公开课回放地址:https://www.bilibili.com/video/BV1He411C7hP
kafka新特性和动态扩容
1.kafka是什么
Kafka是由LinkedIn开发的一个分布式的消息队列。它是一款开源的、轻量级的、分布式、可分区和具有复制备份的(Replicated)、基于ZooKeeper的协调管理的分布式流平台的功能强大的消息系统。与传统的消息系统相比,KafKa能够很好的处理活跃的流数据,使得数据在各个子系统中高性能、低延迟地不停流转。
Kafka使用Scala编写,它以可水平扩展和高吞吐率而被广泛使用。目前越来越多的开源分布式处理系统如Cloudera、Apache Storm、Spark都支持与Kafka集成。
2.什么是消息队列
消息队列:是在消息的传输过程中保存消息的容器。

消息在原始的传输过程中是直接传输的,端对端的数据传递,但是有的时候我们需要将消息数据进行部分的缓冲存储,以达到方便使用的目的,中间的组件可以做消息的传输中间介质,这个组件就是消息队列。更像是一个消息的蓄水池一样的功能
类比现实中更像是高速公路的休息区

那么消息队列在什么场景使用呢
3.消息队列的好处
缓冲
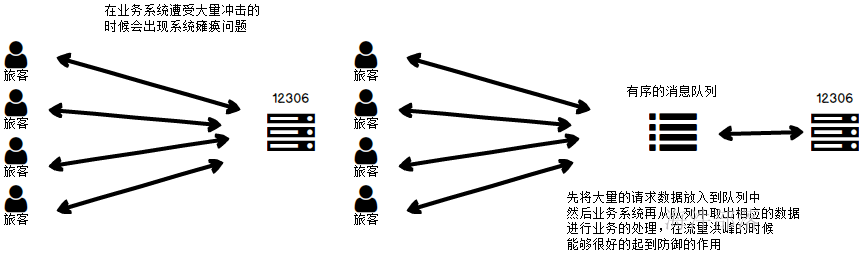
解耦
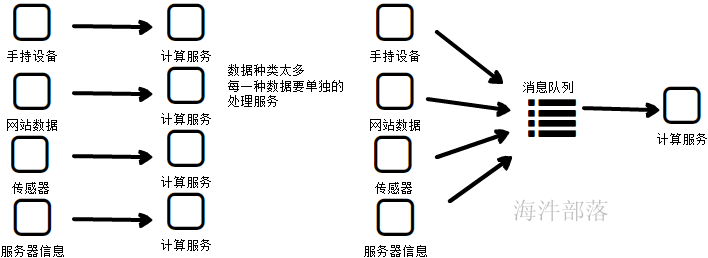
异步
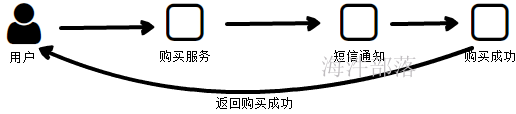
如果是同步服务,如上图,那么用户的体验度是非常差的,因为需要将短信发送完毕然后在返回成功通知,页面才会跳转,但是如果短信发送遇见网络等问题,没有办法直接发送,这个时候客户需要等待很长的时间

直接将需要发送的消息放入到消息队列中,然后消息服务会不停的扫描队列中需要发送的消息将数据发送出去,但是不会让客户等待,用户会大大的增加体验度
抵挡洪峰

如上图,我们需要处理流量的波峰和抖动,那么我们需要设定整个集群的处理能力达到最大的5M/s才可以,但是大多数时候这个处理能力都是浪费的,我们用不到
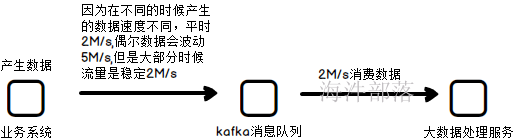
我们可以使用消息队列进行数据的存储,然后计算服务慢慢去消息队列中拉取数据进行消费就可以了,可以在一定程度节省成本
4.kafka的组件结构
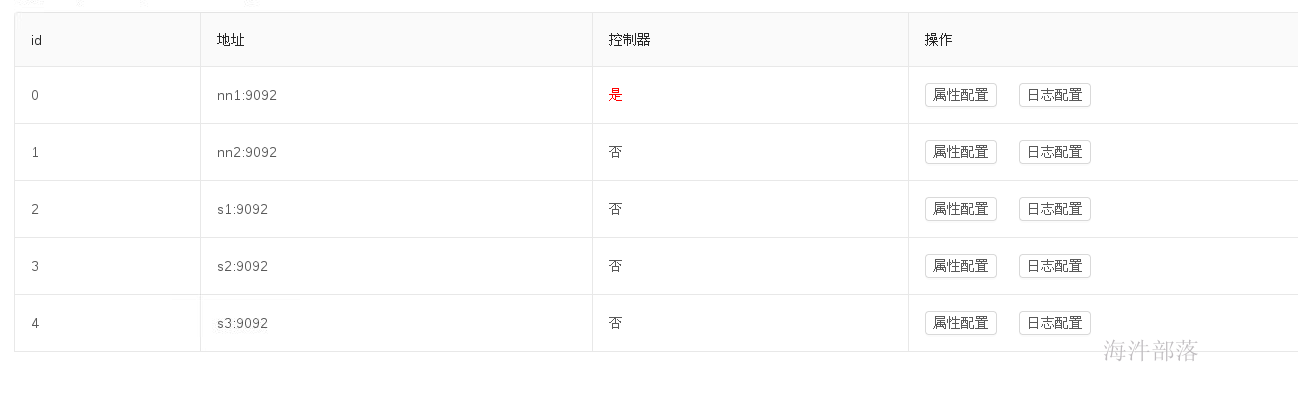
broker:每个kafka的机器节点都会运行一个进程,这个进程叫做broker,负责管理自身的topic和partition,以及数据的存储和处理,因为kafka是集群形式的,所以一个集群中会存在多个broker,但是kafka的整体又不是一个主从集群,需要选举出来一个broker节点为主节点,管理整个集群中所有的数据和操作,以及所有节点的协同工作。每个broker上面都存在一个controller组件,这个组件就是主节点管理组件,负责整个集群的管理,但是只有一个机器是active状态的,这个需要zookeeper进行协调和选举
