可以啊 你把经常查的做成一张大表就行了
- 在 hive 中建模可不可以用一张大表?
-
信息被删除或无权限查看
-
信息被删除或无权限查看
- Java 中的 Collection 为什么设计成接口而非抽象类?
- 如何在 spark 中集成 lightGBM,做大批量数据建模?
- Hadoop 单机模式搭建和伪分布式搭建的区别主要有哪些?
-
信息被删除或无权限查看
- hive 中创建外部表时 location 如何指定数个位置?
- Hadoop 单机模式搭建和伪分布式搭建的区别主要有哪些?
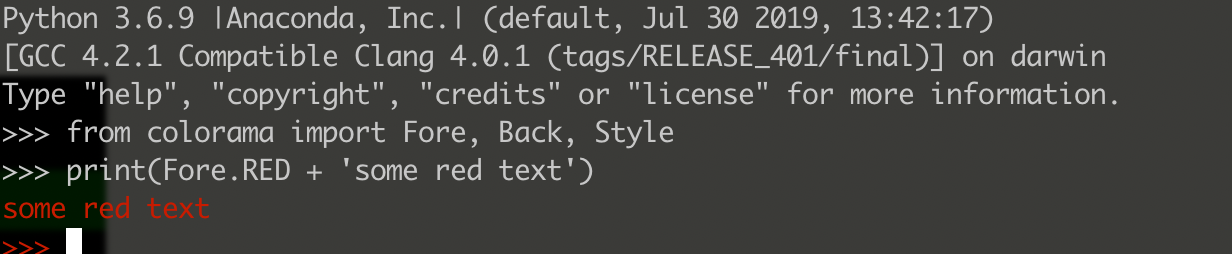
- python colorama 模块不能正常输出颜色怎么解决?
- map/reduce 过程,如何用 map/reduce 实现两个数据源的联合统计?
- 多 hive 表关联成一张大表,表的大小差距比较大,如何提效?
- Pycharm 默认中文字体怎么变了?
- python 的浮点型数据计算为什么会出错?
- Hadoop 除了 Hbase 是否支持其它数据库?