数据导入方式概述
GaussDB 200提供了灵活的数据入库方式:GDS、INSERT、COPY以及gsql元命令\copy。各方式具有不同的特点:GDS因其并行的特点,导入效率高,适用于大批量数据的入库;其他三种方式适用于小批量数据入库,可以考虑其特点自行选择。
| 方式 | 特点 |
|---|---|
| GDS | 通过GDS工具,采用多DN并行导入,导入效率高。适用于大批量数据入库。 |
| INSERT | 通过INSERT语句插入一行或多行数据,及从指定表插入数据。 |
| COPY | 通过COPY FROM STDIN语句直接向GaussDB 200写入数据。通过JDBC驱动的CopyManager接口从其他数据库向GaussDB 200写入数据时,具有业务数据无需落地成文件的优势。 |
GDS数据导入
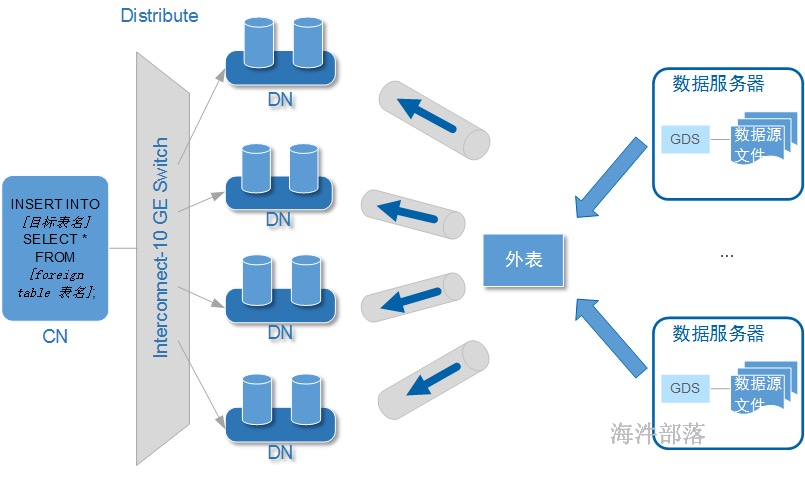
准备数据
准备数据文件
mkdir -p /input_data
cd /input_data
vim product_info0.csv写入如下数据
100,XHDK-A,2017-09-01,A,2017 Shirt Women,red,M,328,2017-09-04,715,good!
205,KDKE-B,2017-09-01,A,2017 T-shirt Women,pink,L,584,2017-09-05,40,very good!
300,JODL-X,2017-09-01,A,2017 T-shirt men,red,XL,15,2017-09-03,502,Bad.
310,QQPX-R,2017-09-02,B,2017 jacket women,red,L,411,2017-09-05,436,It's nice.
150,ABEF-C,2017-09-03,B,2017 Jeans Women,blue,M,123,2017-09-06,120,good.准备GDS安装包
GaussDB-Kernel-V300R002C00-REDHAT-64bit-Gds.tar.gz
在服务端安装包中 find / -name GaussDB-Kernel-V300R002C00-REDHAT-64bit-Gds.tar.gz
mkdir -p /opt/bin解压安装包
cd /opt/bin
tar -zxvf /opt/GaussDB-Kernel-V300R002C00-SUSE11-64bit-Gds.tar.gz添加环境变量
export LD_LIBRARY_PATH="/opt/bin/lib:$LD_LIBRARY_PATH"
source /etc/profile创建gds用户
创建组与用户
groupadd gdsgrp
useradd -g gdsgrp gds_user修改属主
chown -R gds_user:gdsgrp /opt/bin/
chown -R gds_user:gdsgrp /input_data启动GDS
su - gds_user启动gds服务
