公开课回放地址:https://www.bilibili.com/video/BV1eN4y1b7CU
Hbase数据迁移
在生产和工作环境中,我们有时候会遇见集群的升级,集群的冷热备份,公司多集群间数据转移的问题,这个时候hbase作为在大数据环境中主流的存储数据库,是首当其冲需要解决的问题,那么以下我们通过三种方式实现两个集群间的数据的迁移。
1.回顾
在迁移数据之前我们对hbase进行回顾一下
hbase作为google的大数据三篇比较重要的论文之一,它的起源叫做bigtable,意思非常简单就是大表的意思,是一个分布式存储很多数据的大型表格系统,它是对于hdfs中的数据不能直观查询和随机读写的病痛的一个补充和完善
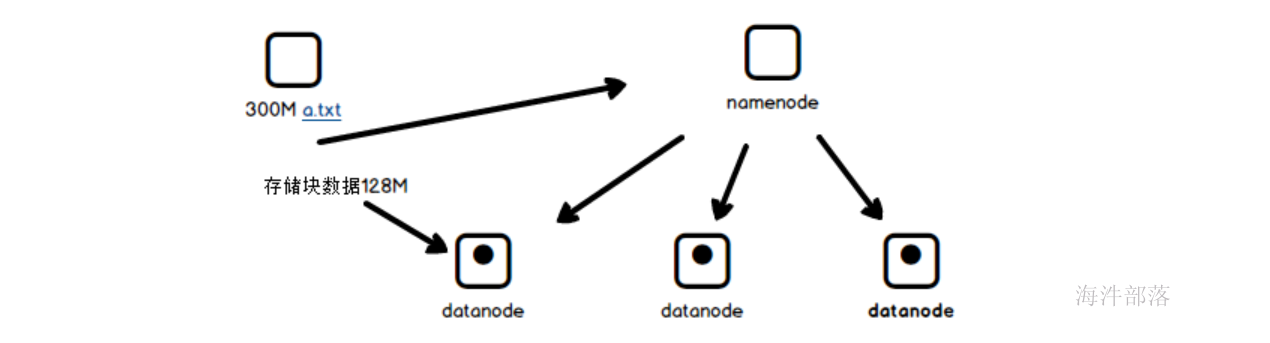
hdfs作为大数据场景中的基本存储介质,像是一个仓库一样可以实现大量数据的整体存储和读取,但是不够灵活,这个时候我们需要一个灵活存储和管理的上层存储框架hbase,它是hbase上层的一个高级框架,可以实现灵活的数据CURD。并且存储量也是比较大的,可以实现大量数据和超宽表的存储和管理
hbase是如何实现上层管理的呢?
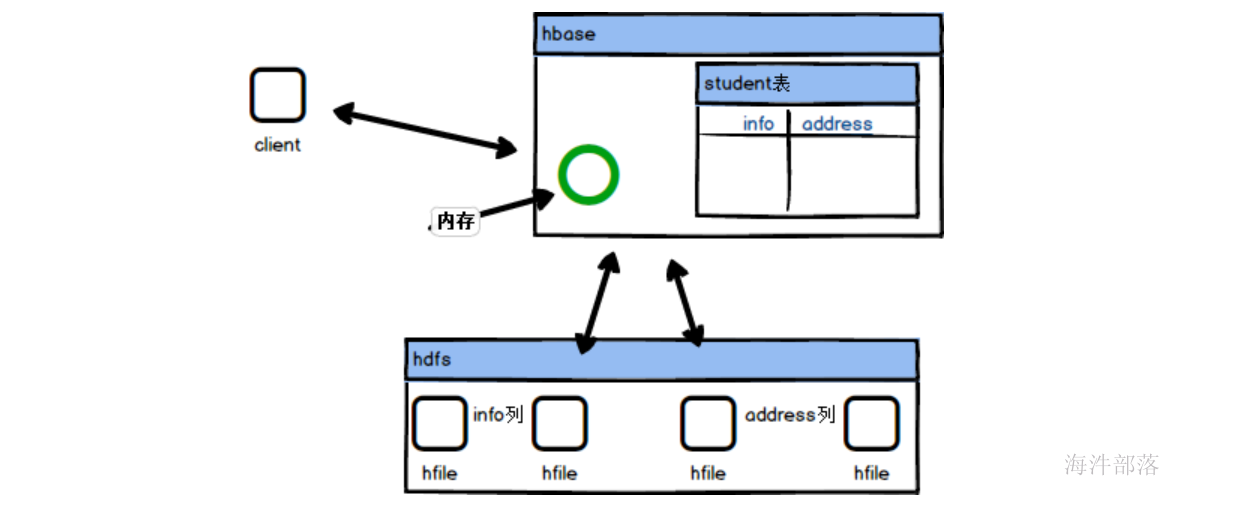
hbase首先是hdfs上层的一个管理层,hbase自身是带有元数据信息的,用来记录我们在hbase中创建了多少个表,并且每个表存在多少个列,这样就可以实现表格级别的使用和管理,并且会将表格的数据放入到hdfs中存储,为了方便查询和管理会按照表的列进行文件的存储和分类,比如info列就会存储到一个单独的hfile文件中,但是hbase中存储的数据会非常的多,那么一个列单独保存在一个hfile中,也是难管理和查询的,所以按照行级别进行数据的分割存储到不同的文件中,这样可以非常快速的检索出来数据,但是不能够解决掉数据的修改问题,因为底层是hdfs的存储,这样是没有办法灵活修改和变化的,这个时候hbase引入了一块内存区域,会将数据的修改和插入放入到内存中,一旦缓存区中的数据满了,那么就会将数据存储到hdfs中并且对数据进行修改和合并操作,能够保证灵活的数据修改,并且通过图中我们可以发现数据是按照列为一个整体进行存储的,所以查询效率会更高,大数据场景中存储的数据会存在很多列,那么我们只需要其中的两列就可以直接去相应的hfile中读取数据,不需要全部的hfile文件都扫描读取
