关于 “” 的搜索结果, 共 2423 条
flink 在处理数据流中两条数据时,第一条数据处理完成,会有延迟一段时间再去处理下一条数据。请问采用什么方式避免这种情况?
by
 张浩
张浩
https://www.hainiubl.com/topics/75801?
2021-11-15
⋅
2877
⋅
0
⋅
3

flink Linux 上运行抱错?
by
 LH
LH
https://www.hainiubl.com/topics/75802?
2021-11-22
⋅
3047
⋅
0
⋅
1
我在一台linux上安装了flink 然后打包上传代码
运行命令/usr/local/flink-1.12.1/bin/flink run -c TestKafka /home/chenhui5/testJoyyKafka-1.0-SNAPSHOT-suniu.jar
然后抱错 The program's entry point class 'TestKafka' was not found in the jar file.
我就一个...
cdh 出现问题该如何解决?
by
 养猪专业户
养猪专业户
https://www.hainiubl.com/topics/75803?
2021-11-26
⋅
2268
⋅
0
⋅
1
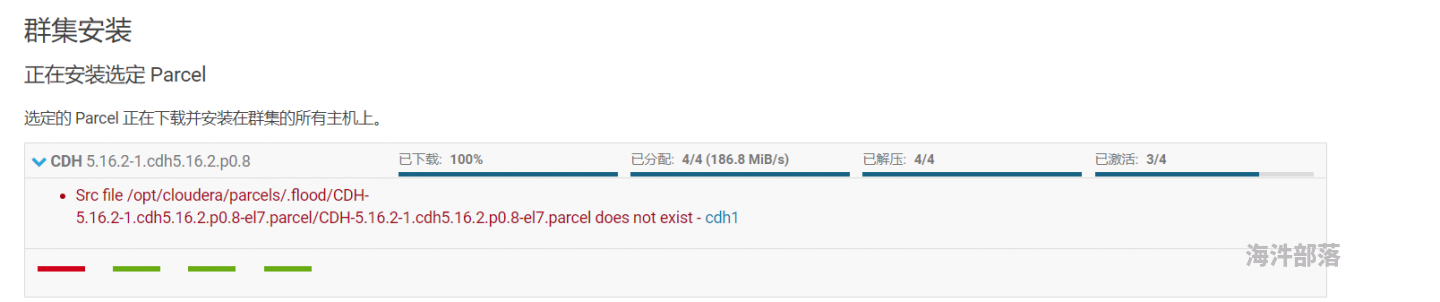
该怎么解决?
flink 消费 kafka 数据 如何保证同一分区的顺序一致性?
by
张浩
https://www.hainiubl.com/topics/75804?
2021-11-30
⋅
3896
⋅
0
⋅
2
前提:producer 按照key 分区,如下图
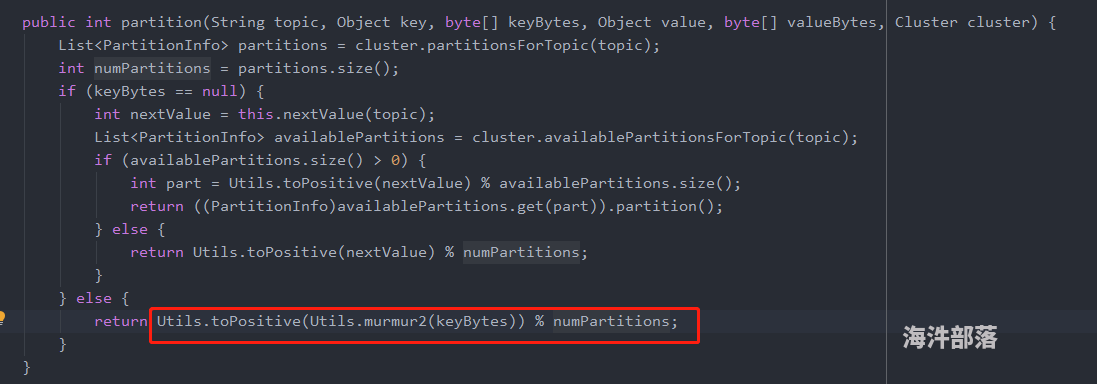
按照以上代码,相同的key的数据应该进入同一分区。
出现问题:
flink 未按照正确的顺序,消费kafka的相同key数据。
案例:

by
 123456789987654321
123456789987654321
https://www.hainiubl.com/topics/75805?