/opt/bin/gds/gds -d /input_data/ -p 192.168.88.226:5000 -H 192.168.88.226/24 -l /opt/bin/gds/gds_log.txt -D-d 保存有待导入数据的数据文件所在目录。
-p ip:port:GDS监听IP和监听端口,默认值为:127.0.0.1,需要替换为能跟GaussDB 200通信的万兆网IP,监听端口的取值范围:1024~65535。默认值为:8098,这个IP与端口对应高斯创建的外表的gsfs地址。
-H address_string:允许哪些主机连接和使用GDS服务,此参数配置的目的是允许GaussDB 200集群可以访问GDS服务进行数据导入。所以请保证所配置的网段包含GaussDB 200集群各主机。
-l log_file:存放GDS的日志文件路径及文件名。
-D:后台运行GDS,仅支持Linux操作系统下使用。
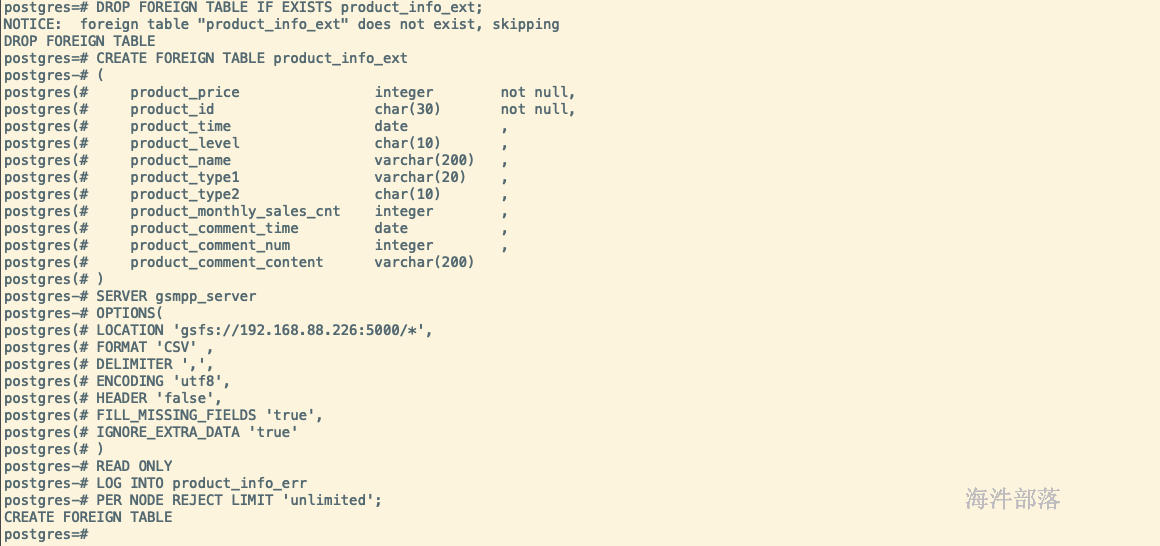
创建高斯外表
创建外表,并指定location地址,对应gds服务启动时配置的-p参数
DROP FOREIGN TABLE IF EXISTS product_info_ext;
CREATE FOREIGN TABLE product_info_ext
(
product_price integer not null,
product_id char(30) not null,
product_time date ,
product_level char(10) ,
product_name varchar(200) ,
product_type1 varchar(20) ,
product_type2 char(10) ,
product_monthly_sales_cnt integer ,
product_comment_time date ,
product_comment_num integer ,
product_comment_content varchar(200)
)
SERVER gsmpp_server
OPTIONS(
LOCATION 'gsfs://192.168.88.226:5000/*',
FORMAT 'CSV' ,
DELIMITER ',',
ENCODING 'utf8',
HEADER 'false',
FILL_MISSING_FIELDS 'true',
IGNORE_EXTRA_DATA 'true'
)
READ ONLY
LOG INTO product_info_err
PER NODE REJECT LIMIT 'unlimited';HEADER参数为是否包含表头
FILL_MISSING_FIELDS参数意义,当数据导入时,数据源文件中一行的最后一个字段缺失的处理方式。默认为false/off,如果设置成TRUE,表示最后一个字段缺失时,把最后一个字段的值设置为NULL,不报错,如果设置为FALSE,表示最后一个字段缺失时,做如下报错提示:missing data for column "tt"。
