40亿个 ip+端口构成,每次数据库中读取然后处理 修改其中的列族中的数据在插入回hbase 中 ,用javaapi再办个小时内处理不完,而且有时候还出现读取超时,甚至导致hbase 挂掉的情况,请问 这个读取和插入有没有好的方式呢?
spark2.1.0 兼容 hive1.1.0 吗?
by
菜鸟程序狗
https://www.hainiubl.com/topics/421?
2018-02-23
⋅
4297
⋅
0
⋅
1
spark2.1.0兼容hive1.1.0吗?
oracle sql 提数?
by
maxy
https://www.hainiubl.com/topics/423?
2018-02-24
⋅
4138
⋅
1
⋅
4
我的库有这样的一张表,表数据如下(一部分):
client_no max(消费) min(消费) date
1 4000 100 1月
1 7000 500 2月
2 9000 300 1月...
spark 中用 hiveContext.sql 对 hive 版本有要求吗?
by
菜鸟程序狗
https://www.hainiubl.com/topics/424?
2018-02-24
⋅
3943
⋅
0
⋅
1
spark中用hiveContext.sql对hive版本有要求吗
广州公司招聘
by
牛牛
https://www.hainiubl.com/topics/425?
2023-07-22
⋅
6297
⋅
0
⋅
0
广州绿番茄软件科技有限公司(Green Tomato) 招聘大量技术人员
IOS工程师(前端):1.2年以上iOS开发经验。2.作为主力开发过至少一个iOS应用。3.熟练掌握swift /Objective-C其中一门语言。4.了解iOS平台内存管理机制、进程管理机制、任务管理机制。5.熟悉Xcode开发环境...
GitHub 上 hadoop,hbase 的 python 监控项目有没有推荐的?
by
 竹马吃了青梅
竹马吃了青梅
https://www.hainiubl.com/topics/426?
2018-02-26
⋅
4904
⋅
0
⋅
1
麻烦大家推荐一些github上的hadoop,hbase的python监控项目
impala 中 cast 函数进行数据类型的转换导致结果错误?
by
 liwei131313
liwei131313
https://www.hainiubl.com/topics/427?
2018-02-27
⋅
7550
⋅
0
⋅
1
表中的某个字段同udfs函数进行相乘,然后再使用cast函数进行数据类型转换,发现结果比真实的结果小0.01,如下图所示:
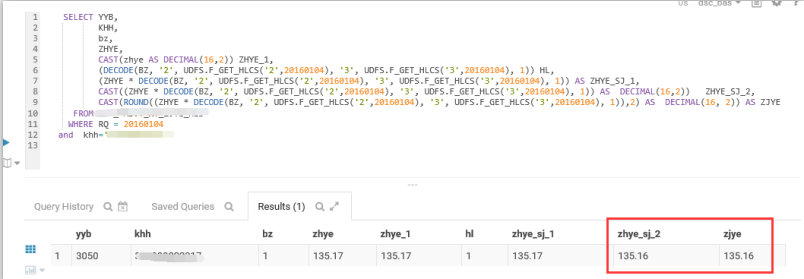
这个结果不正确的原因,有谁知道吗?
sparkSQL 找不到 hive 指定的库?
by
菜鸟程序狗
https://www.hainiubl.com/topics/428?
2018-02-27
⋅
7058
⋅
0
⋅
1
报错:apache.spark.sql.catalyst.analysis.NoSuchDatabaseException: Database 'bikshare' not found
代码:
val spark = SparkSession
.builder()
.appName(this.getClass.getName)
.enableHiveSupport()
.getOrCreate()
import...
如何使用 itext 实现 PDF 数字签章?
by
 ZLB
ZLB
https://www.hainiubl.com/topics/429?
2018-02-28
⋅
5376
⋅
1
⋅
2
请问大牛们,有没有使用过itext来实现签章的?