这得要看你系统上yum的安装目录在那里了。/etc/yum.repos.d 这个是centos的默认目录,你要是用的是ubuntu linux就不会有这个目录。
- 安装 hadoop 发现缺少 CentOS-Base.repo 文件
- spark 调用 jdbc 连接数据库问题?
- spark 为什么自动设置查询字段自带双引号,看可以设置吗?
- Scala 特殊的简写看不懂,内容如下?
- spark 中 spark.sql.warehouse.dir 怎么设置成 HDFS 的上的数据,求个格式?
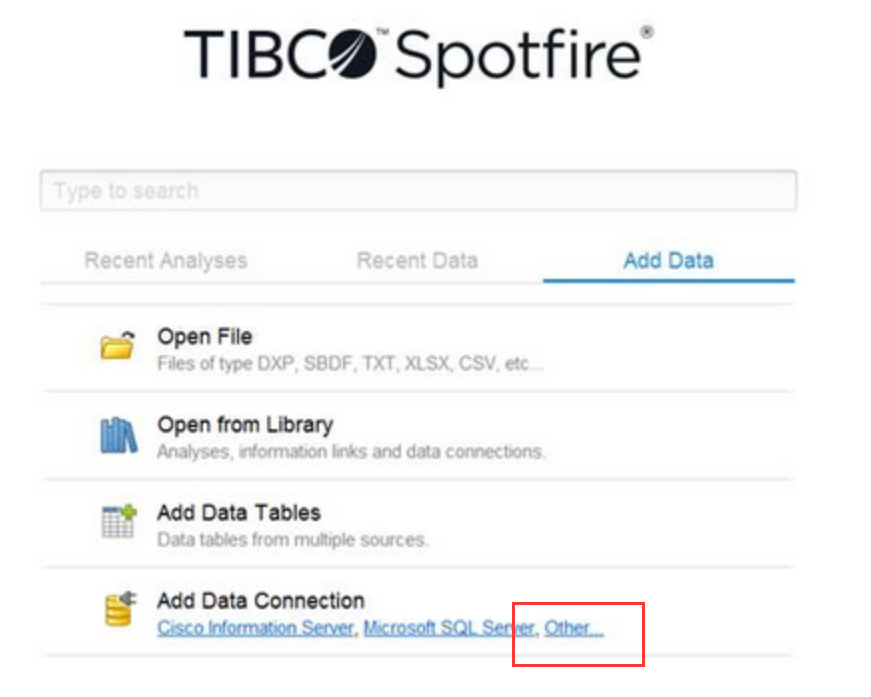
- how to configure my spotfire with hive database?
- how to configure my spotfire with hive database?
- java 第一个程序报错 编译成功 但执 java Hello 时找不到或无法加载主类?
- Zookeeper 异常 ConnectionLossException 怎么办?
- 这个 hbase 的 region 达到多大才会分区呢?
- 如何解释 hadoop 的边缘节点
- python?求大神指点?
- spark 通过 jdbc 方式连接 impala 为什么没有数据只有字段名?
- CDH spark 问题?
- 海牛部落 hive 系列教程(十九):hive 介绍与安装