IGNORE_EXTRA_DATA参数意义,数据源文件中的字段比外表定义列数多时,是否忽略多出的列,默认为false/off,如果设置为TRUE,表示数据源文件中字段比外表定义列数多,则忽略行尾多出来的列,且不报错,如果设置为FALSE,表示若数据源文件中字段比外表定义列数多,做如下报错提示:extra data after last expected column。
PER NODE REJECT LIMIT 'unlimited'参数意义,指定本次数据导入过程中每个DN实例上允许出现的数据格式错误的数量,如果有一个DN实例上的错误数量大于设定值,本次导入失败,报错退出,如果设置为unlimited不限制,则代表导入过程中接手所有错误格式不报错。
LOG INTO product_info_err参数意义,表示导入结果插入到表product_info_err中,可以使用select * from product_info_err进行查询。
READ ONLY参数意义,外表的语法定义通用于导入数据到GaussDB 200集群和从集群导出数据。数据导入集群时,请将外表设为READ ONLY;导出时,请设为WRITE ONLY。
创建高斯表
创建真正存储数据的表
DROP TABLE IF EXISTS product_info;
CREATE TABLE product_info
(
product_price integer not null,
product_id char(30) not null,
product_time date ,
product_level char(10) ,
product_name varchar(200) ,
product_type1 varchar(20) ,
product_type2 char(10) ,
product_monthly_sales_cnt integer ,
product_comment_time date ,
product_comment_num integer ,
product_comment_content varchar(200)
)
WITH (
orientation = column,
compression=middle
)
DISTRIBUTE BY hash (product_id);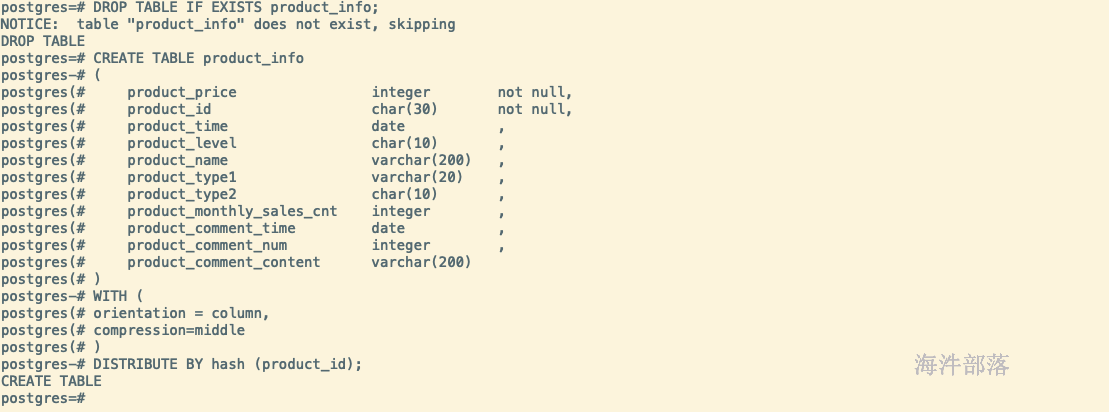
将外表数据导入到正式表
-- INSERT导入方式
INSERT INTO product_info SELECT * FROM product_info_ext ;如果需要创建索引,或者正式表已经创建好索引了,为了保证数据导入效率,在数据导入前先删除索引,在数据导入完成之后再创建索引,如:DROP INDEX product_idx;CREATE INDEX product_idx ON product_info(product_id);

验证结果
SELECT * FROM product_info_ext;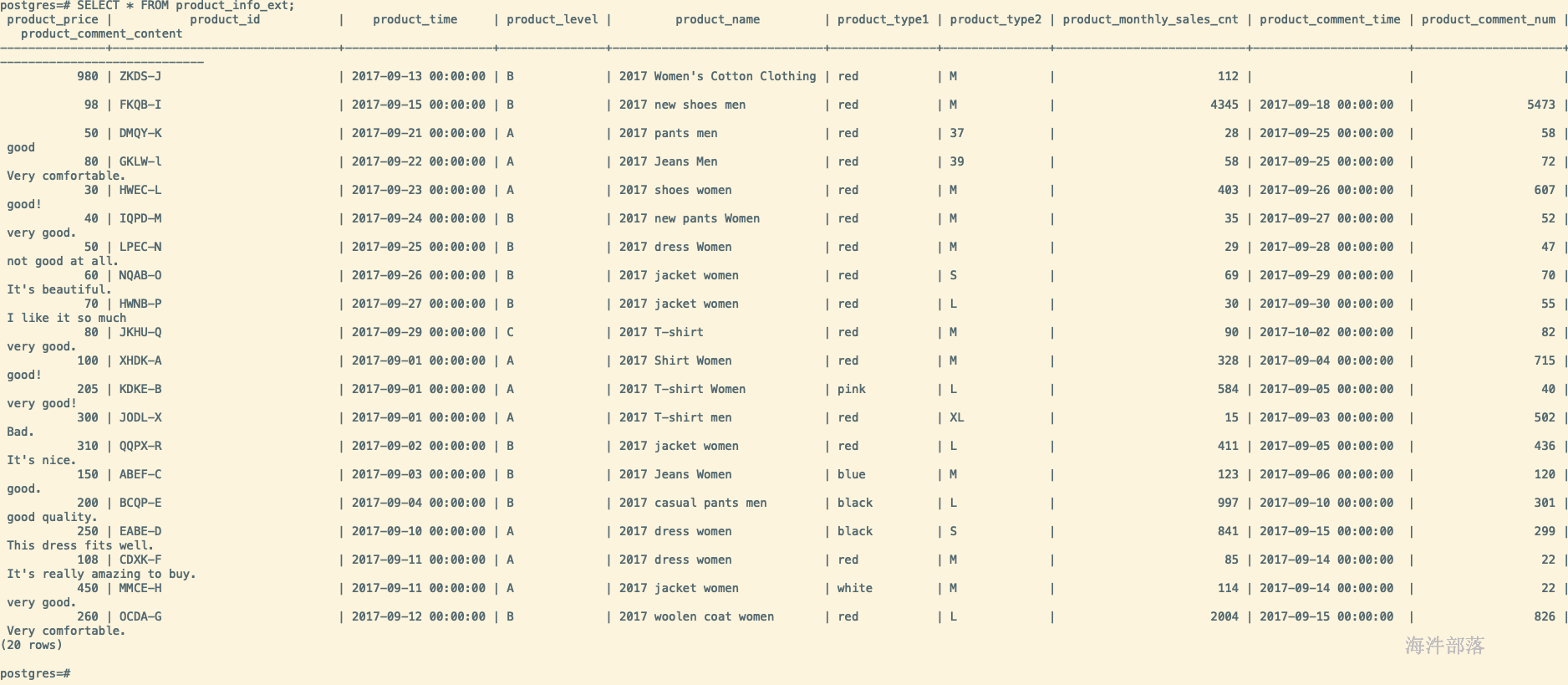
copy table from/to
Copy table to 'localpath'
-- 将product_info中的数据拷贝到/home/omm/product_info.dat
COPY product_info TO '/home/omm/product_info.dat';
