impala介绍
Cloudera Imapala是一款开源的MPP架构的SQL查询引擎,它提供在hadoop环境上的低延迟、高并发的BI/数据分析,是一款开源、与Hadoop高度集成,灵活可扩展的查询分析引擎,目标是基于SQL提供高并发的即席查询。
与其他的查询引擎系统(如presto、spark sql、hive sql)不同,Impala基于C++和Java编写,支持Hadoop生态下的多种组件集成(如HDFS、HBase、Metastore、YARN、Sentry等),支持多种文件格式的读写(如Parqeut、Avro、RCFile等)。
标准的mpp架构,massively-parallel query execution engine,支持在上百台机器的Hadoop集群上执行快速查询,对底层的存储系统解耦,不像数据库要求那么严格,不同的底层存储可以联合查询。
impala在大数据应用处于什么环节及作用
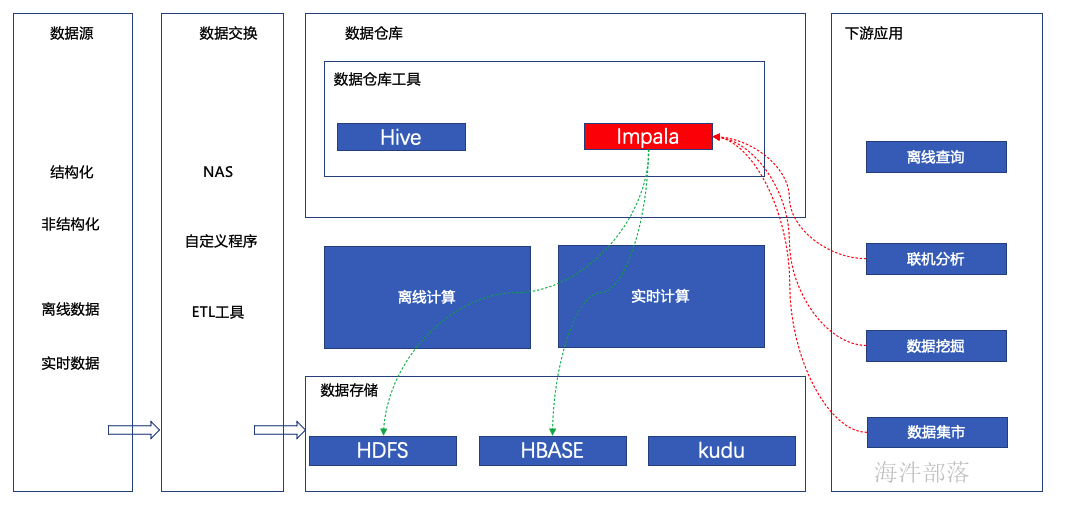
impala在大数据应用领域中处于数据分析环节,利用mpp架构实现高效数据查询,下游应用系统使用impala也比较多,尤其在应用集市查询数据仓库的时候使用的较多。
impala架构体系
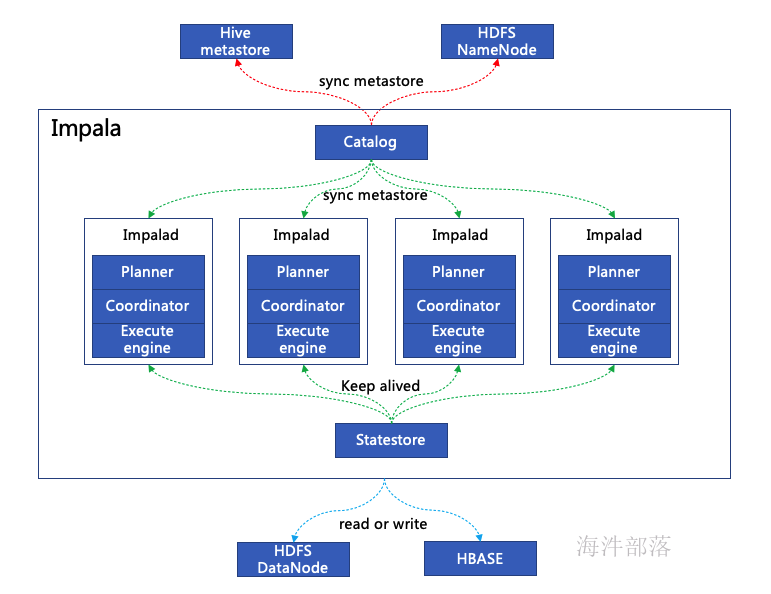
impala由statestore、catalog、impala daemon(impalad)组成。
- statestore是节点状态监控服务,监控impalad状态的服务,如果有impalad故障则发布节点变化消息,底层是一个发布订阅模式的服务。
- catalog负责同步元数据(如hive的metastore),如果元数据发生变化则通过catalog服务通知给所有的impalad节点,impalad节点收到后会刷新已经缓存了的元数据,更新为最新的。
- impalad是impala的核心组件,包含query planner、coordinator、query execute engine三个核心组件,query planner负责解析SQL,生成执行计划树,coordinator负责分发查询计划到各impalad,query execute engine是执行任务实际执行的服务。它负责读写数据文件,接收从impala-shell、Hue、JDBC、ODBC等接口发送的查询语句,并行化查询语句和分发工作任务到Impala集群的各个节点上,同时负责将本地计算好的查询结果发送给协调器节点(coordinator node),客户端可以向运行在任意节点的Impala daemon提交查询,这个节点将会作为这个查询的协调器(coordinator node),其他节点将会传输部分结果集给这个协调器节点,由这个协调器节点构建最终的结果集,在做实验或者测试的时候为了方便,我们往往连接到同一个Impala daemon来执行查询,但是在生产环境运行产品级的应用时,我们应该循环(按顺序)的在不同节点上面提交查询,这样才能使得集群的负载达到均衡,Impala daemon不间断的跟statestore进行通信交流,从而确认哪个节点是健康的能接收新的工作任务。