Hbase
查看acl hbase授权目录
scan 'hbase:acl'
1.查看hbase状态
status2.查看版本号
version
3.命名空间操作
#创建命名空间
create_namespace '命名空间名'
#显示所有命名空间
list_namespace
#删除命名空间
drop_namespace '命名空间名'4.创建表
--建表不用指定rowkey,但是必须指定列族
--创建默认命名空间的表 可以创建很多列族
create '表名称', '列族名称1','列族名称2'
--创建带有命名空间的表
create '命名空间:表名称', '列族名称1','列族名称2'
hbase(main):018:0> create 'mpf:mpftable','cf1','cf2','cf3'
--
create '命名空间:表名称',{NAME => '列族名称1',COMPRESSION => '(压缩格式)SNAPPY'}5.列出所有的表
#查看所有的表
list
#查询指定命名空间下的表
list_namespace_tables '命名空间'6.获取表描述
#默认命名空间
describe '表名'
#指定命名空间
describe '命名空间:表名'7. 删除列族
#删除一个列族
alter 'mpf:mpftable',{NAME=>'cf1',METHOD=>'delete'}
#删除多个列族
alter 'mpf:mpftable',{NAME='cf2',METHOD=>'delete'},{NAME='cf3',METHOD=>'delete'}8.hbase ddl操作
删除表之前必须要下线表
#把表设置为disable(下线)
disable '表名'
#drop表
#先把表下线,再drop表
disable '表名'
drop '表名'
#判断表是否存在
exists '表名'
#判断表是否下线
is_disabled '表名'
#判断表是否上线
is_enabled '表名'
9.hbase dml操作
1.添加数据
# 语法:put <table>,<rowkey>,<family:column>,<value>,<timestamp>
put '命名空间:表名','rowkey'.'列族:列族名','值' #rowkey自己定义
#cf:name 列族下面可以随便添加列字段名称
put 'xinniu:table3','x0001','cf:name','user1'
2.查询数据
#get方式获取单条.
查看表下面的 指定表的 某个rowkey的所有值
get 'xinniu:table3','x00001'
get 'xinniu:table3','x00001','cf1'
查看表下面的 指定表的 某个rowkey的 某个列族下的某个列的 所有值
get 'xinniu:table3','x00001','cf2:address'
3.更新数据
获取指定版本数据 指定版本号,取指定版本数据。 TIMESTAMP不加引号
get 'xinniu:table3','x00001',{COLUMN=>'cf1:age',TIMESTAMP=>1621673127490}
4.扫描表
#Scan ‘表名’,这个动作是全表扫描,如果指定了startrow和endrow则变为范围查询,filter是全表扫。
#扫描全表
scan '表名'
#扫描全表,limit行数
limit限制的是某一个rowkey的值,只会显示第一个rowkey相同的值
scan 'xinniu:table3',{LIMIT => 1}
#查询指定列族
scan 'xinniu:table3', {COLUMNS => 'cf1'}
#查询指定列数据
scan 'xinniu:table3', {COLUMNS => 'cf2:address'}
#扫描表中值=23 的数据
binary 是等于的意思
scan 'xinniu:table3', FILTER=>"ValueFilter(=,'binary:23')"
使用rowkey范围查询,STARTROW与ENDROW是前闭后开的
'|' 代表的是无限大
这样查询是不会扫描全表的
scan 'xinniu:table3', { STARTROW => 'x00001', STOPROW => '|'}
scan 'xinniu:table3', { STARTROW => 'x00001', STOPROW => 'x00002'}
scan 'xinniu:table3', { STARTROW => 'x00001', STOPROW => '|',LIMIT => 3,COLUMN => 'cf1:name'}
scan 'xinniu:table3', { STARTROW => 'x00001', STOPROW => '|',LIMIT => 1,COLUMN => 'cf1:name'}