topic:在kafka中存在一个非常重要的逻辑结构叫做topic,可以称之为主题。当我们很多业务需要使用kafka进行消息队列的消息缓存和处理的时候我们会将消息进行分类处理,不能让多种类的数据放入到一起,这样使用特别混乱,所以topic主主题进行分类,是kafka数据处理的一大特色,可以类比现实中的主播。一个主播在直播的时候都会创建一个自己的房间,每个主播都不会相互干扰。各自主播自己的内容。
partition:分区,每个topic中在使用过程中会存储很多数据,这些数据如果默认只给一个broker进行处理,那么这个broker的压力会太大,集群应该负载均衡让数据的压力在不同的机器上共同分摊,所以每个topic都会分为不同的分区,一个分区是一个topic数据真正的物理存储方式,让数据分为不同的部分,在多个节点上存储和管理。分区是kafka物理存储最小的负载均衡单位,生产者生产数据的时候指向多个分区,消费者也可以在消费数据的时候从不同的分区读取数据
每个broker节点会按照topic的名称和分区的名称组合在一起形成一个文件夹进行文件内容的存储,一个broker会管理多个topic的不同分区的数据
备份:在一个topic中存在多个分区,每个分区存储一部分这个topic的数据,但是因为存在多个机器上,不能够保证数据的稳定性,所以数据需要进行备份管理,所以分区是存在备份的,比如topicA的数据就需要存储多份在不同的机器上,这样数据损坏一份,其他的部分还可以使用
主从:数据在存储的时候需要备份多个,那么这些数据就要保证数据的一致性,所以我们不能再存放数据的时候随意的向任何副本写入,因为这样集群中一个分区的多个副本没有办法保证数据的一致性,所以我们只能写入数据到一个副本,这个副本叫做主副本,其他的副本会从主副本同步数据,从而保证数据的一致性,那么这个主从的选举是broker的主节点进行选举的和zookeeper没有关系
zookeeper:帮助选举broker为主,记录哪个是主broker,集群存在几个topic,每个topic存在几个分区,分区存在几个副本,每个分区分别在哪个机器节点上
producer: 生产者,将数据远程发送到kafka集群,一般都是flume进行数据采集,并且发送到集群,producer一般只能发送数据到一个topic中,和一个主播只能在自己的房间直播一样
consumer:消费者,消费数据并且参加计算处理,一般都是spark,flink等计算框架充当。但是一个消费者可以同时消费多个分区的数据,就如一个观众可以一起看多个小姐姐直播一样
5.kraft集群的搭建
首先选择我们之前搭建kafka时候的初始化镜像
http://cloud.hainiubl.com/#/privateImageDetail?id=2969&imageType=private
搭建准备工作,首先在海牛实验室中启动基础镜像,并且调节资源大小
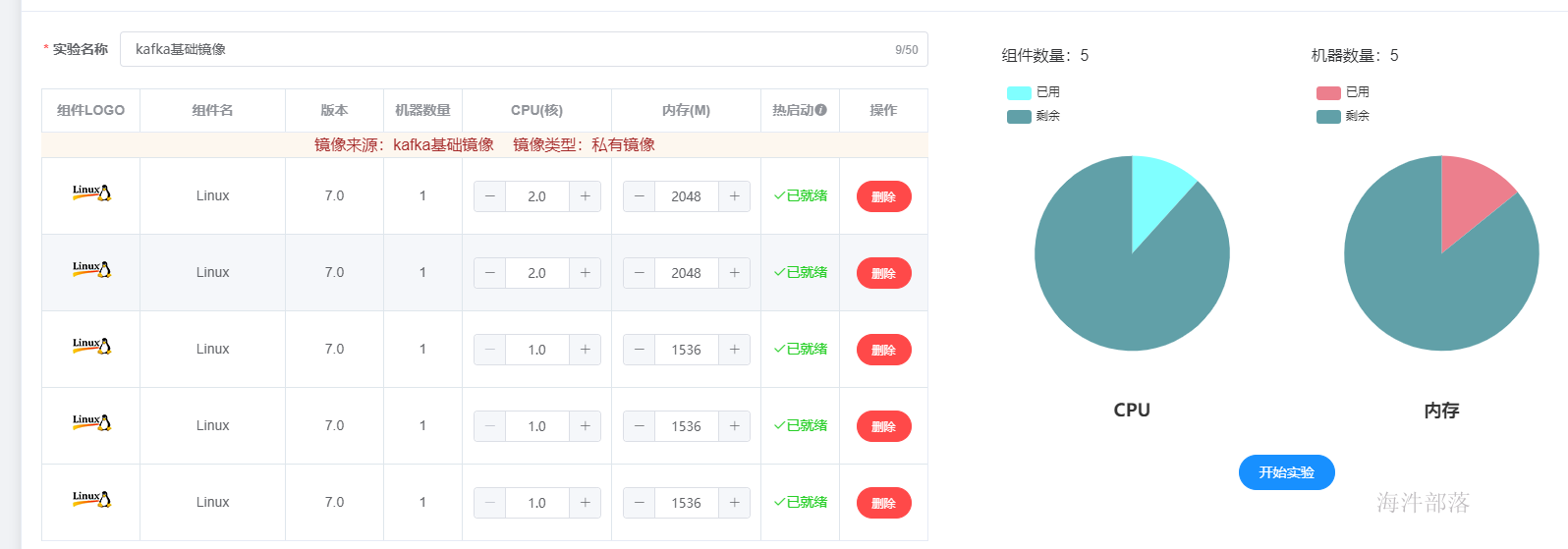
调节大小如下:
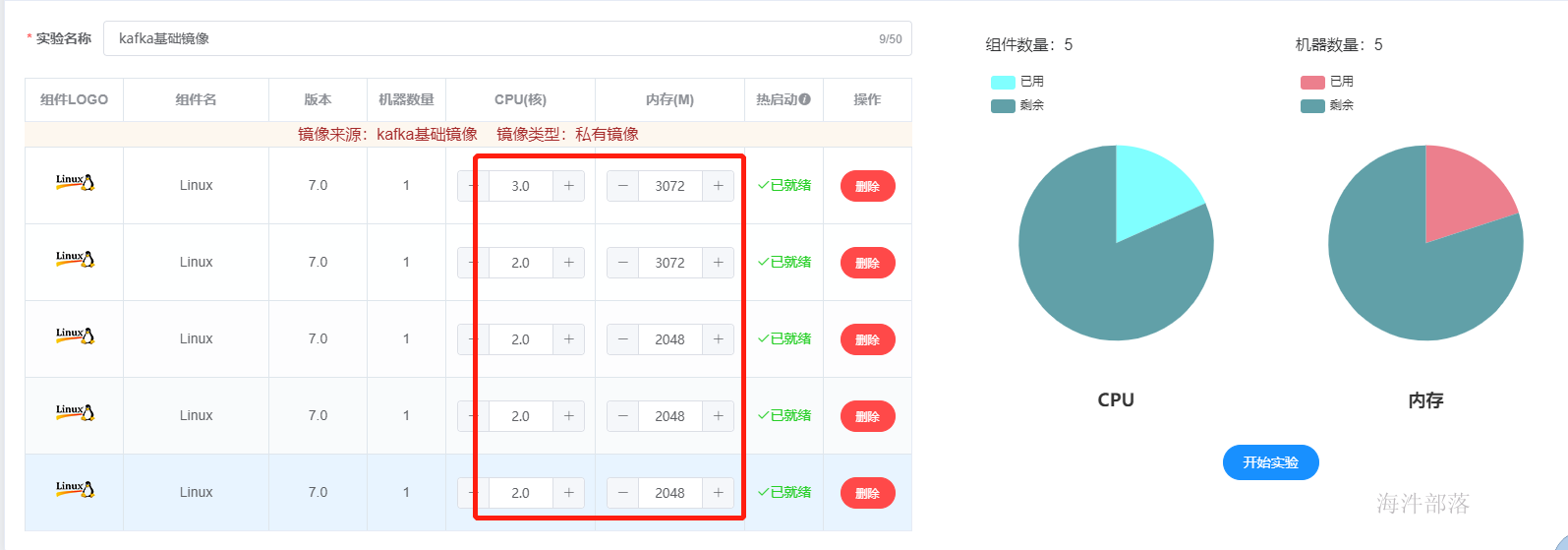
因为演示效果每个机器都安装一个kafka的集群节点
安装包等信息全部都已经存放到 /public/software/bigdata中为大家准备好了。我们直接使用就可以
