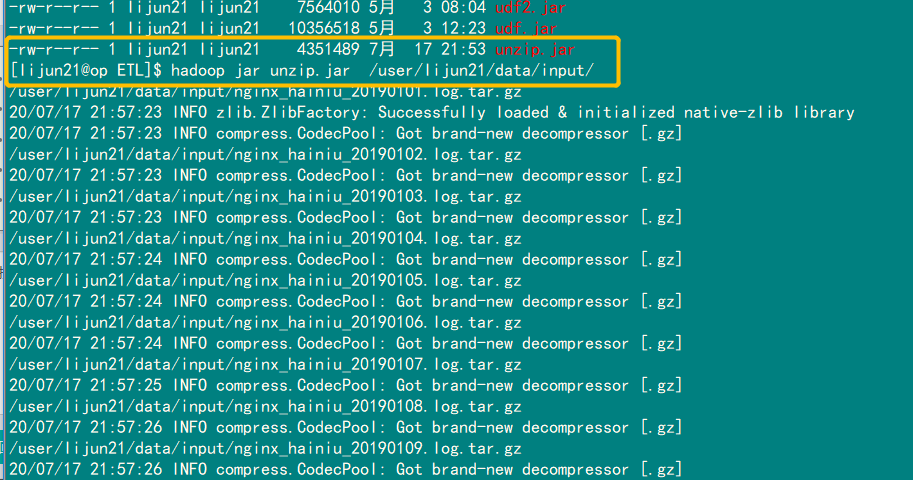
上次在做老苏的ETL项目的时候,为了方便,为了操作方便,老苏提供都是.gz文件和.tar.gz文件(至于这些怎么用xargs提取的,这里就不再详细说明) 大家都知道hdfs的命令并没有解压操作,如果我想在hdfs上解压400多个文件,该如何操作呢?此时我们就可以用一个非常牛逼的类叫做CompressionCodecFactory,里面提供的api可以帮我们实现
1.首先这个api只能对单个文件进行解压,并不能对一个文件夹下的所有文件操作,而且解压后的文件文件名和路径名也要给全才可以,因此我们需要先将这些文件追加到本地文件中: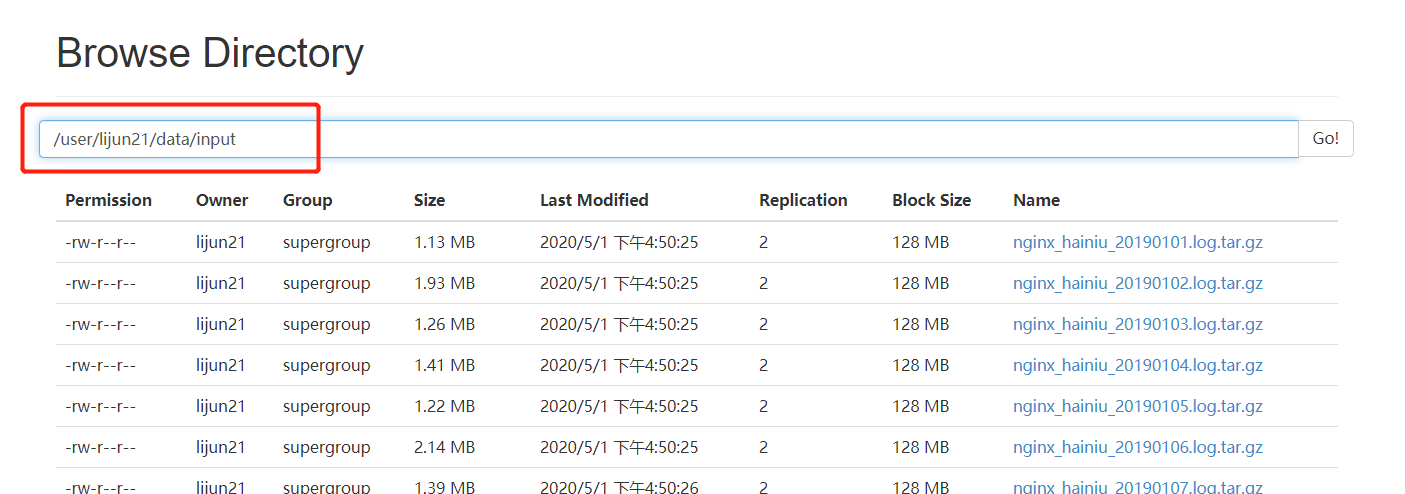

lee2文件内容如下: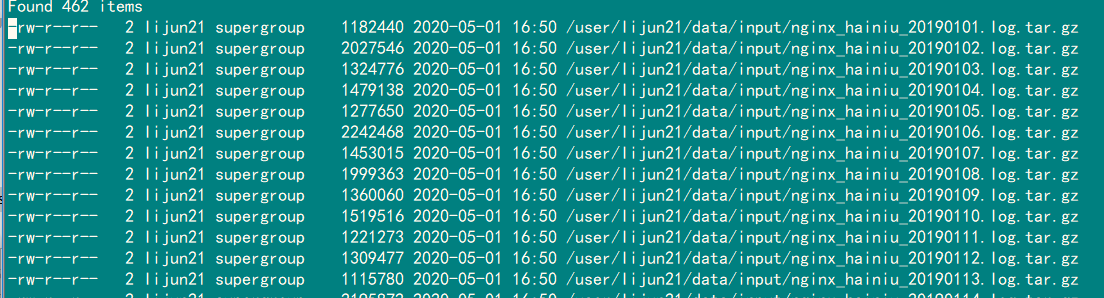
用sz命令导出lee2 文件到windows 中 再用notpad++ 操作一波:
去掉第一行数据,并将所有分隔符换成\t格式,
为了简化mr操作,我们把\也换成\t 分割,得到的文件是这样的
2.编写一个Mapreduce程序,将这个文件中的最后一个元素输出:
public class MR_LOG_CUT extends Configured implements Tool {
//-Dmapreduce.job.reduces=4
@Override
public int run(String[] args) throws Exception {
// 创建hadoop配置文件的加载对象
Configuration myConf = this.getConf();
Job job = Job.getInstance(myConf, "etl_cut");
job.setJarByClass(MR_LOG_CUT.class);
//数据片 -- 输入格式化 -- M --- R ---输出格式化
job.setInputFormatClass(TextInputFormat.class);
job.setMapperClass(MyMapper.class);
//reduce设置
job.setReducerClass(MyReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(NullWritable.class);
//设置输出格式化 文本
job.setOutputFormatClass(TextOutputFormat.class);
//设置I/O路径
Path in = new Path(args[0]);
Path out = new Path(args[1]);
//输出路径必须不存在
FileSystem fs = FileSystem.get(myConf);
if (fs.exists(out)) {
//true 表示 hadoop fs -rm -r -skipTrash
fs.delete(out, true);
System.out.println(job.getJobName() + "'s outputDir has been deleted ");
