连接gaussdb
-
切换用户
su - omm -
加载环境变量
source ${BIGDATA_HOME}/mppdb/.mppdbgs_profile -
连接数据库
gsql -d postgres -p 25308 -
创建用户
create user xiniu with password "xiniu_1688"; -
创建数据库
官方建议:用户自定义数据库数量不超过3个
create database xiniu_db; -
退出gsql
\q -
指定用户登陆,正常情况下不使用omm用户登陆
gsql -d xiniu_db -p 25308 -U xiniu -W "xiniu_1688"
查询集群各节点状态
gs_om -t status --detail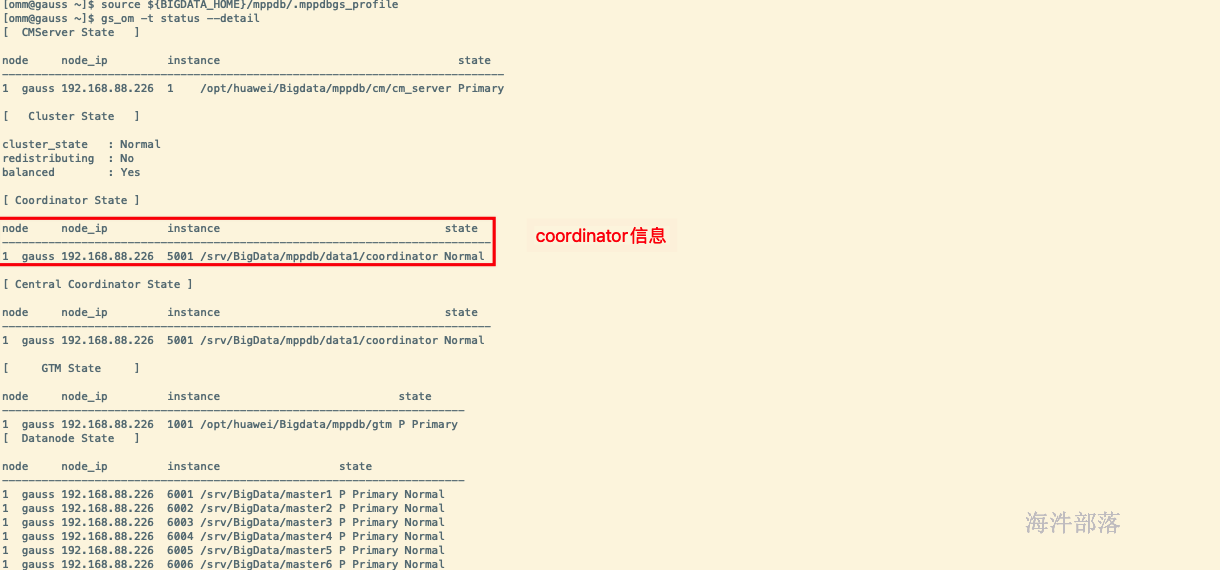
cat /srv/BigData/mppdb/data1/coordinator/postgresql.conf | grep port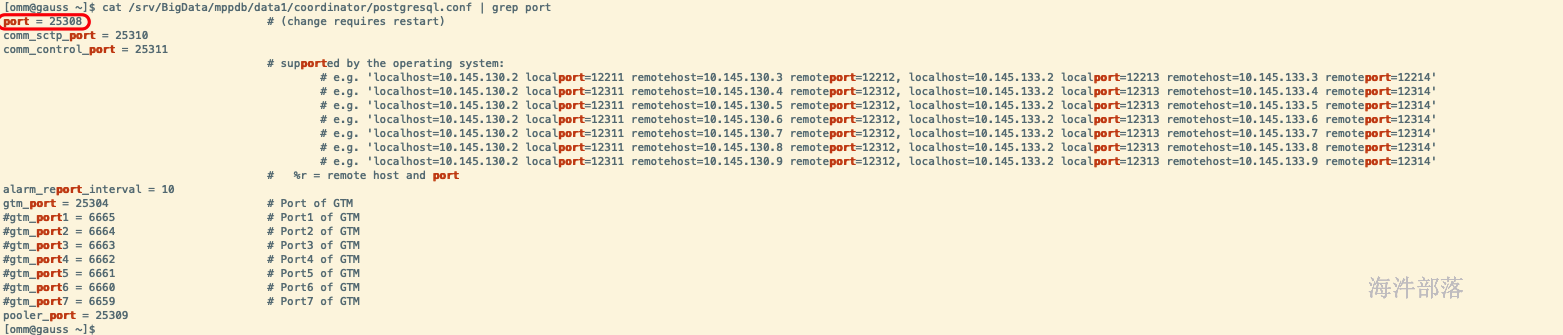
表空间
-
创建表空间
# 使用管理员用户进入gsql su - omm gsql -d postgres -p 25308 # 创建命名空间 create tablespace xiniu relative location 'hdfs_tablespace/hdfs_tablespace_1'; create tablespace xiniu2 relative location 'hdfs_tablespace/hotdata'; -
创建表并指定表空间
create database xiniu_db2 with tablespace = xiniu;