从而实现灵活的数据随机读写
hbase的整体架构如下:
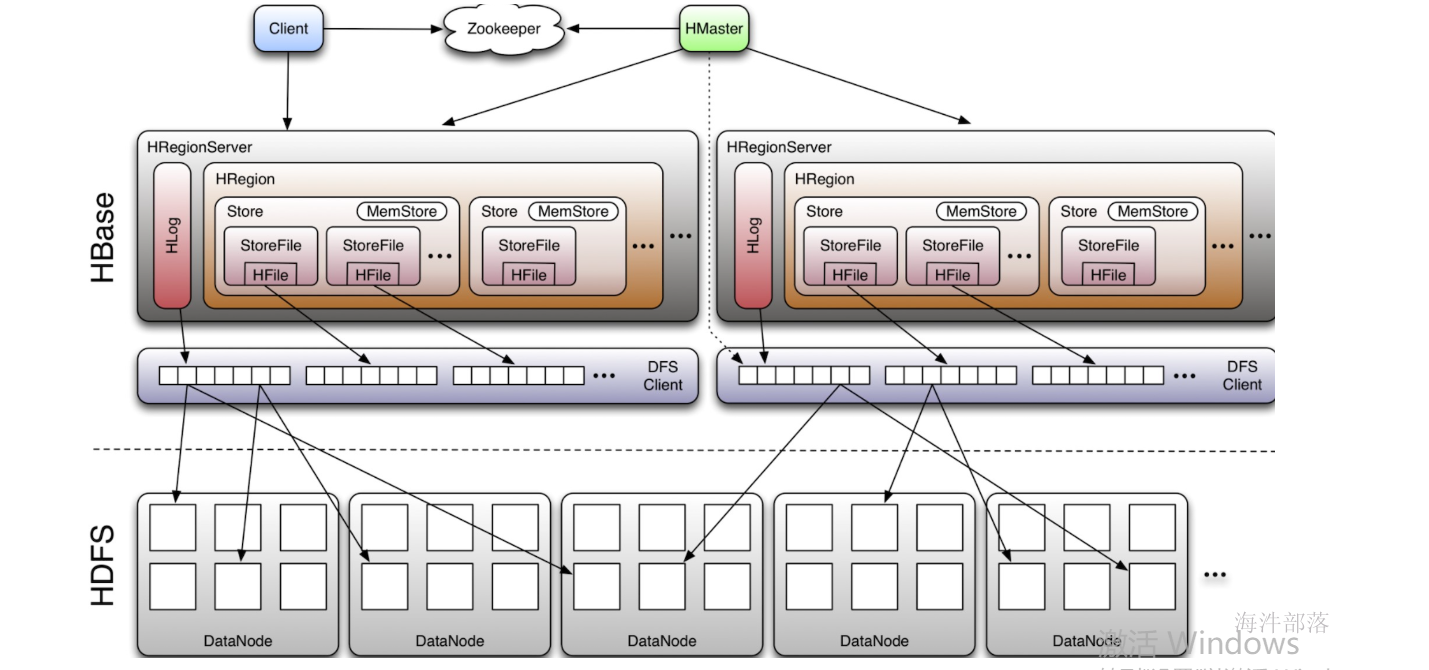
HMaster
hmaster一般都是两台机器,使用zookeeper进行管理和协调
管理表操作,如:create、alter、drop;
管理HRegionServer的负载均衡,调整region分布;
region split后,负责新region重分布;
在HRegionServer停机后,负责失效的HRegionServer上region的迁移;
HRegionServer
真正干活的节点,一般会和datanode部署到一起
维护region,处理region的IO请求,如:put、get、scan、delete;
regionserver负责切分在运行过程中逐渐变大的region
Region
一个表会按照rowkey的范围进行行级别的分割,分割出来的一个部分就叫做region,它是表的一部分数据,可以分散到不同的regionserver中进行管理,是一个表的最小负载均衡的单位
每个region都会记录自己的startkey和endkey的范围
Store
每一个列族对应一个Store,一个Region里包含一个或者多个Store,>由此在设计cf时,尽量将同一系列的数据存在一个列族中,便于同一系列的数据都存在同一个region中。
Hlog
hbase WAL(write ahead log),在用户发起写请求时先向Hlog写一份,然后再将数据向memstore中写,Hlog数据是写磁盘,为了避免HRegionServer故障时memstore数据丢失,Hlog滚动更新,新数据会加入会对应冲抵掉较早的Hlog数据。
Memstore
hbase写缓存,在用户发起写请求时先写入hlog,然后再写入memstore中,当memstore写入达到flush阈值时,将memstore中的数据写到hdfs上(hfile),每个列族对应一个memstore,即一个HStore/Store中只有一个memstore。
storefile
当memstore写数据达到设定的阈值之后,会将数据溢写到hdfs,即storefile,内部存储hfile。storefile会进行合并,当storefile经过多次合并后变得已经达到指定规则的分裂阈值,则再进行region分裂。
2.环境准备