}
FileInputFormat.addInputPath(job, in);
FileOutputFormat.setOutputPath(job, out);
long start = System.currentTimeMillis();
//运行代码
boolean con = job.waitForCompletion(true);
long end = System.currentTimeMillis();
System.out.println(con ? "JOB_STATUS : SUCCESS" : "JOB_STATUS : FILED");
//运行时间
System.out.println("JOB_COST : " + (end - start) / 1000 + " SECONDS");
return 0;
}
private static class MyMapper extends Mapper<LongWritable, Text, Text, NullWritable> {
private Text outKey = new Text(); //创建 key 对象 text类型
private NullWritable outval = NullWritable.get();
private String[] strs = null; //存储切割的字符串数组
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
strs = value.toString().split("\t"); //不需要key值,key值这是行号,无用
//最后一个元素就是我们需要的
outKey.set(strs[strs.length - 1]);
context.write(outKey, outval);
}
}
//reduce的输入是map的输出,输出根据实际情况定
private static class MyReducer extends Reducer<Text, NullWritable, Text, NullWritable> {
//聚合输出,因为没重复的key所以不会聚合咯
@Override
protected void reduce(Text key, Iterable<NullWritable> values, Context context) throws IOException, InterruptedException {
context.write(key, NullWritable.get());
}
}
public static void main(String[] args) throws Exception {
System.exit(ToolRunner.run(new MR_LOG_CUT(), args));
}
}输出后的文件是这样的,然后我们新建一个解压类,放在resource目录下进行加压操作:
为什么要这么做呢,因为该方法只能一个文件一个文件地解压,所以我们需要一个一个遍历文件全路径名来读取每一个.gz/.tar.tar.gz文件,解压完成后我们还需要根据文件名来拼每一个文件的输出路径,所以先写一个根据文件名生成输出路径的工具类如图所示: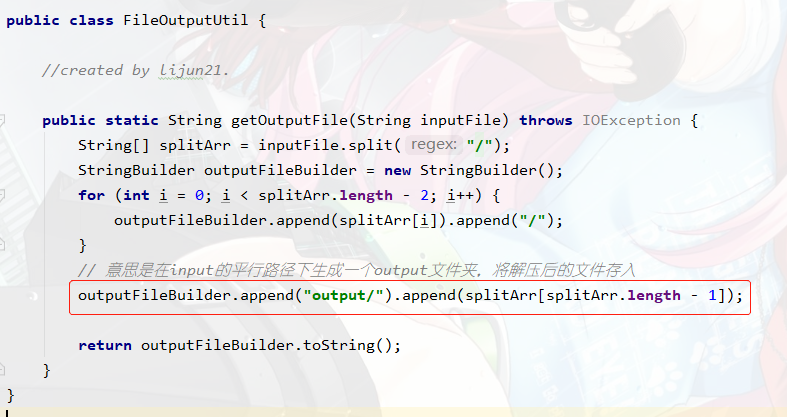
