关于 “” 的搜索结果, 共 2423 条
在 sparkstreaming 中 foreach 算子中开启线程?
by
 生亦何欢
生亦何欢
https://www.hainiubl.com/topics/35969?
2018-12-26
⋅
2837
⋅
0
⋅
1
线程会每次数据进来foreach就会起一次吗,
spark.shuffle.file.buffer 属于 spark 内存里面的哪一部分?
by
生亦何欢
https://www.hainiubl.com/topics/35970?
2018-12-26
⋅
4176
⋅
0
⋅
3
spark里面有两种内存管理模型,shuffle交换的内存空间属于哪一部分,看了一些资料没看懂
请问 pySpark 中怎么序列化一个对象集合为 RDD?
by
生亦何欢
https://www.hainiubl.com/topics/35971?
2018-12-26
⋅
3199
⋅
0
⋅
1
pySpark中怎么序列化一个对象集合为RDD,Scala只需要继承Serializable ,python怎么做呢?
例如:这样最简单的操作
自然语言处理算法工程师(高级) - NLP
by
 join
join
https://www.hainiubl.com/topics/35973?
2023-08-25
⋅
5140
⋅
0
⋅
0
### 职位描述
负责文本挖掘,知识图谱,自然语言理解,问答对话等方向的算法研发
### 岗位要求
在机器学习和数据挖掘领域有相关工作经验
熟悉自然语言处理的基础理论和应用方法
有文本挖掘,搜索相关性优化的经验优先
有相关性模型,排序学习等相关经...
scala 代替 java 实现 Web 后端可行吗?会有什么问题?
by
 卢本伟牛X
卢本伟牛X
https://www.hainiubl.com/topics/35974?
2018-12-28
⋅
2909
⋅
0
⋅
1
以springboot为框架的web项目,实现spark产生的pipelineModel的可视化功能,后端进行解析,用scala时可以使用nbModel.stages(index).asInstanceOf(modeType)进行获取,但是java没有对应的asInstanceOf()方法。
请问java有什么其他的转换方法,或者直接用scala写后端...
关于 spark 的批次处理之间进行去重的问题?
by
 张凌天
张凌天
https://www.hainiubl.com/topics/35975?
2018-12-28
⋅
2830
⋅
0
⋅
1
不同的dstream之间如何进行去重
云服务器 Spark-Submit 后报 NoClassDefFoundError 请问怎么解决?
by
 十年
十年
https://www.hainiubl.com/topics/35976?
2018-12-28
⋅
3052
⋅
0
⋅
1
最近遇到一个spark-submit提交jar包,报java.lang.NoClassDefFoundError: Could not initialize class org.apache.hadoop.hdfs.server.namenode.NameNode的错误,我最开始使用eclipse将spark代码打普通Jar File包之后,上传到云服务器集群,之后换成Runnable Jar File也...
spark 读写 MySQL 出现的权限问题?
by
 听说
听说
https://www.hainiubl.com/topics/35977?
2018-12-28
⋅
2896
⋅
0
⋅
1
今天在向集群提交任务的时候出现了

查看mysql 数据表发现有一半的数据插入成功了
我的设置mysql登陆权限都设置了
.setAppName('project1').setMaster('local')
sc = SparkContext.ge...
maven 如何导出依赖 jar 包?
by
 sparksun007
sparksun007
https://www.hainiubl.com/topics/35981?
2018-12-31
⋅
3728
⋅
1
⋅
1
默认导出的是不带依赖资源jar包的文件,那么请问如何导出带jar包的呢?希望能详细些,网上查了很多资料还是看不懂啊,用的Eclipse开发环境~谢谢了!
spark-shell 执行 hc.sql ("load data inpath '/tmp/tags' overwrite into table tags") 出错,怎么解决?
by
 sourtanghc
sourtanghc
https://www.hainiubl.com/topics/35982?
