1.kafka分布式消息队列
(1).概述
Kafka是由LinkedIn开发的一个分布式的消息系统,用作LinkedIn的活动流(Activity Stream)和运营数据处理管道(Pipeline)的基础
Kafka使用Scala编写,它以可水平扩展和高吞吐率而被广泛使用。目前越来越多的开源分布式处理系统如Cloudera、Apache Storm、Spark都支持与Kafka集成
设计目标
以时间复杂度为O(1)的方式提供消息持久化能力,对TB级以上数据也能保证常数时间复杂度的访问性能
高吞吐率。即使在非常廉价的商用机器上也能做到单机支持每秒100K条以上消息的传输
支持Kafka Server间的消息分区,及分布式消费,同时保证每个Partition内的消息顺序传输
同时支持离线数据处理和实时数据处理
Scale out:支持在线水平扩展
(2).为什么使用消息队列
解耦、冗余、扩展性、灵活性 & 峰值处理能力、可恢复性、顺序保证、缓冲、异步通信
(3).体系结构
(4).基本原理
(4-1).分布式
Commit Log 的 partitions分布在kafka集群中不同的broker上,每个broker可以请求备份其他broker上partition上的数据。kafka集群支持配置一个partition备份的数量
针对每个partition,都有一个broker起到“leader”的作用,0个多个其他的broker作为“follwers”的作用
leader处理所有的针对这个partition的读写请求,而followers被动复制leader的结果。如果这个leader失效了,其中的一个follower将会自动的变成新的leader。每个broker都是自己所管理的partition的leader,同时又是其他broker所管理partitions的followers,kafka通过这种方式来达到负载均衡
(4-2).消息生产
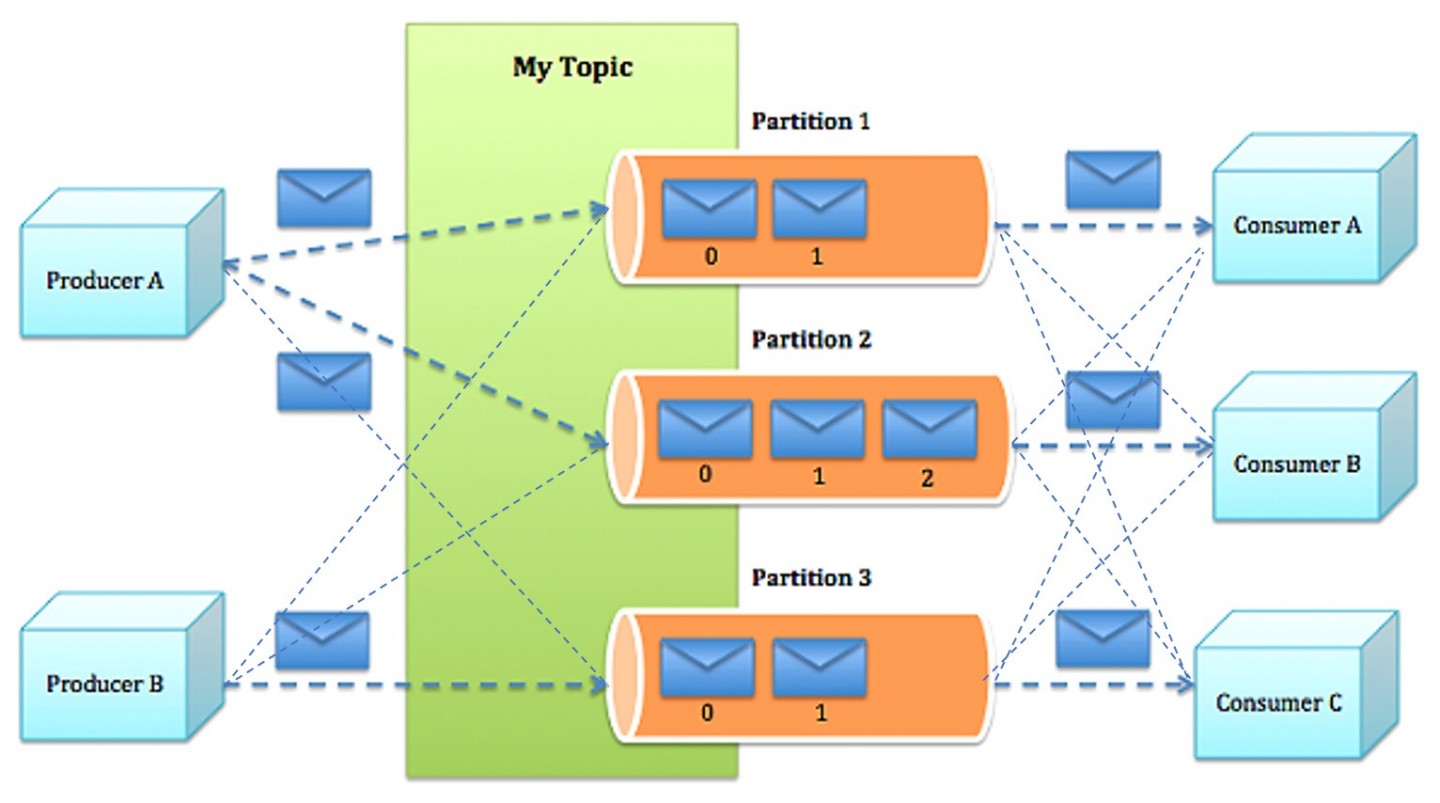
Producer将消息发布到它指定的topic中,并负责决定发布到哪个分区
主要两种方式
round-robin做简单的负载均
根据消息中的某一个关键字来进行区分
