关于 “” 的搜索结果, 共 2423 条
Linux 的 groupadd -r -g 1009 g1 创建的是普通用户组还是系统用户组?
by
 螺旋的邂逅
螺旋的邂逅
https://www.hainiubl.com/topics/75327?
2020-09-26
⋅
3525
⋅
0
⋅
2
groupadd -r -g 1009
-r 创建系统用户组,
1009是普通用户组
那这条语句创建的是哪个组
在工作中遇到一个 hive 表用到了自定义的一个类,无法查询对应表,如何将这个类部署到 hadoop 集群不同 ip 的 agent 上?
by
 羽翔
羽翔
https://www.hainiubl.com/topics/75328?
2020-09-28
⋅
2903
⋅
0
⋅
3

在工作中遇到一个hive表用到了自定义的一个类,无法查询对应表,如何将这个类部署到hadoop集群不同ip 的agent 上
通过读快照将 hfile 装成 orc 文件的时候 报错 Can not create a Path from a null string 不知道为问题出在哪里?
by
 小小书生
小小书生
https://www.hainiubl.com/topics/75329?
2020-09-30
⋅
3942
⋅
0
⋅
2
通过读快照将hfile装成orc文件的时候报错
报错提示: Can not create a Path from a null string
检查啦快照名称参数,orc在hdfs上的输出路径和临时存储路径
配置文件core-site.xml和hdfs-site.xml直接copy过来的
度快照转hfile的类(SnapshotHfile2Orcr)和任务链...
ListIterator 遍历的时候为啥没有输出 iterator 添加的元素呢?
by
 Josiah
Josiah
https://www.hainiubl.com/topics/75330?
2020-10-01
⋅
2659
⋅
0
⋅
2

但是在外面就输出了
scan hbase 表中数据 为 orc 格式,在 eclipse 运行时 报下列错?
by
 hx999
hx999
https://www.hainiubl.com/topics/75331?
2020-10-04
⋅
2498
⋅
0
⋅
2
org.apache.hadoop.security.AccessControlException: Permission denied: user=hanxu, access=WRITE, inode="/tmp/hbase1/scanhbase2orc_1004_hanxu/_temporary/0":hadoop:supergroup:drwxr-xr-x
 MapReduce
MapReduce
https://www.hainiubl.com/topics/75332?
2020-10-07
⋅
3010
⋅
0
⋅
3
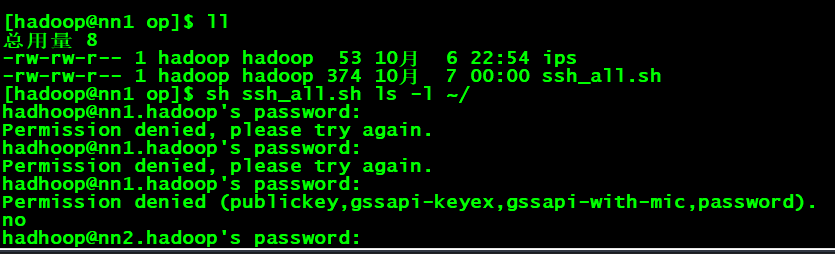
已经配置过免密, 切换用户是不需要密码的, 多级操作输入完命令,让我输入密码,每次都会弹出Permission denied, please try again.,第三次是Permission denied (publickey,gssapi-keyex...
MR 中的 Reduce 端源码分析
by
 AIZero
AIZero
https://www.hainiubl.com/topics/75333?
2020-10-10
⋅
3194
⋅
2
⋅
0
<div style="text-align:center"><b>Reduce阶段的核心</b></div>
- Copy和Merge阶段:Copy阶段和Merge阶段基本同时进行的
- Reduce阶段:返回伪迭代器,执行Reduce函数输出数据到HDFS
<br/>
<div style="text-align:center">核心面板:ReduceTask</div>
```jav...
spark 在自己集群 yarn 执行任务失败?
by
 爱拼才会赢
爱拼才会赢
https://www.hainiubl.com/topics/75334?
2020-10-13
⋅
2989
⋅
0
⋅
5
自己yarn集群配置好后,提交以下任务执行不了,报错信息如下:
```
spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--queue hainiu \
--deploy-mode client \
/usr/local/spark/examples/jars/spark-examples_2.11-2.1.1.jar \
2...
hadoop 报错问题?
by
MapReduce
https://www.hainiubl.com/topics/75336?