http://cloud.hainiubl.com/?#/privateImageDetail?id=16485&imageType=private
实验镜像如上
点击加入实验配置,如上图
此实验包含两个集群,分别是nn1,nn2,s1,s2,s3 作为一个集群称之为原始集群,数据原始存放位置,nn11,nn21,s11,s21,s31作为目标集群
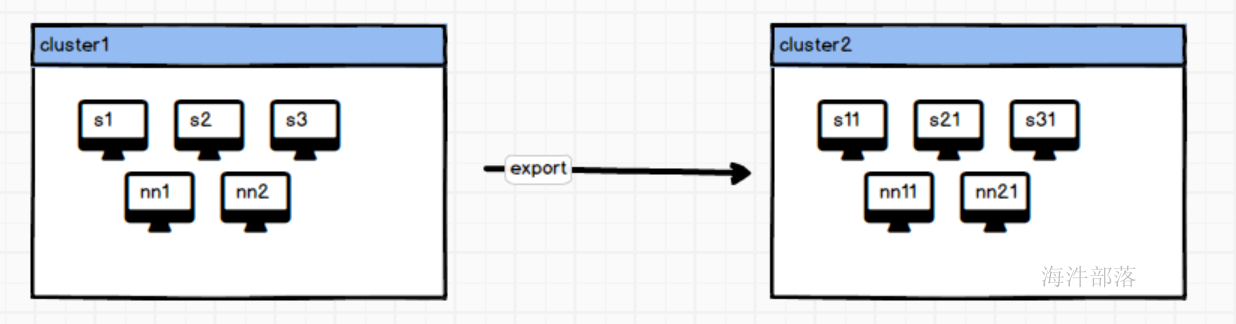
3.启动集群
#分别在cluster1和cluster2集群中进入nn1和nn11
#以上两个机器作为两个集群的主节点进行启动,
#启动顺序如下
su - hadoop
ssh_all_zk.sh /usr/local/zookeeper/bin/zkServer.sh start
# 两个集群同时启动zk集群
start-dfs.sh
start-yarn.sh
#启动hdfs和yarn集群
start-hbase.sh
# 启动两个机器的hbase集群
# 分别进入到nn2和nn21节点
# 因为要使用hive,要先启动mysql和hive的metastore
su - root
systemctl start mysqld
su - hadoop
nohup hive --service metastore &到现在为止启动组件准备完毕
选择左下角的远程桌面,然后分别进入到监控页面查询进程
分别查询是不是所有组件都正常执行
3.使用hive进行数据迁移
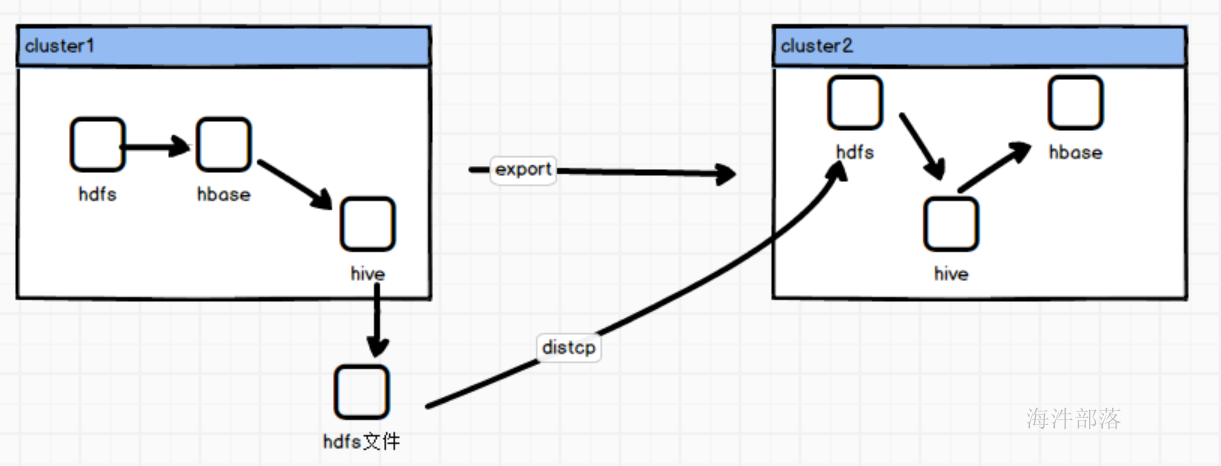
逻辑如上:
- 集群一中存在hbase中表的数据install_hbase 存在2000w条数据
- 将数据使用hive将数据导出到hdfs文件
- 将集群一的数据进行distcp传到另一个集群中
- 在另一个集群中使用hive创建hdfs的表映射到文件,再创建hbase的映射表,使用hive进行数据的导入
create external table install_hbase(aid string,pkgname string,uptime string,type int,country string,category string)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping" =
":key,info:pkgname,info:uptime,info:type,info:country,info:category")