Producer根据指定的partition方法(round-robin、hash等),将消息发布到指定topic的partition里面
(4-3).消息消费
消息传递模式
队列(queuing),多个consumer从服务器中读取数据,根据消费者自己定义的队列数据位置来得到数据
发布订阅(publish-subscribe),在 publish-subscribe模型中,消息会被广播给所有的consumer
Kafka提供了一种consumer的抽象概念:consumer group
每个consumer都要标记自己属于哪一个consumer group
发布到topic中的message会被传递到consumer group中的一个consumer 实例
consumer实例可以运行在不同的进程上,也可以在不同的物理机器上
如果所有的consumer都位于同一个consumer group 下,这就类似于传统的queue模式,并在众多的consumer instance之间进行负载均衡
(4-4).消费顺序
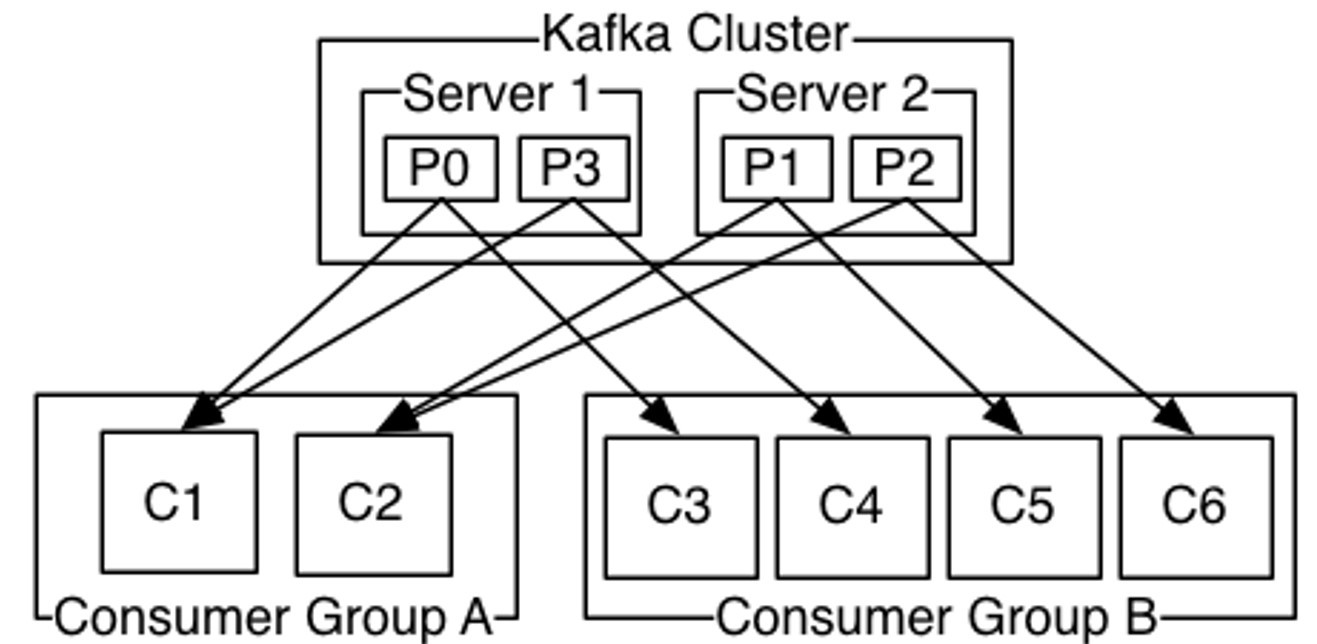
Kafka通过Topic中partition概念实现并行消费
Kafka可以同时提供顺序性保证和多个consumer同时消费时的负载均衡
实现的原理是通过将一个topic中的partition分配给一个consumer group中的不同consumer instance
通过这种方式,我们可以保证一个partition在同一个时刻只有一个consumer instance在消息,从而保证顺序
Kafka只在partition的范围内保证消息消费的局部顺序性,不能在同一个topic中的多个partition中保证总的消费顺序性
(5).kafka优化
多磁盘并且不做raid,就是为了充分利用多磁盘并发读写,又保证每个磁盘连续读写 的特性
合理设置topic的partition数量,保证并发度
Jvm参数调优推荐使用 CMS或者G1 垃圾回收器,内存不宜过大4G左右即可
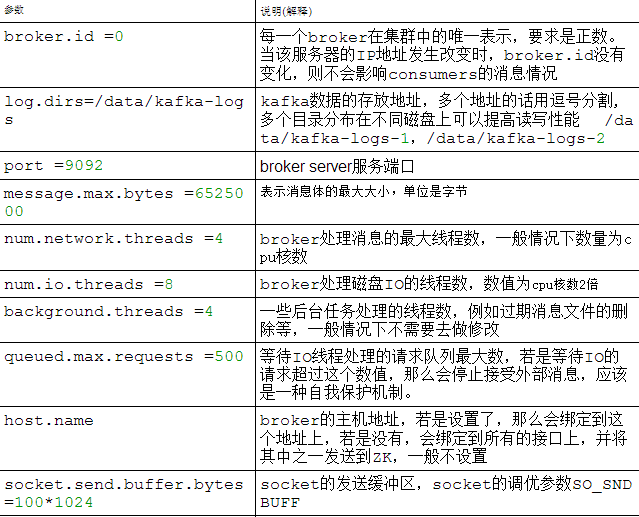