2020-10-14
⋅
4239
⋅
1
⋅
1
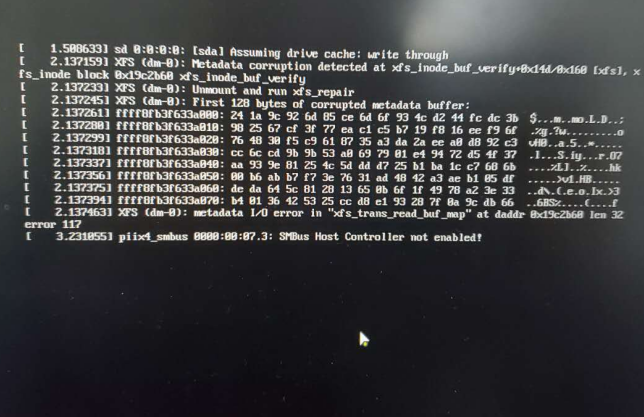
这是刚开机的出现的界面, 报出几行错误 ,百度之后,尝试用,xfs_repair,进行修复, 但是出现couldn't initialize XFS library ,不让我进行修复,如下图:
 Balder-Chang
Balder-Chang
https://www.hainiubl.com/topics/75337?
2020-10-16
⋅
3049
⋅
0
⋅
1
请教个问题:
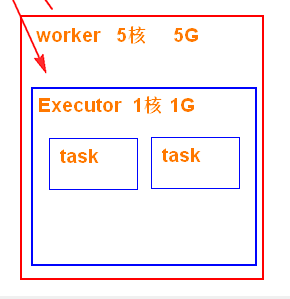
这个图是否可以理解为,若集群中有五个作业ID在运行时,每个作业ID恰好都在这个worker中启动了一个excutor,然后每个executor的资源为均为1 core 、1G?
按我之前的理解...
为啥静态类(不是内部类)不能被实例化呢?
by
Josiah
https://www.hainiubl.com/topics/75338?
2020-10-18
⋅
3865
⋅
1
⋅
7
?(●ˇ∀ˇ●)
scala01
by
 123456789987654321
123456789987654321
