关于 “” 的搜索结果, 共 2423 条
海牛部落 Linux 系列教程:(3) Shell 基本命令
by
 青牛
青牛
https://www.hainiubl.com/topics/168?
2017-09-22
⋅
37070
⋅
18
⋅
136
###1 查看目录和文件
1.1显示当前目录:pwd
Linux中用 pwd 命令来查看”当前工作目录“的完整路径。 简单得说,每当你在终端进行操作时,你都会有一个当前工作目录。
在不太确定当前位置时,就会使用pwd来判定当前目录在文件系统内的确切位置。
命令格式:

bin: 存放二进制可执行文件(ls,cat,mkdir等)
boot: 存放用于系统引导时使用的各种文件
dev: 用于存放设备文件
etc:存放系统配置文件
home: 存放所有用户...
海牛部落 Linux 系列教程:(5) 用户与用户组管理
by
青牛
https://www.hainiubl.com/topics/170?
2017-09-22
⋅
22175
⋅
11
⋅
78
###1 Linux 的账号与群组
1.1 使用者标识符:UID 与 GID
虽然我们登入 Linux 主机的时候,输入的是我们的账号,但是其实 Linux 主机不会直接认识你的账号名称,他仅认识 ID。而你的 ID 与账号的对应就在 /etc/passwd 当中。
每个登入的使用者都会有两个ID,...
海牛部落 Linux 系列教程:(6) 进程管理
by
青牛
https://www.hainiubl.com/topics/171?
2017-09-22
⋅
22127
⋅
21
⋅
73
在Linux系统上运行的任何东西,每一个用户的工作、每一个系统监控程序等等都是以进程的形式运行的。因此进程管理是Linux系统管理非常重要的一个方面。在这一章,我们将详细介绍如何管理进程:
■ 如何查找系统中运行的进程。
■ 找出扰乱系统的进程。
■ 如...
海牛部落 Linux 系列教程:(7) 软件管理
by
青牛
https://www.hainiubl.com/topics/172?
2017-09-22
⋅
18621
⋅
9
⋅
59
###1 什么是yum?
1.1 yum 简介
yum 的理念是使用一个中心仓库(repository)管理一部分甚至一个distribution 的应用程序相互关系,根据计算出来的软件依赖关系进行相关的升级、安装、删除等等操作,减少了Linux 用户一直头痛的dependencies 的问题。这一点上,yum 和a...
海牛部落 Linux 系列教程:(8) Shell 编程
by
青牛
https://www.hainiubl.com/topics/173?
2017-09-22
⋅
21828
⋅
23
⋅
72
###1 Vim 编辑器
1.1 vim 常用命令
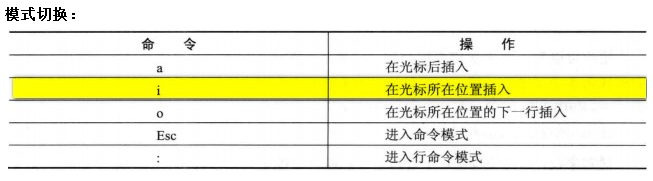
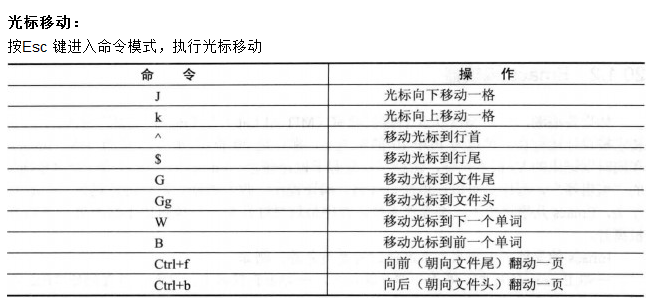

2. [hadoop 的 Windows 伪分布式环境部署](http://hainiubl.com/topics/88)...
海牛部落 java 系列教程:(3)流程控制
by
青牛
https://www.hainiubl.com/topics/179?
2017-09-28
⋅
26876
⋅
6
⋅
84
目录
顺序结构
分支结构
循环结构
###1 顺序结构
顺序结构:从上到下依次执行,排在前面的代码先执行,排在后面的后执行,如图:
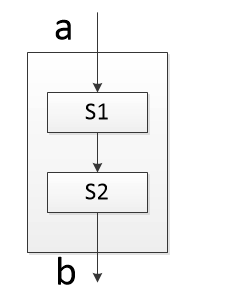
###2 分支结构
分支结构:表示程序的处理需要根...