5.删除某列数据
# 语法:delete <table>, <rowkey>, <family:column>
# 必须指定列名
# 会删除执行列的所有版本数据
delete '命名空间:表名','rowkey','列族名:列字段名'
delete 'mpf:mpftable','x001','cf1:name'
5.1删除整行数据
# 语法:deleteall <table>, <rowkey>
deleteall 'mpf:mpftable','x001'
6.清空表数据
先执行的是关闭表操作
然后在进行清空
#清空表数据且不保留region信息
truncate <table>
#清空表数据保留region信息
truncate_preserve <table>
7.查询表有多少行--> count
INTERVAL设置多少行显示一次及对应的rowkey,默认1000;
CACHE每次去取的缓存区大小,默认是10,调整该参数可提高查询速度
# 语法:count <table>, {INTERVAL => intervalNum, CACHE => cacheNum}
#使用count统计table3行数
每3行显示一次, 每次去缓存取6条
count 'xinniu:table3',{INTERVAL => 3,CACHE => 6}
#put数据用于统计行数
put 'xinniu:table3','id06', 'cf2:cert_no','110625'
put 'xinniu:table3','id06', 'cf2:cert_type','身份证'
put 'xinniu:table3','id07', 'cf2:cert_no','110725'
put 'xinniu:table3','id07', 'cf2:cert_type','身份证'
put 'xinniu:table3','id08', 'cf2:cert_no','110825'
put 'xinniu:table3','id08', 'cf2:cert_type','身份证'
put 'xinniu:table3','id09', 'cf2:cert_no','110925'
put 'xinniu:table3','id09', 'cf2:cert_type','身份证'
put 'xinniu:table3','id10', 'cf2:cert_no','110925'
put 'xinniu:table3','id11', 'cf2:cert_type','身份证'
put 'xinniu:table3','id01', 'cf2:cert_no','110925'
put 'xinniu:table3','id02', 'cf2:cert_type','身份证'
put 'xinniu:table3','id03', 'cf2:cert_no','110925'
put 'xinniu:table3','id03', 'cf2:cert_type','身份证'
put 'xinniu:table3','id04', 'cf2:cert_no','110925'
put 'xinniu:table3','id04', 'cf2:cert_type','身份证'
put 'xinniu:table3','id05', 'cf2:cert_no','110925'
put 'xinniu:table3','id05', 'cf2:cert_type','身份证'
8.大表count
在linux执行,不是在hbase shell里面查询
#大表取多少条使用如下方式进行统计。
#语法
hbase org.apache.hadoop.hbase.mapreduce.RowCounter ‘tablename’
#例如
hbase org.apache.hadoop.hbase.mapreduce.RowCounter 'mpftable'
1.)cdh设置用户id1到1000有效
想用超级管理员去跑,这里需要改为1,然后重启yarn
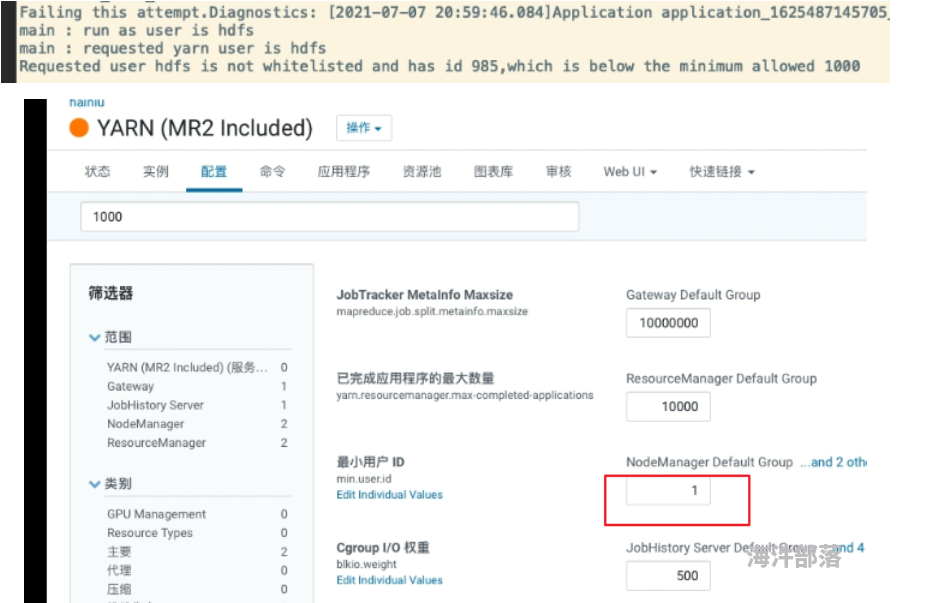
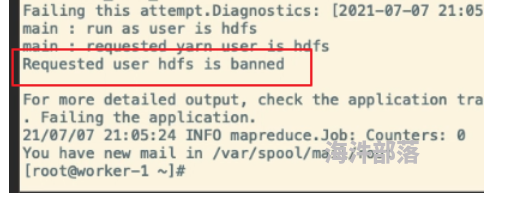
2.)用户被禁用 -->删掉hdfs用户 重启yarn

9.counter计数器
#该场景适合在一些实时场景使用,如某点击类事件触发时则在hbase中incr一条,用于统计累计点击数比较方便。
#语法: incr <tablename>,<rowkey>,<family:column>,long n
# 给表的指定行指定列族的指定列设置计数器
插入的时候 列字段不能一样
incr 'xinniu:table3','id01','cf1:cert_no',1
#获取counter数