# 首先将安装包解压到每个机器中
ssh_root.sh tar -zxvf /public/software/bigdata/kafka_2.12-3.3.2.tgz -C /usr/local/
# 查看解压情况
ssh_root.sh ls /usr/local|grep kafka
# 修改权限
ssh_root.sh chown hadoop:hadoop -R /usr/local/kafka_2.12-3.3.2/
# 创建软连接
ssh_root.sh ln -s /usr/local/kafka_2.12-3.3.2/ /usr/local/kafka
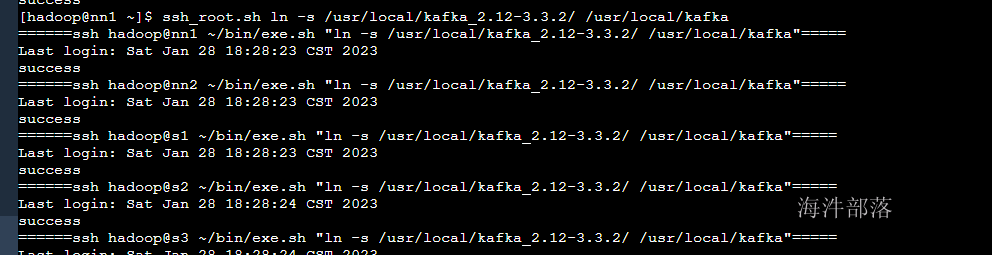
查看安装包中的内容

比较重要的三个文件夹
bin 执行脚本
config 配置文件
libs 依赖包
# 配置环境变量
echo 'export KAFKA_HOME=/usr/local/kafka' >> /etc/profile
echo 'export PATH=$PATH:$KAFKA_HOME/bin' >> /etc/profile
source /etc/profile
首先连接所有的节点
选择批量命令
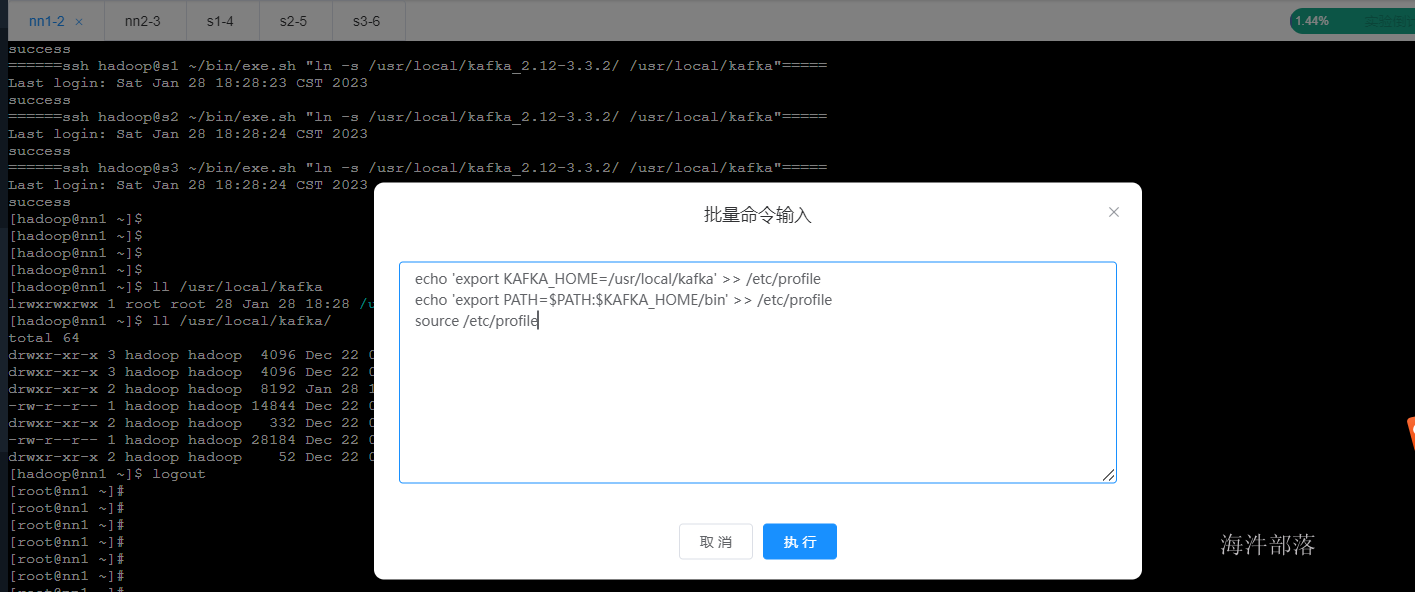
将上面的命令群体执行
到现在为止集群的初始化安装已经完毕,我们下面做kafka的自定义设置
# 修改server.properties配置文件
cd /usr/local/kafka/config/kraft
vim server.properties修改如下的配置
log.dirs=/data/kafka-logs # kafka存放数据的位置
#角色
process.roles=broker, controller
# 节点id
node.id=0
# 选举节点
controller.quorum.voters=0@nn1:9093,1@nn2:9093,2@s1:9093
# broker暴露端口
advertised.Listeners=PLAINTEXT://nn1:9092# 首先修改log.dirs zookeeper.connect两个参数
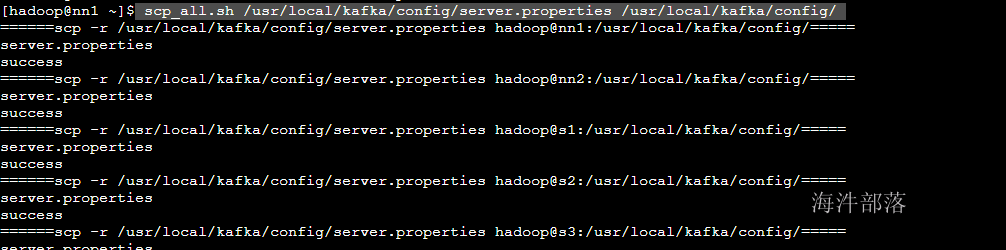
# 分发到不同的机器节点
scp_all.sh /usr/local/kafka/config/kraft/server.properties /usr/local/kafka/config/kraft/分发配置文件以后一定要记得将node.id和ip修改,并且只有前三个的角色是controller后面的角色不能存在controller,因为controller角色必须在controller.quorum.voters中包含
listeners=PLAINTEXT://:9092,CONTROLLER://:9093 前三个机器可以有CONTROLLER后面两个不能有,因为他们是broker节点不参与选举