2021-12-02
⋅
8087
⋅
1
⋅
0
# Doris介绍
Apache Doris最早诞生于2008年,最初只为解决百度凤巢报表的专用系统。在08年那个时候数据存储和计算成熟的开源产品非常少,Hbase的导入性能只有大约2000条/秒,在这种不能满足业务的背景下,doris1诞生了,并且跟随百度凤巢系统一起正式上线。
Apach...
Doris 部署 (CentOS 原生部署) 2
by
123456789987654321
https://www.hainiubl.com/topics/75806?
2021-12-02
⋅
5746
⋅
1
⋅
0
## 安装
```shell
#准备三台物理机, 需要以下环境支持:
Linux (Centos 7+)
Java 1.8+
CPU需要支持AVX2指令集
`cat /proc/cpuinfo |grep avx2`
有结果输出表明CPU支持,如果没有支持,建议更换机器,
StarRocks使用向量化技术需要一定的指令集支持才能发...
解析多层 JSON 嵌套数据的时候,某些字段混有 “” {}导致解析失败?
by
LH
https://www.hainiubl.com/topics/75807?
2021-12-05
⋅
2841
⋅
0
⋅
3

解析json的时候 用的fastjson映射成java对象 但是有写数据含有多余的“” {} 导致json解析失败 用的flink处理kafka的json埋点数据
flink 消费 kafka 的数据存入 MySQL,怎么检验存入 MySQL 数据的正确性?
by
LH
https://www.hainiubl.com/topics/75808?
2021-12-07
⋅
2610
⋅
0
⋅
1
有个需求,就是用flink消费kafka的数据。经过一些列的逻辑处理后存入mysql,怎么验证或者说监控存入mysql的数据的正确性呢?有什么方法吗
flink 窗口消费 kafak 的数据 为什么数据能标准输出到控制台上,但是出不来 设置的时间窗口 60 秒?
by
LH
https://www.hainiubl.com/topics/75809?
2021-12-09
⋅
2852
⋅
0
⋅
2

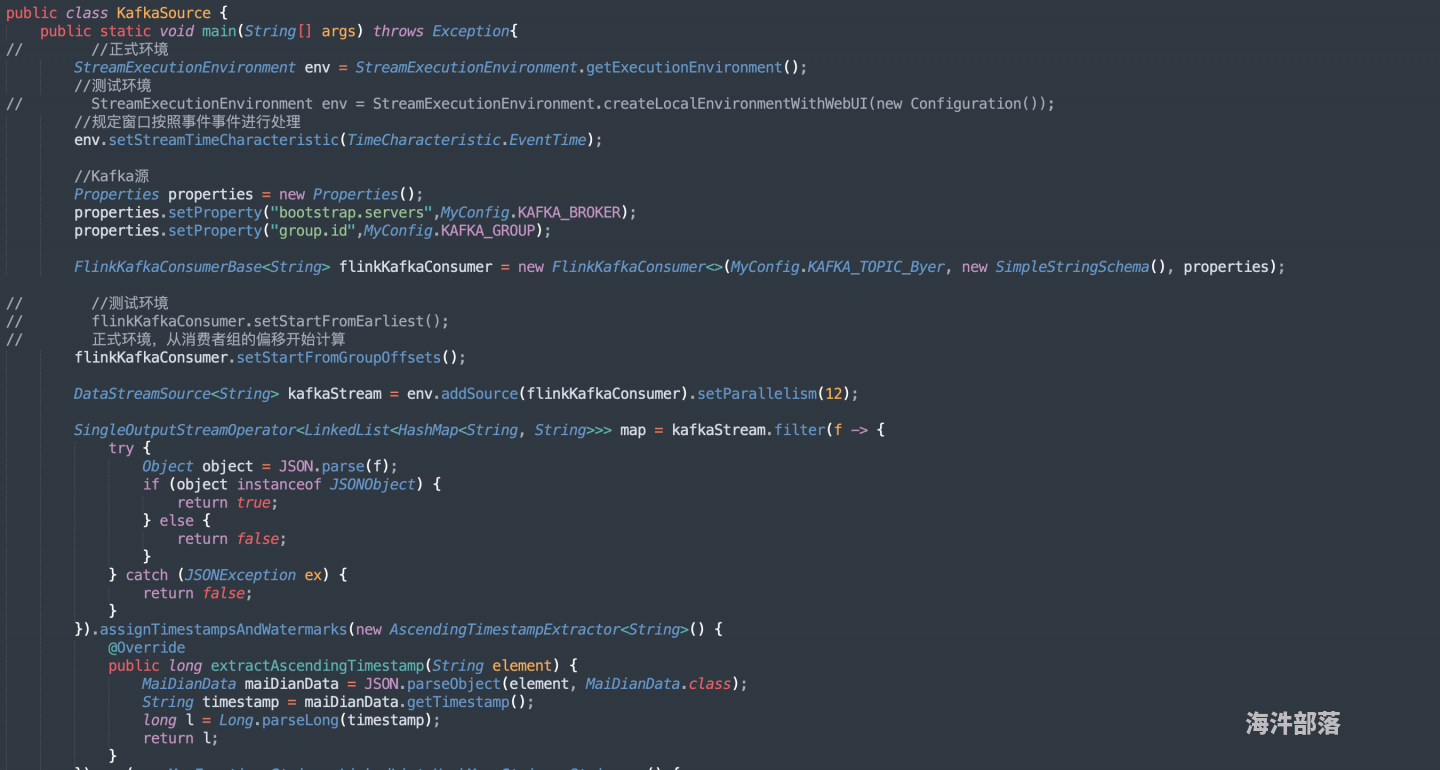
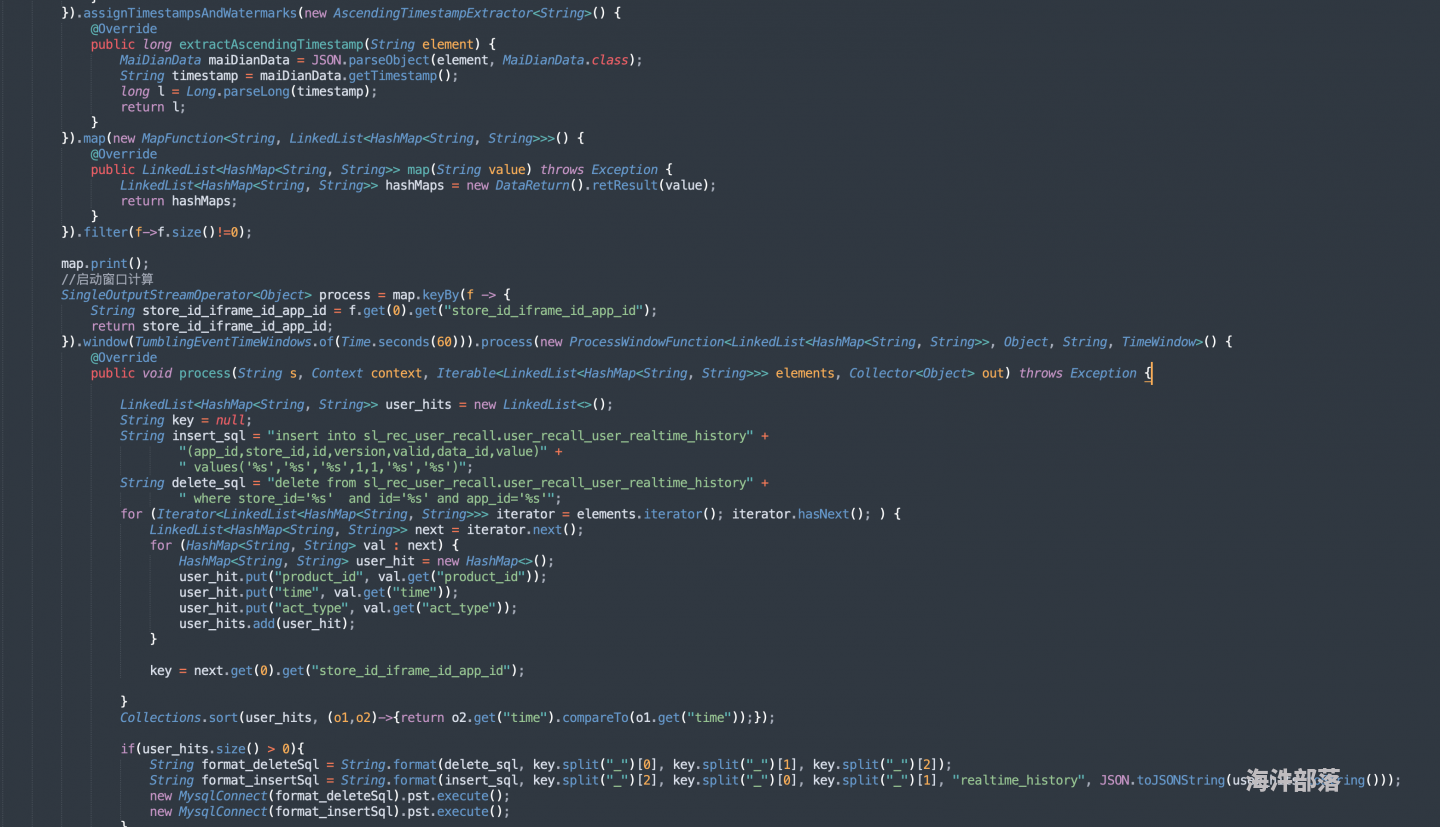
kafka的这个topic是多分...
jar 包打包失败,试了一晚上了,也没大成功?
