1 排序

order by
会对输入做全局排序,因此只有一个reducer。
设置reduce个数没用
order by 在hive.mapred.mode = strict 模式下 必须指定 limit 否则执行会报错。
sort by
不是全局排序,其在数据进入reducer前完成排序。 因此,如果用sort by进行排序,并且设置mapred.reduce.tasks>1, 则sort by只保证每个reducer的输出有序,不保证全局有序。
distribute by
(类似于分桶),就是把相同的key分到一个reducer中,根据distribute by指定的字段对数据进行划分到不同的输出reduce 文件中。
CLUSTER BY
cluster by column = distribute by column + sort by column (注意,都是针对column列,且采用默认ASC,不能指定排序规则为asc 或者desc)
示例
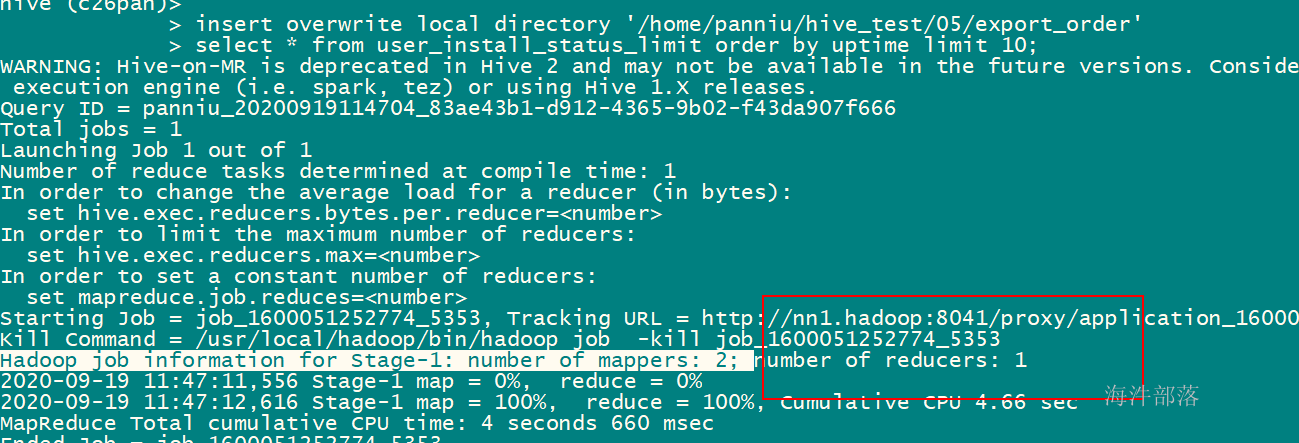
1)order by只能有一个reducer,设置了reducer也不起作用
-- 设置reduce个数为2
set mapred.reduce.tasks=2;
insert overwrite local directory '/home/xinniu/hive_test/05/export_order'
