YARN学习
YARN工作机制简单学习
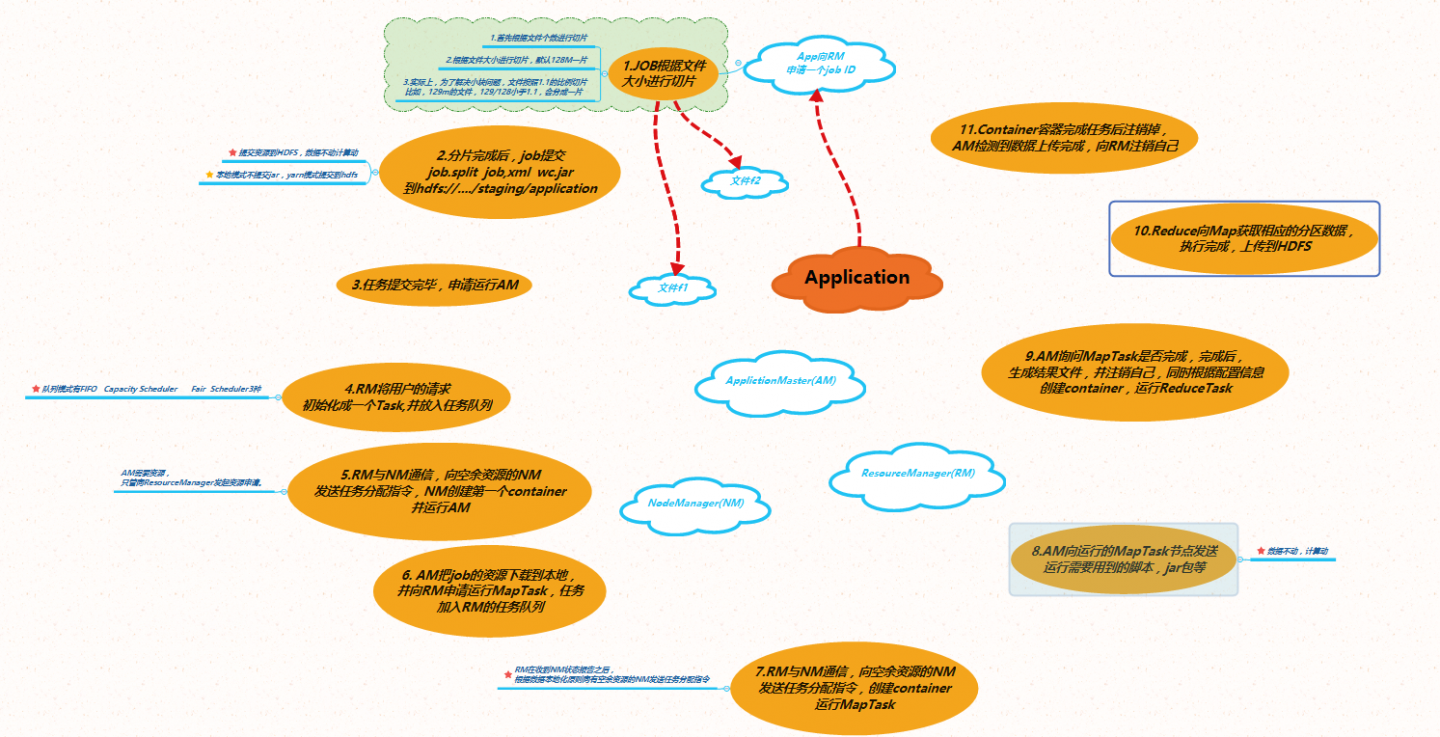
shuffle简单学习
shuffle是指从Map产生输出开始,包裹系统执行排序以及传送Map输出到Reducer作为输入的过程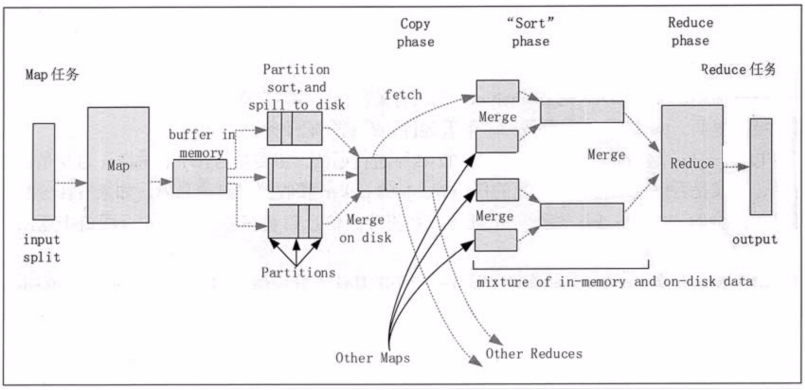
Map端的shuffle

-
切片大概流程是什么?
- job根据输入的文件进行切片
- 首先根据文件个数进行切片
- 之后根据文件大小进行切片,默认128M一片
- 实际上,为了解决小块问题,文件按照1.1的比例切片
比如,129M的文件,129/128小于1.1,会分成一片
-
问:MapTask个数怎么确定?
- MapTask个数由切片的个数进行确定
- MapTask阶段的环形缓存区是什么? -> shuffle
- 每个Map任务都有一个用来写入输出数据的环形内存缓冲区,默认100M
- 在yarn集群上,会有多个MapTask跑任务(可能跑在不同的NodeManager上)
- 环形缓存区存储原则,小部分存索引,大部分存数据。
- 在环形缓冲区发生快排-分区-combiner(用索引提高效率)
- 采用2-8原则,数据存满80%就开始溢写,20%继续进行数据输入,保证读写实时性
- 溢写后,磁盘上有多个文件(满80%就溢写)
- 文件类型有2种,一个存索引,一个存数据
- Map完成之前,溢写文件被合并成一个索引文件和数据文件(多路归并排序)
Reduce端的shuffle

-
两次shuffle内存缓存区发生的地方
- 位置:MapTask处理的数据,需要写入内存环形缓存区 作用:排序-分区-combiner
- 位置:reduce将从map阶段拿到的数据写入内存缓存区 作用:归并多个MapTask过来的数据
- 两次shuffle归并分别发生在什么地方?
- 位置:MapTask任务处理完成之前,归并溢写出的文件
- 位置:reduce将从多个map拿到的数据进行归并(两两归并:4个数据块->2个数据块->1个数据块)

