1 hbase shell基础实操
1.1 查看hbase状态
status1.2 查看版本号
version1.3 命名空间操作
# 创建命名空间
create_namespace '命名空间名'
# 显示所有命名空间
list_namespace
# 删除命名空间
drop_namespace '命名空间名'1.4 创建表
# 创建默认命名空间的表
create '表名称', '列族名称1','列族名称2','列族名称N'
# 创建带有命名空间的表
create '命名空间:表名称', '列族名称1','列族名称2','列族名称N'示例:
# 创建hainiu_table表,表里有三个列族
create 'xinniu:hainiu_table','cf1','cf2','cf3'创建完之后有一个region是上线的
状态和该表region的位置:

1.5 列出所有的表
# 查看所有的表
list
# 查询指定命名空间下的表
list_namespace_tables '命名空间'1.6 获取表描述
# 默认命名空间
describe '表名'
# 指定命名空间
describe '命名空间:表名'1.7 删除列族
# 删除hainiu_table 表的 cf3 列族
alter 'xinniu:hainiu_table',{NAME=>'cf3',METHOD=>'delete'}
# 查看表结构
describe 'xinniu:hainiu_table'
# 创建表
create 'xinniu:table1','cf1','cf2','cf3'
# 删除多个列族
alter 'xinniu:table1', {NAME => 'cf3', METHOD => 'delete'},{NAME => 'cf2', METHOD => 'delete'}1.8 其他ddl操作
# 把表设置为disable(下线)
disable '表名'
# drop表
# 先把表下线,再drop表
disable '表名'
drop '表名'
# 判断表是否存在
exists '表名'
# 判断表是否下线
is_disabled '表名'
# 判断表是否上线
is_enabled '表名'2 hbase dml操作
要保证表是enable状态
2.1 添加数据
添加数据的时候需要指定rowkey,列族列名,值
# 语法:put <table>,<rowkey>,<family:column>,<value>,<timestamp>
# 【注意:插入数据前要保证表是enable状态】
# 基本信息的列族
put 'xinniu:hainiu_table','id01', 'cf1:name','hainiu1'
put 'xinniu:hainiu_table','id01', 'cf1:age','10'
put 'xinniu:hainiu_table','id01', 'cf1:sex','boy'
# 证件信息的列族
put 'xinniu:hainiu_table','id01', 'cf2:cert_no','110125'