select * from user_install_status_limit order by uptime limit 10;设置的reduce数量不起作用
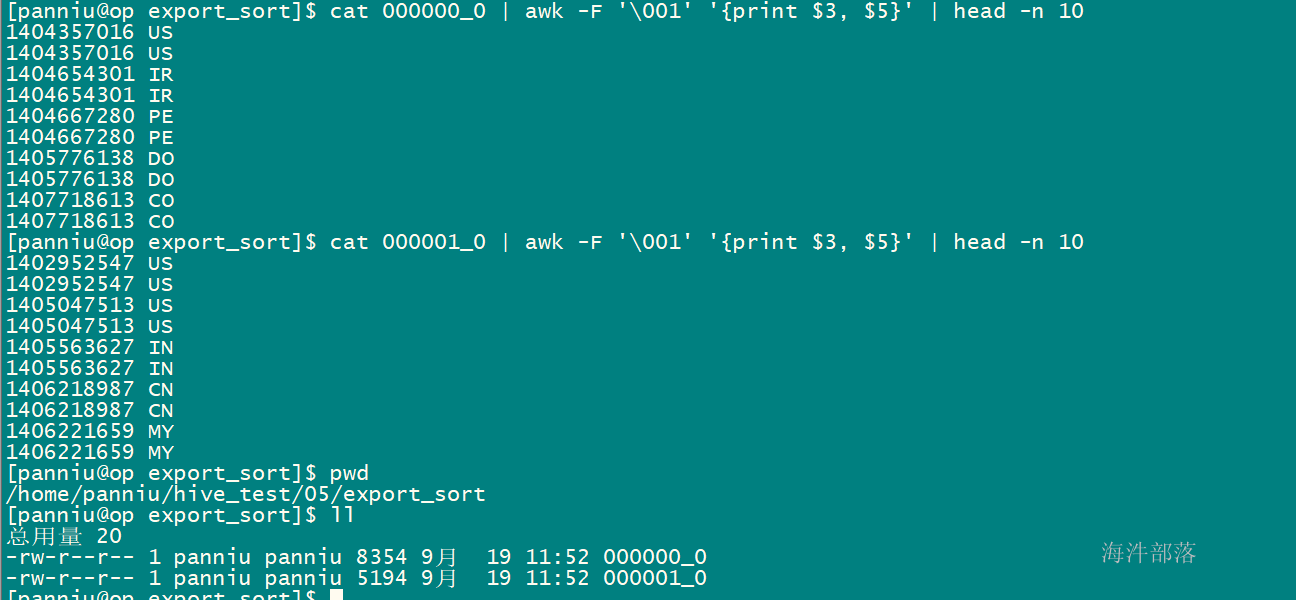
2)sort by只能保证单个文件内有序,如果设置成一个reducer那作用和order是一样的
set mapred.reduce.tasks=2;
insert overwrite local directory '/home/xinniu/hive_test/05/export_sort'
select * from user_install_status_limit sort by uptime ;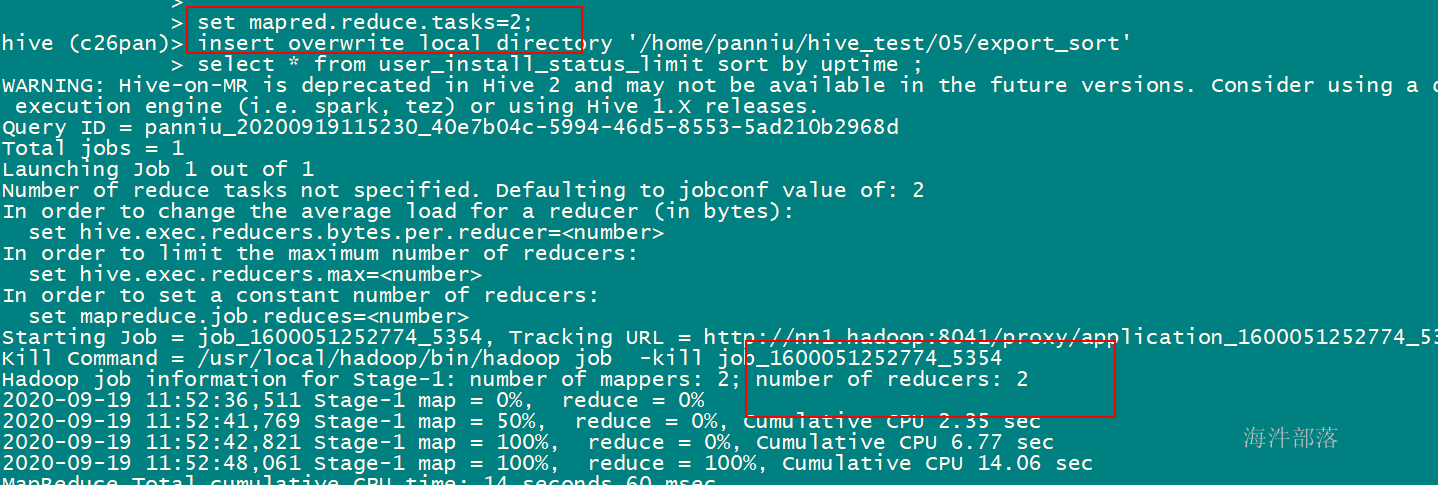
3)distribute by sort by = cluster by
set mapred.reduce.tasks=2;
insert overwrite local directory '/home/xinniu/hive_test/05/export_cluster'
select * from user_install_status_limit cluster by country;
--等于
set mapred.reduce.tasks=2;