TBLPROPERTIES ("hbase.table.name" = "install_hbase");
set mapreduce.job.queuename=root.hainiu;
insert overwrite directory '/tmp/install' select * from install_hbase;将数据存储到hdfs的/tmp/install文件中
然后将数据远程发送到另一个集群使用distcp
实现集群拷贝
hadoop distcp -Dmapreduce.job.queuename=root.hainiu -m 3 /tmp/install hdfs://nn11:9000/检查集群二中的传输内容

这个时候在集群二中创建hive的映射表和hbase映射表,然后使用hive将数据进行导入
create table install_hbase(aid string,pkgname string,uptime string,type int,country string,category string);
load data inpath '/install/000000_0' into table install_hbase;
Loading data to table default.install_hbase
hive (default)> set mapreduce.job.queuename=root.hainiu;
hive (default)> select count(1) from install_hbase;
发现数据已经到达hive表中
这个时候使用hive创建hbase的映射表
create table install_hbase_export(aid string,pkgname string,uptime string,type int,country string,category string)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping" =
":key,info:pkgname,info:uptime,info:type,info:country,info:category")
TBLPROPERTIES ("hbase.table.name" = "install_hbase_export");
insert into install_hbase_export select * from install_hbase;
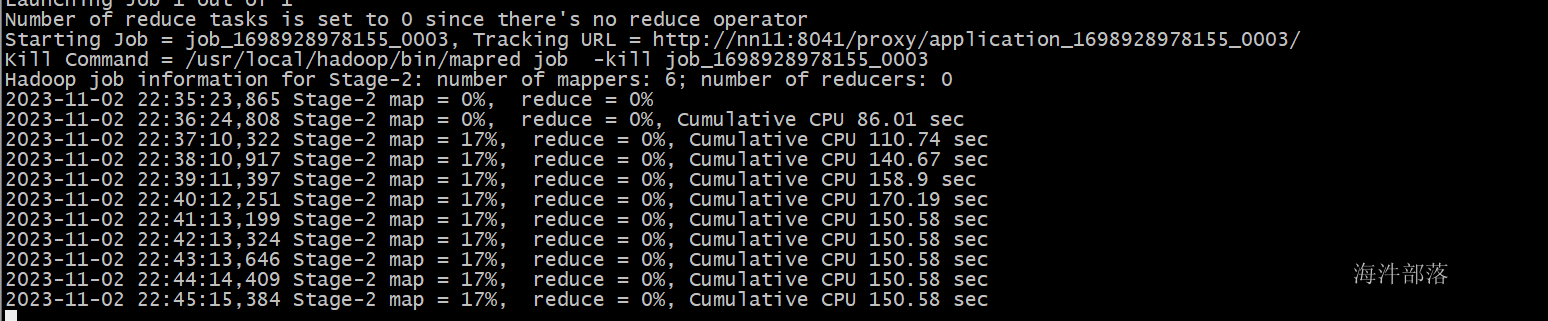
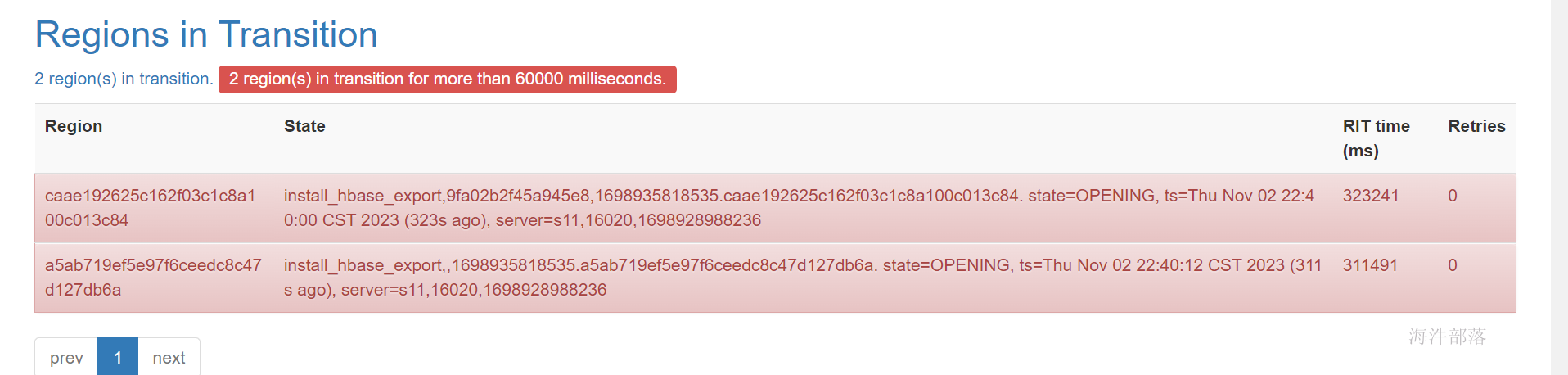
发现会出现因为内存不足死掉问题
因为在hbase中存储数据,首先数据会存储到hbase的内存memstore中,这个时候和yarn会争抢内存,所以会出现hbase节点宕机问题,而且因为hbase的数据存储底层是需要分region的,那么region数据过大会出现region拆分下线问题。
所以我们导入数据一般采用bulkload方式
4.使用ImportTsv导入数据
原理如下:
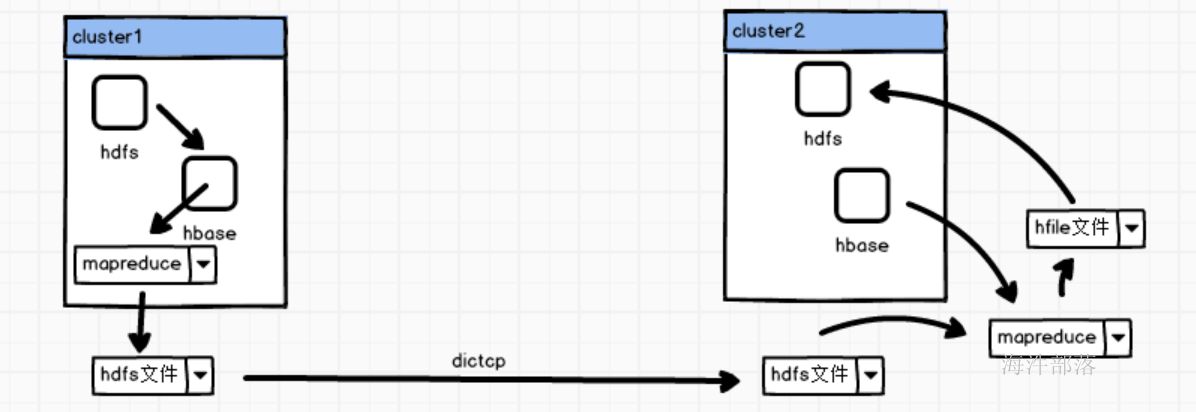
- 首先将数据使用mr将第一个集群的hbase数据写出到hdfs中
- 然后将数据使用distcp远程复制过来到第二个集群
- 然后使用mapreduce根据hbase的表结构,直接生成hbase对应的hfile文件
- 然后将hfile文件直接加载到hdfs中
- 这个过程省去了在hbase内存中存储的过程,保证效率的同时保证了hbase的稳定性
操作步骤如下:
# 首先在第一个集群中执行hive任务,将数据导出到hdfs中
set mapreduce.job.queuename=root.hainiu;
insert overwrite directory '/tmp/install' select * from install_hbase;
执行任务完毕后可以发现数据已经成功导出
然后使用distcp远程发送到集群二中
hadoop distcp -Dmapreduce.job.queuename=root.hainiu -m 3 /tmp/install hdfs://nn11:9000/tmp/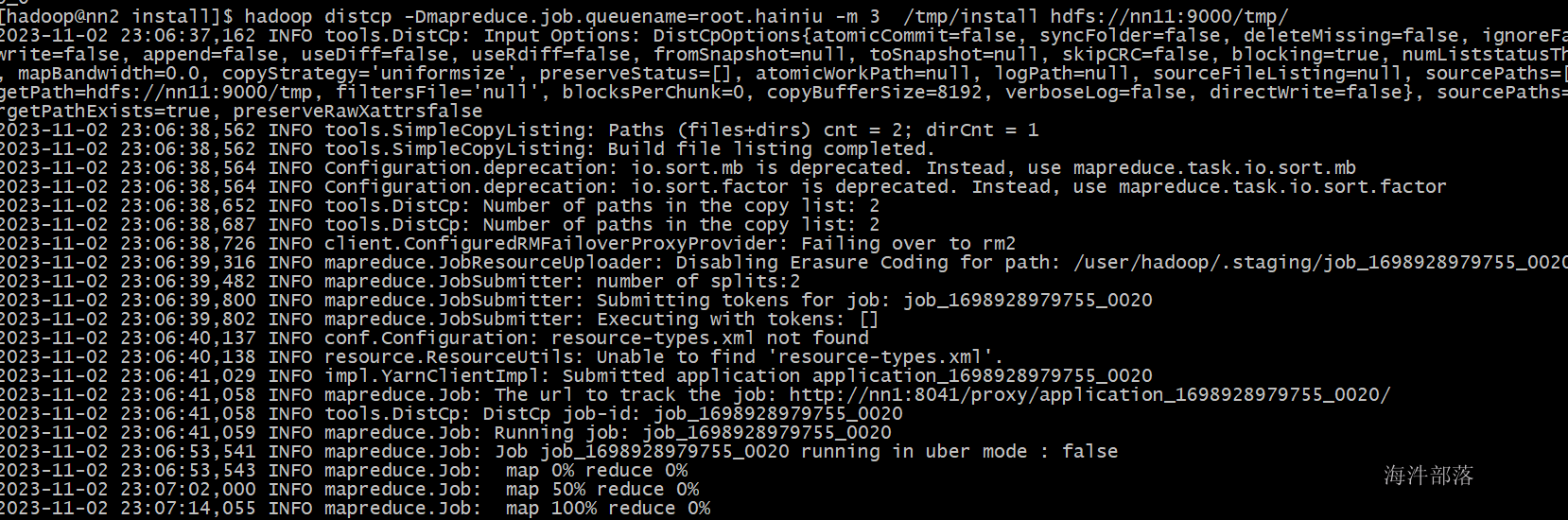

可以发现文件已经传输完毕
# 在集群二中创建hbase的表
hbase shell
create 'install_hbase','info'
这个时候使用ImportTsv生成hbase对应的hfile文件