by
123456789987654321
https://www.hainiubl.com/topics/75810?
2021-12-09
⋅
3003
⋅
0
⋅
5
麻烦大哥帮我看看
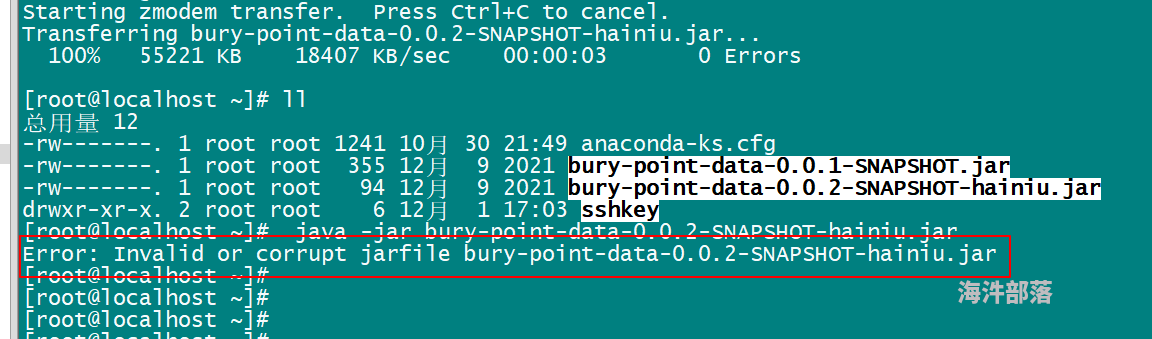
[root@localhost ~]# java -jar bury-point-data-0.0.2-SNAPSHOT-hainiu.jar
Error: Invalid or corrupt jarfile bury-point-data-0.0.2-SNAPSHOT-hainiu.jar
我照着海牛的视频部署集群,结果配置到 myql 的时候报错
by
 小兔几
小兔几
https://www.hainiubl.com/topics/75811?
2021-12-12
⋅
2654
⋅
0
⋅
1

可能是vim /etc/my.cnf 配置文件有问题,按照csdn上的配置了也没啥用
我照着视频配置 cdh 集群,结果配置到 MySQL 时报错,照着 csdn 上改了也不好使,怎么办?
by
小兔几
https://www.hainiubl.com/topics/75812?