海牛部落 java 系列教程:(4)方法
by
青牛
https://www.hainiubl.com/topics/180?
2017-09-28
⋅
22396
⋅
23
⋅
74
###1 认识方法
1.2 什么是方法?
方法就是C语言里的函数,是一个独立的功能模块。
1.3 为什么需要方法?
每个方法都有自己独立的功能,可以将功能代码写在一个方法里,然后调用该方法实现该功能,可以多次调用该方法,提高代码的复用性;还可以减...
大数据 java 基础
by
青牛
https://www.hainiubl.com/topics/181?
2017-09-28
⋅
52862
⋅
32
⋅
79
###在程序界混你可以不知道lua、go、ruby、scala但是你必须得知道java,因为它无处不在 android系统、web网站、大数据处处都有它的身影。所以有句话说:“精通Java饿不死一点也不假”。
1. [ java 语言概述](http://hainiubl.com/topics/149)
2. [数据类型和运算符]...
大数据 Linux 教程
by
青牛
https://www.hainiubl.com/topics/182?
2017-09-28
⋅
48941
⋅
29
⋅
81
###作为服务器界的操作系统Linux,它在服务器界的普及程度就如同PC界的Windows操作系统一样,最关键的是它还免费。大数据技术做为在服务器集群上运行的软件,所以自然是运行在Linux操作系统之上的,所以Linux操作系统是学习大数据的基础。
1. [在虚拟机中安装 CentOS...
海牛部落 java 系列教程:(5)数组和排序
by
青牛
https://www.hainiubl.com/topics/183?
2017-09-28
⋅
21155
⋅
7
⋅
70
###1 数组
数组是编程语言中最常见的的数据结构,其本身是个引用类型数据。
java数组要求所有的数组元素具有相同的数据类型。
一旦数组的初始化完成,数组在内存中所占的空间将被固定下来,数组的长度将不可变
数组既可以存储基本类型数据,也可以存储引用类型数...
数据仓储工具 hive
by
青牛
https://www.hainiubl.com/topics/186?
2017-09-29
⋅
37570
⋅
11
⋅
42
###MapReducer实在太难写了,还得学习Java编程语言,做为一个SQLER在大数据时代该怎么办,没关系Hive可以拯救你。
1. [hive 介绍与安装](http://hainiubl.com/topics/103)
2. [数据类型、运算符、建库、建表](http://hainiubl.com/topics/112)
3. [orc 文件、b...
NOSQL 数据库 hbase
by
青牛
https://www.hainiubl.com/topics/187?
2017-09-29
⋅
27654
⋅
4
⋅
29
###传统的关系型数据库比如Mysql、Oracle在大数据时代显得心有余悸而力不足了,所以需要专门应付大数据业务模式的集群式NoSQL数据库Hbase。
1. [Hbase 概述与安装、Hbase 原理和简单的 shell 操作](http://hainiubl.com/topics/122)
2. [Java 操作](http://hainiu...
海牛部落 oozie 系列教程(三十五):Linux 的 crontab 和 oozie 的 cronschedule
by
青牛
https://www.hainiubl.com/topics/188?
2017-09-29
⋅
18392
⋅
19
⋅
40
###1.linux的crontab
cron不停地检查所有配置的任务在当前是否应该运行,任务运行的最小时间间隔是1分钟,也就是说任务最频繁只能每分钟运行一次。
(1).crontab命令选项
crontab -u <-l, -r, -e>
-u:指定一个用户
-l:列出某个用户的任务计划
-r:删除某个用...
海牛部落 python 系列教程(三十六):python 开发环境安装与 python 基础 1
by
青牛
https://www.hainiubl.com/topics/189?
2017-09-29
⋅
20012
⋅
3
⋅
50
###1.python简介
Python语言是少有的一种可以称得上即简单又功能强大的编程语言。你将惊喜地发现Python语言是多么地简单,它注重的是如何解决问题而不是编程语言的语法和结构。
Python的官方介绍是:Python是一种简单易学,功能强大的编程语言,它有高效率的高层数据...