https://www.hainiubl.com/topics/75339?
2020-10-19
⋅
2868
⋅
1
⋅
1
# scala
## Scala常用的转义字符(escape char)
```scala
\t :一个制表位,实现对齐的功能
\n :换行符
\\ :一个\
\" :一个"
\r :一个回车 println("hello\rk");
```
## 注释(comment)
```scala
单行注释
格式: //注释文字
多行...
怎么能变正常???
by
 小菜牛
小菜牛
https://www.hainiubl.com/topics/75340?
2020-10-20
⋅
2570
⋅
0
⋅
1
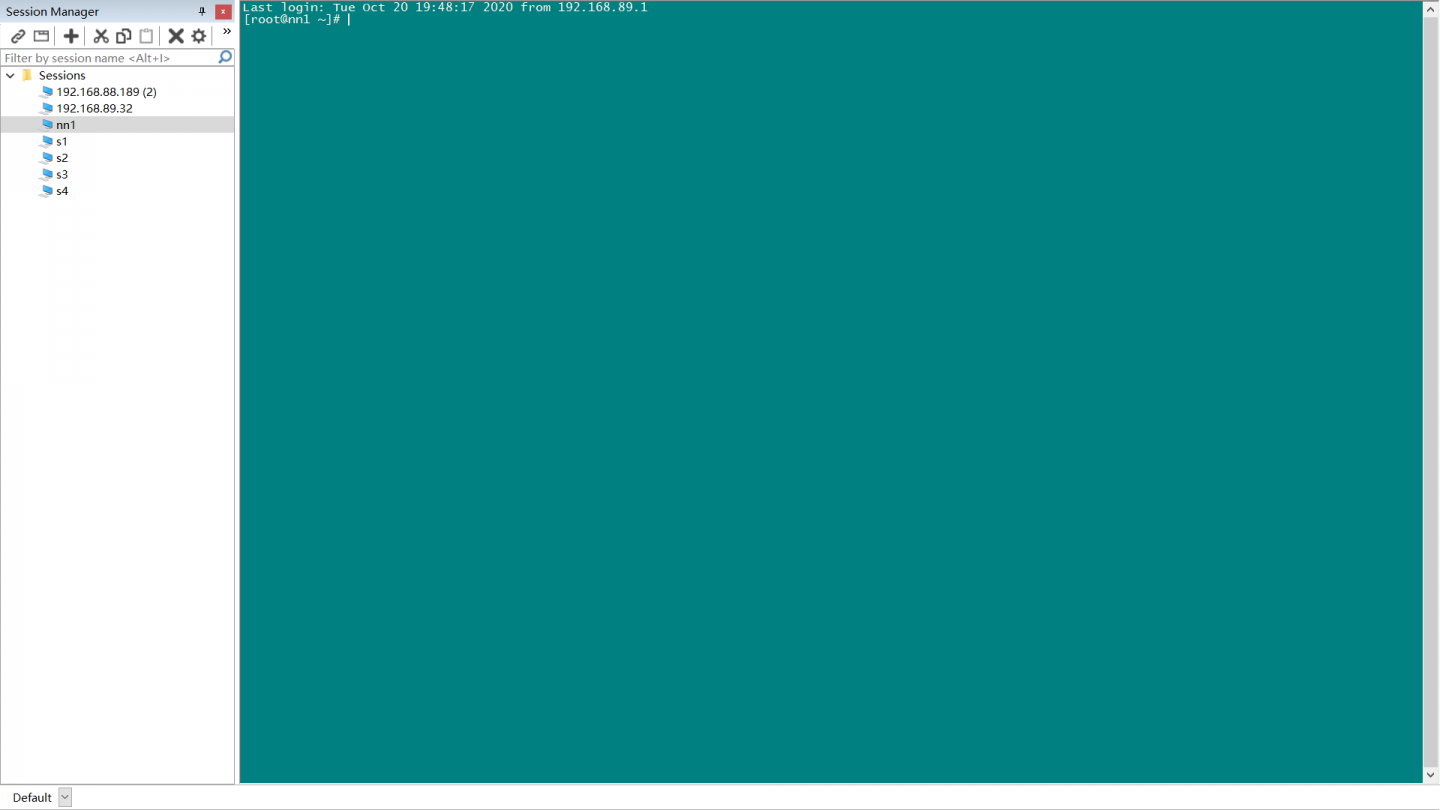
运行 WordCount 出错,提示没有 hadoop,请问该如何解决?
by
桐悟
https://www.hainiubl.com/topics/75341?
2020-10-20
⋅
2492
⋅
0
⋅
1
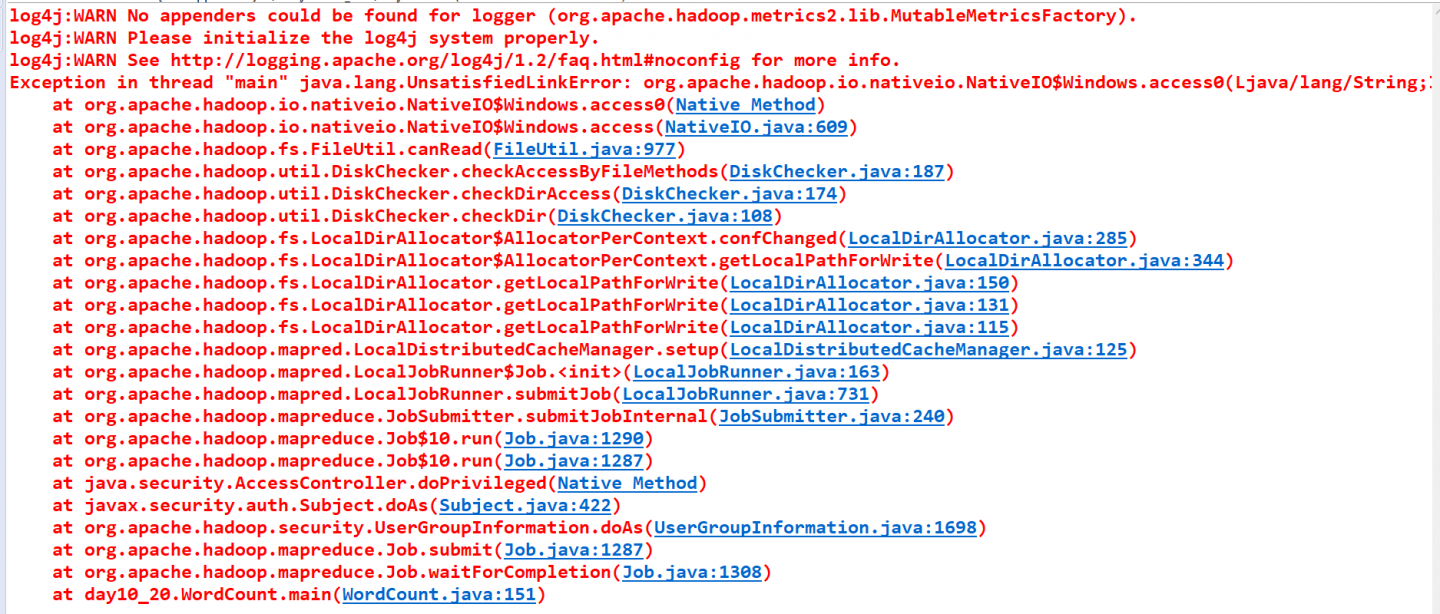

Spark 插入 Es 能插入 id?
by
爱拼才会赢
https://www.hainiubl.com/topics/75343?