- 进行解压逻辑操作,主要思路是:先依次读取我们的压缩文件名文件 part-r-00000 ,再创建url 根据CompressionCodecFactory 来判断文件的压缩格式,进行解压,设置我们的解压后文件名,用IOUtils完成解压后输出,具体代码如下:
import com.lee.utils.FileOutputUtil;
import jline.internal.InputStreamReader;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.io.compress.CompressionCodec;
import org.apache.hadoop.io.compress.CompressionCodecFactory;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
import java.net.URI;
public class LeeFileDecompressor {
//实现批量解压数据
public static void main(String[] args) {
LeeFileDecompressor fd = new LeeFileDecompressor();
// 将文件加载到内存
InputStream in = null;
String filePath;
BufferedReader reader = null;
try {
//加载资源
in = LeeFileDecompressor.class.getClassLoader().getResourceAsStream("part-r-00000");
// 因为是字符流 所以用 BufferedReader 进行解析
reader = new BufferedReader(new InputStreamReader(in, "UTF-8"));
String line;
while ((line = reader.readLine()) != null) {
// 获取到数据
if (!"".equals(line.trim())) {
//构建文件路径,args[0]是输出路径名,需带 ‘/’
filePath = (args[0] + line).trim();
fd.UnzipOne(filePath);
}
}
} catch (Exception e) {
e.printStackTrace();
} finally {
try {
if (null != reader) {
reader.close();
}
if (null != in) {
in.close();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
public void UnzipOne(String fileDir) {
InputStream in = null;
OutputStream out = null;
String outputUri ;