# 分别在不同的节点修改 node.id的编号
# nn1 --> node.id=0
# nn2 --> node.id=1
# s1 --> node.id=2
# s2 --> node.id=3
# s3 --> node.id=4
# 查看每个机器的编号
ssh_all.sh cat /usr/local/kafka/config/kraft/server.properties | grep node.id
# 创建每个机器上的kafka的数据存储文件夹
ssh_root.sh mkdir /data/kafka-logs
# 修改权限
ssh_root.sh chown hadoop:hadoop -R /data/kafka-logs

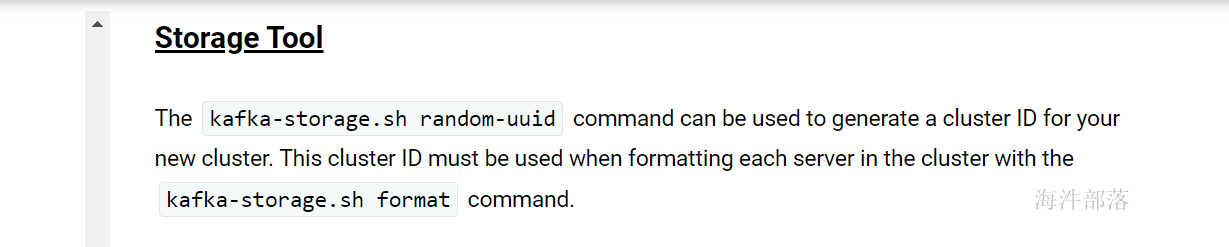
kafka-storage.sh random-uuid 生成集群id

kafka-storage.sh format 格式化存储空间
# -c 指定配置文件 -t指定集群id
kafka-storage.sh format -t bzSjRpblTiOfeQE6KJ2WjQ -c /usr/local/kafka/config/kraft/server.properties 
每个机器都要执行
启动集群
# 五个机器
ssh_all.sh /usr/local/kafka/bin/kafka-server-start.sh -daemon /usr/local/kafka/config/kraft/server.properties
# 测试集群
kafka-topics.sh --bootstrap-server nn1:9092 --create --topic topic_1 --partitions 3 --replication-factor 2
kafka-topics.sh --bootstrap-server nn1:9092 --list
安装kafka监控
# 切换用户解压
su - root
unzip /public/software/bigdata/kafka-console-ui.zip -d /usr/local/
# 启动监控
/usr/local/kafka-console-ui/bin/start.sh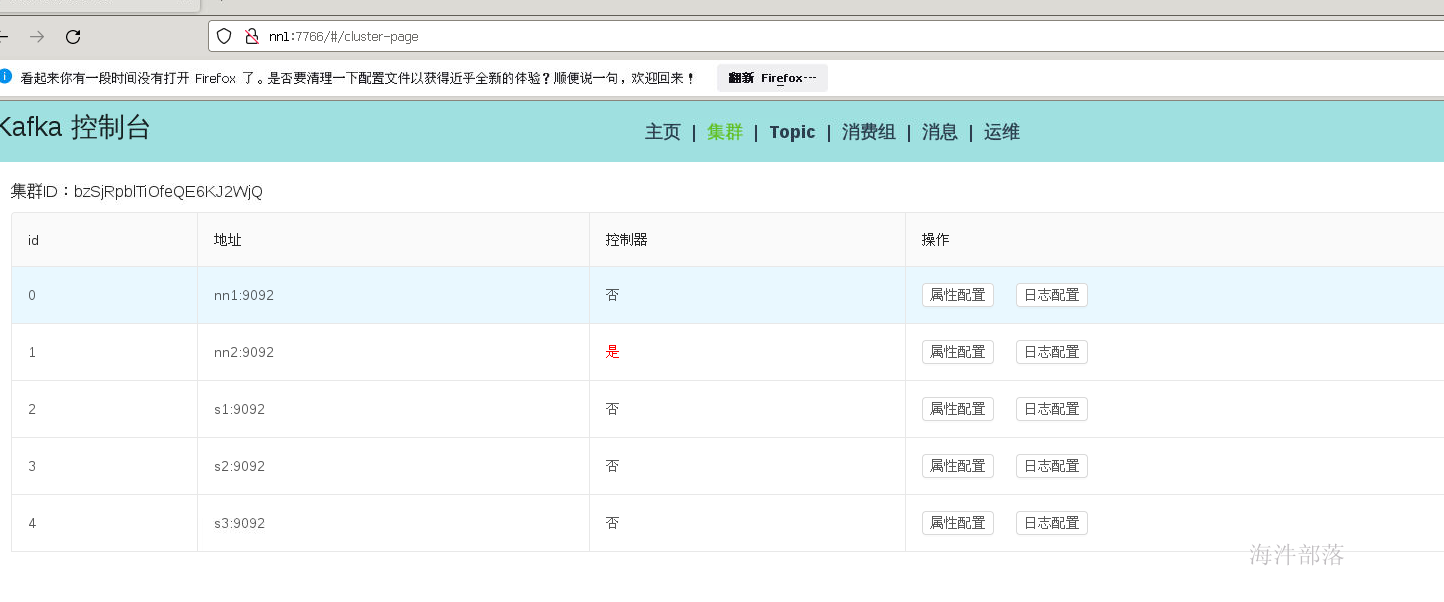
集群运行很正常
6.kafka动态增加节点
在生产环境中数据量存储可能随着公司业务的发展而增加,但是集群的存储性能和处理能力没有办法满足日常的使用需要,这个时候我们需要增加kafka的节点数量,增加机器减少各个节点的压力,这个时候我们需要增加kafka的broker数量,并且实现数据的转移
首先在实验室中选择一个空的linux操作系统
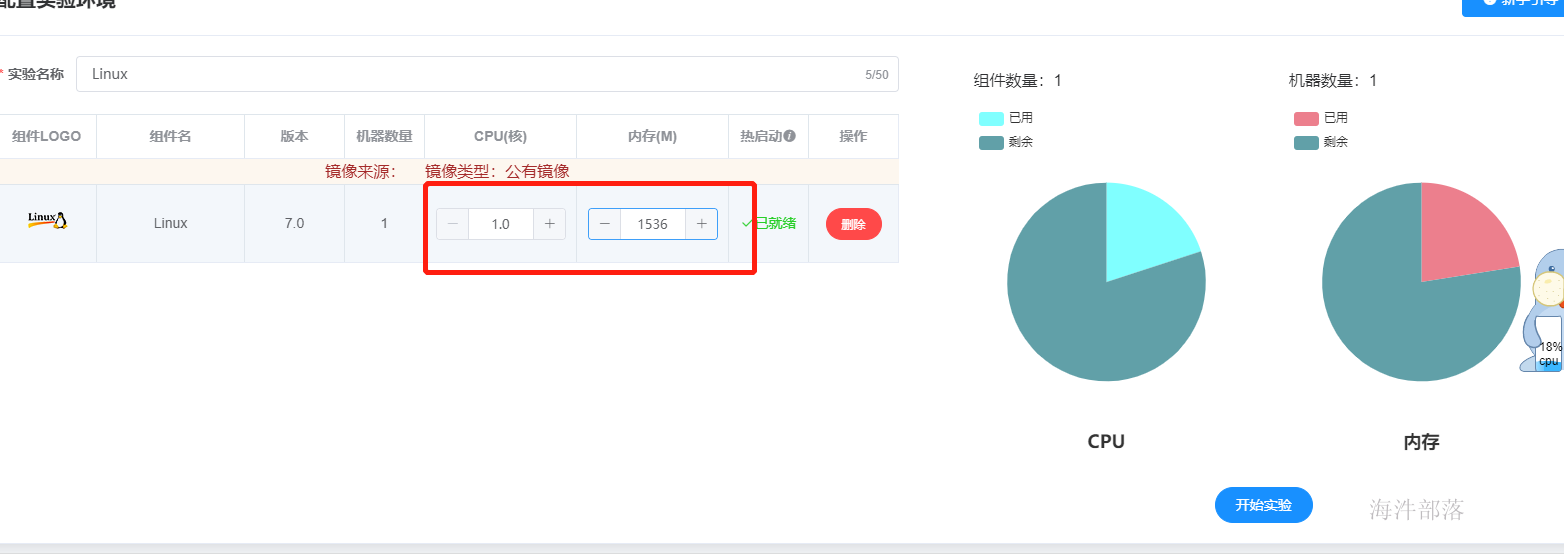
并且提交资源的大小1core 1.5G
然后启动节点后开始配置
-
host映射
-
主机名
-
创建hadoop用户,修改密码
-
和其他机器的免密
-
java环境 安装配置
- kafka环境 安装配置

首先自己的名称映射改为s4
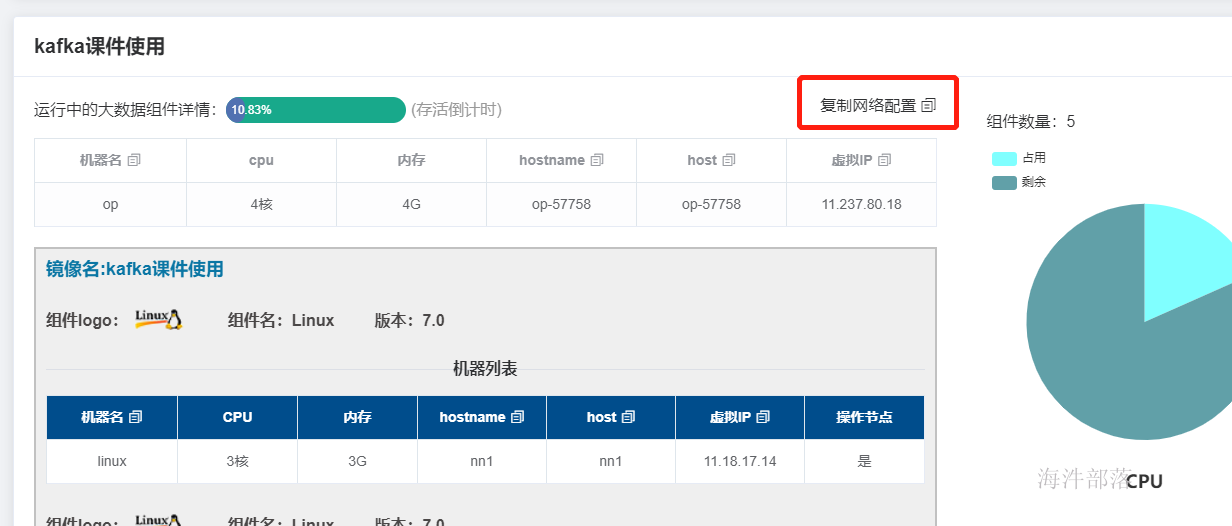
在运行中的实验界面点击复制网络按钮,复制原生kafka集群中的所有机器映射