2.kafka安装
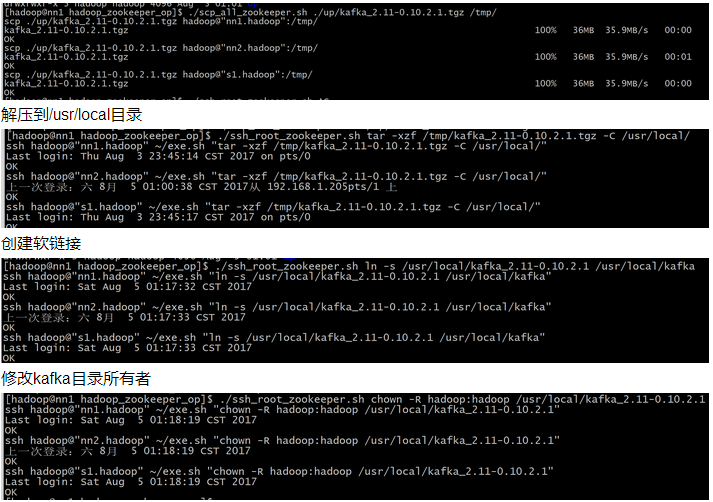
复制到每台机器
修改/usr/local/kafka/config/server.properties文件
定义端口