insert overwrite local directory '/home/xinniu/hive_test/05/export_distribute_sort'
select * from user_install_status_limit distribute by country sort by country;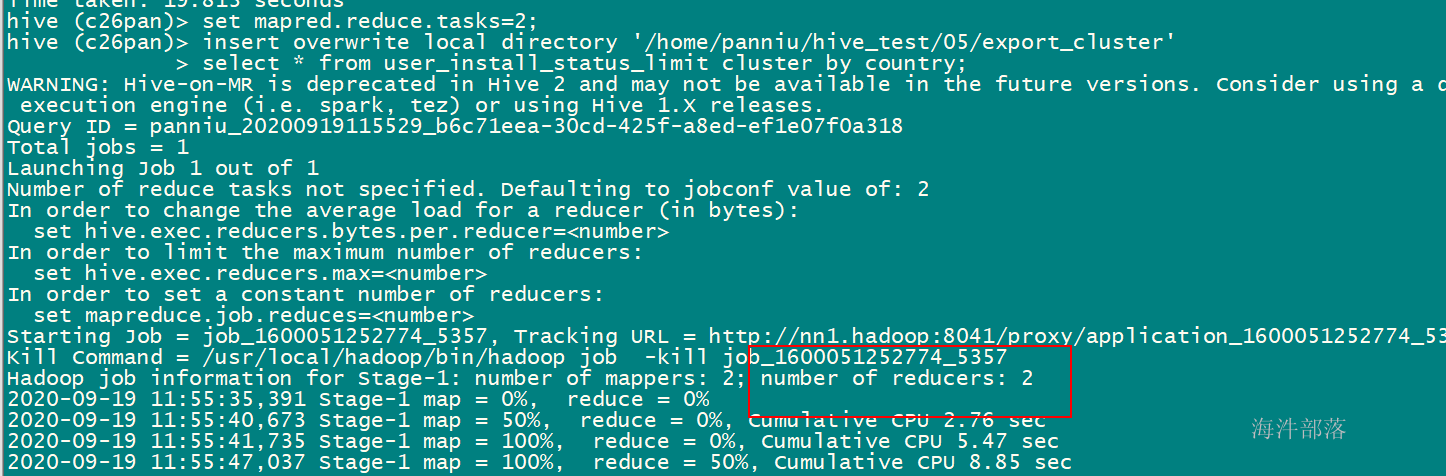

想实现降序,需要用 distribute by country sort by country组合
set mapred.reduce.tasks=2;
insert overwrite local directory '/home/xinniu/hive_test/05/export_distribute_sort_desc'
select * from user_install_status_limit distribute by country sort by country desc;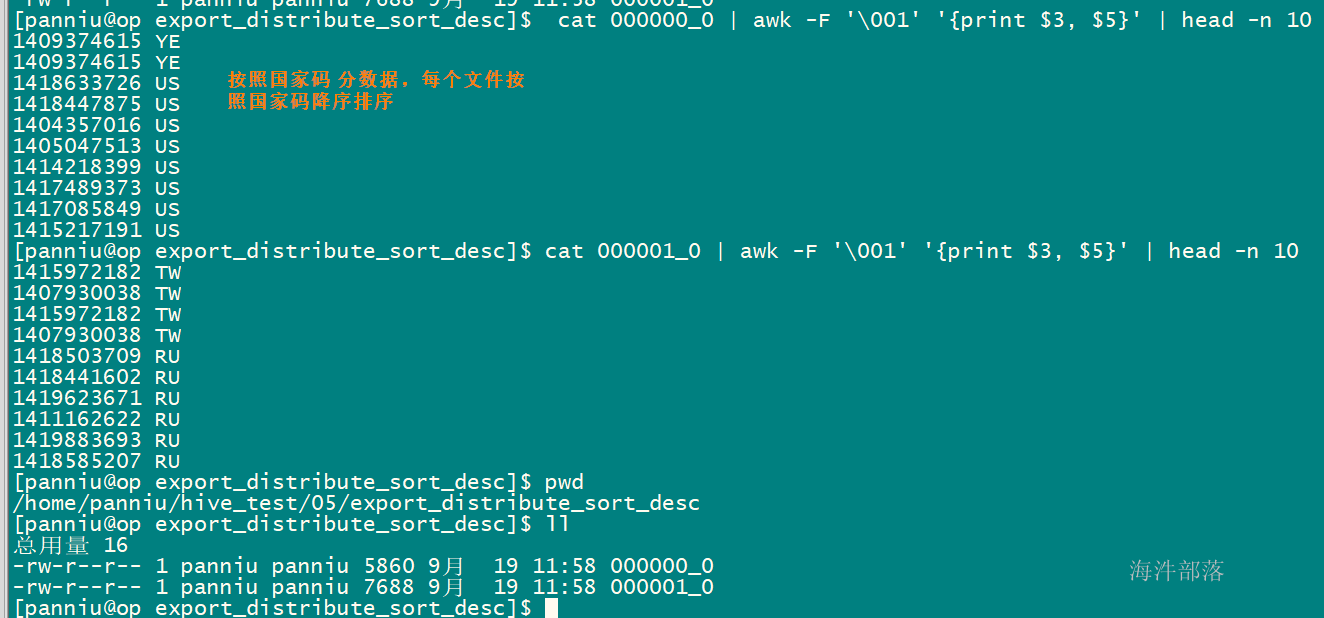
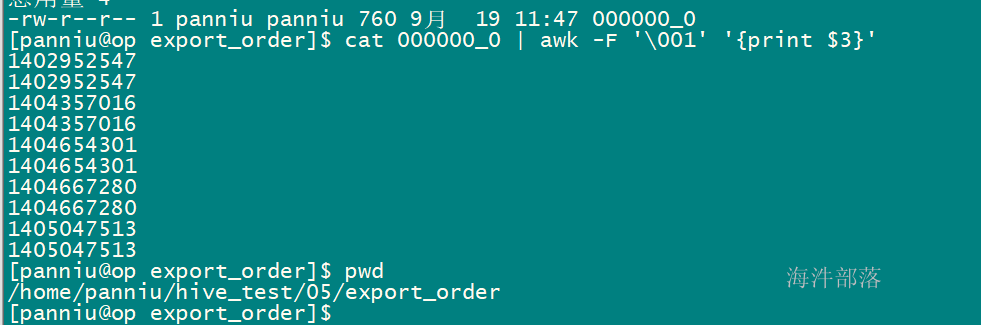
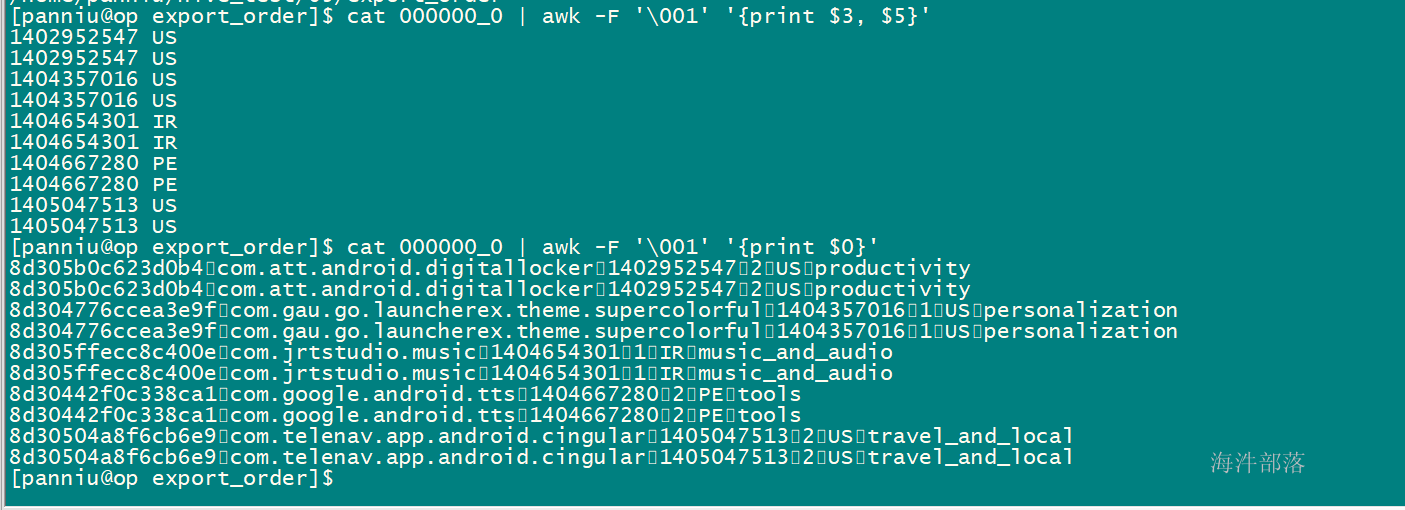
打印000000_0 文件的第五列的数据
cat ./000000_0_select_cluster |awk -F '\001' '{print $5}'
awk工作流程:
读入有'\n'换行符分割的一条记录,然后将记录按指定的域分隔符划分域,填充域,
$0则表示所有域;
$1表示第一个域;
$n表示第n个域;
默认域分隔符是"空白键" 或 "[tab]键"
-F指定域分隔符,本例指定\001
在select结果中cluster by可以保证组内是有序的
在桶表中clustered by组内是否有序要根据sort by决定
2 窗口函数
聚合函数(如sum()、avg()、max()等等)是针对定义的行集(组)执行聚集,每组只返回一个值。
窗口函数也是针对定义的行集(组)执行聚集,可为每组返回多个值。如既要显示聚集前的数据,又要显示聚集后的数据。
select sex, count(*) from student group by sex;窗口查询有两个步骤:将记录分割成多个分区,然后在各个分区上调用窗口函数。
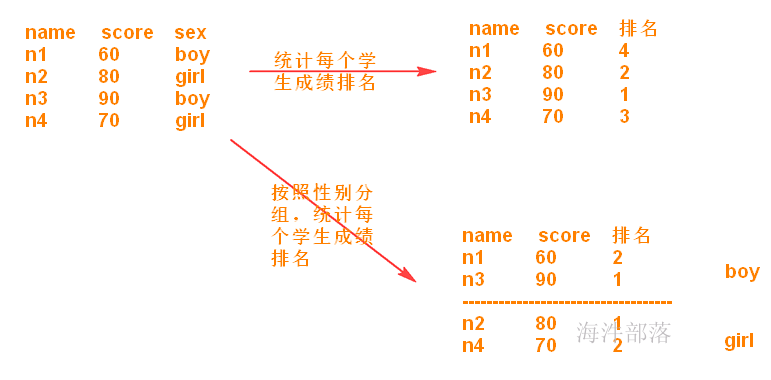
语法:主要是over( PARTITION BY (根据某条件分组,形成一个小组)….ORDER BY(再组内进行排序) …. )
2.1 over
over (order by col1) --按照 col1 排序
over (partition by col1) --按照 col1 分区
over (partition by col1 order by col2) -- 按照 col1 分区,按照 col2 排序
--带有窗口范围
