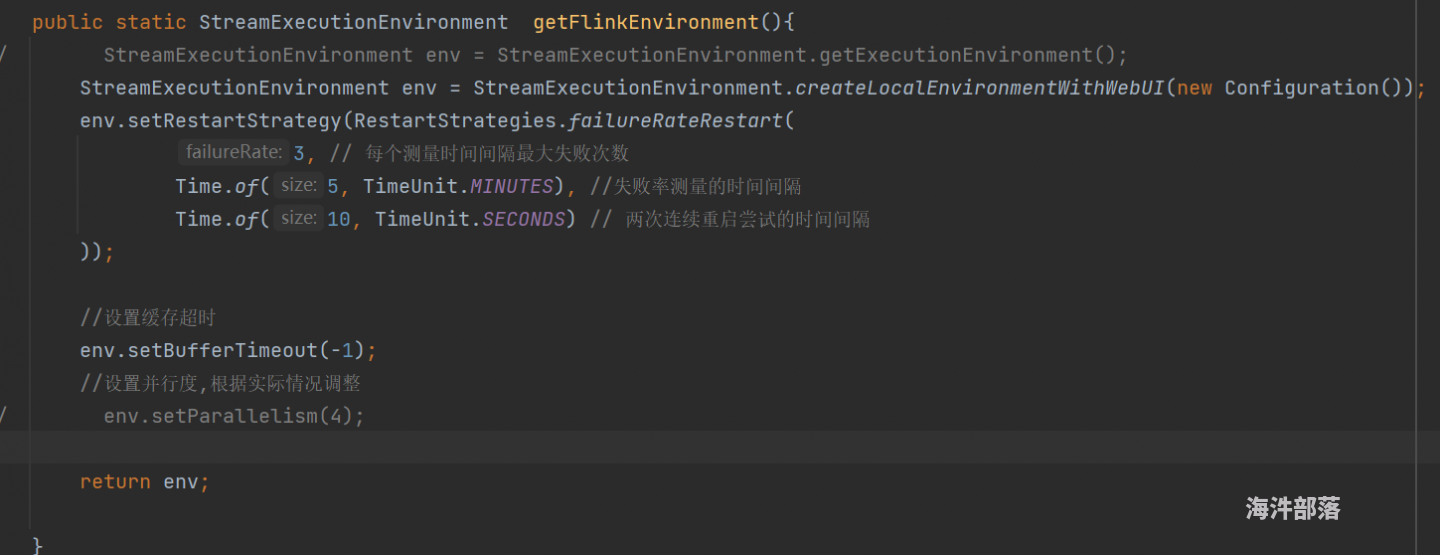
本测试仅有kafkasource->map->print,三种算子。
1.将source/map/print的并行度均设为2,即kafkasource(2)->map(2)->print(2)。由于并行度一致,flink会将以上3个subtask合并为一个subtask放在slot里,共有2个subtask。
