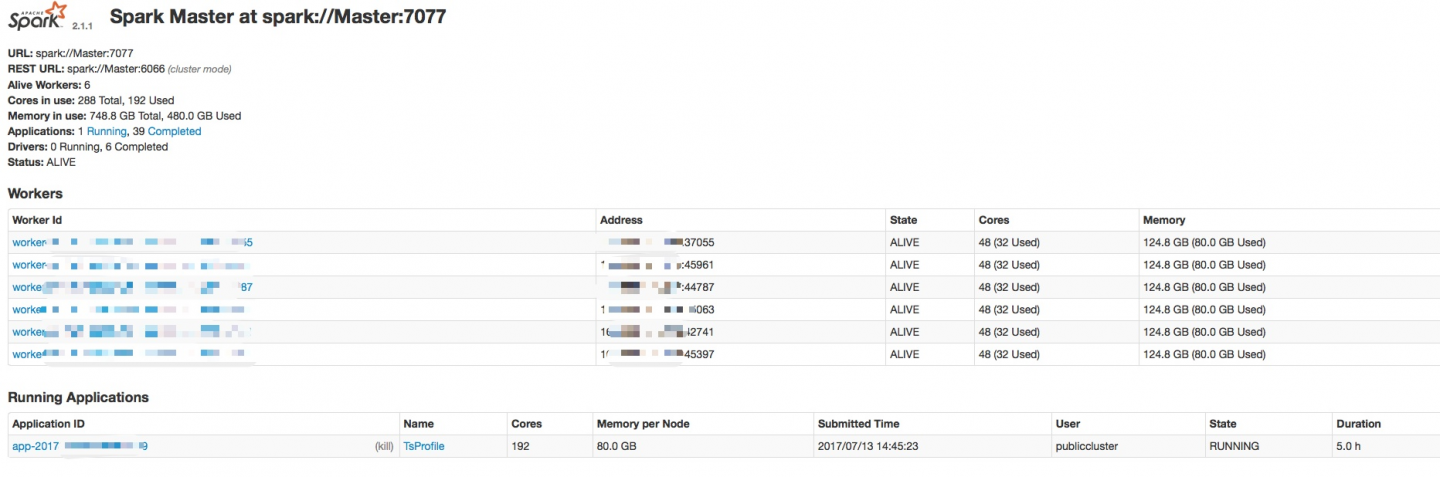
现在问题是分批利用集群处理数据:
按照理论来说,同一个任务流程,每批的处理时间应该相同,但是现在问题是,第1批是时间很快,大概5分钟能处理完,运行一段时间后,到第30多批后,运行效率会降下来,大概30分钟才能处理完,完全不知道为什么出现这种情况,spark的内存不是动态释放的吗?
现在问题是分批利用集群处理数据:
按照理论来说,同一个任务流程,每批的处理时间应该相同,但是现在问题是,第1批是时间很快,大概5分钟能处理完,运行一段时间后,到第30多批后,运行效率会降下来,大概30分钟才能处理完,完全不知道为什么出现这种情况,spark的内存不是动态释放的吗?

1、可能有任务之间的依赖 2、spark的内存最好自己代码释放 3、找到运行缓慢的代码

关注海汼部落