put 'xinniu:hainiu_table','id01', 'cf2:cert_type','身份证'2.2 查询一行数据
使用rowkey点查:
如果不指定列族则查询所有列族下所有列;
如果不指定列则查询所有列;
如果指定列族与列则只返回指定列的数据。
# 语法:get <table>,<rowkey>,[<family:column>,....]
# 获取一行数据
get 'xinniu:hainiu_table','id01'
# 获取一行,一个列族的所有数据
get 'xinniu:hainiu_table','id01','cf1'
# 获取一个id,一个列族中一个列的所有数据
get 'xinniu:hainiu_table','id01','cf1:name'也可以用下面的方式:
# 获取一行的列族
get 'xinniu:hainiu_table', 'id01', {COLUMN => 'cf1'}
# 获取一行中多个列族
get 'xinniu:hainiu_table', 'id01', { COLUMN => ['cf1','cf2']}
# 获取一行的某列族的列
get 'xinniu:hainiu_table', 'id01', {COLUMN => 'cf1:name'}
# 获取一行某列族的列并匹配时间戳
get 'xinniu:hainiu_table', 'id01', {COLUMN => 'cf1:name', TIMESTAMP => 1517890480644}
# 获取一行中,值为110125的列
get 'xinniu:hainiu_table', 'id01', {FILTER => "ValueFilter(=, 'binary:110125')"}2.3 更新数据
hbase没有upsert之类的语法,更新数据与添加数据语法一致,如果已经存在则增加一个新的版本。
# 语法:重新put,put时会覆盖原来的数据
2.4 扫描表
Scan '表名',这个动作是全表扫描,如果指定了startrow和endrow则变为范围查询,filter是全表扫。
# 语法:scan <table> ,{COLUMNS => [ <family:column>,.... ], LIMIT => num}示例:
先向hainiu_table 表加入id02、id03、id04数据
put 'xinniu:hainiu_table','id02', 'cf2:cert_no','110225'
put 'xinniu:hainiu_table','id02', 'cf2:cert_type','身份证'
put 'xinniu:hainiu_table','id03', 'cf2:cert_no','110325'
put 'xinniu:hainiu_table','id03', 'cf2:cert_type','身份证'
put 'xinniu:hainiu_table','id04', 'cf2:cert_no','110425'
