你不要用map用flatMap。把aa改成list类型,这样返回的就是rdd[String]类型的,然后你rdd.foreach就是获取每一个值了
- 个人中心
- Ta 发表的回复(2256)
-
spark 读取数据 split 问题?
-
Hadoop 部署集群时节点无法启动问题?
@足迹 你环境变量没设置吧
-
wordcount 执行不了,查日志提示 maximum-am-resource-percent is insufficient,应该怎么设置?
@大中 目前来看你的队列没有可用的资源,换fair-scheduler.xml试试
给你个参考
yarn-site.xml
fair-scheduler.xml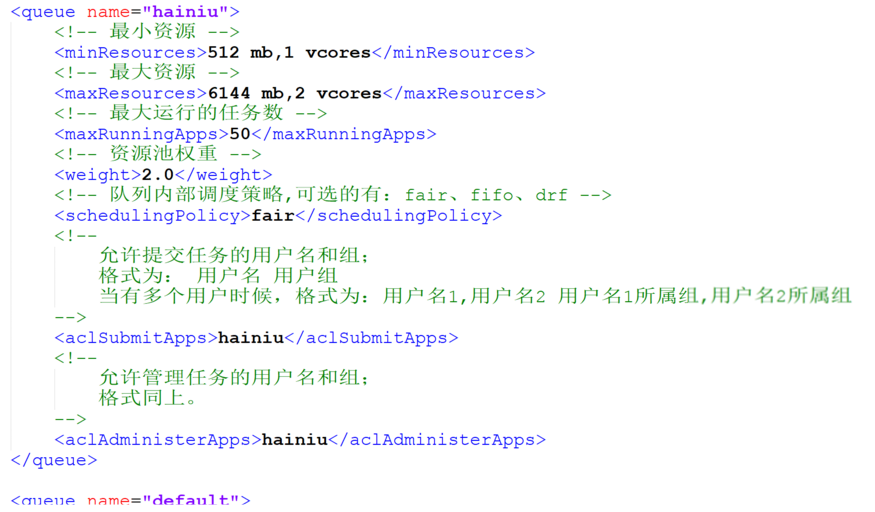
-
wordcount 执行不了,查日志提示 maximum-am-resource-percent is insufficient,应该怎么设置?
@大中 看一下子队列
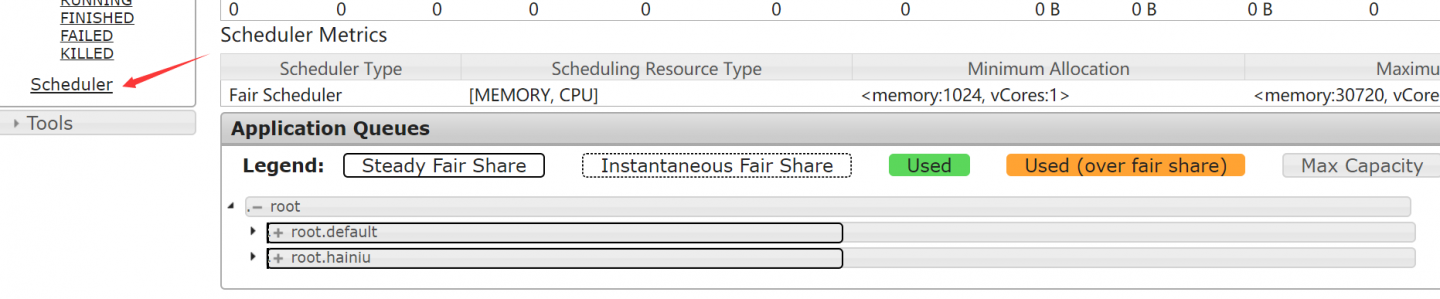
-
wordcount 执行不了,查日志提示 maximum-am-resource-percent is insufficient,应该怎么设置?
@大中 那就看一下scheduler的设置是否生效了,再把map和reducer的内存设置小一点
-
hadoop 环境搭建完成后接下来该做什么?