基本操作
-
创建行表
建表的时候如果不指定orientation则默认为行表
set default_tablespace = 'xiniu'; create table test1( id integer ) distribute by hash (id); # 因为用户xiniu没有操作xiniu表空间的权限,所以建表会失败 -
表空间权限管理
grant create on tablespace xiniu to xiniu;

-
再次建表
set default_tablespace = 'xiniu'; create table test1( id integer ) distribute by hash (id);

-
创建列表
-- compression是压缩等级(high、middle、low) -- orientation是指定列存参数 set default_tablespace = 'xiniu'; create table test2( id integer, name char(15), age integer ) with (orientation = column ,compression = middle) distribute by hash (id); set default_tablespace = 'xiniu'; create table test4( id integer, name char(15), age integer ) with (orientation = column ,compression = low) distribute by hash (id);

-
插入数据
-- 创建表 CREATE TABLE customer_t1 ( c_customer_sk integer, c_customer_id char(5), c_first_name char(6), c_last_name char(8) ) with (orientation = column,compression=middle) distribute by hash (c_last_name); -- 单行插入数据 INSERT INTO customer_t1 VALUES (3769, 'hello', 'Grace'); -- 多行插入数据 INSERT INTO customer_t1 (c_customer_sk, c_customer_id, c_first_name) VALUES (6885, 'maps', 'Joes'), (4321, 'tpcds', 'Lily'), (9527, 'world', 'James'); -- 从select结果集插入数据 CREATE TABLE customer_t2 ( c_customer_sk integer, c_customer_id char(5), c_first_name char(6), c_last_name char(8) ) ; -- 建表的时候不指定分布键,则由系统选择一个可以作为分布键的字段作为分布键 -- NOTICE: The 'DISTRIBUTE BY' clause is not specified. Using 'c_customer_sk' as the distribution column by default. -- HINT: Please use 'DISTRIBUTE BY' clause to specify suitable data distribution column. INSERT INTO customer_t2 SELECT * FROM customer_t1; -
更新数据
-- 更新一个字段 UPDATE customer_t1 SET c_customer_sk = 9876 WHERE c_customer_sk = 9527; -- 使用表达式更新 UPDATE customer_t1 SET c_customer_sk = c_customer_sk + 100 where c_customer_sk = 9876; -- 更新多个字段 UPDATE customer_t1 SET c_customer_id = 'Admin', c_first_name = 'Local' WHERE c_customer_sk = 6885; -
查表
-- 查看表属性 \d+ customer_t1;

-
查数
-- 与hive一致 select * from customer_t1; select count(1) from customer_t1; select distinct (c_customer_sk) from customer_t1;

-
删除数据
-- 删除指定行 DELETE FROM customer_t1 WHERE c_customer_sk = 3769; -- 删除所有行 DELETE FROM customer_t1; -- 清空表 TRUNCATE TABLE customer_t1; -- 删除表 DROP TABLE customer_t1; -
查看数据库用户
SELECT * FROM pg_user;

gaussdb200常用操作
-
schema
schema命名不能以pg_开头,那是系统预留的。
-- 创建schema CREATE SCHEMA myschema; -- 创建schema并且同时指定给某用户 CREATE SCHEMA myschema AUTHORIZATION xiniu; -- 使用omm管理员创建一个测试user xiniu2 create user xiniu2 with password "Yghn_1688"; -- 管理schema权限 GRANT USAGE ON schema myschema TO xiniu2; GRANT CREATE ON schema myschema TO xiniu2; GRANT ALL ON schema myschema TO xiniu2; -- 指定schema建表 使用xiniu建表 -- 设置searchpath set search_path to myschema; CREATE TABLE myschema.mytable(id int, name varchar(20));-- 找个表是使用xiniu用户创建的,其他用户不能访问 -- 使用xiniu2登陆xiniu_db gsql -d xiniu_db -p 25308 -U xiniu2 -W Yghn_1688 -- 查看schema \dn -- 在myschema下创建表(xiniu2用户) create table myschema.xiniu2table(id integer);-- 此时只有xiniu2用户有myschema.xiniu2table的权限 -- 对表进行权限管理,使不同用户在同一个schema中拥有各自的权限 grant select on myschema.mytable to xiniu2; grant select on myschema.xiniu2table to xiniu; -- 同一个数据库中可以存在不同的schema,不同的schema中的表名可以重复 -- 使用xiniu2用户再创建一个schema -- 如果xiniu2没有创建schema的权限,则需要使用管理员用户给xiniu2赋予数据库操作权限 -- grant all on database xiniu_db to xiniu2; create schema xiniu2schema; create table xiniu2schema.mytable (id integer); -- 如上可以发现在同一个数据库(xiniu_db)中出现了同名的表(mytable),这就是schema较为实用的地方,并且可以对schema进行赋权管理。