2021-12-12
⋅
2231
⋅
1
⋅
1

flinksql 完结版
by
123456789987654321
https://www.hainiubl.com/topics/75813?
2021-12-13
⋅
2505
⋅
2
⋅
0
# FLINK
## 1.tableAPI
```java
package com.practice.apitest.tableapi;
import com.practice.apitest.beans.SensorReading;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStream...
FlinkCDC
by
123456789987654321
https://www.hainiubl.com/topics/75814?
2021-12-16
⋅
3466
⋅
1
⋅
0
# FinkCDC
## 一、测试程序
> 官方文档: https://github.com/ververica/flink-cdc-connectors
>
> https://ververica.github.io/flink-cdc-connectors/master/
>
> Flink CDC 系列 - 实时抽取 Oracle 数据,排雷和调优实践:
>
> htt...
flink 连 kafka 的方式是什么?直连还是?
by
 小小只鸟
小小只鸟
https://www.hainiubl.com/topics/75815?
2021-12-31
⋅
2731
⋅
0
⋅
1
操作环境:
flink 1.12
kafka 0.10(3个broker)
通过flink-connector-kafka的api连接的kafka,想问下flink连kafka会根据topic的分区数动态确定source并行度么.
spark sql?
by
 志欲遒
志欲遒
https://www.hainiubl.com/topics/75816?
2022-01-25
⋅
2417
⋅
0
⋅
4
##### spark sql 操作mysql
问各位大佬一个问题,在通过spark sql 先删除后插入mysql过程中,造成死锁!有什么解决办法没有啊?代码如下:
```
//先删除表数据,再插入
JdbcUtil.deleteByKey(url, prop, rawTable, "time", month)
dfRawMonthlyActiveUsers.write.m...
sql server 怎么在 hive 实现?
by
 Eliuak
Eliuak
https://www.hainiubl.com/topics/75817?
2022-01-26
⋅
2261
⋅
0
⋅
1
这个sql server怎么在hive中实现
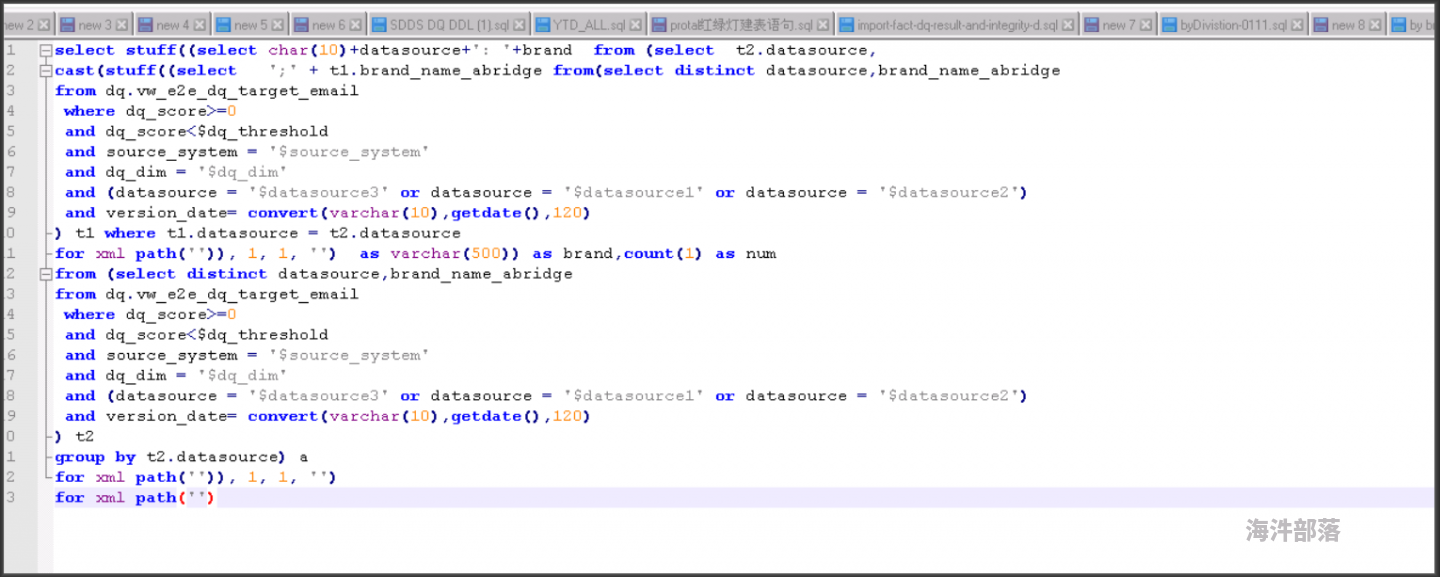
怎么给 hive 表 str 类型的 uid 映射成数值类型的唯一编号?