Copy table to stdout
-- 将product_info 输出到stdout。
COPY product_info TO stdout;
copy table from stdin
-- 创建product_info_t1表。
DROP TABLE IF EXISTS product_info_t1;
CREATE TABLE product_info_t1
(
product_price integer not null,
product_id char(30) not null,
product_time date ,
product_level char(10) ,
product_name varchar(200) ,
product_type1 varchar(20) ,
product_type2 char(10) ,
product_monthly_sales_cnt integer ,
product_comment_time date ,
product_comment_num integer ,
product_comment_content varchar(200)
)
WITH (
orientation = column,
compression=middle
)
DISTRIBUTE BY hash (product_id);
-- 从stdin拷贝数据到表product_info_t1,字段间使用\t分割(tab键),使用\.结束(换行)。
COPY product_info_t1 FROM stdin;
copy table from 'localpath'
-- 从/home/omm/product_info.dat文件拷贝数据到表product_info_t1。
COPY product_info_t1 FROM '/home/omm/product_info.dat';
-- 从/home/omm/product_info.dat文件拷贝数据到表product_info_t1,使用参数如下:导入格式为TEXT(format 'text'),分隔符为'\t'(delimiter E'\t'),忽略多余列(ignore_extra_data 'true'),不指定转义(noescaping 'true')。
COPY product_info_t1 FROM '/home/omm/product_info.dat' WITH(format 'text', delimiter E'\t', ignore_extra_data 'true', noescaping 'true');
磁盘碎片清理
-- 如果导入过程中,进行了大量的更新或删除行时,应运行VACUUM FULL命令,然后运行ANALYZE命令。大量的更新和删除操作,会产生大量的磁盘页面碎片,从而逐渐降低查询的效率。VACUUM FULL可以将磁盘页面碎片恢复并交还操作系统。
-- ANALYZE的作用是收集表的统计信息,将统计信息保存在系统表PG_STATISTIC中,便于执行计划树的优化。
VACUUM FULL product_info;
ANALYZE product_info;