图1.1为并行度一致时代码输出结果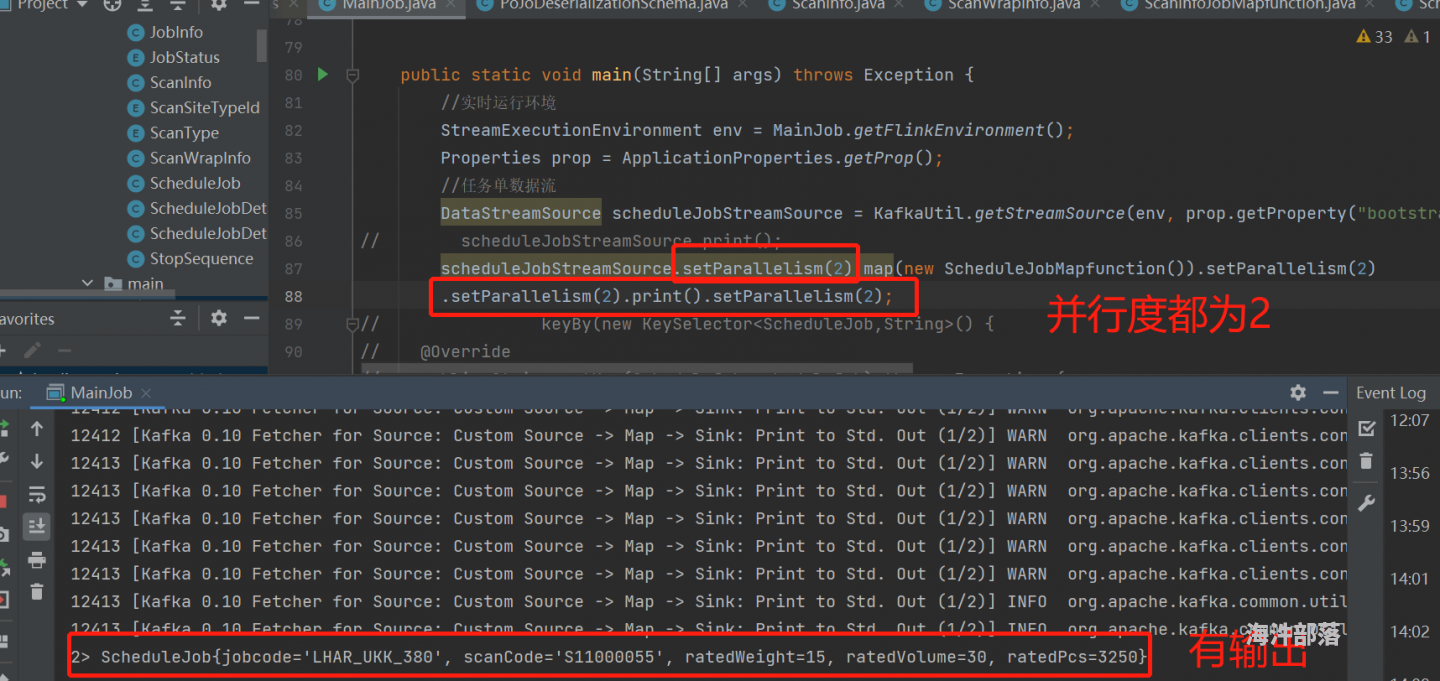
图1.2 为并行度一致时webui执行情况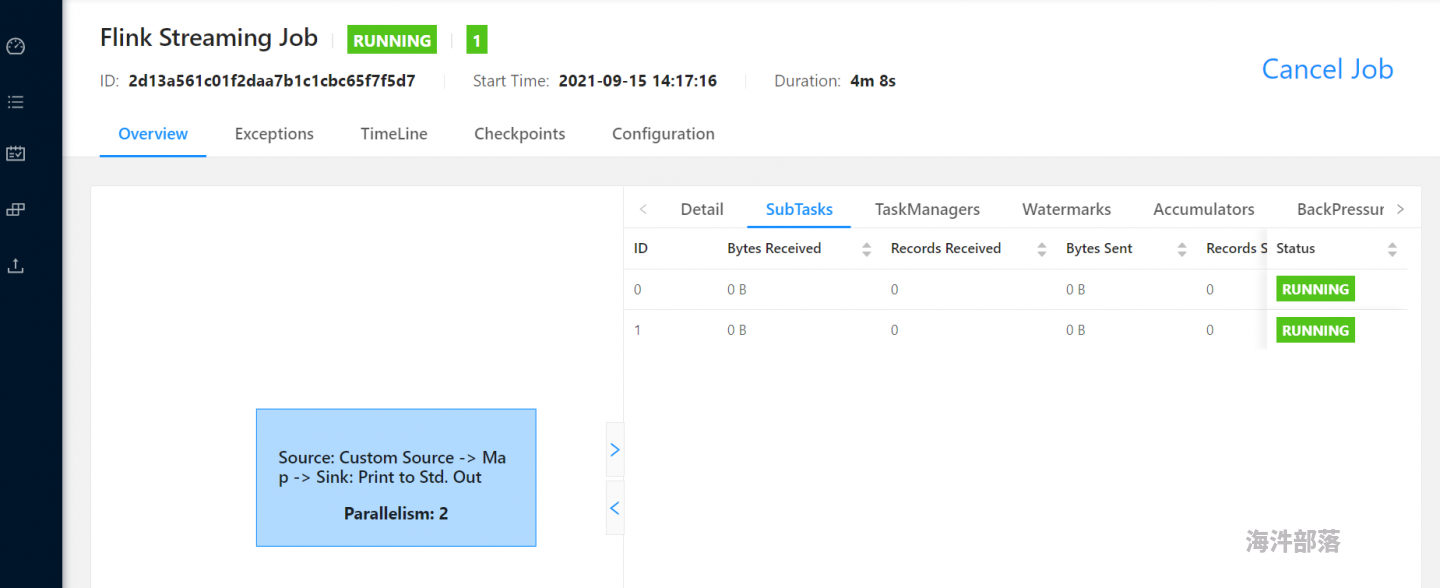
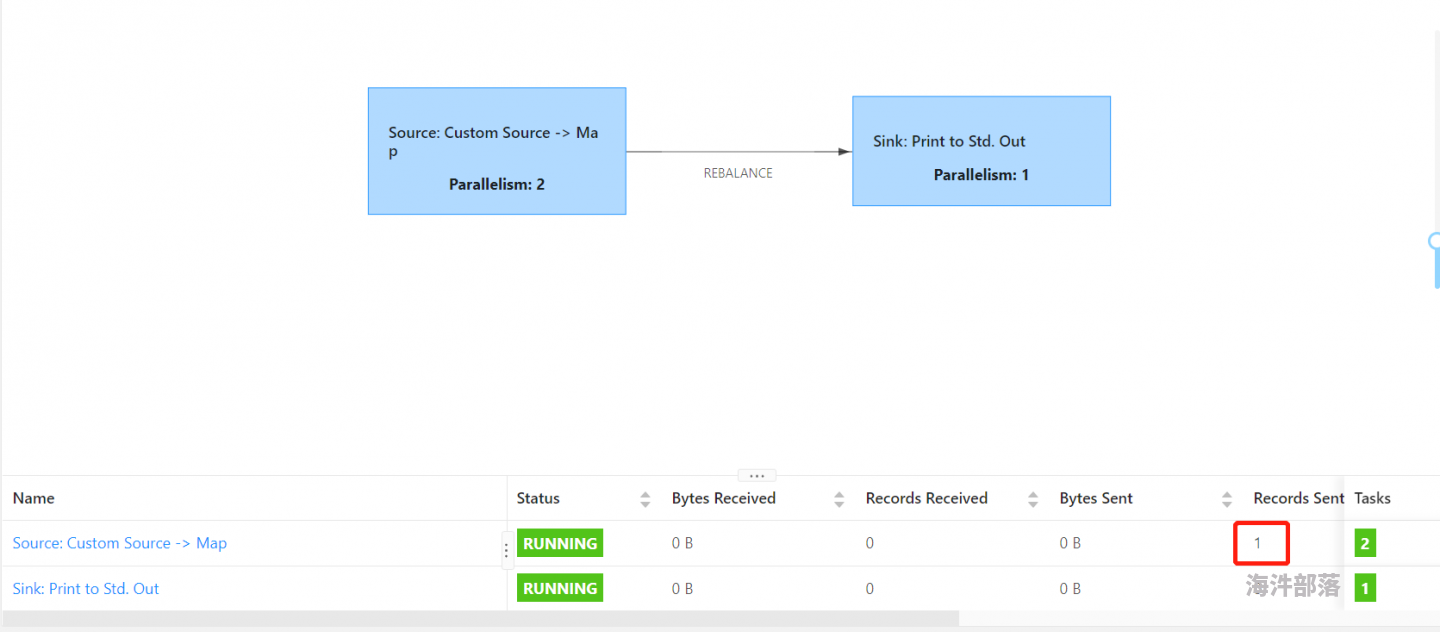