数据上报,相关产品对接数据埋点,可以理弄个埋点管理系统。接下用mr,hive或spark做数据的ETL,弄好结构化数据,然后再建数据仓储,之后就能用hive或spark-sql做数据的分析。再弄个报表系统出报表用hue或者esayreport都可以。涉及到流式计算的话可以用kafka和spark-streaming。
-
请教一下,Spark Streaming 怎么实时读取 Redis 的数据?
可以,难度不大。
你把数据从redis读出来放到kafka里呗,然后用spark-streaming去读kafka的数据,或者写个程序从redis把数据读出来用socket或文件的形式传给spark-streaming,spark-streaming支持很多种源的方式 -
后台程序是直接访问 HDFS 中数据吗?
@BigTester 存储数据加上离线分析,一般导出的都是处理过的数据
-
Hadoop 部署集群时节点无法启动问题?
[hadoop@master hadoop]$ sh -x start-dfs.sh this=/usr/local/hadoop/sbin/start-dfs.sh +++ dirname -- /usr/local/hadoop/sbin/start-dfs.sh ++ cd -P -- /usr/local/hadoop/sbin ++ pwd -P bin=/usr/local/hadoop-3.0.0/sbin [[ -n /usr/local/hadoop ]] HADOOP_DEFAULT_LIBEXEC_DIR=/usr/local/hadoop/libexec HADOOP_LIBEXEC_DIR=/usr/local/hadoop/libexec HADOOP_NEW_CONFIG=true [[ -f /usr/local/hadoop/libexec/hdfs-config.sh ]] . /usr/local/hadoop/libexec/hdfs-config.sh ++ [[ -z /usr/local/hadoop/libexec ]] ++ [[ -n '' ]] ++ [[ -e /usr/local/hadoop/libexec/hadoop-config.sh ]] ++ . /usr/local/hadoop/libexec/hadoop-config.sh +++ [[ -z 4 ]] +++ [[ 4 -lt 3 ]] +++ [[ 4 -eq 3 ]] +++ [[ -z /usr/local/hadoop/libexec ]] +++ [[ -n '' ]] +++ [[ -e /usr/local/hadoop/libexec/hadoop-functions.sh ]] +++ . /usr/local/hadoop/libexec/hadoop-functions.sh ++++ declare -a HADOOP_SUBCMD_USAGE ++++ declare -a HADOOP_OPTION_USAGE ++++ declare -a HADOOP_SUBCMD_USAGE_TYPES /usr/local/hadoop/libexec/hadoop-functions.sh:行398: 未预期的符号 <' 附近有语法错误 /usr/local/hadoop/libexec/hadoop-functions.sh:行398: done < <(for text in "${input[@]}"; do' +++ hadoop_deprecate_envvar HADOOP_PREFIX HADOOP_HOME /usr/local/hadoop/libexec/hadoop-config.sh:行70: hadoop_deprecate_envvar: 未找到命令 +++ [[ -n '' ]] +++ [[ -e /usr/local/hadoop/libexec/hadoop-layout.sh ]] +++ hadoop_bootstrap /usr/local/hadoop/libexec/hadoop-config.sh:行87: hadoop_bootstrap: 未找到命令 +++ HADOOP_USER_PARAMS=("$@") +++ hadoop_parse_args /usr/local/hadoop/libexec/hadoop-config.sh:行104: hadoop_parse_args: 未找到命令 +++ shift '' /usr/local/hadoop/libexec/hadoop-config.sh: 第 105 行:shift: : 需要数字参数 +++ hadoop_find_confdir /usr/local/hadoop/libexec/hadoop-config.sh:行110: hadoop_find_confdir: 未找到命令 +++ hadoop_exec_hadoopenv /usr/local/hadoop/libexec/hadoop-config.sh:行111: hadoop_exec_hadoopenv: 未找到命令 +++ hadoop_import_shellprofiles /usr/local/hadoop/libexec/hadoop-config.sh:行112: hadoop_import_shellprofiles: 未找到命令 +++ hadoop_exec_userfuncs /usr/local/hadoop/libexec/hadoop-config.sh:行113: hadoop_exec_userfuncs: 未找到命令 +++ hadoop_exec_user_hadoopenv /usr/local/hadoop/libexec/hadoop-config.sh:行119: hadoop_exec_user_hadoopenv: 未找到命令 +++ hadoop_verify_confdir /usr/local/hadoop/libexec/hadoop-config.sh:行120: hadoop_verify_confdir: 未找到命令 +++ hadoop_deprecate_envvar HADOOP_SLAVES HADOOP_WORKERS /usr/local/hadoop/libexec/hadoop-config.sh:行122: hadoop_deprecate_envvar: 未找到命令 +++ hadoop_deprecate_envvar HADOOP_SLAVE_NAMES HADOOP_WORKER_NAMES /usr/local/hadoop/libexec/hadoop-config.sh:行123: hadoop_deprecate_envvar: 未找到命令 +++ hadoop_deprecate_envvar HADOOP_SLAVE_SLEEP HADOOP_WORKER_SLEEP /usr/local/hadoop/libexec/hadoop-config.sh:行124: hadoop_deprecate_envvar: 未找到命令 +++ hadoop_os_tricks /usr/local/hadoop/libexec/hadoop-config.sh:行129: hadoop_os_tricks: 未找到命令 +++ hadoop_java_setup /usr/local/hadoop/libexec/hadoop-config.sh:行131: hadoop_java_setup: 未找到命令 +++ hadoop_basic_init /usr/local/hadoop/libexec/hadoop-config.sh:行133: hadoop_basic_init: 未找到命令 +++ declare -F hadoop_subproject_init +++ hadoop_subproject_init +++ [[ -z '' ]] +++ [[ -e /hdfs-env.sh ]] +++ hadoop_deprecate_envvar HADOOP_HDFS_LOG_DIR HADOOP_LOG_DIR /usr/local/hadoop/libexec/hdfs-config.sh:行38: hadoop_deprecate_envvar: 未找到命令 +++ hadoop_deprecate_envvar HADOOP_HDFS_LOGFILE HADOOP_LOGFILE /usr/local/hadoop/libexec/hdfs-config.sh:行40: hadoop_deprecate_envvar: 未找到命令 +++ hadoop_deprecate_envvar HADOOP_HDFS_NICENESS HADOOP_NICENESS /usr/local/hadoop/libexec/hdfs-config.sh:行42: hadoop_deprecate_envvar: 未找到命令 +++ hadoop_deprecate_envvar HADOOP_HDFS_STOP_TIMEOUT HADOOP_STOP_TIMEOUT /usr/local/hadoop/libexec/hdfs-config.sh:行44: hadoop_deprecate_envvar: 未找到命令 +++ hadoop_deprecate_envvar HADOOP_HDFS_PID_DIR HADOOP_PID_DIR /usr/local/hadoop/libexec/hdfs-config.sh:行46: hadoop_deprecate_envvar: 未找到命令 +++ hadoop_deprecate_envvar HADOOP_HDFS_ROOT_LOGGER HADOOP_ROOT_LOGGER /usr/local/hadoop/libexec/hdfs-config.sh:行48: hadoop_deprecate_envvar: 未找到命令 +++ hadoop_deprecate_envvar HADOOP_HDFS_IDENT_STRING HADOOP_IDENT_STRING /usr/local/hadoop/libexec/hdfs-config.sh:行50: hadoop_deprecate_envvar: 未找到命令 +++ hadoop_deprecate_envvar HADOOP_DN_SECURE_EXTRA_OPTS HDFS_DATANODE_SECURE_EXTRA_OPTS /usr/local/hadoop/libexec/hdfs-config.sh:行52: hadoop_deprecate_envvar: 未找到命令 +++ hadoop_deprecate_envvar HADOOP_NFS3_SECURE_EXTRA_OPTS HDFS_NFS3_SECURE_EXTRA_OPTS /usr/local/hadoop/libexec/hdfs-config.sh:行54: hadoop_deprecate_envvar: 未找到命令 +++ hadoop_deprecate_envvar HADOOP_SECURE_DN_USER HDFS_DATANODE_SECURE_USER /usr/local/hadoop/libexec/hdfs-config.sh:行56: hadoop_deprecate_envvar: 未找到命令 +++ hadoop_deprecate_envvar HADOOP_PRIVILEGED_NFS_USER HDFS_NFS3_SECURE_USER /usr/local/hadoop/libexec/hdfs-config.sh:行58: hadoop_deprecate_envvar: 未找到命令 +++ HADOOP_HDFS_HOME=/usr/local/hadoop +++ export HDFS_AUDIT_LOGGER=INFO,NullAppender +++ HDFS_AUDIT_LOGGER=INFO,NullAppender +++ export HDFS_NAMENODE_OPTS=-Dhadoop.security.logger=INFO,RFAS +++ HDFS_NAMENODE_OPTS=-Dhadoop.security.logger=INFO,RFAS +++ export HDFS_SECONDARYNAMENODE_OPTS=-Dhadoop.security.logger=INFO,RFAS +++ HDFS_SECONDARYNAMENODE_OPTS=-Dhadoop.security.logger=INFO,RFAS +++ export HDFS_DATANODE_OPTS=-Dhadoop.security.logger=ERROR,RFAS +++ HDFS_DATANODE_OPTS=-Dhadoop.security.logger=ERROR,RFAS +++ export HDFS_PORTMAP_OPTS=-Xmx512m +++ HDFS_PORTMAP_OPTS=-Xmx512m +++ export 'HDFS_DATANODE_SECURE_EXTRA_OPTS=-jvm server' +++ HDFS_DATANODE_SECURE_EXTRA_OPTS='-jvm server' +++ export 'HDFS_NFS3_SECURE_EXTRA_OPTS=-jvm server' +++ HDFS_NFS3_SECURE_EXTRA_OPTS='-jvm server' +++ hadoop_shellprofiles_init /usr/local/hadoop/libexec/hadoop-config.sh:行140: hadoop_shellprofiles_init: 未找到命令 +++ hadoop_add_javalibpath /usr/local/hadoop/build/native /usr/local/hadoop/libexec/hadoop-config.sh:行143: hadoop_add_javalibpath: 未找到命令 +++ hadoop_add_javalibpath /usr/local/hadoop/ /usr/local/hadoop/libexec/hadoop-config.sh:行144: hadoop_add_javalibpath: 未找到命令 +++ hadoop_shellprofiles_nativelib /usr/local/hadoop/libexec/hadoop-config.sh:行146: hadoop_shellprofiles_nativelib: 未找到命令 +++ hadoop_add_common_to_classpath /usr/local/hadoop/libexec/hadoop-config.sh:行152: hadoop_add_common_to_classpath: 未找到命令 +++ hadoop_shellprofiles_classpath /usr/local/hadoop/libexec/hadoop-config.sh:行153: hadoop_shellprofiles_classpath: 未找到命令 +++ hadoop_exec_hadooprc /usr/local/hadoop/libexec/hadoop-config.sh:行157: hadoop_exec_hadooprc: 未找到命令 +++ [[ -z true ]] [[ 0 -ge 1 ]] nameStartOpt=' ' ++ /usr/local/hadoop/bin/hdfs getconf -namenodes NAMENODES=master.hadoop [[ -z master.hadoop ]] echo 'Starting namenodes on [master.hadoop]' Starting namenodes on [master.hadoop] hadoop_uservar_su hdfs namenode /usr/local/hadoop/bin/hdfs --workers --config '' --hostnames master.hadoop --daemon start namenode declare program=hdfs declare command=namenode shift 2 declare uprogram declare ucommand declare uvar declare svar hadoop_privilege_check [[ 1000 = 0 ]] /usr/local/hadoop/bin/hdfs --workers --config '' --hostnames master.hadoop --daemon start namenode ERROR: No parameter provided for --config Usage: hdfs [OPTIONS] SUBCOMMAND [SUBCOMMAND OPTIONS] OPTIONS is none or any of: --buildpaths attempt to add class files from build tree --config dir Hadoop config directory --daemon (start|status|stop) operate on a daemon --debug turn on shell script debug mode --help usage information --hostnames list[,of,host,names] hosts to use in worker mode --hosts filename list of hosts to use in worker mode --loglevel level set the log4j level for this command --workers turn on worker mode SUBCOMMAND is one of: Admin Commands: cacheadmin configure the HDFS cache crypto configure HDFS encryption zones debug run a Debug Admin to execute HDFS debug commands dfsadmin run a DFS admin client dfsrouteradmin manage Router-based federation ec run a HDFS ErasureCoding CLI fsck run a DFS filesystem checking utility haadmin run