-
分区
- 语法格式
CREATE TABLE [ IF NOT EXISTS ] partition_table_name ( [ { column_name data_type [ COLLATE collation ] [ column_constraint [ ... ] ] | table_constraint | LIKE source_table [ like_option [...] ] }[, ... ] ] ) [ WITH ( {storage_parameter = value} [, ... ] ) ] [ COMPRESS | NOCOMPRESS ] [ TABLESPACE tablespace_name ] [ DISTRIBUTE BY { REPLICATION | { [ HASH ] ( column_name ) } } ] [ TO { GROUP groupname | NODE ( nodename [, ... ] ) } ] PARTITION BY { {VALUES (partition_key)} | {RANGE (partition_key) ( partition_less_than_item [, ... ] )} | {RANGE (partition_key) ( partition_start_end_item [, ... ] )} } [ { ENABLE | DISABLE } ROW MOVEMENT ];- 创建分区表(gaussdb200只支持范围分区)
-- 创建分区表 CREATE TABLE myschema.customer_address ( ca_address_sk integer NOT NULL , ca_address_id integer NOT NULL , ca_street_number character(10) , ca_street_name character varying(60) , ca_street_type character(15) , ca_suite_number character(10) , ca_city character varying(60) , ca_county character varying(30) , ca_state character(2) , ca_zip character(10) , ca_country character varying(20) , ca_gmt_offset numeric(5,2) , ca_location_type character(20) ) TABLESPACE xiniu DISTRIBUTE BY HASH (ca_address_sk) PARTITION BY RANGE (ca_address_id) ( PARTITION P1 VALUES LESS THAN(5000), PARTITION P2 VALUES LESS THAN(10000), PARTITION P3 VALUES LESS THAN(15000), PARTITION P4 VALUES LESS THAN(20000), PARTITION P5 VALUES LESS THAN(25000), PARTITION P6 VALUES LESS THAN(30000), PARTITION P7 VALUES LESS THAN(40000), PARTITION P8 VALUES LESS THAN(MAXVALUE) ) ENABLE ROW MOVEMENT;

-
修改分区
-- 删除分区 ALTER TABLE myschema.customer_address DROP PARTITION P8; -- 增加分区 ALTER TABLE myschema.customer_address ADD PARTITION P8 VALUES LESS THAN (MAXVALUE); -- 插入数据 insert into myschema.customer_address (ca_address_sk,ca_address_id) values (1,4999); -- 修改ca_address_sk值 update myschema.customer_address set ca_address_id = 5000 where ca_address_sk = 1; -- 修改行迁移开关 ALTER TABLE myschema.customer_address DISABLE ROW MOVEMENT; -- 关闭行迁移开关后再进行修改 update myschema.customer_address set ca_address_id = 4999 where ca_address_sk = 1; -- 修改分区名 ALTER TABLE myschema.customer_address RENAME PARTITION P8 TO P_9; -- 表空间权限管理(管理员用户) grant all on tablespace xiniu2 to xiniu; -- 修改指定分区的表空间 ALTER TABLE myschema.customer_address MOVE PARTITION P6 TABLESPACE xiniu2;