hbase org.apache.hadoop.hbase.mapreduce.ImportTsv -D mapreduce.job.queuename=root.hainiu \
-Dimporttsv.separator=$(echo -e "\001") \
-Dimporttsv.columns=HBASE_ROW_KEY,info:pkgname,info:uptime,info:type,info:country,info:category \
-Dimporttsv.skip.bad.lines=false \
-Dimporttsv.bulk.output=/hbase_tmp \
default:install_hbase hdfs://ns1/tmp/install对应参数解析
- Dimporttsv.separator分隔符,本应该是\001但是hbase导出的时候不支持,所以必须使用echo转译为一个单独符号,否则编译不过,拆分符号超出长度
- Dimporttsv.columns 字段映射
- Dimporttsv.skip.bad.lines 跳过错误行
- Dimporttsv.bulk.output 对应hfile结果输出文件夹
- default:install_hbase 对应hbase的变
- hdfs://ns1/tmp/install 对应的文件内容

这个时候去文件夹中查询数据
使用加载命令将数据增量导入到hbase的对应表中
hbase org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles /hbase_tmp default:install_hbase
这个时候去hbase中查询数据
create external table install_hbase(aid string,pkgname string,uptime string,type int,country string,category string)
STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping" =
":key,info:pkgname,info:uptime,info:type,info:country,info:category")
TBLPROPERTIES ("hbase.table.name" = "install_hbase");