a DFS HA admin client jmxget get JMX exported values from NameNode or DataNode. oev apply the offline edits viewer to an edits file oiv apply the offline fsimage viewer to an fsimage oiv_legacy apply the offline fsimage viewer to a legacy fsimage storagepolicies list/get/set block storage policies Client Commands: classpath prints the class path needed to get the hadoop jar and the required libraries dfs run a filesystem command on the file system envvars display computed Hadoop environment variables fetchdt fetch a delegation token from the NameNode getconf get config values from configuration groups get the groups which users belong to lsSnapshottableDir list all snapshottable dirs owned by the current user snapshotDiff diff two snapshots of a directory or diff the current directory contents with a snapshot version print the version Daemon Commands: balancer run a cluster balancing utility datanode run a DFS datanode dfsrouter run the DFS router diskbalancer Distributes data evenly among disks on a given node journalnode run the DFS journalnode mover run a utility to move block replicas across storage types namenode run the DFS namenode nfs3 run an NFS version 3 gateway portmap run a portmap service secondarynamenode run the DFS secondary namenode zkfc run the ZK Failover Controller daemon SUBCOMMAND may print help when invoked w/o parameters or with -h. HADOOP_JUMBO_RETCOUNTER=1 echo 'Starting datanodes' Starting datanodes hadoop_uservar_su hdfs datanode /usr/local/hadoop/bin/hdfs --workers --config '' --daemon start datanode declare program=hdfs declare command=datanode shift 2 declare uprogram declare ucommand declare uvar declare svar hadoop_privilege_check [[ 1000 = 0 ]] /usr/local/hadoop/bin/hdfs --workers --config '' --daemon start datanode ERROR: No parameter provided for --config Usage: hdfs [OPTIONS] SUBCOMMAND [SUBCOMMAND OPTIONS] OPTIONS is none or any of: --buildpaths attempt to add class files from build tree --config dir Hadoop config directory --daemon (start|status|stop) operate on a daemon --debug turn on shell script debug mode --help usage information --hostnames list[,of,host,names] hosts to use in worker mode --hosts filename list of hosts to use in worker mode --loglevel level set the log4j level for this command --workers turn on worker mode SUBCOMMAND is one of: Admin Commands: cacheadmin configure the HDFS cache crypto configure HDFS encryption zones debug run a Debug Admin to execute HDFS debug commands dfsadmin run a DFS admin client dfsrouteradmin manage Router-based federation ec run a HDFS ErasureCoding CLI fsck run a DFS filesystem checking utility haadmin run a DFS HA admin client jmxget get JMX exported values from NameNode or DataNode. oev apply the offline edits