by
LH
https://www.hainiubl.com/topics/75818?
2022-01-29
⋅
2636
⋅
0
⋅
1
目前我们uid,iid都是str类型的 想做一个字典 映射成int类型的类似
uid1: 1
uid2:2
uid:3
这种
hive有实现这种功能的方法吗?
MySQL 基础
by
123456789987654321
https://www.hainiubl.com/topics/75819?
2022-02-15
⋅
2359
⋅
1
⋅
0
# Mysql
## 1.查看表的创建信息
```sql
-- \G换行
show create table 表名称\G
```
## 2.**MySQL**的编码设置:
2.1查看编码命令
```sql
show variables like 'character_%';
show variables like 'collation_%';
```
2.2修改mysql的数据目录下...
MySQL 存储过程,函数,触发器
by
123456789987654321
https://www.hainiubl.com/topics/75820?
2022-02-15
⋅
2315
⋅
1
⋅
0
# 存储过程
## 1.**分类**
```mysql
存储过程的参数类型可以是IN、OUT和INOUT
--注意:IN、OUT、INOUT 都可以在一个存储过程中带多个
1、没有参数(无参数无返回)
2、仅仅带 IN 类型(有参数无返回)
3、仅仅带 OUT 类型(无参数有返回)
4、既带 IN...
spark-submit 提交代码报错?
by
LH
https://www.hainiubl.com/topics/75821?
2022-02-15
⋅
2224
⋅
0
⋅
1
提交spark代码运行时报错

MySQL 用户,权限,引擎,优化操作
by
123456789987654321
https://www.hainiubl.com/topics/75822?
2022-02-16
⋅
2437
⋅
0
⋅
0
# 1.用户管理
**登录MySQL服务器**
```sql
mysql –h hostname|hostIP –P port –u username –p DatabaseName –e "SQL语句"
```
## 1.创建用户
```sql
CREATE USER 用户名 [IDENTIFIED BY '密码'][,用户名 [IDENTIFIED BY '密码']];
--CREATE USER 'kangs...
MySQL 服务器参数优化
by
123456789987654321
https://www.hainiubl.com/topics/75823?
2022-02-16
⋅
3408
⋅
1
⋅
0
# 服务器优化
## 1.**优化**MySQL的参数
**innodb_buffer_pool_size**
```sql
--表示InnoDB类型的 表 和索引的最大缓存
--它不仅仅缓存 索引数据 ,还会缓存 表的数据 。这个值越大,查询的速度就会越快。这个值太大会影响操作系统的性能。
```...
注册类时同时跑代码还是串行跑?
by
LH
https://www.hainiubl.com/topics/75824?