2020-10-21
⋅
3200
⋅
1
⋅
1
我在用Spark插入Es时,不想用Es自己生成的ID,但自己插入ID报错。代码如下图
```
val conf: SparkConf = new SparkConf().setAppName("SparkElasticsearch").setMaster("local[*]")...
sql 种 varchar 和 char 的字符串判断问题?
by
螺旋的邂逅
https://www.hainiubl.com/topics/75344?
2020-10-22
⋅
2791
⋅
1
⋅
2
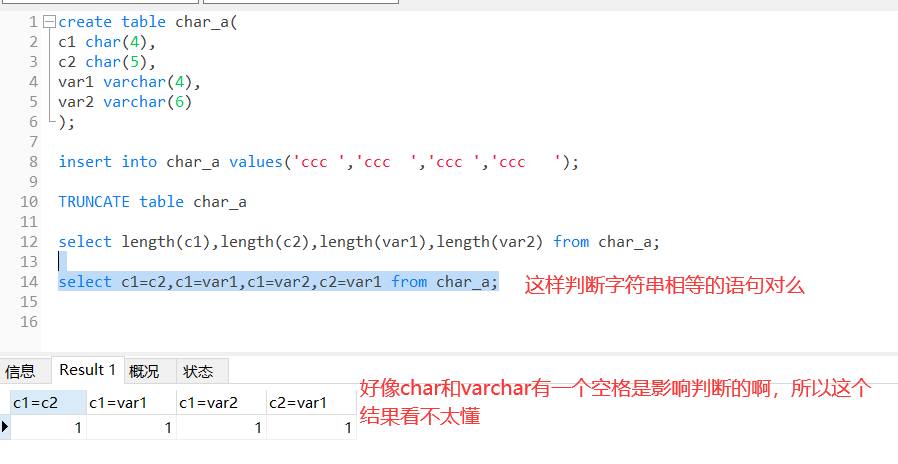
还有问一句,hive的char、varchar 和 sql 的 char、 varchar的性质是一样的么
想去的公司要精通 SQL,那是个什么概念,怎样才算精通?
by
螺旋的邂逅
https://www.hainiubl.com/topics/75345?
2020-10-22
⋅
3110
⋅
0
⋅
3
PostgreSQL 数据库函数
by
123456789987654321
https://www.hainiubl.com/topics/75346?
2020-10-23
⋅
5097
⋅
1
⋅
2
本人独立承担一个项目,所有业务逻辑全部由sql书写完成,因此分享两个月的总结!
# postgresql
<https://www.cnblogs.com/hole/p/11699702.html>
https://www.yiibai.com/html/postgresql/2013/080443.html
## sql函数
### SQL UNION 操作符
```sql
U...
JAVA 8 Stream 流 学习笔记
by
123456789987654321
https://www.hainiubl.com/topics/75347?
2020-10-23
⋅
3187
⋅
1
⋅
0
# Lambda表达式
```java
1. Lanbda表达式标准格式
//Lambda表达式的标准格式为:(参数类型 参数名称) -> { 代码语句 }
格式说明:
小括号内的语法与传统方法参数列表一致:
无参数则留空;多个参数则用逗号分隔。
2. Lanbda表达...
NGINX
by
123456789987654321
https://www.hainiubl.com/topics/75348?
2020-10-23
⋅
4930
⋅
1
⋅
0
# nginx安装
# 1.安装pcre依赖
```shell
1)第一步,安装 pcre
wget http://downloads.sourceforge.net/project/pcre/pcre/8.37/pcre-8.37.tar.gz
2)解压文件
./configure 完成后,回到 pcre 目录下执行 make,
3)再执行
make install
```
### **第...
scala02
by
123456789987654321
https://www.hainiubl.com/topics/75349?