它同时接收catalogd daemon(从Impala 1.2之后支持)传来的广播消息来更新元数据信息,当集群中的任意节点create、alter、drop任意对象、或者执行INSERT、LOAD DATA的时候触发广播消息。
impala任务执行流程
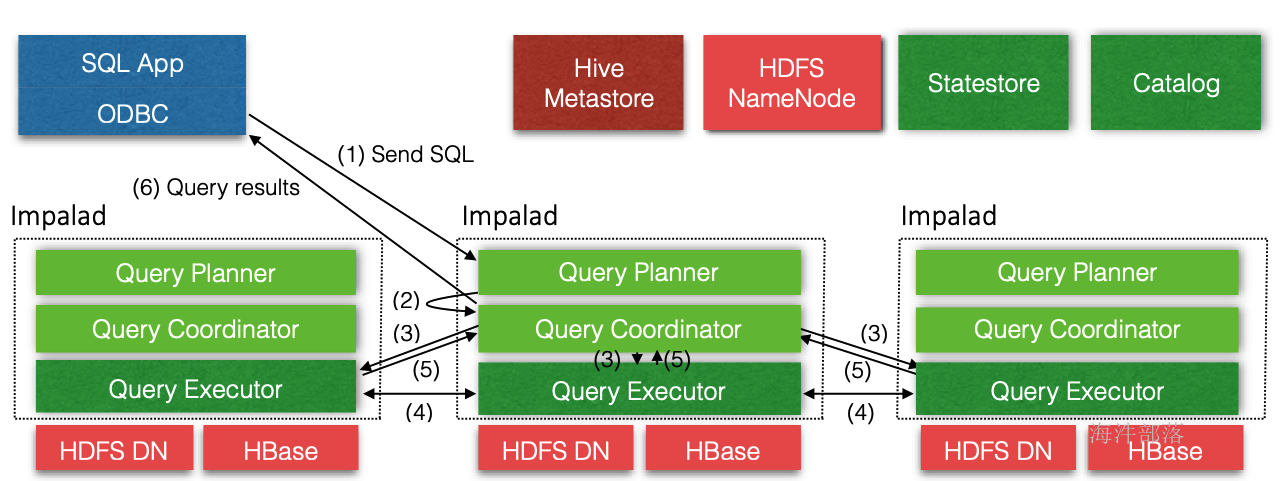
- 通过jdbc等驱动发送查询sql到任意impalad节点。
- imaplad接收到请求,由planner解析用户SQL请求,生成查询计划树,并发给coordinator。
- 接收到任务的impalad节点的coordinator收到查询计划树,分配任务到相应的impalad节点执行。
- impalad接收其他的coordinator发过来的查询请求,执行本地查询。
- impalad执行本地扫描,查询时使用LLVM进行代码生成、编译、执行,然后把结果返回给coordinator(谁发过来的就发回给谁)。
- coordinator(始作俑者)汇总结果,返回给client客户端。
impala支持的文件格式
Impala可以对Hadoop中大多数格式的文件进行查询,通过create table和insert的方式将一部分格式的数据加载到table中,但值得注意的是,有一些格式的数据它是无法写入的(write to),对于Impala无法写入的数据格式,通常是通过Hive建表,使用Hive进行数据的写入,然后使用Impala来对这些保存好的数据执行查询操作。
| 文件类型 | 文件格式 | 压缩编码 | CREATE | INSERT |
|---|---|---|---|---|
| Parquet | 结构化 | SnappyGZIP | Y | Y |
| Text | 非结构化 | LZO | Y。默认采用未压缩的text,字段由ASCII编码的0x01字符串分割。 | Y。如果使用了LZO压缩,则只能通过Hive建表和插入数据。 |
| Avro | 结构化 | SnappyGZIPDeflateBZIP2 | 在Impala 1.4.0 或者更高的版本上支持,之前的版本只能通过Hive来建表 | N。只能通过LOAD DATA的方式将已经转换好格式的数据加载进去,或者使用Hive来插入数据。 |
| RCFile | 结构化 | SnappyGZIPDeflateBZIP2 | Y | N。只能通过LOAD DATA的方式将已经转换好格式的数据加载进去,或者使用Hive来插入数据。 |