2022-02-18
⋅
2390
⋅
0
⋅
4
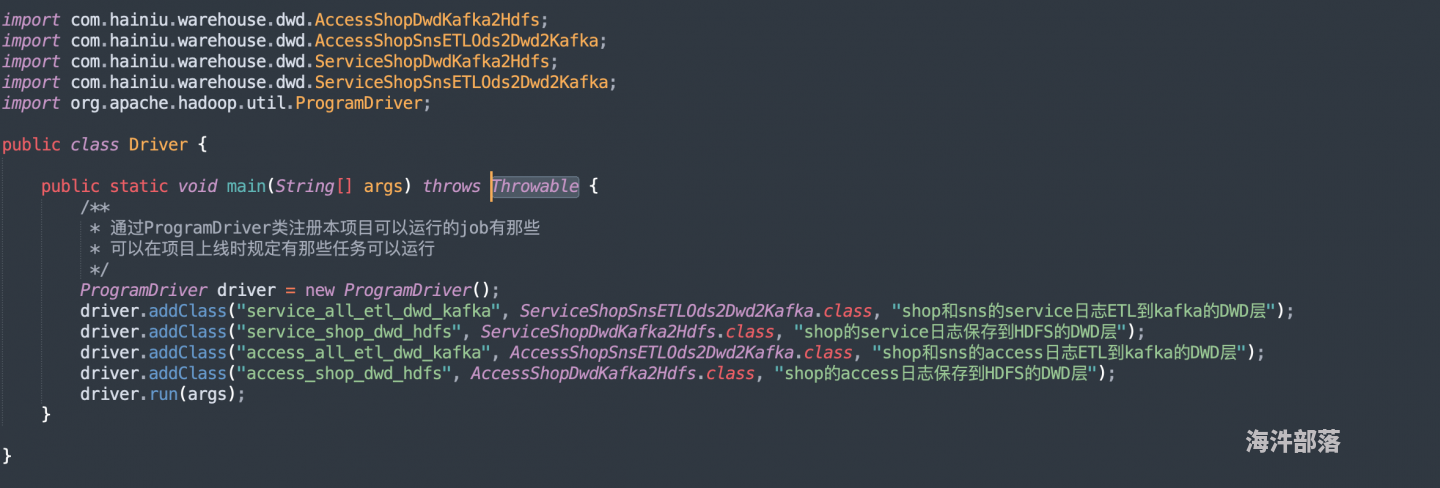
是跑完第一个注册类之后再跑第二个吗?
还是四个同时跑呀?
Docker 完整版
by
123456789987654321
https://www.hainiubl.com/topics/75826?
2022-02-24
⋅
2513
⋅
1
⋅
0
# Docker
## 1.Docker安装
docker官网
> https://docs.docker.com/engine/install/centos/
### **1.确定centos版本**
```shell
cat /etc/redhat-release #centos7 或者 8
```
### **2.卸载旧版本**
```shell
yum remove docker \...
关于 udaf 函数 reduce 阶段无法处理 map 端的输出问题?
by
 user10086
user10086
https://www.hainiubl.com/topics/75827?
2022-03-24
⋅
2040
⋅
0
⋅
1
需求是传入两个参数(xmltxt,time),按照时间顺序排序 合并xml,获取最完整的一条xml。思路是在map端将两个参数合并,添加到list里。然后reduce阶段获取所有数据再按照时间排序合并。目前在执行 函数内置 merge()方法时出问题。代码如下:
 kpwong
kpwong
https://www.hainiubl.com/topics/75828?
2022-03-25
⋅
3851
⋅
0
⋅
5
提交flink 自带的 程序 SocketWindowWordCount.jar 到yarn上 出现
Deployment took more than 60 seconds. Please check if the requested resources are available in the YARN cluster 错误。
不知道怎么解决
yarn 配置如下
<configuration>
<!-- 指定MR...
Flink 消费 kafka 数据时,LAG 堆积严重?
by
LH
https://www.hainiubl.com/topics/75829?
2022-03-28
⋅
5161
⋅
0
⋅
2
flink消费kafka latest模式。eventprocess基本就是来一条处理一条。给了12个solt。source并行度6(kafka topic六个分区)。处理逻辑给的36个并行度因为是往Tidb里面插入数据。 导致最后LAG积压严重。
设了checkpoint exactly once 60s
愁死了
parquet 格式转换成 hive 常用的格式?
by
 MrWang
MrWang
https://www.hainiubl.com/topics/75831?
2022-03-30
⋅
2229
⋅
0
⋅
1
parquet格式转换成hive常用的格式?
HDFS 写数据时,DataNode 为什么是串行写,而不是并行写?
by
 huadisan
huadisan
https://www.hainiubl.com/topics/75832?
2022-04-07
⋅
2143
⋅
0
⋅
0
HDFS写数据时,DataNode为什么是串行写,而不是并行写?