海牛部落 python 系列教程(三十七):python 基础 2
by
青牛
https://www.hainiubl.com/topics/190?
2017-09-29
⋅
18295
⋅
6
⋅
48
###1.数据结构
Python中有三种内建的数据结构——列表、元组和字典
(30).列表
list是处理一组有序项目的数据结构,即你可以在一个列表中存储一个 序列 的项目。并且里面的值是能够被改变的
列表中的项目应该包括在方括号中,这样Python就知道你是在指明一个列表。一旦...
海牛部落 spark 系列教程(三十八):spark 介绍、RDD 原理、spark 开发环境搭建
by
青牛
https://www.hainiubl.com/topics/191?
2017-09-29
⋅
28453
⋅
13
⋅
86
###1.什么Spark
Spark是加州大学伯克利分校AMP实验室(Algorithms, Machines, and People Lab)开发的通用内存并行计算框架,用于构建大型的、低延迟的数据分析应用程序。
Spark使用Scala语言开发,它还提供了对Scala、Python、Java(支持Java 8)和R语言的支持
Apac...
海牛部落 spark 系列教程(三十九):RDD 编程基础使用
by
青牛
https://www.hainiubl.com/topics/192?
2017-09-29
⋅
19802
⋅
5
⋅
55
###1.常用的转换
假设rdd的元素是: {1,2,2,3}

应用于pairRdd

:RDD 编程二次排序、mapjoin
by
青牛
https://www.hainiubl.com/topics/193?
2017-09-29
⋅
22844
⋅
12
⋅
51
###1.二次排序
自定义比较类用于key

用spark rdd实现二次排序
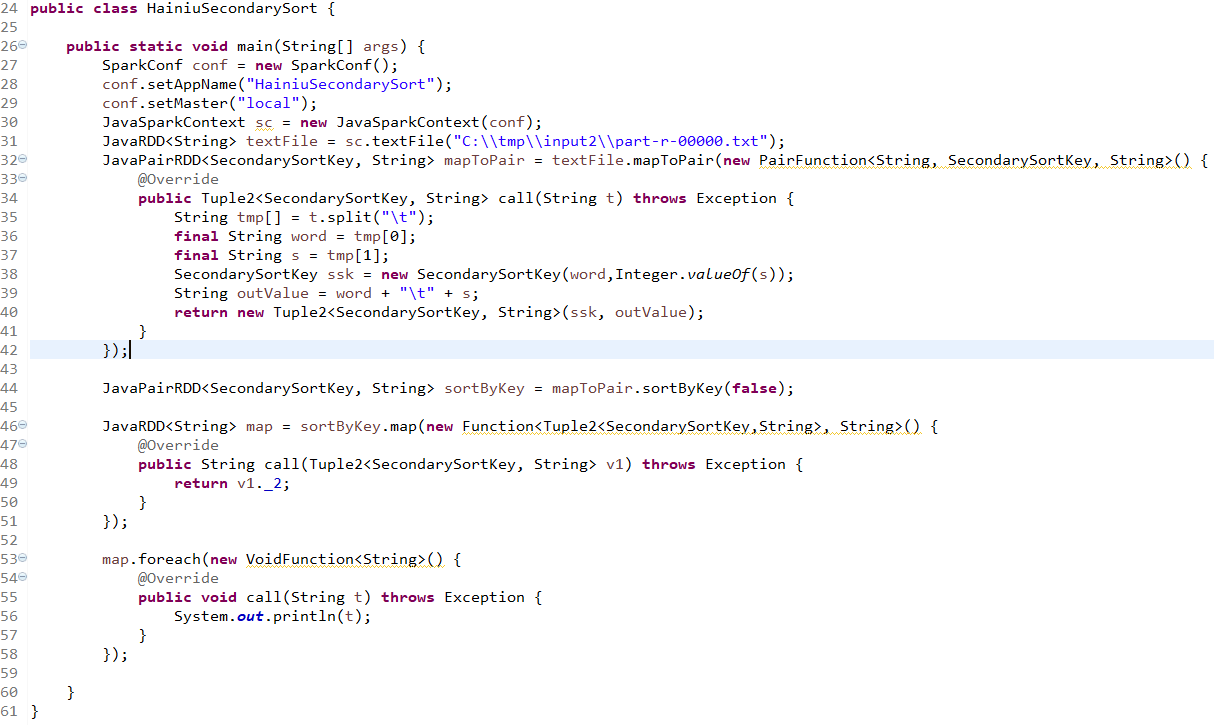
海牛部落 spark 系列教程(四十一):spark-sql
by
青牛
https://www.hainiubl.com/topics/194?