2019-01-01
⋅
6055
⋅
1
⋅
12
```
ERROR hdfs.KeyProviderCache: Could not find uri with key [dfs.encryption.key.provider.uri] to create a keyProvider !!
java.lang.IllegalArgumentException: Wrong FS: hdfs://master:9000/tmp/tags/part-00000-b53ea587-a49e-4bfd-b952-0653aef45ada.sna...
scala 的脚本放在哪?
by
张凌天
https://www.hainiubl.com/topics/35985?
2019-01-02
⋅
2869
⋅
0
⋅
1
我该如何运行这个脚本,直接scalac肯定不对。。
《Linux 多线程服务端编程》中,弱回调的 StockFactory 是如何析构的?
by
卢本伟牛X
https://www.hainiubl.com/topics/35986?
2019-01-03
⋅
3035
⋅
0
⋅
1
弱回调的StockFactory无论Stock和StockFactory谁先挂掉都不会影响程序的正确运行。能否分析下Stock和StockFactory分别挂掉时的析构过程?
java 中补码右移时如果末尾变 0 的话要加 1 吗?
by
生亦何欢
https://www.hainiubl.com/topics/35987?
2019-01-03
⋅
2618
⋅
0
⋅
1
java中补码右移时如果末尾变0的话要加1吗?
如何评价 spark 在机器学习中的应用状况?
by
十年
https://www.hainiubl.com/topics/35988?
2019-01-03
⋅
2643
⋅
0
⋅
1
现阶段正在着手在spark上运行word2vec训练词向量,但是没有发现分布式训练词向量的优势何在,numPartition设为1时,训练时长与单机比优势不明显,调高numPartition训练质量又会下降很多。有点怀疑是不是这种迭代调节参数的算法并不适合在spark上运行?还是我打开的方式...
Spark 配置如何处理 1G 大小的文件,做积分统计?
by
听说
https://www.hainiubl.com/topics/35989?
2019-01-03
⋅
2911
⋅
0
⋅
1
3 台4核8G服务器组成的Spark集群,处理不了1g大小的文本文件,是对用积分记录做统计,然后排序输出,但是处理是内存溢出,或通讯超时,这是怎么回事,需要如何做优化?
怎么用 TensorFlow on spark 求指教?
by
张凌天
https://www.hainiubl.com/topics/35990?
2019-01-03
⋅
2702
⋅
0
⋅
1
怎么用TensorFlow on spark 求指教?
使用 Phoenix 做用户标签效率如何?可以满足这种需求吗?
by
 歌唱祖国
歌唱祖国
https://www.hainiubl.com/topics/35992?
2019-01-07
⋅
3498
⋅
0
⋅
1
如题,使用Phoenix做用户标签效率如何?可以满足这种需求吗?
spark 的广播变量 brodcast 传递多大的数据是合适的?
by
卢本伟牛X
https://www.hainiubl.com/topics/35997?
2019-01-08
⋅
3153
⋅
0
⋅
1
spark的广播变量brodcast传递多大的数据是合适的?
如何提高 spark 的数据分析能力?
by
张凌天
https://www.hainiubl.com/topics/35998?
2019-01-08
⋅
2954
⋅
0
⋅
1
最近在用spark分析一些具体业务需求。但几个需求做下来总感觉很吃力。需求的整体逻辑差的很多。所以希望大佬们推荐一些好的统计分析视频或者书籍。不胜感激。
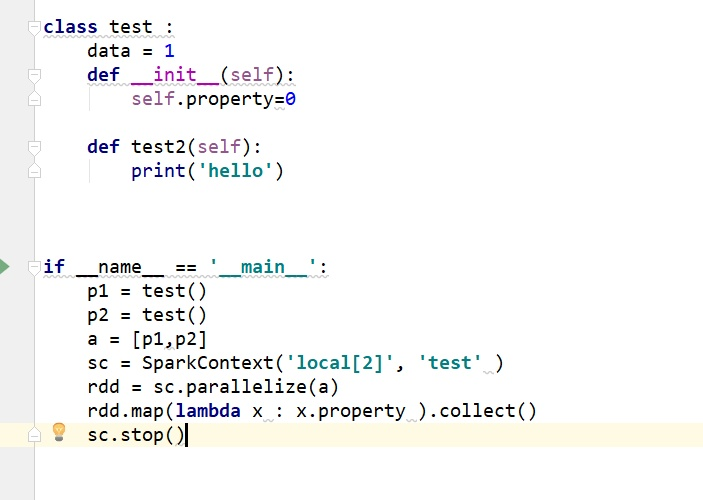
请问 pySpark 中怎么序列化一个对象集合为 RDD?