| SequenceFile | 结构化 | SnappyGZIPdeflateBZIP2 | Y | N。只能通过LOAD DATA的方式将已经转换好格式的数据加载进去,或者使用Hive来插入数据。 |
所以在impala中最常见的压缩格式就是parquet格式Snappy – 推荐的编码,在压缩率和解压速度之间有很好的平衡性,Snappy压缩速度很快,但是不如GZIP那样能节约更多的存储空间,Impala不支持Snappy压缩的text file。
impala与hive对比
-
执行计划:
Hive:依赖于MapReduce执行框架,执行计划分成 map->shuffle->reduce->map->shuffle->reduce…模型,一个Query会被编译成多轮MapReduce,则会有更多的写中间结果,由于MapReduce执行框架本身的特点,过多的中间过程会增加整个Query的执行时间。
Impala:把执行计划表现为一棵完整的执行计划树,分发执行计划到各个Impalad执行查询,不像Hive那样把它组合成管道型的map->reduce模式,以此保证Impala有更好的并发性和避免不必要的中间sort与shuffle。
-
数据流:
Hive:采用推的方式,每一个计算节点计算完成后将数据主动推给后续节点。
Impala:采用拉的方式,后续节点通过getNext主动向前面节点要数据,以此方式数据可以流式的返回给客户端,且只要有1条数据被处理完,就可以立即展现出来,而不用等到全部处理完成,更符合SQL交互式查询使用。
-
内存使用:
Hive:在执行过程中如果内存放不下所有数据,则会使用外存,以保证Query能顺序执行完。每一轮MapReduce结束,中间结果也会写入HDFS中,同样由于MapReduce执行架构的特性,shuffle过程也会有写本地磁盘的操作。
Impala:在遇到内存放不下数据时,如果开启了溢写磁盘开关会将数据溢写到磁盘,否则oom。
-
适用场景:
Hive:适合大批量跑批任务。
Impala:适合交互式查询需求。
impala数据类型
| Hive数据类型 | Impala数据类型 | 长度 |
|---|---|---|
| TINYINT | TINYINT | 1byte有符号整数 |
| SMALINT | SMALINT | 2byte有符号整数 |
| INT | INT | 4byte有符号整数 |
| BIGINT | BIGINT | 8byte有符号整数 |
| BOOLEAN | BOOLEAN | 布尔类型,true或者false |
| FLOAT | FLOAT | 单精度浮点数 |
| DOUBLE | DOUBLE | 双精度浮点数 |
| STRING | STRING | 字符系列,可以使用单引号或者双引号 |
| TIMESTAMP | TIMESTAMP | 时间类型 |
| BINARY | 不支持 | 字节数组 |