hive (default)> set mapreduce.job.queuename=root.hainiu;
hive (default)> select count(1) from install_hbase;
hbase org.apache.hadoop.hbase.mapreduce.RowCounter -Dmapreduce.job.queuename=root.hainiu 'install_hbase'


数据到此导入完毕
5.使用快照方式实现数据迁移
首先我们先来了解一下hbase的快照原理
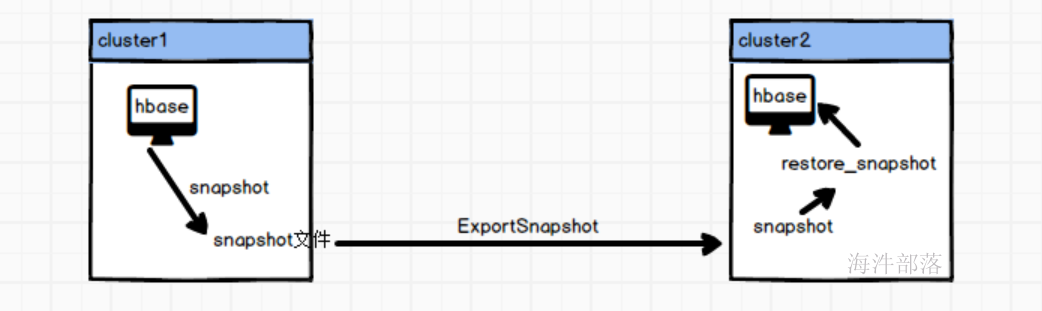
让我们先回顾一下hbase的snapshot原理
snapshot 是很多存储系统和数据库系统都支持的功能。一个 snapshot 是一个全部文件系统、或者某个目录在某一时刻的镜像。实现数据文件镜像最简单粗暴的方式是加锁拷贝(之所以需要加锁,是因为镜像得到的数据必须是某一时刻完全一致的数据),拷贝的这段时间不允许对原数据进行任何形式的更新删除,仅提供只读操作,拷贝完成之后再释放锁。这种方式涉及数据的实际拷贝,数据量大的情况下必然会花费大量时间,长时间的加锁拷贝必然导致客户端长时间不能更新删除,这是生产线上不能容忍的。
snapshot 机制并不会拷贝数据,可以理解为它是原数据的一份指针。在 HBase 这种 LSM 类型系统结构下是比较容易理解的,我们知道 HBase 数据文件一旦落到磁盘之后就不再允许更新删除等原地修改操作,如果想更新删除的话可以追加写入新文件(HBase 中根本没有更新接口,删除命令也是追加写入)。这种机制下实现某个表的 snapshot 只需要给当前表的所有文件分别新建一个引用(指针),其他新写入的数据重新创建一个新文件写入即可。如下图所示
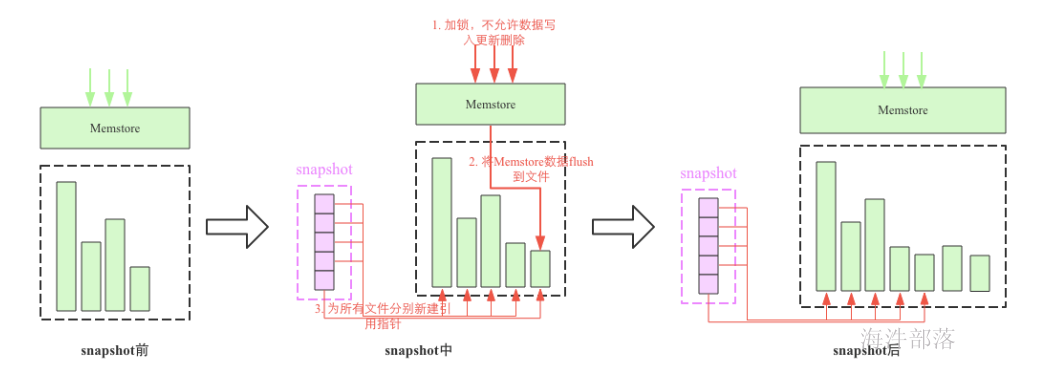
snapshot流程主要涉及3个步骤:
-
加一把全局锁,此时不允许任何的数据写入更新以及删除
-
将Memstore中的缓存数据flush到文件中(可选)
- 为所有HFile文件分别新建引用指针,这些指针元数据就是snapshot
但是大家会有一个问题,如果是表的数据file被删除会怎么办,因为毕竟不是复制数据而是将数据创建新的连接指针指向。删除的数据会存储到archive归档文件夹中,不会真正的删除。所以数据会持久保存不会丢失。
snapshot的使用