2020-10-23
⋅
2845
⋅
1
⋅
0
# scala函数式编程
## 方法、函数、函数式编程
### 函数的定义
```scala
基本语法
def 函数名 ([参数名: 参数类型], ...)[[: 返回值类型] =] {
语句...
return 返回值
}
1.函数声明关键字为def (definition)
2.[参数名: 参数类型], ... :表示函数...
DBUtils query 方法为啥用 Integer 接收返回值不行呢?
by
Josiah
https://www.hainiubl.com/topics/75350?
2020-10-28
⋅
2751
⋅
0
⋅
1

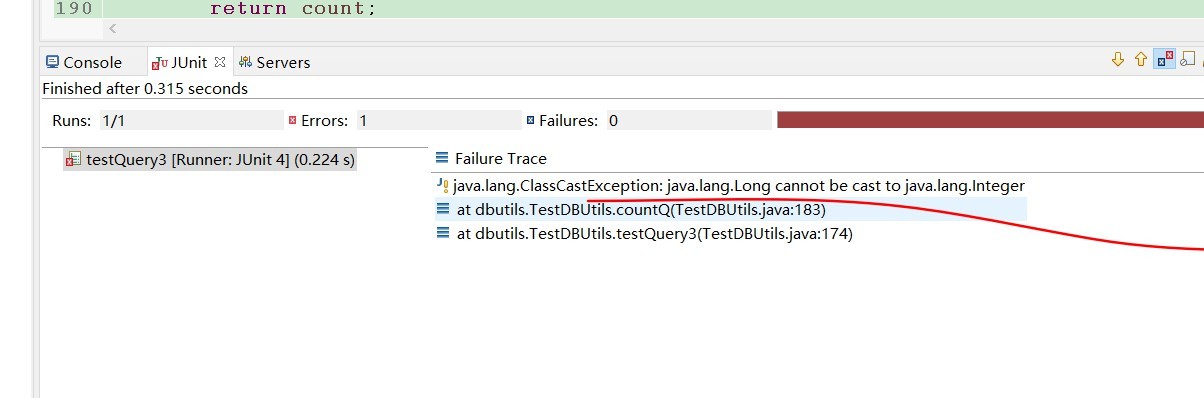
为啥是Long类型,,我在源码里也没找到关于Long类型的字样
scala03
by
123456789987654321
https://www.hainiubl.com/topics/75351?
2020-10-28
⋅
2767
⋅
1
⋅
0
# 包
## 1
```scala
1.基本语法
package 包名
2.Scala包的三大作用(和Java一样)
1) 区分相同名字的类
2) 当类很多时,可以很好的管理类
3) 控制访问范围
3.Scala中包名和源码所在的系统文件目录结构要可以不一致,但是编译后的字节码文件路径和包名会...
ETL 工具 -- KETTLE 基本使用 1
by
123456789987654321
https://www.hainiubl.com/topics/75352?
2020-10-28
⋅
5288
⋅
2
⋅
0
# Kettle
```java
软件链接:https://pan.baidu.com/s/1jF6kMg4t0UmTNicT6TefFw
提取码:irjm
```
## csv转换为excel
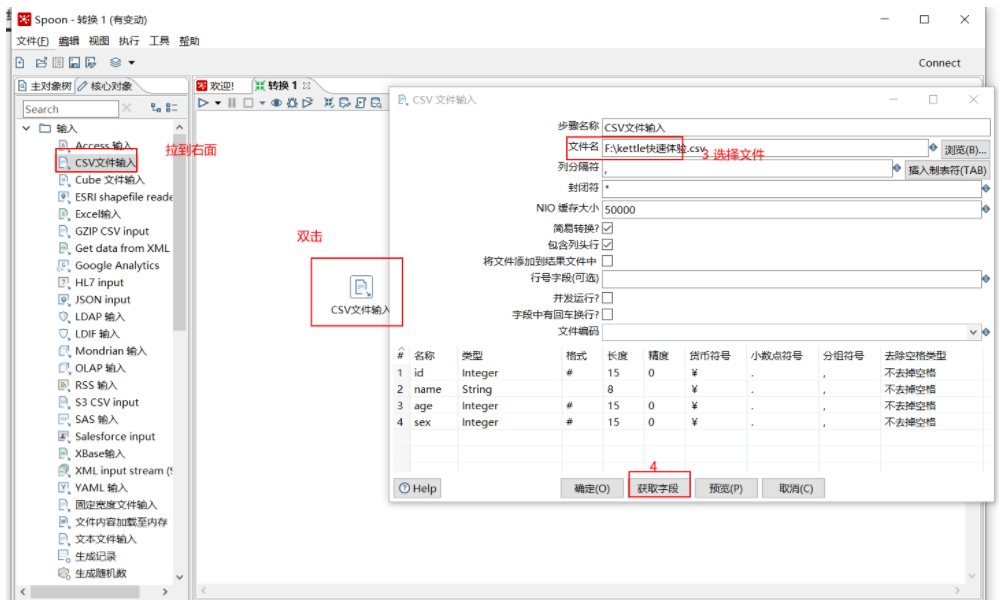
### 2.输入

JavaEE 阶段 ssd 中出现的问题?
