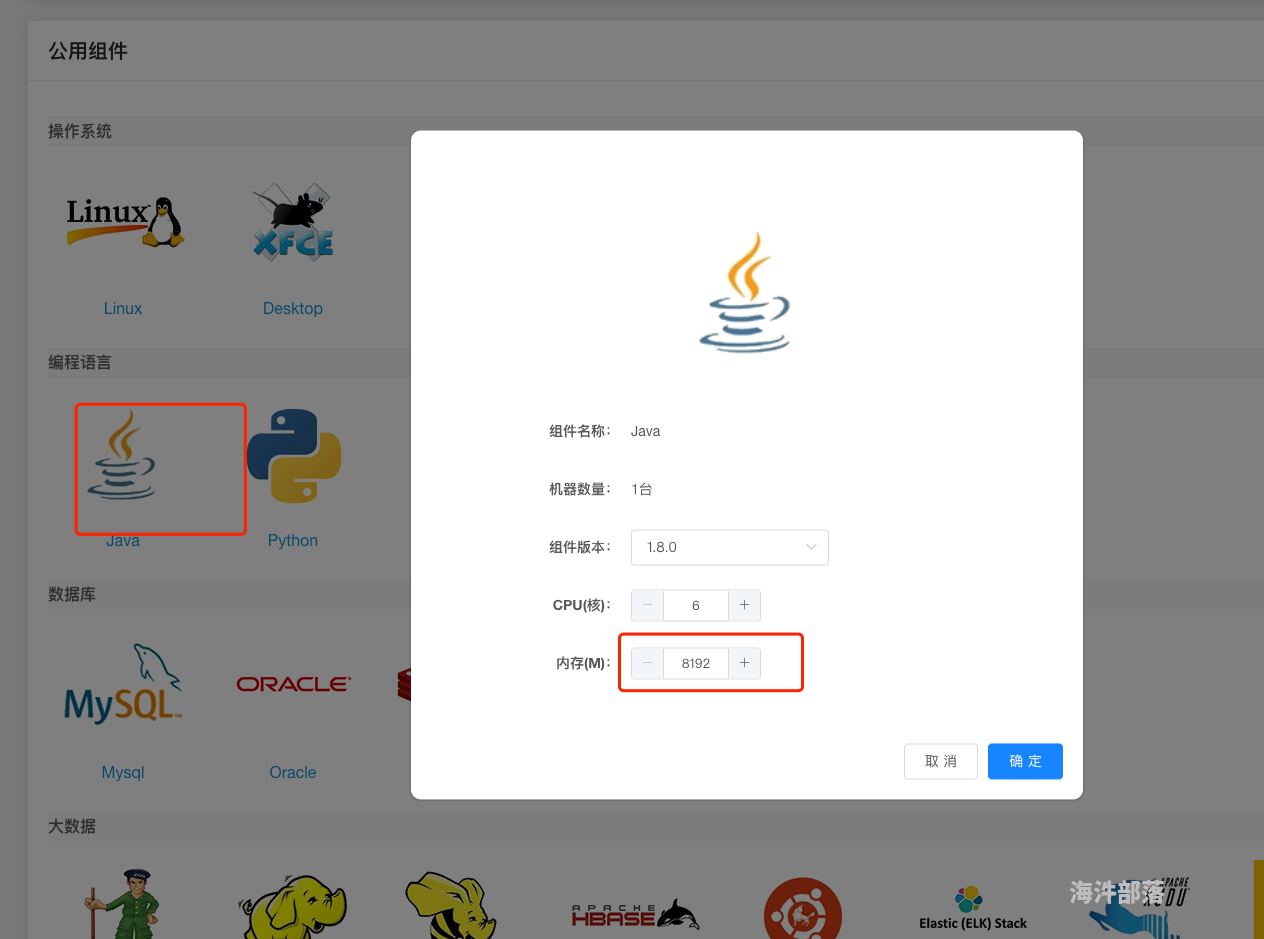
@NEMOlv 之前的临时桌面配置高,后来上线正式桌面了,那个配置就降低了
- spark 使用的是 local 模式,在临时桌面上内存不足,请问应该如何修改?