snapshot是HBase非常核心的一个功能,使用snapshot的不同用法可以实现很多功能,比如:
- 全量/增量备份:任何数据库都需要有备份的功能来实现数据的高可靠性,snapshot可以非常方便的实现表的在线备份功能,并且对在线业务请求影响非常小。使用备份数据,用户可以在异常发生的情况下快速回滚到指定快照点。增量备份会在全量备份的基础上使用binlog进行周期性的增量备份。
- 使用场景一:通常情况下,对重要的业务数据,建议至少每天执行一次snapshot来保存数据的快照记录,并且定期清理过期快照,这样如果业务发生重要错误需要回滚的话是可以回滚到之前的一个快照点的。
- 使用场景二:如果要对集群做重大的升级的话,建议升级前对重要的表执行一次snapshot,一旦升级有任何异常可以快速回滚到升级前。
2. 数据迁移:可以使用ExportSnapshot功能将快照导出到另一个集群,实现数据的迁移
- 使用场景一:机房在线迁移,通常情况是数据在A机房,因为A机房机位不够或者机架不够需要将整个集群迁移到另一个容量更大的B集群,而且在迁移过程中不能停服。基本迁移思路是先使用snapshot在B集群恢复出一个全量数据,再使用replication技术增量复制A集群的更新数据,等待两个集群数据一致之后将客户端请求重定向到B机房
而我们使用的则是第二种数据迁移
步骤如下:
# 首先将第一个表的数据进行snapshot备份
snapshot 'install_hbase','install_ckpt'
复制备份数据到第二个集群
hbase org.apache.hadoop.hbase.snapshot.ExportSnapshot -Dmapreduce.job.queuename=root.hainiu -snapshot install_ckpt -copy-from hdfs://nn2:9000/hbase -copy-to hdfs://nn11:9000/hbase -mappers 3 -bandwidth 8192
这个时候去第二个集群查询备份数据
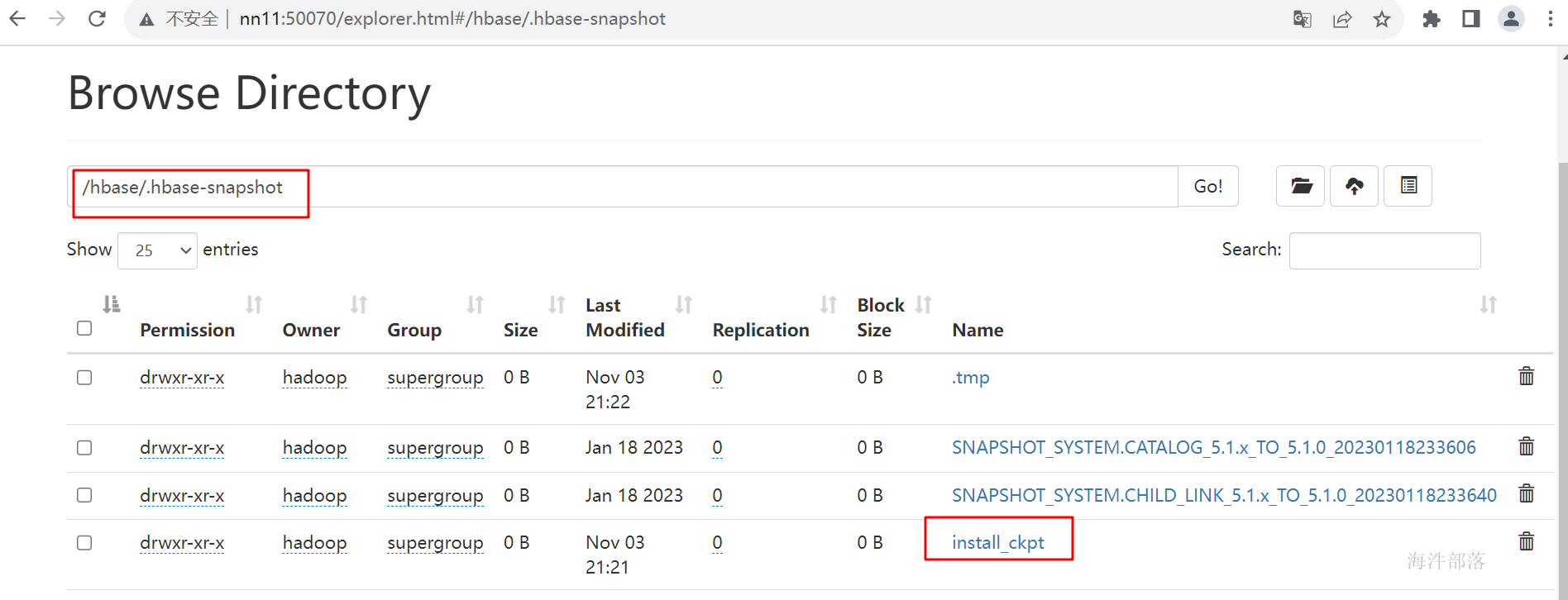
进入到第二个集群的hbase页面
hbase shell
然后恢复数据
restore_snapshot 'install_ckpt
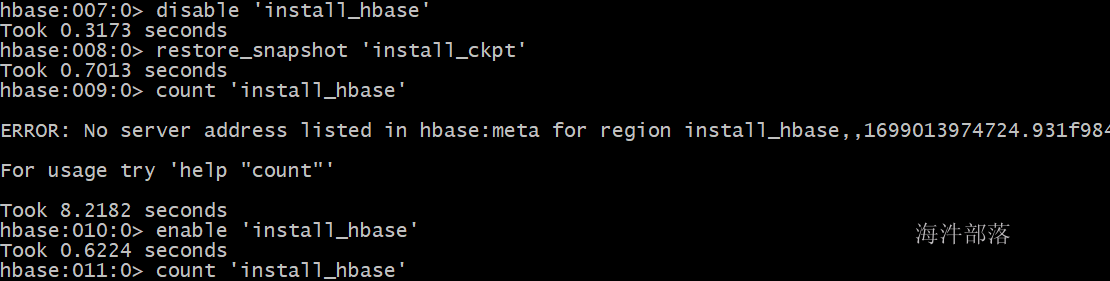
到此数据恢复完毕