by
 52赫兹
52赫兹
https://www.hainiubl.com/topics/75354?
2020-11-04
⋅
2391
⋅
0
⋅
3

为什么一直显示这个警告呢 ?
flink 项目中遇到两个没法处理的 bug?
by
AIZero
https://www.hainiubl.com/topics/75355?
2020-11-06
⋅
3305
⋅
0
⋅
5
1. 第一个是环境问题
只要对pom加入依赖之类的就会出现这个问题,直接处理没头绪,目前只能重新建一个工程就不会报错,想直接处理的办法
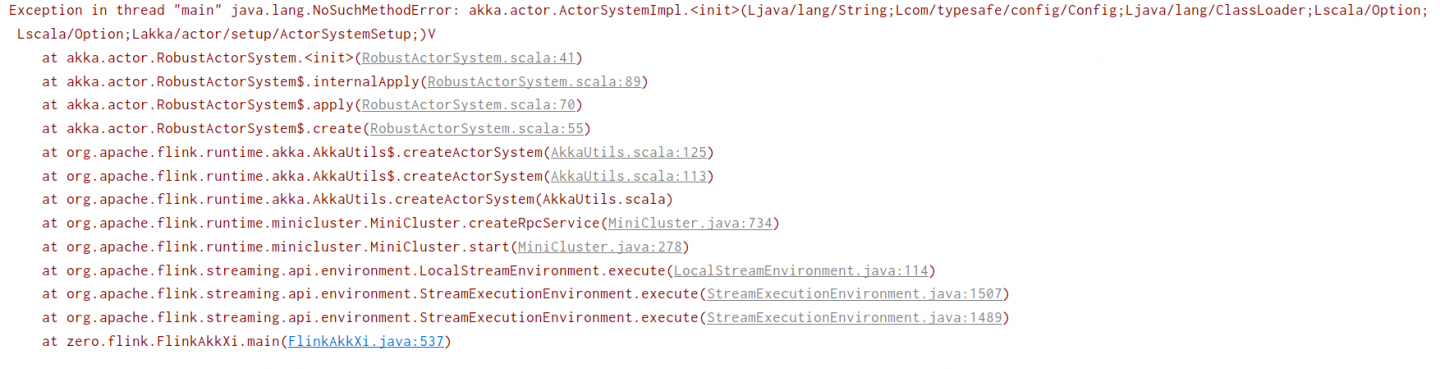
2. 第二个是flink运行时,最初几分钟都正常,过...
想成为青牛男神这样的程序员需要具备多少知识?看多少书?成长的路径怎么走?
by
ab4482559
https://www.hainiubl.com/topics/75356?
2020-11-10
⋅
3422
⋅
4
⋅
1
人总得有梦想,万一实现了呢?
表达式转型由下到上?
by
Josiah
https://www.hainiubl.com/topics/75357?
2020-11-10
⋅
2870
⋅
1
⋅
2
有这样的一堆代码
```
byte b1=1,b2=2,b3,b6,b8;
final byte b4=4,b5=6,b7;
b3=(b1+b2); /*语句1*/
b6=b4+b5; /*语句2*/
b8=(b1+b4); /*语句3*/
b7=(b2+b5); /*语句4*/
System.out.println(b3+b6);
```
为啥语句3是编译错误的呢?
b4是final 类型...
关于 python2.7 以及 python3.9 版本共处一室的个人尝试
by
 CM
CM
https://www.hainiubl.com/topics/75358?
2020-11-11
⋅
4325
⋅
0
⋅
5
# * **前言:**
众所周知,python2.7已经是python2的最后一个版本,并已经在本年度年初失去更新支持,python3以及更新到3.9了。学校的python项目采用2.7,一些项目相关的包可能无法在python3中获取。而安装完2.7后各种提示2.7将要失去更新支持,同时,学校提高的ide工...