by
生亦何欢
https://www.hainiubl.com/topics/35999?
2019-01-08
⋅
3595
⋅
0
⋅
1
pySpark中怎么序列化一个对象集合为RDD,Scala只需要继承Serializable ,python怎么做呢?
例如:这样最简单的操作
Spark SQL 到底怎么搭建起来?
by
听说
https://www.hainiubl.com/topics/36000?
2019-01-08
⋅
2696
⋅
0
⋅
1
半年内版本升级到1.3了,依赖的hive还要0.13.1版本,人家hive都升级到1.1了。回头又要依赖hadoop的mapredue和yarn,还要2.4版本的,可是人家都升级到2.6了。
别告诉我那你就用0.13.1的hive和2.4的hadoop啊,2.4的hadoop已经被官方抛弃了,连官方下载链接都没有,2.x的...
Eclipse Console,Linux 控制台和 Windows cmd 的输出原理有什么区别?描述详见说明
by
十年
https://www.hainiubl.com/topics/36001?
2019-01-08
⋅
2926
⋅
0
⋅
1
同问题在stackoverflow,spark社区上也问了,暂无回答,并行着放到知乎上了。
近日在玩弄Spark,我需要抓取Eclipse Scala IDE中Console的输出Log,然后做一些挖掘工作。后来因为某些原因,需要从控制台提交并直接抓取数据。在Linux和Win下各有一个完全等价的集群。
L...
Spark 查询时间分析,scan 扫描 vs join 哪个更耗时,差距几个数量级?
by
张凌天
https://www.hainiubl.com/topics/36002?
2019-01-08
⋅
2797
⋅
0
⋅
1
本身最近在做Spark相关查询优化问题的研究,请问Spark sql做查询的时候,i/o扫描 vs join 哪个更耗时,查询的性能瓶颈具体在哪,希望能给出具体的时间分析?join等值连接 相比 i/o扫描差距有多大?
补充一下:我说的join物理实现是sort merge join,是两个大表直接...
Spark RDD 能否知道指定分区数据?
by
卢本伟牛X
https://www.hainiubl.com/topics/36004?
2019-01-08
⋅
2753
⋅
0
⋅
1
请问一下能否知道rdd第一个分区的数据呢?或者指定分区数据呢?
Phoenix 加盐表,sqoop 导入数据到 HBase 该表,数据是否可以自动加盐?
by
歌唱祖国
https://www.hainiubl.com/topics/36007?
2019-01-09
⋅
4738
⋅
0
⋅
2
如题,Phoenix加盐表,sqoop导入数据到HBase该表,数据是否可以自动加盐?在Phoenix中能否查询到数据?
phoenix 怎么做时间加减?类似于 MySQL 里面的 interval 1 day
by
歌唱祖国
https://www.hainiubl.com/topics/36008?
2019-01-10
⋅
5212
⋅
0
⋅
1
phoenix怎么做时间加减?类似于mysql里面的interval 1 day
如何用 PYTHON 在不调用库的情况下实现 ping 命令?
by
卢本伟牛X
https://www.hainiubl.com/topics/36010?
2019-01-14
⋅
2699
⋅
0
⋅
1
实现ping通的判断等等……
python 查找 dataframe 的目标索引,后利用 For 循环删除行为什么不好使?
by
张凌天
https://www.hainiubl.com/topics/36017?
2019-01-14
⋅
2807
⋅
0
⋅
1