xgboost gbdt lightGbm都有这个参数 有些模型不需要权重 不是所有的模型都需要的
-
信息被删除或无权限查看
- 数据挖掘时,当正负样本不均,代码如何实现改变正负样本权重?
- Spark 如何获得当前 alive 节点的个数?
- 为什么 Spark 比 MapReduce 快?
- HDFS 中元数据和数据为什么要分离?
- 为什么 hadoop 不直接采用 lustre 而要用 hdfs?
- 为什么 hdfs 不支持随机写?
- 请问 HDFS、TFS、GFS 等分布式文件系统,哪个更适合用来做视频存储?
- 有没有可能将 Java 源代码编译成 LLVM 能接受的中间形式,以执行 Java 程序?
- JAVA 中 finally 之前有 return 语句该如何执行?
- Java 程序每次运行都需要编译一次吗?
- yarn 与 hdfs 的关系?
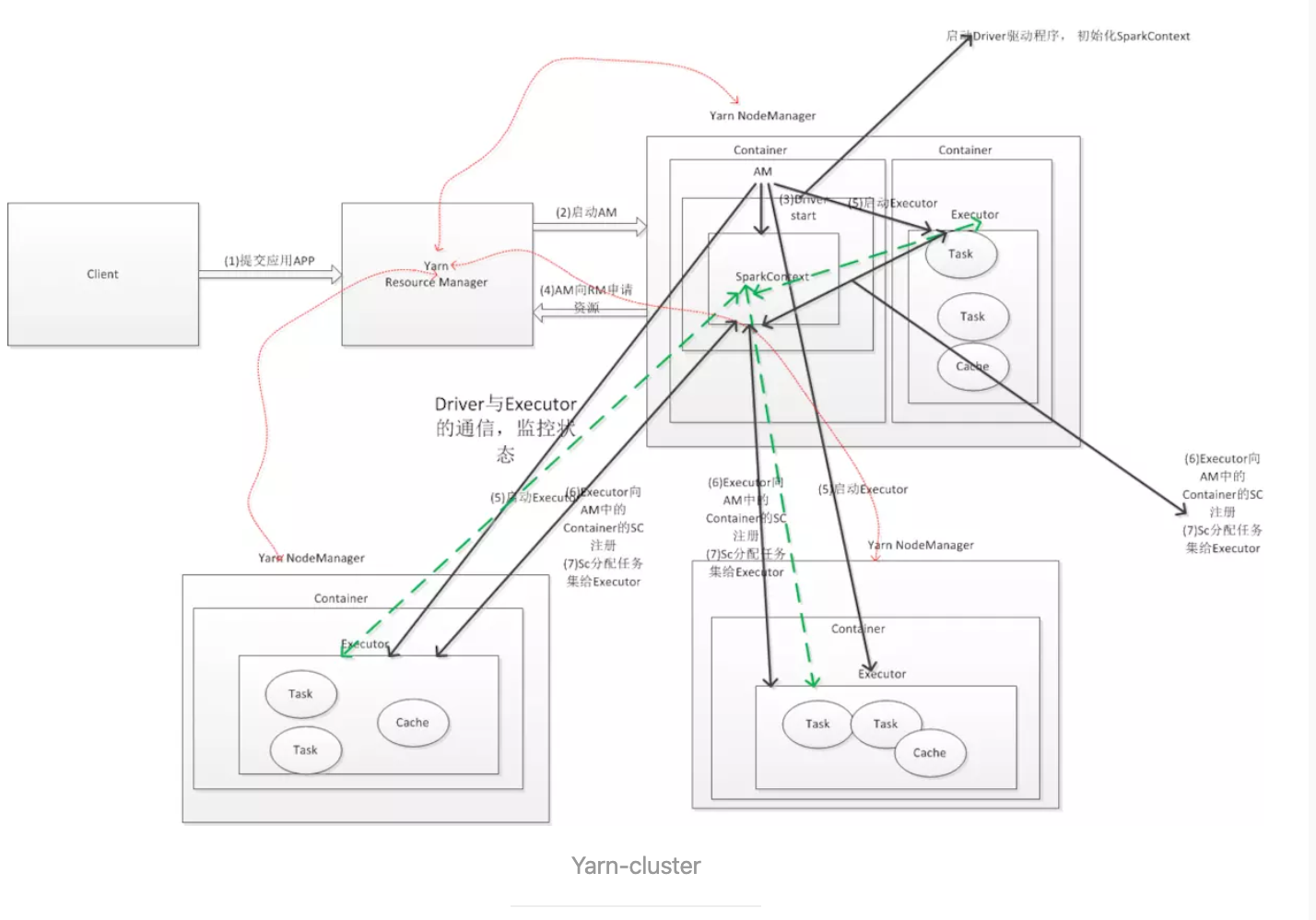
- spark 如何和 yarn 结合的?
- Yarn 的出现到底给 MapReduce、Spark 等带来了什么?
-
信息被删除或无权限查看