2017-09-29
⋅
19430
⋅
4
⋅
48
###1.hive vs spark-sql
为了给熟悉RDBMS但又不理解MapReduce的技术人员提供快速上手的工具,hive应运而生,它是运行在Hadoop上的SQL-on-hadoop工具。但是MapReduce计算过程中大量的中间磁盘落地过程消耗了大量的I/O,运行效率底,spark sql而是采用内存存储可以减少大...
海牛部落 spark 系列教程(四十二):spark-sql 编程
by
青牛
https://www.hainiubl.com/topics/195?
2017-09-29
⋅
18676
⋅
1
⋅
41
###1.spark-sql的json
pom
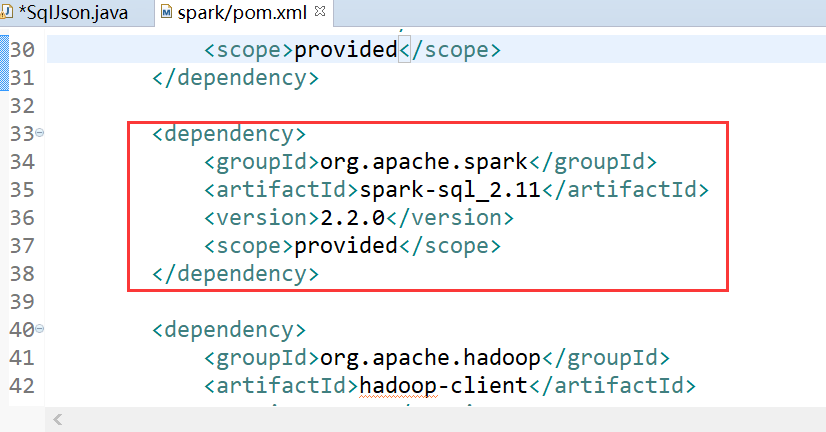

代码
:spark-hbase_bulkload、spark 程序集群运行、spark-streaming
by
青牛
https://www.hainiubl.com/topics/196?
2017-09-29
⋅
18366
⋅
47
⋅
40
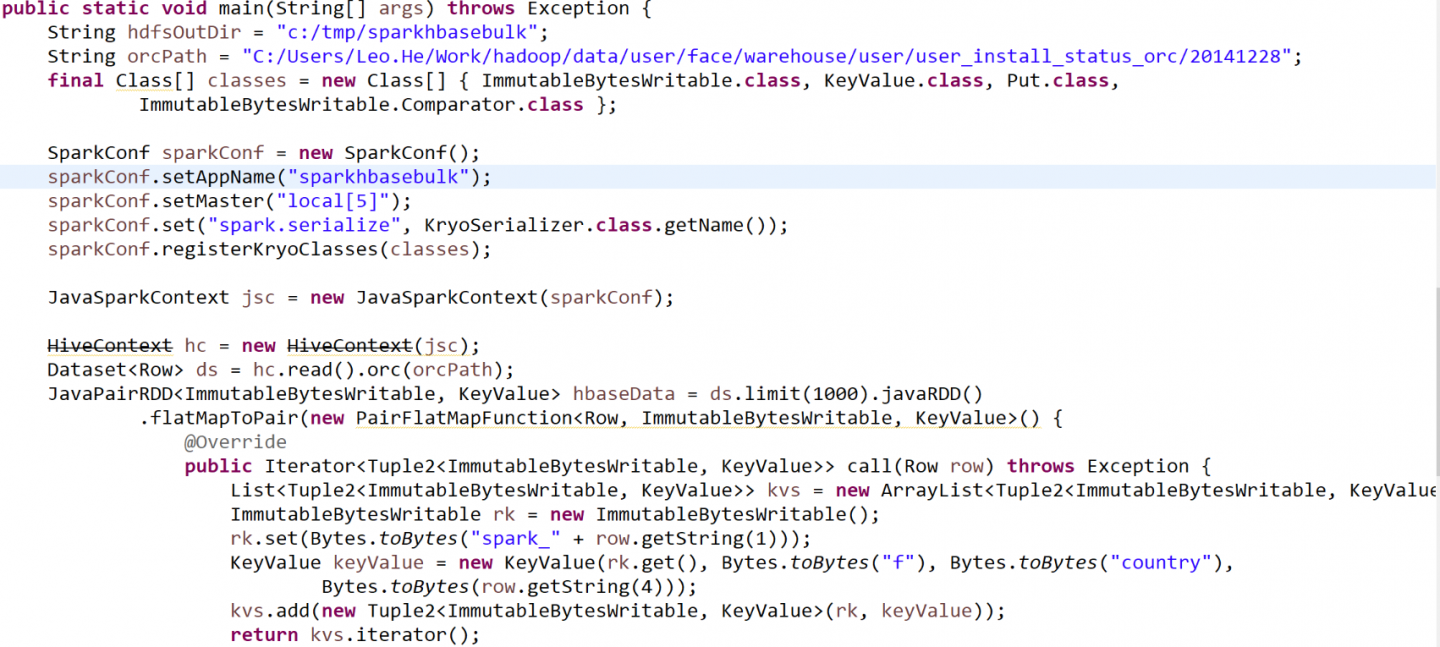
###1.hbase bulk load
pom:

代码:
:Spark 的 updateStateByKey、Windows、checkpoint、updateStateByKey_last_update、SparkStreamingFile