那么这台机器映射就改完了,但是所有机器都应该识别这个机器,所以这个配置要每个机器都一样
在群体分发命令中执行
cat > /etc/hosts <<EOF
127.0.0.1 localhost
11.147.251.92 s4
11.18.17.14 nn1
11.106.67.9 nn2
11.138.24.88 s1
11.138.24.85 s2
11.87.38.3 s3
EOF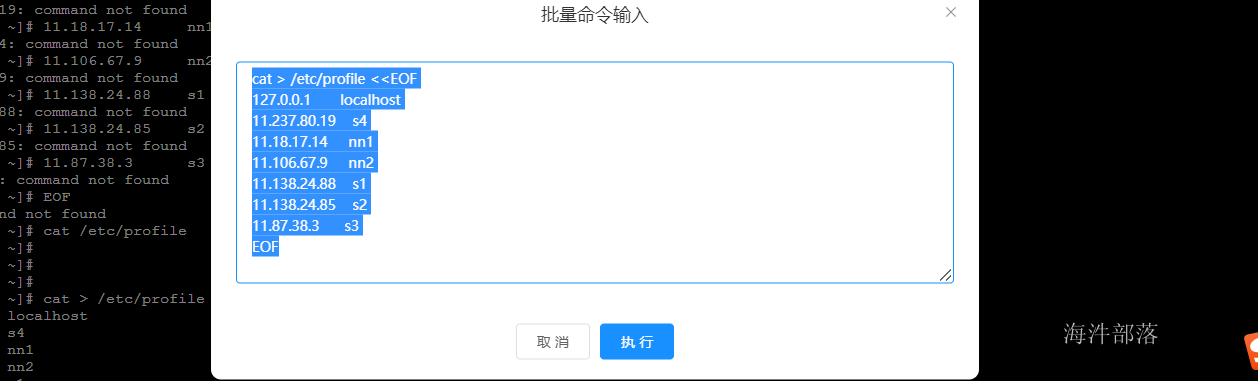
使用输入重定向的方式将配置信息放入到原kafka集群的所有机器节点
# 修改新增节点的主机名为 s4
vim /etc/hostname
# 输入s4
# 创建hadoop用户
useradd hadoop
passwd hadoop
# 密码为123456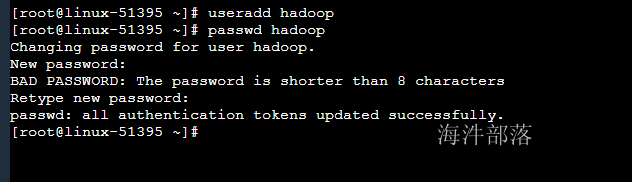
创建完毕用户以后将原kafka集群的nn1节点的hadoop用户的ssh文件夹发送过来,就可以免密相互通信了
# nn1节点执行
scp -r /home/hadoop/.ssh hadoop@s4:/home/hadoop
测试免密登录
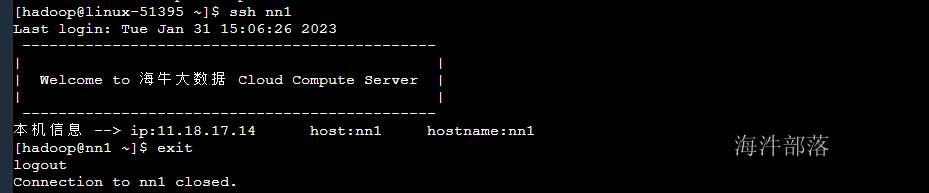
安装java环境
rpm -ivh /public/software/java/jdk-8u144-linux-x64.rpm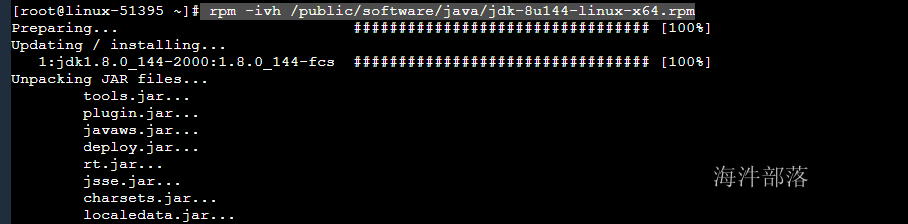
安装kafka
# 解压kafka
tar -zxvf /public/software/bigdata/kafka_2.12-3.3.2.tgz -C /usr/local/
# 创建软连接
ln -s /usr/local/kafka_2.12-3.3.2/ /usr/local/kafka
# 修改权限
chown hadoop:hadoop -R /usr/local/kafka_2.12-3.3.2/
# 创建kafka存储目录
mkdir /data/kafka-logs
# 修改文件夹权限
chown hadoop:hadoop /data/kafka-logs修改环境变量
echo 'export JAVA_HOME=/usr/java/jdk1.8.0_144/' >> /etc/profile
echo 'export PATH=$PATH:$JAVA_HOME/bin' >> /etc/profile
echo 'export KAFKA_HOME=/usr/local/kafka' >> /etc/profile
echo 'export PATH=$PATH:$KAFKA_HOME/bin' >> /etc/profile
source /etc/profile配置kafka的参数
broker.id=5
log.dirs=/data/kafka-logs
zookeeper.connect=nn1:2181启动kafka
su - hadoop
kafka-server-start.sh -daemon /usr/local/kafka/config/server.properties