get_counter 'xinniu:table3', 'id01', 'cf1:cert_no'
#多用于统计点击量等场景使用较多
10.多版本管理 即,相同rowkey相同列插入不同值。
相同rowkey 相同列 插入不同值。
#1.建表
create 'mpf:mpftable1','cf1'
#2.修改设置版本,查询时,加上版本就可以查出来版本
alter 'mpf:mpftable1',{ NAME =>'cf1', VERSIONS => 2 }
#插入多个版本数据
put 'mpf:mpftable1','id01','cf1:cert_no','version1'
put 'mpf:mpftable1','id01','cf1:cert_no','version2'
put 'mpf:mpftable1','id01','cf1:cert_no','version3'
#获取指定版本数据
get 'mpf:mpftable1', 'id01', { COLUMN =>'cf1:cert_no', VERSIONS => 2}
10.hbase预分region
#为什么要预分region
#不预分region,hbase默认只有一个region,并且startkey和endkey不指定,只有触发了region split之后才会分裂成多个region,当写入的数据量较大的时候会伴随着频繁的region split操作,严重影响性能,同时不能充分利用IO性能,造成因IO瓶颈影响写入性能。
#预分region后一张表的数据被预分到不同的region上,同时向多个region中写数据,大大提升了并发,且减少了region split的次数,避免单节点IO瓶颈问题。
#建表时预分region
#region个数
#官方推荐region个数计算公式:
(RSXmx*hbase.regionserver.global.memstore.size)/(hbase.hregion.memstore.flush.size*column familys)
#RS Xmx为regionserver堆栈内存大小,官方推荐每台regionserver内存大小设置20-24G,不推荐设置更大,因为 更大的堆栈内存GC效率较低
#hbase.regionserver.global.memstore.size为整个regionserver中memstore总大小占用总内存的比例,一般默认为0.4
#hbase.hregion.memstore.flush.size为memstoreflush阈值,一般默认128,可以自己设置column familys为列族数
#例:(20G*0.4)/(128M*2)=32
#官方推荐每个regionserver上region个数在20-200之间。
#region大小
#单个region官方推荐大小为5-10GB,
#可以通过hbase.hregion.max.filesize设置,当超过该值后会触发split,与region split策略相关。
#预分region需要考虑两个因素,即 region个数与region大小。
#预分region
#1.VERSIONS => 3 最大版本数有三个
#2.预分region的{}放到后面
#3.SPLITS_FILE => 文件地址,里面文件写的是,region从几到几
#实现步骤
#1.创建SPLITS_FILE: 文件里面内容
1
10
20
30
40
50
60
#2.创建表
create 'xinniu:advance_split_region',{NAME => 'cf',VERSIONS => 3},
{SPLITS_FILE => '/tmp/advance_split_region_file'}
#3.查看预分region数量
11.开启压缩
#查看压缩方式
describe '命名空间:表名'
#建表时指定压缩格式,开启压缩后可以非常有效的缓解hbase数据膨胀问题。
# NAME 列族名
create 'xinniu:compression_table',{NAME => 'cf',VERSIONS => 3,COMPRESSION => 'SNAPPY'}, {SPLITS_FILE => '/tmp/advance_split_region_file'}
hive数据导入hbase
1 .使用hbase外表方式加载(第一种方式)
#在hive中创建hbase外表,并指定hbase表名,将hbase映射到hive表。
#在hive中向hbase外表中插入数据,将数据同步到hbase中。
#不需要在hdfs建表,但是必须要用hive的内表去做. 如果要用外表方式,必须现在hbase建表
# 1.创建hbase外表
create 'xinniu:dataload2',{NAME => 'cf',COMPRESSION => 'SNAPPY'}