2.改变source/map/print三种算子的并行度,如kafkasource(2)->map(2)->print(1),之后flink会将以上kafkasource和map合并为一个subtask,最终有3个subtask。
图1.1为并行度不一致时代码输出结果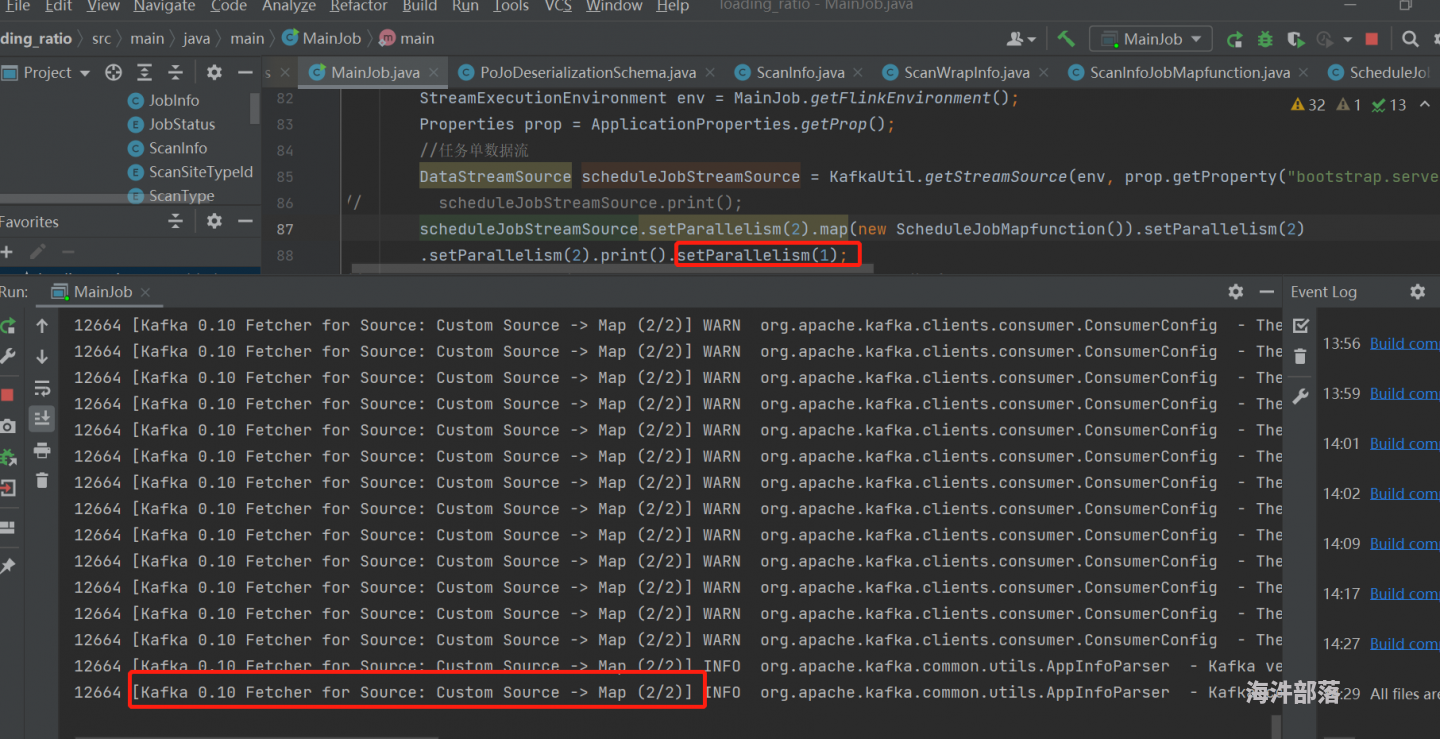