by
青牛
https://www.hainiubl.com/topics/197?
2017-09-29
⋅
18619
⋅
34
⋅
36
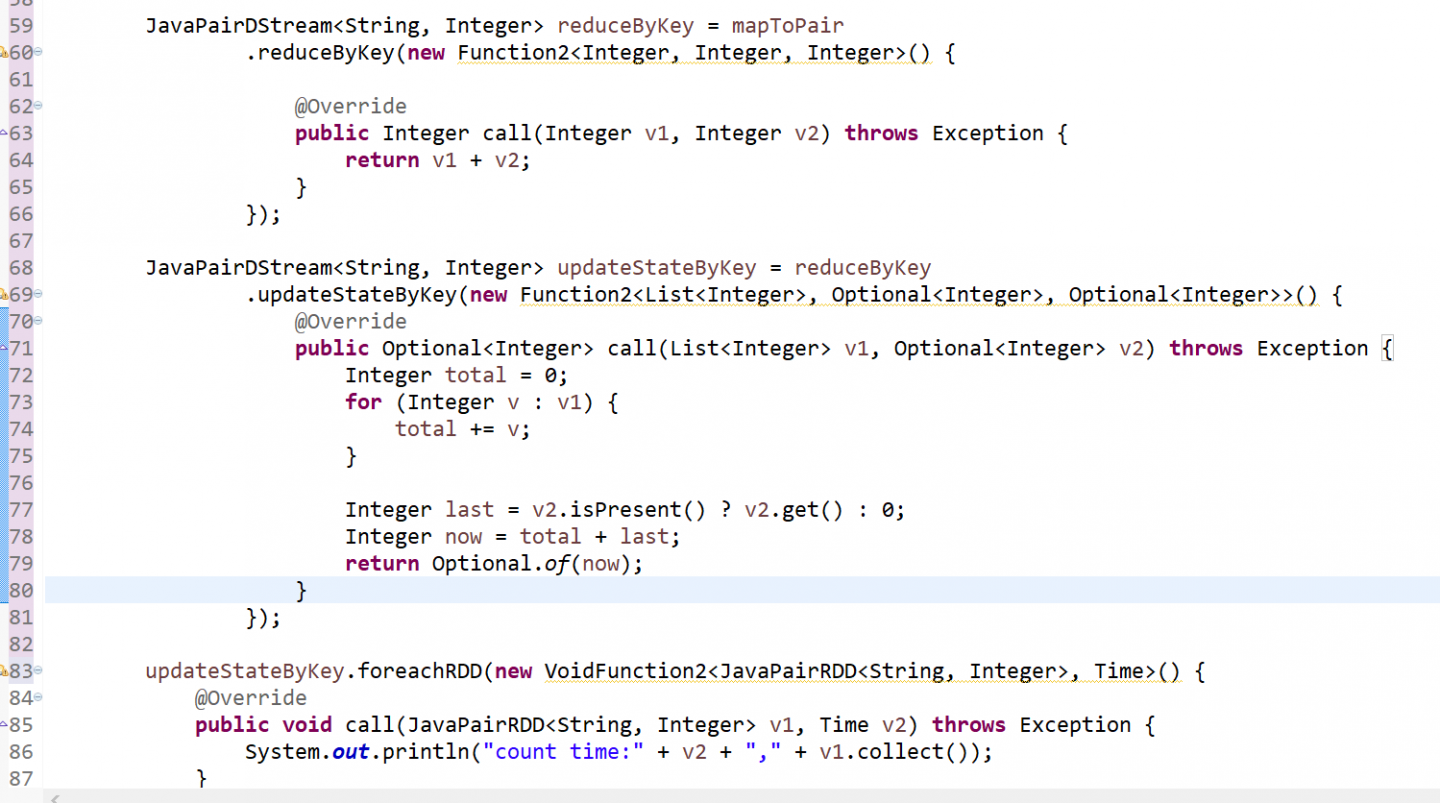
###1.updateStateByKey
代码:


2. [oozie 基本元素、oozie_SSH、MySQL 命令导入导出、tomcat 与 HTML 介绍](http://hainiubl.com/top...
万能的胶水语言 python
by
青牛
https://www.hainiubl.com/topics/199?
2017-09-29
⋅
47747
⋅
9
⋅
79
###Python做为使用最为广泛的脚本语言,不仅网络爬虫、大数据、深度学习甚至在未来的人工智能都有用武之地。
1. [python 开发环境安装与 python 基础 1](http://hainiubl.com/topics/189)
2. [python 基础 2](http://hainiubl.com/topics/190)
海牛部落 spark 系列教程(四十三):spark-hbase
by
青牛
https://www.hainiubl.com/topics/200?
2017-09-29
⋅
17654
⋅
16
⋅
34