put 'xinniu:hainiu_table','id04', 'cf2:cert_type','身份证'
# 扫描全表,大表操作不可取
scan 'xinniu:hainiu_table'
# 获取表中前两行
scan 'xinniu:hainiu_table', {LIMIT => 2}
# 扫描表中指定列族数据
scan 'xinniu:hainiu_table', {COLUMNS => 'cf1'}
# 扫描表中执行列族中列的数据
scan 'xinniu:hainiu_table', {COLUMNS => 'cf2:cert_no'}
# 扫描表中值=110225 的数据
scan 'xinniu:hainiu_table', FILTER=>"ValueFilter(=,'binary:110225')"
# 带有行筛选的scan, [STARTROW, STOPROW)
scan 'xinniu:hainiu_table', { STARTROW => 'id02', STOPROW => 'id03z'}
# 查询 rowkey>=id03,查询2行,筛选 cf2 列族的数据
scan 'xinniu:hainiu_table', {COLUMNS => 'cf2', LIMIT => 2, STARTROW => 'id03'}
# 查询 rowkey = id02 的行的cf2:cert_no
scan 'xinniu:hainiu_table', { STARTROW => 'id02', STOPROW => 'id02', COLUMN => 'cf2:cert_no'}
# 查询 rowkey 在 [id02, id04)
scan 'xinniu:hainiu_table', { STARTROW => 'id02', STOPROW => 'id04', COLUMN => 'cf2:cert_no'}2.5 删除某列数据
# 语法:delete <table>, <rowkey>, <family:column>
# 必须指定列名
# 会删除指定列的最新版本数据
# 删除行健为id04的值的‘cf2:cert_type’字段
delete 'xinniu:hainiu_table', 'id04', 'cf2:cert_type'2.6 删除整行数据
# 语法:deleteall <table>, <rowkey>
# 会删除指定行的所有版本
# 先新增id05行数据,用于删除行
put 'xinniu:hainiu_table','id05', 'cf2:cert_no','110525'
put 'xinniu:hainiu_table','id05', 'cf2:cert_type','身份证'
put 'xinniu:hainiu_table','id05', 'cf1:name','hainiu5'
# 删除id05行数据
deleteall 'xinniu:hainiu_table', 'id05'2.7 清空表数据