- spark 使用的是 local 模式,在临时桌面上内存不足,请问应该如何修改?
- spark-submit 提交无法连接 master?
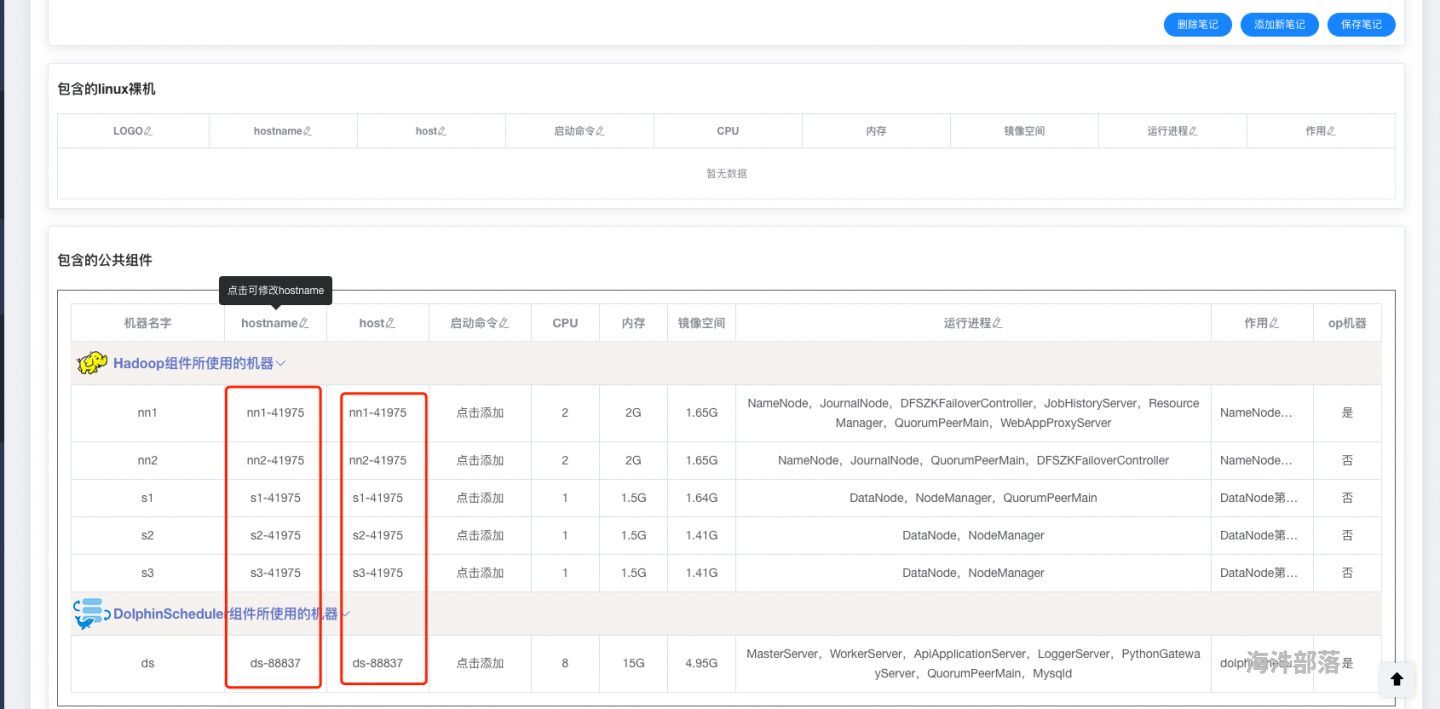
- 在启动镜像时,host 与 hostname 不对应?
- 在启动镜像时,host 与 hostname 不对应?
- 可不可以 Web 上搞个上商店,方便购买 VPN 和扩容资源?
- 使用云平台 Spark 的默认配置可以支持百万级大数据的处理吗?
- datanode 挂了?
- [下载] 大数据面试宝典
- 镜像文件如何与我本地 IP 互通?
- 安装包?
- 大数据现在用 python 学好一点,还是用 Java 学?
- 大数据现在用 python 学好一点,还是用 Java 学?
- 大数据现在用 python 学好一点,还是用 Java 学?
- 大数据现在用 python 学好一点,还是用 Java 学?