这里的分区键采用的是ca_address_id,非分布键,那么这个分区键的值就存在被修改的可能性,一旦分区键的值发生了变化,可能就会影响到数据的分布,如果movement开关关闭会导致修改失败,如果movement开关打开,则可以正常修改,并且会将数据迁移到对应的分区上。
重点强调一下指定分区的表空间的意义……,非常重要,相信在未来一定会非常实用。
重点强调一下指定分区的表空间的意义……,非常重要,相信在未来一定会非常实用。
重点强调一下指定分区的表空间的意义……,非常重要,相信在未来一定会非常实用。
-
查询分区数据
-- 查询分区 SELECT * FROM myschema.customer_address PARTITION (P2); SELECT * FROM myschema.customer_address PARTITION FOR (5000);
-
索引
索引可以提高数据的访问速度,但同时也增加了插入、更新和删除操作的处理时间,所以是否要为表增加索引,索引建立在哪些字段上,是创建索引前必须要考虑的问题。需要分析应用程序的业务处理、数据使用、经常被用作查询的条件或者被要求排序的字段来确定是否建立索引。
索引建立在数据库表中的某些列上,所以在创建索引时,应该仔细考虑在哪些列上创建索引?
- 在经常需要搜索查询的列上创建索引,可以加快搜索的速度。
- 在作为主键的列上创建索引,强制该列的唯一性和组织表中数据的排列结构。
- 在经常使用连接的列上创建索引,这些列主要是一些外键,可以加快连接的速度。
- 在经常需要根据范围进行搜索的列上创建索引,因为索引已经排序,其指定的范围是连续的。
- 在经常需要排序的列上创建索引,因为索引已经排序,这样查询可以利用索引的排序,加快排序查询时间。
- 在经常使用WHERE子句的列上创建索引,加快条件的判断速度。
- 为经常出现在关键字ORDER BY、GROUP BY、DISTINCT后面的字段建立索引。
-- 创建表 CREATE TABLE myschema.web_returns_p2 ( ca_address_sk integer NOT NULL , ca_address_id integer NOT NULL , ca_street_number character(10) , ca_street_name character varying(60) , ca_street_type character(15) , ca_suite_number character(10) , ca_city character varying(60) , ca_county character varying(30) , ca_state character(2) , ca_zip character(10) , ca_country character varying(20) , ca_gmt_offset numeric(5,2) , ca_location_type character(20) ) TABLESPACE xiniu DISTRIBUTE BY HASH (ca_address_sk) PARTITION BY RANGE (ca_address_sk) ( PARTITION P1 VALUES LESS THAN(5000), PARTITION P2 VALUES LESS THAN(10000), PARTITION P3 VALUES LESS THAN(15000), PARTITION P4 VALUES LESS THAN(20000), PARTITION P5 VALUES LESS THAN(25000), PARTITION P6 VALUES LESS THAN(30000), PARTITION P7 VALUES LESS THAN(40000), PARTITION P8 VALUES LESS THAN(MAXVALUE) TABLESPACE xiniu2 ) ENABLE ROW MOVEMENT; -- 倒数 INSERT INTO myschema.web_returns_p2 SELECT * FROM myschema.customer_address; -- 创建索引,注意分区表是不支持全局索引的,索引我们用的是local本地索引。 CREATE INDEX myschema_web_returns_p2_index1 ON myschema.web_returns_p2 (ca_address_id) local; -- 查询所有索引 SELECT RELNAME FROM PG_CLASS WHERE RELKIND='i'; -- 查看指定索引 \di+ myschema.myschema_web_returns_p2_index1;gaussdb200支持如下四种索引:
索引方式 描述 唯一索引 可用于约束索引属性值的唯一性,或者属性组合值的唯一性。如果一个表声明了唯一约束或者主键,则GaussDB 200自动在组成主键或唯一约束的字段上创建唯一索引(可能是多字段索引),以实现这些约束。目前,GaussDB 200只有B-Tree可以创建唯一索引。 多字段索引 一个索引可以定义在表中的多个属性上。目前,GaussDB 200中的B-Tree支持多字段索引,且最多可在32个字段上创建索引。 部分索引 建立在一个表的子集上的索引,这种索引方式只包含满足条件表达式的元组。 表达式索引 索引建立在一个函数或者从表中一个或多个属性计算出来的表达式上。表达式索引只有在查询时使用与创建时相同的表达式才会起作用。 -- 创建一张普通表 CREATE TABLE myschema.customer_address_bak AS TABLE myschema.customer_address;创建唯一索引
-- 使用场景,经常查询的字段上设置,且全局唯一,在查询与修改上效率都有明显提升效果 CREATE INDEX index_ca_address_sk ON myschema.customer_address_bak (ca_address_sk);创建多字段索引
-- 经常查询的多个字段 CREATE INDEX more_column_index ON myschema.customer_address_bak(ca_address_sk ,ca_street_number );创建部分索引
-- 在指定范围内建立索引,一般应用在冷热数据上,如果全表做索引太影响写入效率,且其他数据查询频率又不高,此时可以选择热数据的范围做索引 CREATE INDEX part_index ON myschema.customer_address_bak(ca_address_sk) WHERE ca_address_sk > 5050;创建表达式索引
-- 通过表达式对某一列进行预处理,再形成索引,想想他写入速度就快不到哪去,但是如果经常在查询中经常使用到trunc某一个字段,那创建这类索引还是值得的。 CREATE INDEX para_index ON myschema.customer_address_bak (trunc(ca_street_number)); -
视图
视图与hive没区别
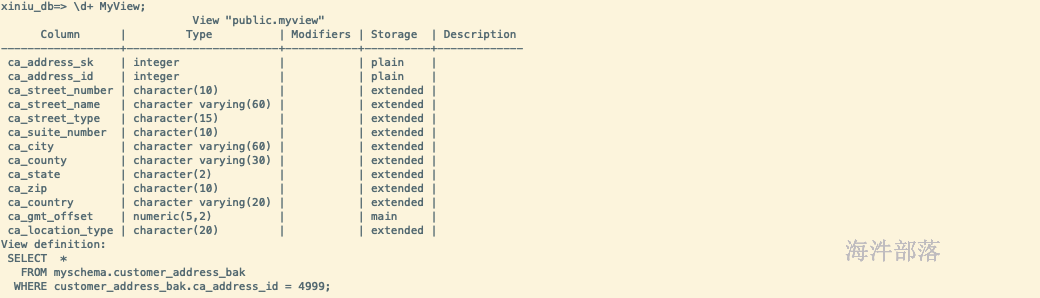
-- 创建索引 CREATE OR REPLACE VIEW MyView AS SELECT * FROM myschema.customer_address_bak WHERE ca_address_id = 4999; -- 查看索引 \d+ MyView;
-
事务
BEGIN; SELECT * FROM myschema.customer_address; UPDATE myschema.customer_address SET ca_address_id = 5001 WHERE ca_address_sk = 1; SELECT * FROM myschema.customer_address; END;
excute&prepare
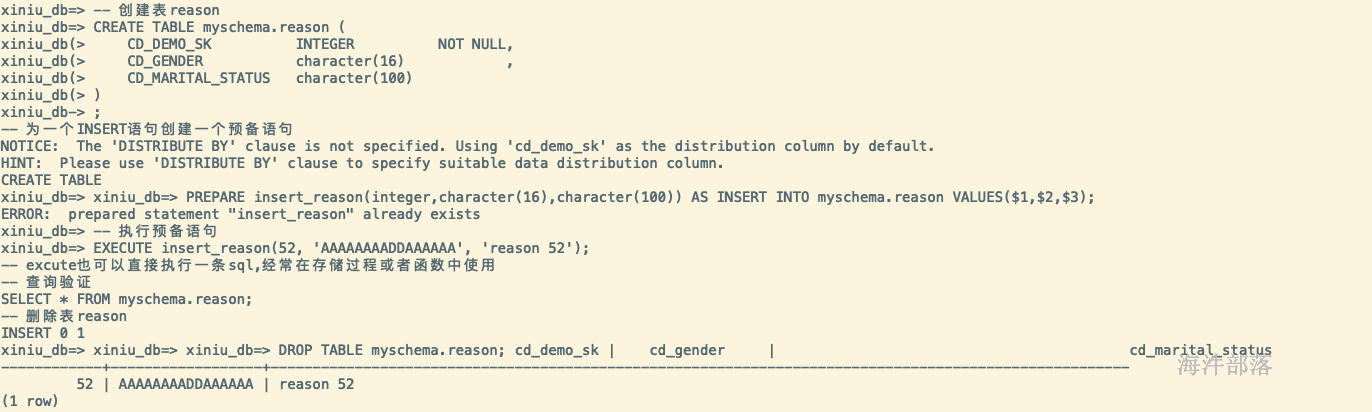
-- 创建表reason
CREATE TABLE myschema.reason (
CD_DEMO_SK INTEGER NOT NULL,
CD_GENDER character(16) ,
CD_MARITAL_STATUS character(100)
)
;
-- 为一个INSERT语句创建一个预备语句
PREPARE insert_reason(integer,character(16),character(100)) AS INSERT INTO myschema.reason VALUES($1,$2,$3);
-- 执行预备语句
EXECUTE insert_reason(52, 'AAAAAAAADDAAAAAA', 'reason 52');
-- excute也可以直接执行一条sql,经常在存储过程或者函数中使用
-- 查询验证
SELECT * FROM myschema.reason;
-- 删除表reason
DROP TABLE myschema.reason;