# 清空表数据且不保留region信息
truncate <table>
# 清空表数据保留region信息
truncate_preserve <table>2.8 查询表有多少行
2.8.1 小表统计
小表可以使用这种方式,大表不采用这种方式。
# 语法:count <table>, {INTERVAL => intervalNum, CACHE => cacheNum}
# INTERVAL设置多少行显示一次及对应的rowkey,默认1000;
# CACHE每次去取的缓存区大小,默认是10,调整该参数可提高查询速度
#put数据用于统计行数
put 'xinniu:hainiu_table','id06', 'cf2:cert_no','110625'
put 'xinniu:hainiu_table','id06', 'cf2:cert_type','身份证'
put 'xinniu:hainiu_table','id07', 'cf2:cert_no','110725'
put 'xinniu:hainiu_table','id07', 'cf2:cert_type','身份证'
put 'xinniu:hainiu_table','id08', 'cf2:cert_no','110825'
put 'xinniu:hainiu_table','id08', 'cf2:cert_type','身份证'
put 'xinniu:hainiu_table','id09', 'cf2:cert_no','110925'
put 'xinniu:hainiu_table','id09', 'cf2:cert_type','身份证'
# 查询表中数据行数
count 'xinniu:hainiu_table'
# 按照2行显示一次,查询
count 'xinniu:hainiu_table', {INTERVAL => 2} 2.8.2 大表count
大表取多少条使用如下方式进行统计。
# 调用的hbase jar中自带的统计行数的类。
hbase org.apache.hadoop.hbase.mapreduce.RowCounter 'tablename'
hbase org.apache.hadoop.hbase.mapreduce.RowCounter 'xinniu:hainiu_table'用 hdfs 用户去执行时报错,原因是 hdfs用户id是 994, 而提交yarn的用户id是1000及以上,需要修改yarn配置:
在配置里搜 user
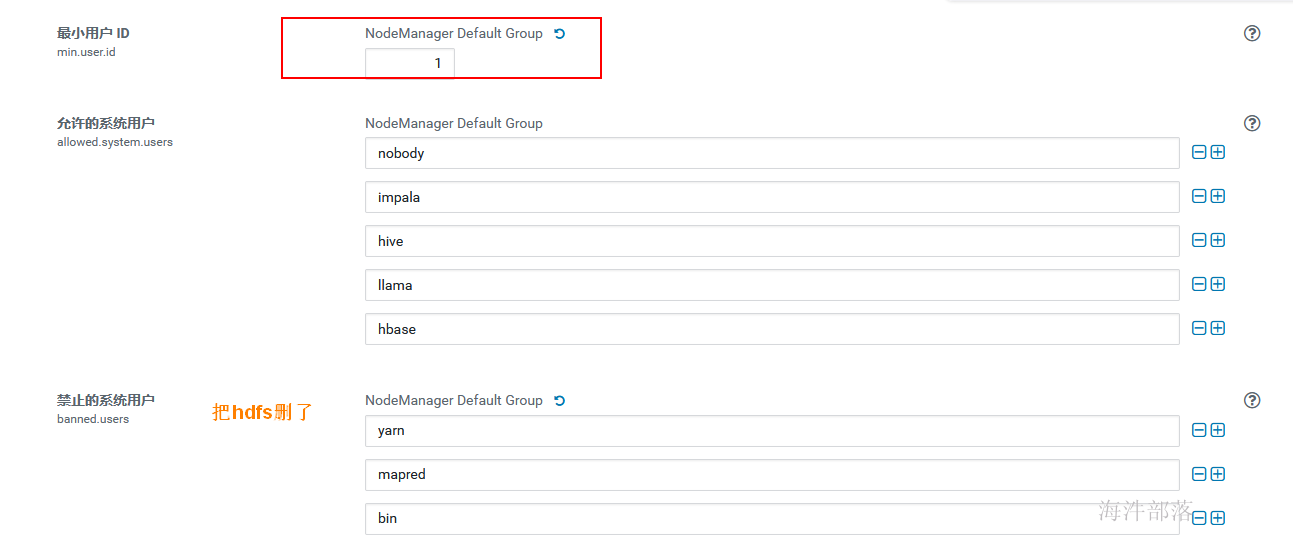
由于 hdfs 用户没有读取xinniu:hainiu_table表的权限,所以需要用hbase给hdfs赋权。
grant '@hdfs', 'RWXCA', 'xinniu:hainiu_table'
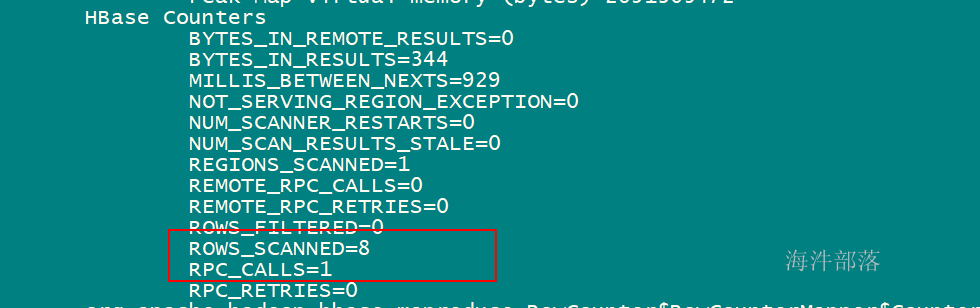
跑完mr后得到的counter数据:
2.8.3 counter计数器