#2.准备hive源表数据
create table xinniu.source_table4hbase(
key string,
pk string,
col1 string,
col2 string,
datatime string
)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
#:key指的是主键,往外表家在数据的固定写法
WITH SERDEPROPERTIES ("hbase.columns.mapping" =":key,cf:pk,cf:col1,cf:col2,cf:datatime")
TBLPROPERTIES("hbase.table.name" = "xinniu:dataload1");
#3.查询hive表数据插入到hbase外表中
insert into table xinniu.source_table4hbase select concat(pk,datatime) key,pk pk,col1 col1,col2 col2,datatime datatime from xinniu.source_table;
查询hbase表数据
scan '命名空间:表名'
2.importTSV+bulkload(第二种方式)
#importTSV 只支持 text 或者 csv
#参数详解
#-Dimporttsv.separator指定分隔符
#-Dimporttsv.columns指定列映射:HBASE_ROW_KEY强制要求写,cf:pk指定rowkey字段,其他字段与hive表中对应
#-Dimporttsv.skip.bad.lines是否跳过无效行
#-Dimporttsv.bulk.output:hfile输出路径
1.使用importTSV生成hfile文件
#1.执行语句 在hdfs上创建文件 在linux下面执行,不在hive下面执行
hbase org.apache.hadoop.hbase.mapreduce.ImportTsv
# | 指定的hive的分隔符
-Dimporttsv.separator='|'
# HBASE_ROW_KEY 指定列 必须要写, 其预期段位表的映射关系
-Dimporttsv.columns=HBASE_ROW_KEY,cf:pk,cf:col1,cf:col2,cf:datatime
#是否跳过无效行 false如果遇到无效的,整个任务就退回去了
-Dimporttsv.skip.bad.lines=false
# hfile输出路径 xinniu:dataload2 指定的是在hbase创建的表的表名
-Dimporttsv.bulk.output=/user/xinniu/hfile xinniu:dataload2
#hive这张表的路径 在hdfs的路径s
hdfs://ns1/hive/warehouse/xinniu.db/source_table/datatime=20210107/sourcedata-20210107
2.使用bulkload加载数据到hbase表中
#语法 xxxLoadIncrementalHFiles hfile路径(上一步的输出路径) hbase表名
hbase org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles /user/xinniu/hfile xinniu:dataload2
导出hbase数据
使用hive外表的方式导出hbase数据(这张外表就是用来导数据的,不是用来分析查询的,如果外表被删掉hbase数据也不会被删掉,另外如果hbase表已经存在,hive创建内表会报错)
使用hive外表的方式先关联到hbase 表,然后将hive外表数据导出到指定目录。
--加载本地数据到 hive外表
insert overwrite local directory'/tmp/xinniu/source_table4hbase'
row format delimited fields terminated by ','
select * from xinniu.source_table4hbase;
hbase数据导出为orc文件
如果需要导出为orc文件,则需要创建一张临时的orc表,再将hbase外表的数据查询插入到orc表中,再将orc表数据执行导出,导出orc文件到指定路径。
-- 创建orc表
create table orctable stored as orc
as
select * from source_table4hbase
where 1=0;
-- 通过hbase的hive外表将数据导入到orc表中
insert into table orctable
select * from source_table4hbase;