###1.table put
POM:
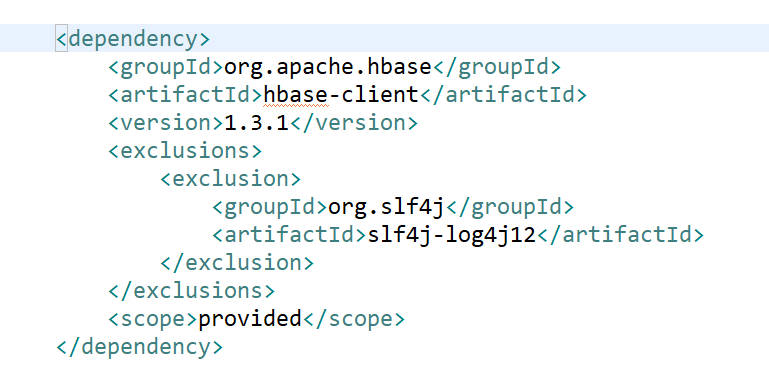
代码
:kafka 介绍与安装、kafka-java-API、spark-streaming-kafka、cogroup
by
青牛
https://www.hainiubl.com/topics/201?
2017-09-29
⋅
22900
⋅
8
⋅
51
###1.kafka分布式消息队列
(1).概述
Kafka是由LinkedIn开发的一个分布式的消息系统,用作LinkedIn的活动流(Activity Stream)和运营数据处理管道(Pipeline)的基础
Kafka使用Scala编写,它以可水平扩展和高吞吐率而被广泛使用。目前越来越多的开源分布式处理系统如...
spark 基于内存的分布式计算框架
by
青牛
https://www.hainiubl.com/topics/202?
2017-09-29
⋅
36356
⋅
9
⋅
33
###大数据的处理怎么能变快一点,答案是请用spark,因为它是基于内存的,可以有效减少数据的落地次数。
1. [spark 介绍、RDD 原理、spark 开发环境搭建](http://hainiubl.com/topics/191)
2. [RDD 编程基础使用](http://hainiubl.com/topics/192)
3. [RDD 编程...