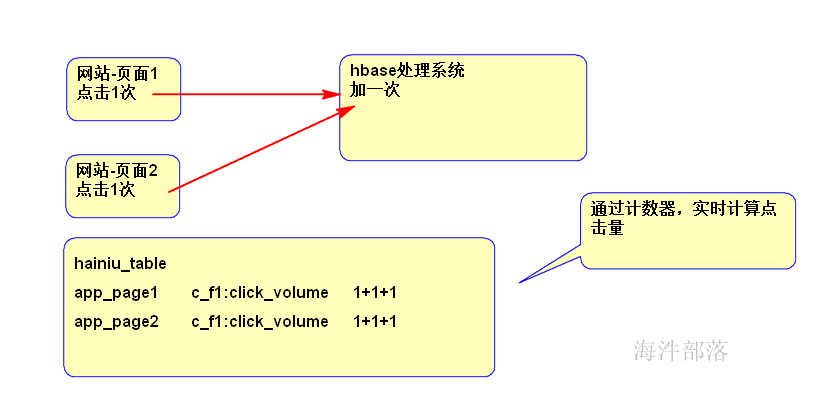
该场景适合在一些实时场景使用,如某点击类事件触发时则在hbase中incr一条,用于统计累计点击数比较方便。
多用于统计点击量等场景
# 语法: incr <tablename>,<rowkey>,<family:column>,long n
# 一次加1
incr 'xinniu:hainiu_table', 'app_page1', 'cf2:button_volume'
# 一次加N
incr 'xinniu:hainiu_table', 'app_page1', 'cf2:button_volume', 1000
示例:
2.9 多版本管理
即,相同rowkey相同列插入不同值。
#修改设置版本,查询时,加上版本就可以查出来版本
alter 'xinniu:hainiu_table',{ NAME =>'cf1', VERSIONS => 2 }
put 'xinniu:hainiu_table','id10', 'cf1:name','name10a'
put 'xinniu:hainiu_table','id10', 'cf1:name','name10aa'
put 'xinniu:hainiu_table','id10', 'cf1:name','name10aaa'
#此时,可以查询出2个版本的数据
get 'xinniu:hainiu_table', 'id10', { COLUMN =>'cf1:name', VERSIONS => 5}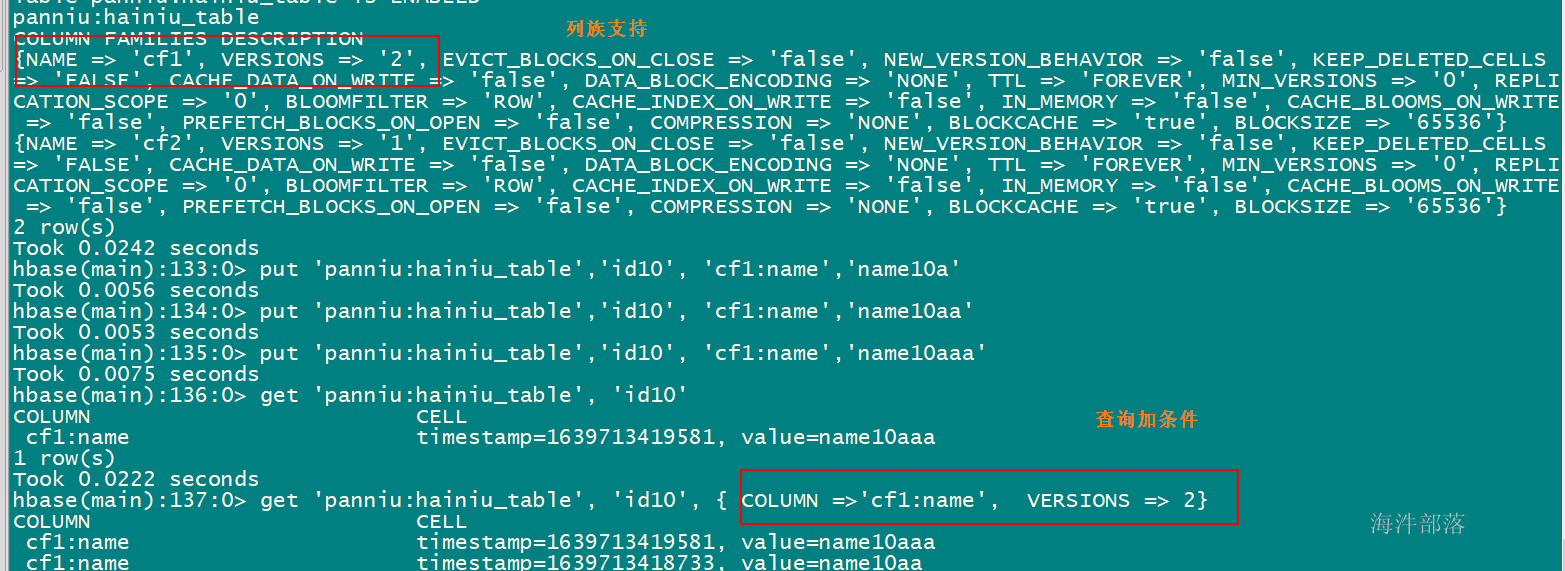
3 hbase预分region
3.1 为什么要预分region
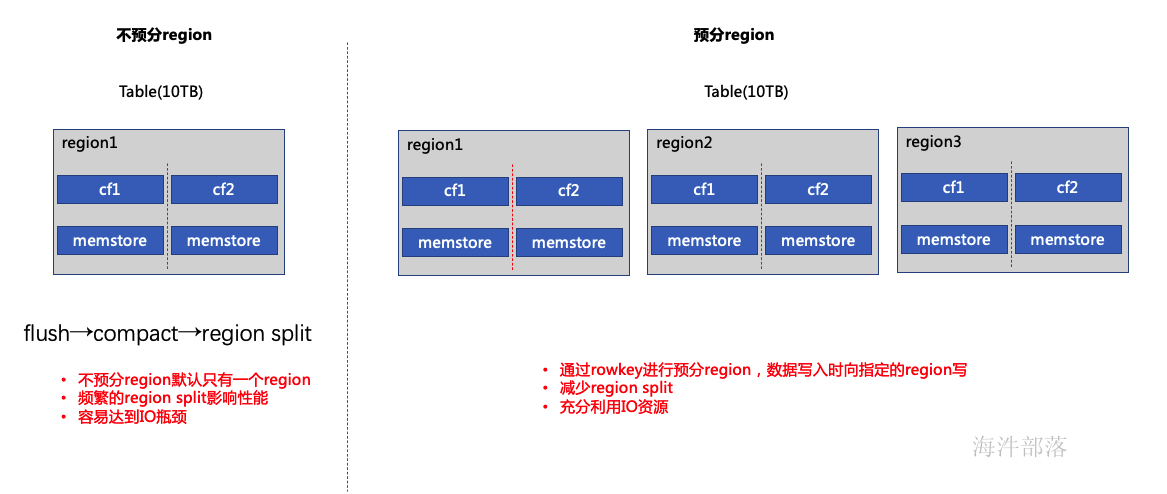
不预分region,hbase默认只有一个region,并且startkey和endkey不指定,只有触发了region split之后才会分裂成多个region,当写入的数据量较大的时候会伴随着频繁的region split操作,严重影响性能,同时不能充分利用IO性能,造成因IO瓶颈影响写入性能。
预分region后一张表的数据被预分到不同的region上,同时向多个region中写数据,大大提升了并发,且减少了region split的次数,避免单节点IO瓶颈问题。
3.2 建表时预分region
预分region需要考虑两个因素,即region个数与region大小。
- region个数
官方推荐region个数计算公式:
#
(RS Xmx * hbase.regionserver.global.memstore.size) / (hbase.hregion.memstore.flush.size * column familys)其中:
RS Xmx:regionserver堆栈内存大小,官方推荐每台regionserver内存大小设置20-24G,不推荐设置更大,因为更大的堆栈内存GC效率较低。