在监控页面中可以看到多了一台机器
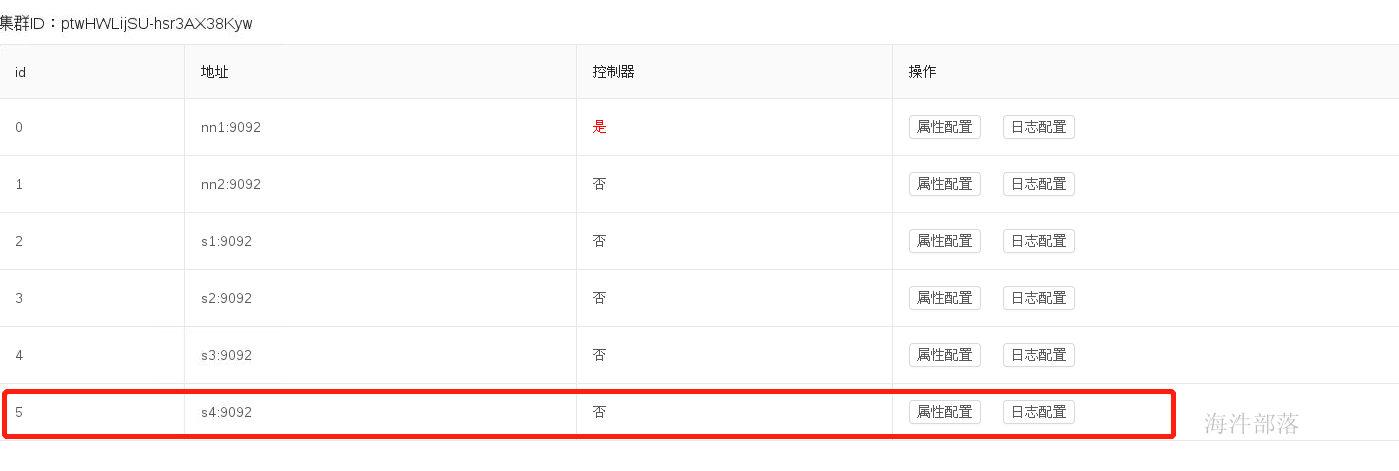
7.节点压力均衡

首先我们查看节点topic的原生分布情况
kafka-topics.sh --bootstrap-server nn1:9092 --list
kafka-topics.sh --bootstrap-server nn1:9092 --describe --topic topic_a这个时候我们需要使用新的机器节点来分摊压力,这个时候要生成分配的计划
使用集群重新分配命令

kafka-reassign-partitions.sh # 重分命令
--bootstrap-server #集群地址
--broker-list # 将要分布在那几个broker上面的列表
--topics-to-move-json-file # 哪个topic需要重新均衡,这个配置需要一个json文件,结构如下图
--generate # 生成计划
# 首先创建一个topic.json 输入如下内容
{"topics":[{"topic":"topic_a"}],"version":1}
# 整体代码命令如下
kafka-reassign-partitions.sh --bootstrap-server nn1:9092 --broker-list 0,1,2,3,4,5 --topics-to-move-json-file topic.json --generate结果如下:
# 当前分配情况
Current partition replica assignment
{"version":1,"partitions":[{"topic":"topic_a","partition":0,"replicas":[4,3,2],"log_dirs":["any","any","any"]},{"topic":"topic_a","partition":1,"replicas":[1,0,2],"log_dirs":["any","any","any"]},{"topic":"topic_a","partition":2,"replicas":[2,4,0],"log_dirs":["any","any","any"]},{"topic":"topic_a","partition":3,"replicas":[2,3,1],"log_dirs":["any","any","any"]}]}
# 目标分配情况
Proposed partition reassignment configuration
{"version":1,"partitions":[{"topic":"topic_a","partition":0,"replicas":[1,2,3],"log_dirs":["any","any","any"]},{"topic":"topic_a","partition":1,"replicas":[2,3,4],"log_dirs":["any","any","any"]},{"topic":"topic_a","partition":2,"replicas":[3,4,5],"log_dirs":["any","any","any"]},{"topic":"topic_a","partition":3,"replicas":[4,5,0],"log_dirs":["any","any","any"]}]}将目标计划放入到一个文件中
