VPN连接成功之后,在运行试验页面找到IP然后连接相应的服务
不要,垃圾灌水,给你做沉贴处理
同学发这样的文章才可以加精,获得积分https://hainiubl.com/topics/76575
是的,你和这个问题一样的 https://www.hainiubl.com/topics/76629
可以的,你看一下视频教程 https://www.hainiubl.com/topics/76618/video/19
建议使用markdown调整一下文本格式,可以给加精处理
选Java组件里面有idea
先删除再创建试试
贴下过程图
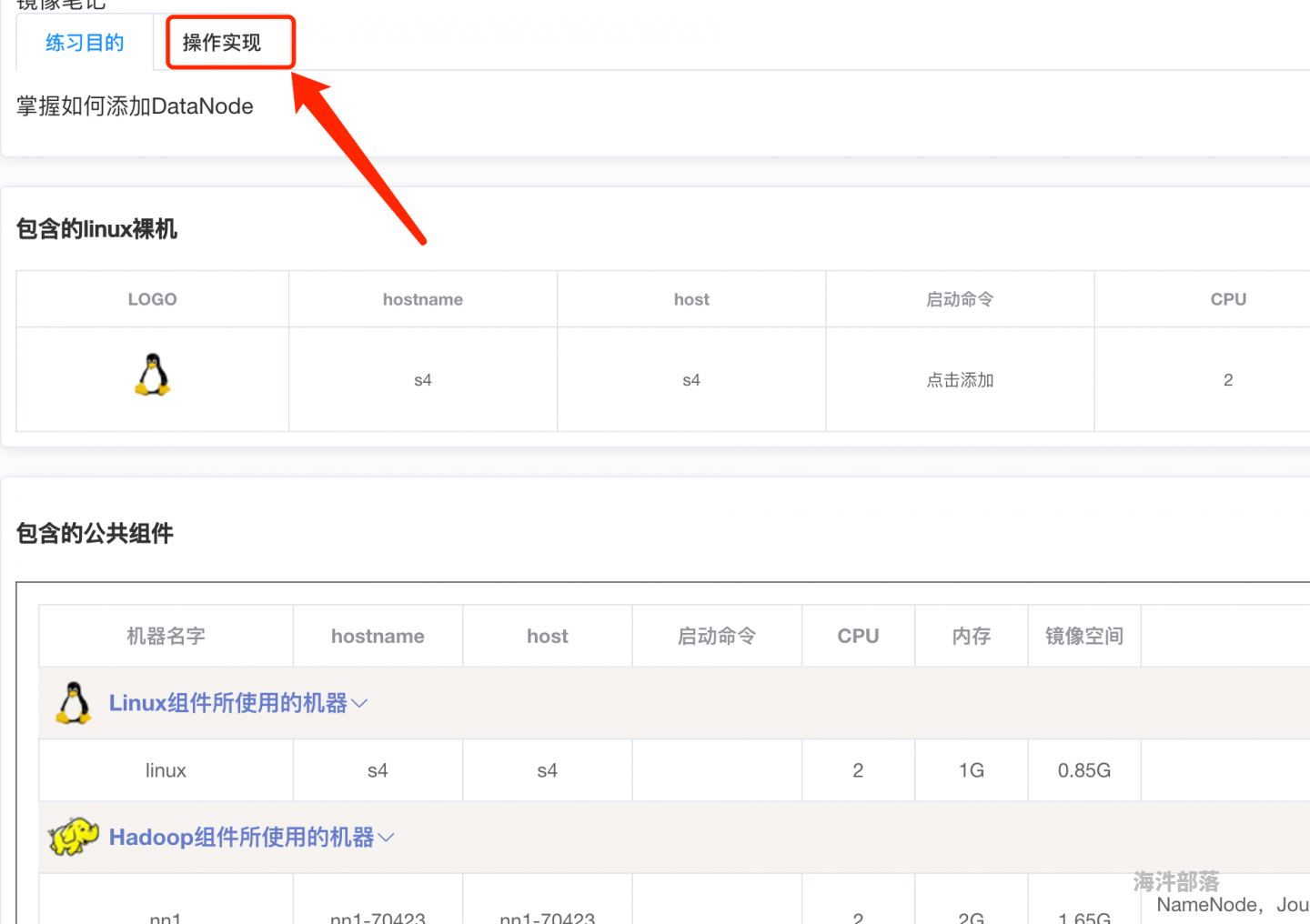
@qiqiqiqiq 这里有个现成的《HDFS 添加新节点》优秀镜像,你要是没有运行权限你就看一下操作流程
@qiqiqiqiq 要所有机器都同步相同的配置
一样,opt下是/usr/local下的软链接
跟我们平台的 重启实验 没关系,是你自己安装的问题,是不是新的linux机器没配置好。你想想为什么重启实验好使?因为重启实验同样会重启你的hadoop程序,也就是说你现在的情况是不能动态添加只能重启整个hadoop集群来解决