hbase.regionserver.global.memstore.size:为整个regionserver中memstore总大小占用总内存的比例,一般默认为0.4
hbase.hregion.memstore.flush.size:为memstoreflush阈值,一般默认128,可以自己设置
column familys:为列族数
例:(20G*0.4)/(128M*2)=32
官方推荐每个regionserver上region个数在20-200之间。
- region大小
单个region官方推荐大小为5-10GB,可以通过hbase.hregion.max.filesize设置,当超过该值后会触发split,与region split策略相关。
- 预分region
# 根据需求,把要导入的文件分成多个region
# 分析方法:按照rowkey的高位去分析
# 创建split文件,在文件中添加 splitkey(添加几个,取决于业务需求)
vim /home/xinniu/advance_split_region_file
8d305
8d306
8d307
# 创建表时,指定split文件,来实现创建预分表
create 'xinniu:advance_split_region', 'cf', {SPLITS_FILE => '/home/xinniu/advance_split_region_file'}webui上显示:

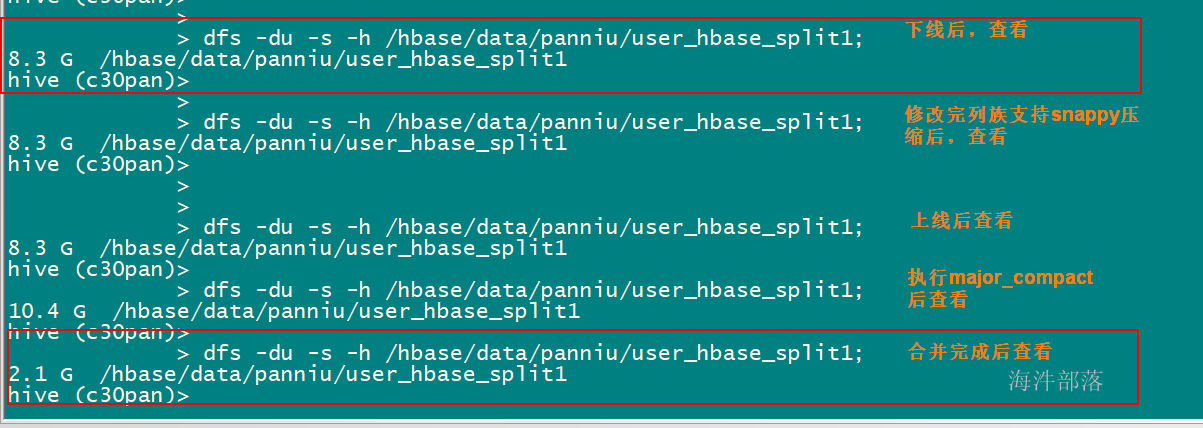
4 开启压缩
建表时指定压缩格式,开启压缩后可以非常有效的缓解hbase数据膨胀问题。
create 'xinniu:user_hbase_split1',{NAME => 'cf',VERSIONS => 3,COMPRESSION => 'SNAPPY'}, {SPLITS_FILE => '/tmp/advance_split_region_file'}如果建表没指定压缩格式,那需要修改列族支持,步骤如下:
1) disable 'xinniu:user_hbase_split1'
如果表的数据量很大,region很多,disable过程会比较缓慢,需要等待较长时间。过程可以通过查看hbase master log日志监控。
2) alter 'xinniu:user_hbase_split1', NAME => 'cf', COMPRESSION => 'snappy'
NAME即column family,列族。HBase修改压缩格式,需要一个列族一个列族的修改。名字一定要与你自己列族的名字一致,否则就会创建一个新的列族并且压缩格式是snappy的。
3)enable 'xinniu:user_hbase_split1'
重新enable表
4)major_compact 'xinniu:user_hbase_split1'
enable表后,HBase表的压缩格式并没有生效,还需要执行一个命令,major_compact
Major compact除了做文件Merge操作,还会将其中的delete项删除。