viewer to an edits file oiv apply the offline fsimage viewer to an fsimage oiv_legacy apply the offline fsimage viewer to a legacy fsimage storagepolicies list/get/set block storage policies Client Commands: classpath prints the class path needed to get the hadoop jar and the required libraries dfs run a filesystem command on the file system envvars display computed Hadoop environment variables fetchdt fetch a delegation token from the NameNode getconf get config values from configuration groups get the groups which users belong to lsSnapshottableDir list all snapshottable dirs owned by the current user snapshotDiff diff two snapshots of a directory or diff the current directory contents with a snapshot version print the version Daemon Commands: balancer run a cluster balancing utility datanode run a DFS datanode dfsrouter run the DFS router diskbalancer Distributes data evenly among disks on a given node journalnode run the DFS journalnode mover run a utility to move block replicas across storage types namenode run the DFS namenode nfs3 run an NFS version 3 gateway portmap run a portmap service secondarynamenode run the DFS secondary namenode zkfc run the ZK Failover Controller daemon SUBCOMMAND may print help when invoked w/o parameters or with -h. (( HADOOP_JUMBO_RETCOUNTER=HADOOP_JUMBO_RETCOUNTER + 1 )) ++ /usr/local/hadoop/bin/hdfs getconf -secondarynamenodes SECONDARY_NAMENODES=0.0.0.0 [[ -n 0.0.0.0 ]] [[ master.hadoop =~ , ]] [[ 0.0.0.0 == \0.\0.\0.\0 ]] ++ hostname SECONDARY_NAMENODES=master.hadoop echo 'Starting secondary namenodes [master.hadoop]' Starting secondary namenodes [master.hadoop] hadoop_uservar_su hdfs secondarynamenode /usr/local/hadoop/bin/hdfs --workers --config '' --hostnamesmaster.hadoop --daemon start secondarynamenode declare program=hdfs declare command=secondarynamenode shift 2 declare uprogram declare ucommand declare uvar declare svar hadoop_privilege_check [[ 1000 = 0 ]] /usr/local/hadoop/bin/hdfs --workers --config '' --hostnames master.hadoop --daemon start secondarynamenode ERROR: No parameter provided for --config Usage: hdfs [OPTIONS] SUBCOMMAND [SUBCOMMAND OPTIONS] OPTIONS is none or any of: --buildpaths attempt to add class files from build tree --config dir Hadoop config directory --daemon (start|status|stop) operate on a daemon --debug turn on shell script debug mode --help usage information --hostnames list[,of,host,names] hosts to use in worker mode --hosts filename list of hosts to use in worker mode --loglevel level set the log4j level for this command --workers turn on worker mode SUBCOMMAND is one of: Admin Commands: cacheadmin configure the HDFS cache crypto configure HDFS encryption zones debug run a Debug Admin to execute HDFS debug commands