# 创建 new.json 输入如下内容
{"version":1,"partitions":[{"topic":"topic_a","partition":0,"replicas":[1,2,3],"log_dirs":["any","any","any"]},{"topic":"topic_a","partition":1,"replicas":[2,3,4],"log_dirs":["any","any","any"]},{"topic":"topic_a","partition":2,"replicas":[3,4,5],"log_dirs":["any","any","any"]},{"topic":"topic_a","partition":3,"replicas":[4,5,0],"log_dirs":["any","any","any"]}]}在命令中增加如下参数,进行重新分配

# 重新分配命令如下
kafka-reassign-partitions.sh --bootstrap-server nn1:9092 --reassignment-json-file new.json --execute
# 验证
kafka-reassign-partitions.sh --bootstrap-server nn1:9092 --reassignment-json-file new.json --verify
# 查看最新topic的分布情况
kafka-topics.sh --bootstrap-server nn1:9092 --topic topic_a --describe
已经重新分布了,这次比较均匀
8.动态删除broker
在生产环境中,有的broker可能性能不足或者损坏等问题,我们需要动态的将这个节点从kafka集群中删除,保证集群正常执行,防止损坏带来问题。
这个过程如上面的增加节点相同,需要将即将删除的broker节点上所管理的topic的分区分摊给其他节点,然后将这个节点删除掉就可以了
在重新的列表中将broker5 删除掉
# 首先创建一个topic.json 输入如下内容
{"topics":[{"topic":"topic_a"}],"version":1}
# 整体代码命令如下
kafka-reassign-partitions.sh --bootstrap-server nn1:9092 --broker-list 0,1,2,3,4 --topics-to-move-json-file topic.json --generate
# 列表中只有0 1 2 3 4产生结果如下:
Current partition replica assignment