FileSystem fs;
try {
Configuration conf = new Configuration();
// 输入路径,args[0] 给出
String uri = fileDir;
System.out.println(uri);
// 得到输入文件系统
fs = FileSystem.get(URI.create(uri), conf);
// 得到输入路径的Path格式
Path inputPath = new Path(uri);
// System.out.println("输入路径是:" + inputPath);
CompressionCodecFactory factory = new CompressionCodecFactory(conf);
// 检测输入路径是否存在压缩类型
CompressionCodec codec = factory.getCodec(inputPath);
if (codec == null) {
System.err.println("未发现压缩格式哦: " + uri);
System.exit(1);
}
//注意,这里写的getOutputFile() 是获得在input的同级目录下新建一个output目录存放解压文件
if (uri.endsWith(".tar.gz")) {
//如果是 .tar.gz结尾 则直接去掉
outputUri =
CompressionCodecFactory.removeSuffix(FileOutputUtil.getOutputFile(uri), ".tar.gz");
} else{
outputUri =
//否则就是.gz结尾的直接去除即可
CompressionCodecFactory.removeSuffix(FileOutputUtil.getOutputFile(uri), ".gz");
}
// 创建输入流
in = codec.createInputStream(fs.open(inputPath));
out = fs.create(new Path(outputUri));
//输出到input同级目录下的output文件中
IOUtils.copyBytes(in, out, conf);
} catch (IOException e) {
e.printStackTrace();
} finally {
IOUtils.closeStream(in);
IOUtils.closeStream(out);
}
}
}
- 指明mainClass, 打jar包,直接运行,需要给出文件的输出路径,需要带上\:
-


查看运行的控制台输出:
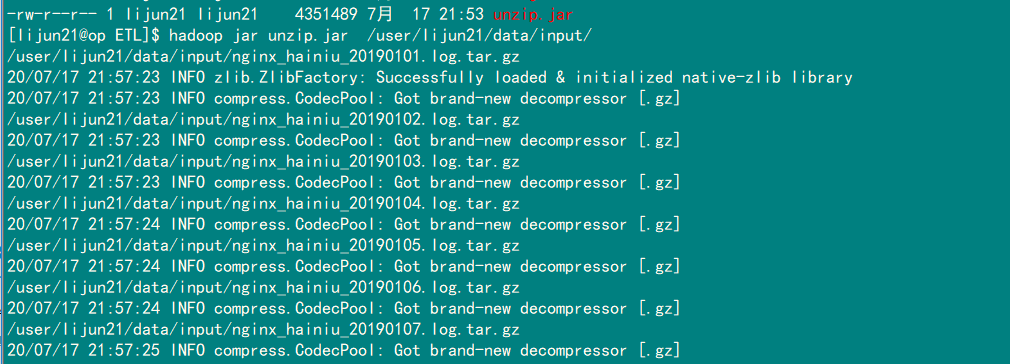
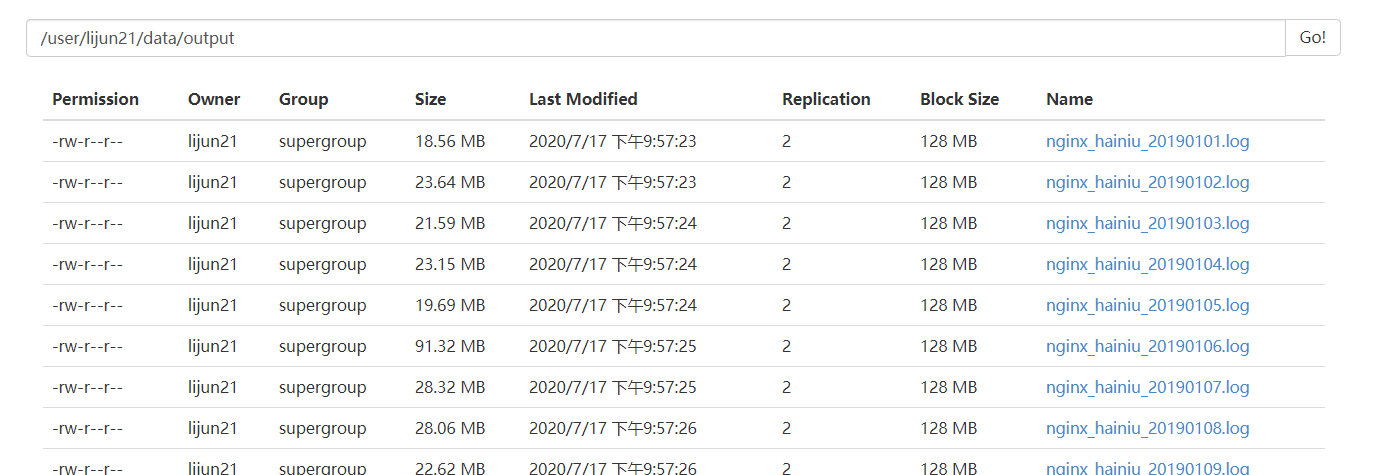
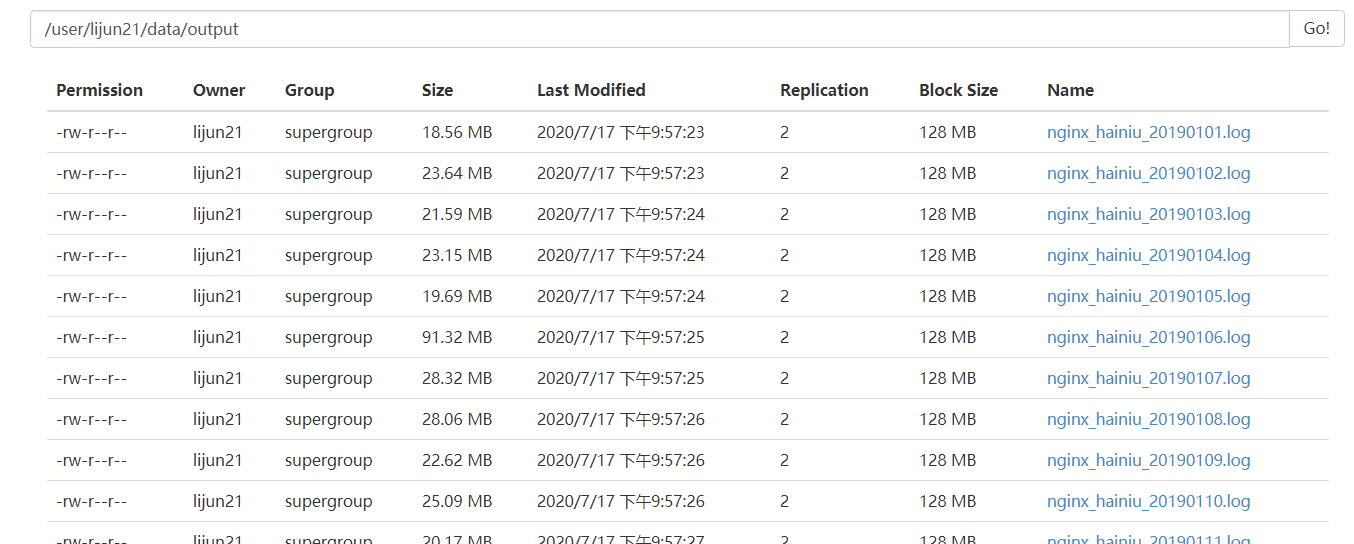
去hdfs查看我们的输出文件,.tar.gz和 .gz 结尾的文件全部去掉了后缀,

至此,大功告成!
总结: 因为解压过程不需要跑mapreduce,所以速度比较快,如有疑问,请联系我
本帖已被设为精华帖!