设置zookeeper地址和超时时间

配置producer服务地址 producer.properties

配置consumer地址 consumer.properties

配置log存储目录,设成多硬盘方式

设置日志数据是否自动删除

拷贝配置文件到每台机器
这个设置要每台机器不一样,和zookeepery的myid一个意思 server.properties

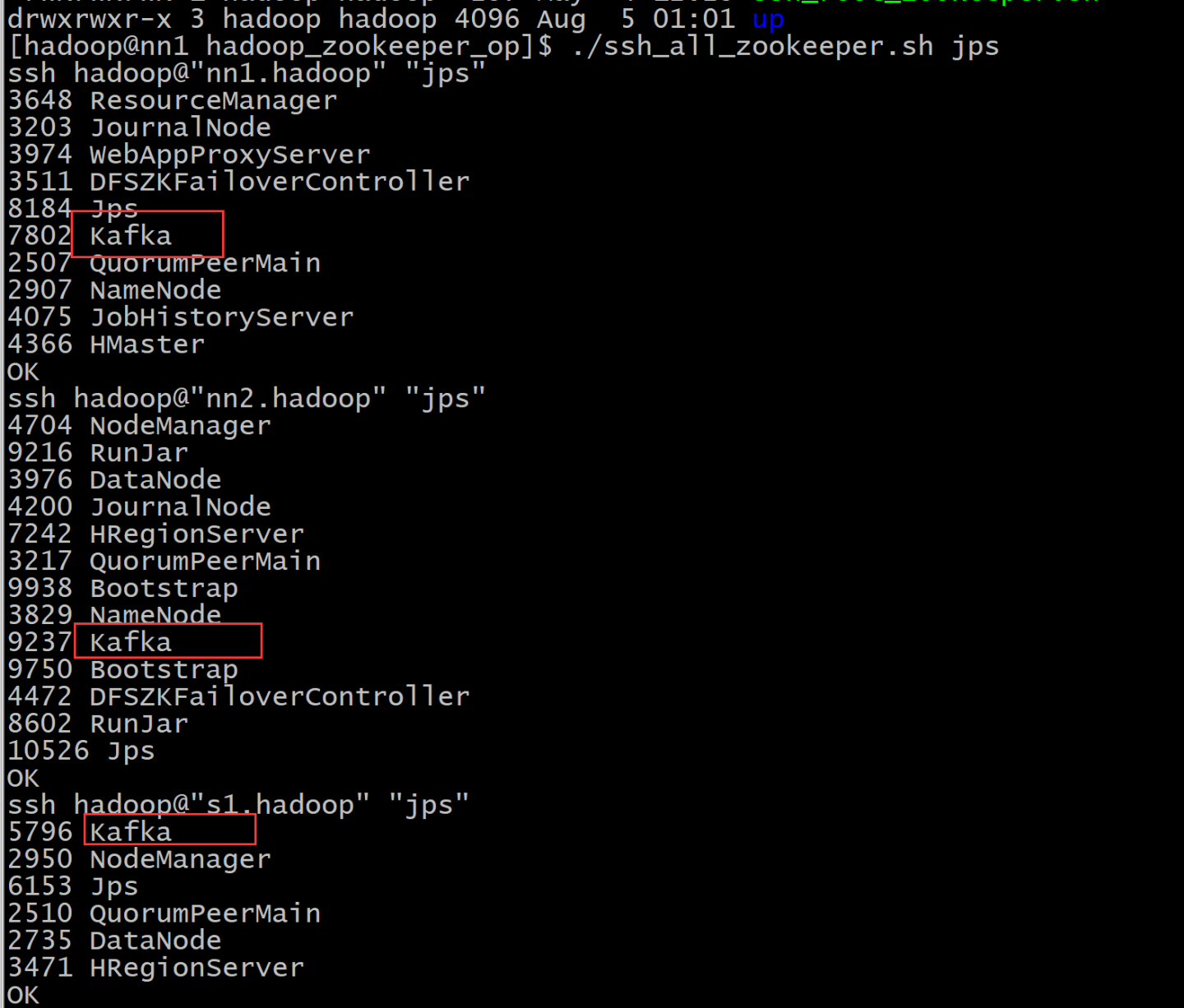
./ssh_all_zookeeper.sh "nohup /usr/local/kafka/bin/kafka-server-start.sh /usr/local/kafka/config/server.properties > /tmp/kafka_logs 2>&1 &"
创建topic
版权声明:原创作品,允许转载,转载时务必以超链接的形式表明出处和作者信息。否则将追究法律责任。来自海汼部落-青牛,http://hainiubl.com/topics/201