{"version":1,"partitions":[{"topic":"topic_a","partition":0,"replicas":[1,2,3],"log_dirs":["any","any","any"]},{"topic":"topic_a","partition":1,"replicas":[2,3,4],"log_dirs":["any","any","any"]},{"topic":"topic_a","partition":2,"replicas":[3,4,5],"log_dirs":["any","any","any"]},{"topic":"topic_a","partition":3,"replicas":[4,5,0],"log_dirs":["any","any","any"]}]}
Proposed partition reassignment configuration
{"version":1,"partitions":[{"topic":"topic_a","partition":0,"replicas":[3,4,0],"log_dirs":["any","any","any"]},{"topic":"topic_a","partition":1,"replicas":[4,0,1],"log_dirs":["any","any","any"]},{"topic":"topic_a","partition":2,"replicas":[0,1,2],"log_dirs":["any","any","any"]},{"topic":"topic_a","partition":3,"replicas":[1,2,3],"log_dirs":["any","any","any"]}]}保留计划
# 创建 new1.json 输入如下内容
{"version":1,"partitions":[{"topic":"topic_a","partition":0,"replicas":[3,4,0],"log_dirs":["any","any","any"]},{"topic":"topic_a","partition":1,"replicas":[4,0,1],"log_dirs":["any","any","any"]},{"topic":"topic_a","partition":2,"replicas":[0,1,2],"log_dirs":["any","any","any"]},{"topic":"topic_a","partition":3,"replicas":[1,2,3],"log_dirs":["any","any","any"]}]}执行计划
# 重新分配命令如下
kafka-reassign-partitions.sh --bootstrap-server nn1:9092 --reassignment-json-file new1.json --execute
验证是否完毕
kafka-reassign-partitions.sh --bootstrap-server nn1:9092 --reassignment-json-file new1.json --verify
关闭broker5
kafka-server-stop.sh 
查看监控页面,broker5已经从列表中删除了