图1.2 为并行度一致时webui执行情况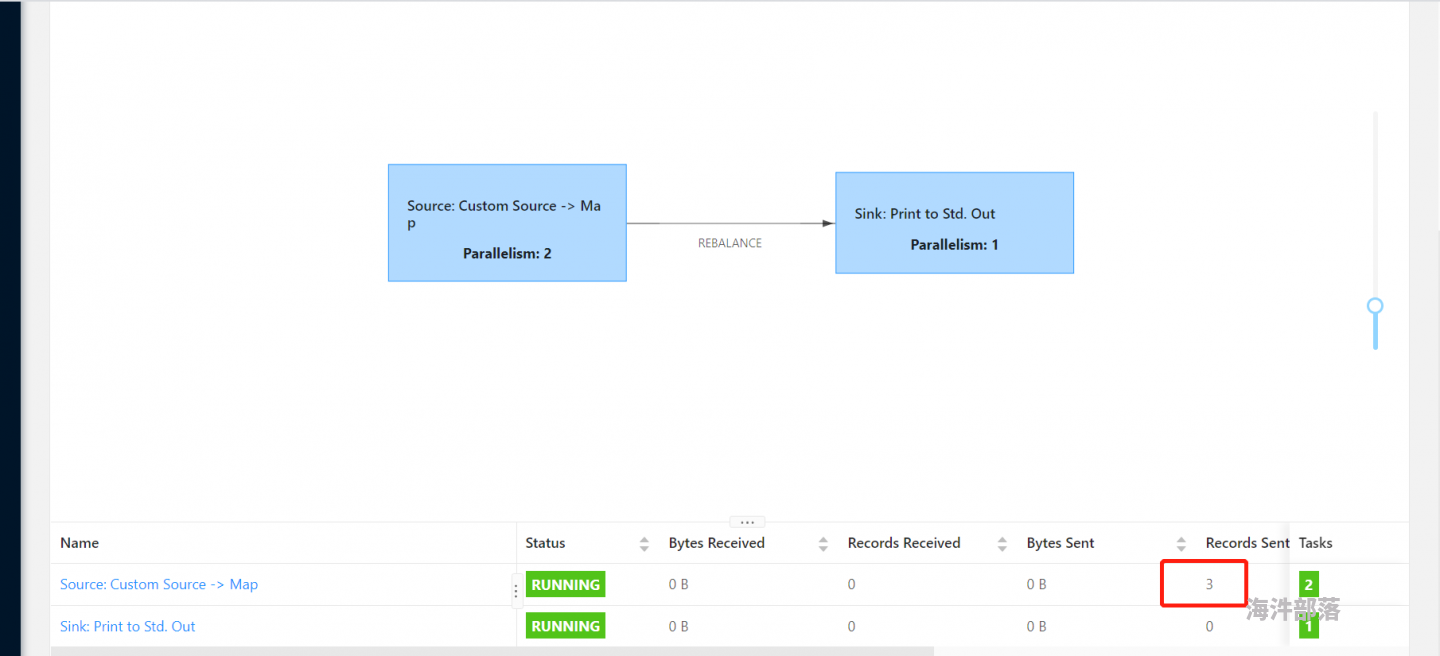
通过测试,在读取kafka数据源后,并行度一致的情况下,是有结果输出的。但是在并行度不一致的情况,没有结果输出。task的状态都是running,背压也ok。所以,造成这种问题的原因是什么呢?