dfsadmin run a DFS admin client dfsrouteradmin manage Router-based federation ec run a HDFS ErasureCoding CLI fsck run a DFS filesystem checking utility haadmin run a DFS HA admin client jmxget get JMX exported values from NameNode or DataNode. oev apply the offline edits viewer to an edits file oiv apply the offline fsimage viewer to an fsimage oiv_legacy apply the offline fsimage viewer to a legacy fsimage storagepolicies list/get/set block storage policies Client Commands: classpath prints the class path needed to get the hadoop jar and the required libraries dfs run a filesystem command on the file system envvars display computed Hadoop environment variables fetchdt fetch a delegation token from the NameNode getconf get config values from configuration groups get the groups which users belong to lsSnapshottableDir list all snapshottable dirs owned by the current user snapshotDiff diff two snapshots of a directory or diff the current directory contents with a snapshot version print the version Daemon Commands: balancer run a cluster balancing utility datanode run a DFS datanode dfsrouter run the DFS router diskbalancer Distributes data evenly among disks on a given node journalnode run the DFS journalnode mover run a utility to move block replicas across storage types namenode run the DFS namenode nfs3 run an NFS version 3 gateway portmap run a portmap service secondarynamenode run the DFS secondary namenode zkfc run the ZK Failover Controller daemon SUBCOMMAND may print help when invoked w/o parameters or with -h. (( HADOOP_JUMBO_RETCOUNTER=HADOOP_JUMBO_RETCOUNTER + 1 )) ++ /usr/local/hadoop/bin/hdfs getconf -confKey dfs.namenode.shared.edits.dir SHARED_EDITS_DIR= case "${SHARED_EDITS_DIR}" in ++ tr '[:upper:]' '[:lower:]' ++ /usr/local/hadoop/bin/hdfs getconf -confKey dfs.ha.automatic-failover.enabled AUTOHA_ENABLED=false [[ false = \t\r\u\e ]] exit 3 [hadoop@master hadoop]$@足迹 根据你的debug信息来看你应该是hadoop-env.sh里没配置或者HADOOP_CONF_DIR没配置
给你参看一下我的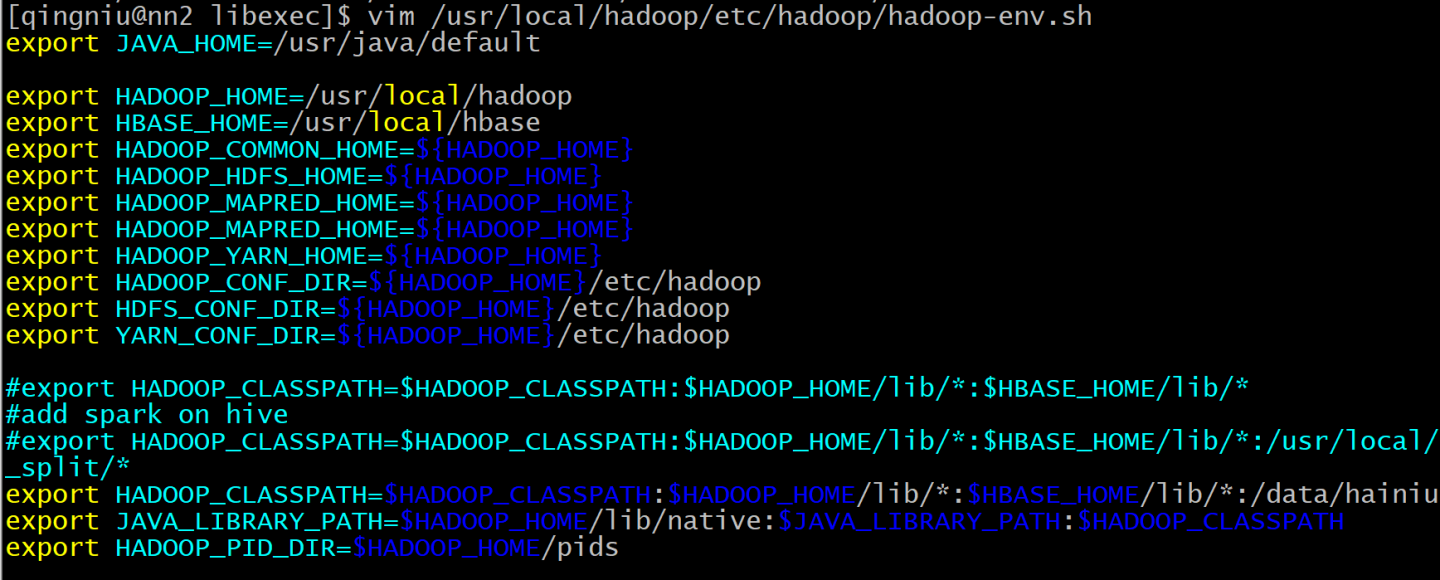
另外以后注意使用markdown语法编辑
-
后台程序是直接访问 HDFS 中数据吗?
不要直接访问HDFS上的数据,那样每次都走网络,把文件get到本地操作,或是导入到mysql中,可以用sqoop
-
设置 SSH 免密登录仍需密码?
@BigTester 恩恩,那就是落步骤了
-
Hadoop 部署集群时节点无法启动问题?
sh -x start-dfs.sh 看一下debug信息
-
Hadoop 部署集群时节点无法启动问题?
可以手动从主机ssh到其他slave节点吗?
-
Hadoop 50070 端口没有监听?
@足迹 不客气,很遗憾没有猜中你的问题:relaxed: :relaxed: :relaxed: :relaxed: :relaxed: :relaxed:
-
关于 spark hbase MySQL 的几个问题?
第一个问题:
你使用的hbase的类没有继承Serializable,spark要求在rdd的function中的类都要继承Serializable。
不过你现在使用的是hbase现有的类,所以没办法修改代码让其继承Serializable,那可以借助spark的KryoSerializer进行序列代,比如conf.set("spark.serialize",classOf[KryoSerializer].getName()) conf.registerKryoClasses(Array[Class[_]](classOf[ImmutableBytesWritable]))或者把hbase的类放在rdd的function里面
第二个问题:
可以,使用SparkSession或者SQLContext都可以