over (partition by col1 order by col2 ROWS 窗口范围) -- 在窗口范围内,按照 col1 分区,按照 col2 排序下面先学习窗口函数是如何操作的
--wt1 表数据
id name age
1 a1 10
2 a2 10
3 a3 10
4 a4 20
5 a5 20
6 a6 20
7 a7 20
8 a8 30
--建表
CREATE TABLE wt1(
id int,
name string,
age int
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
load data local inpath '/home/xinniu/0709/f3' overwrite into table wt1;
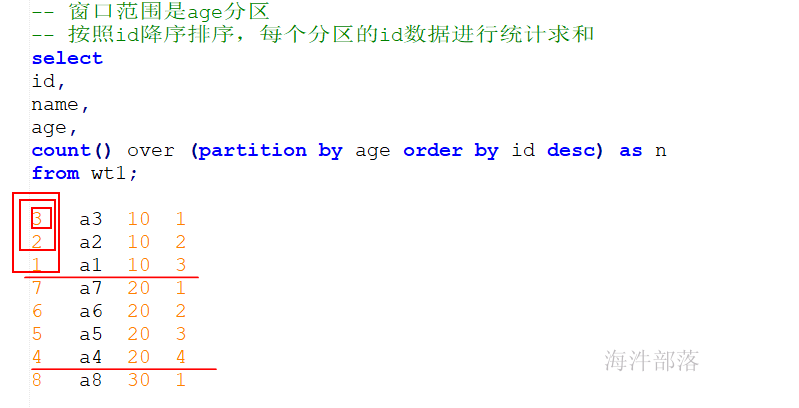
-- 窗口范围是整个表
-- 按照age排序,每阶段的age数据进行统计求和
select
id,
name,
age,
count() over (order by age) as n
from wt1;
1 a1 10 3
2 a2 10 3
3 a3 10 3
4 a4 20 7
5 a5 20 7
6 a6 20 7
7 a7 20 7
8 a8 30 8
------------------------------------
-- 窗口范围是表下按照age进行分区
-- 在分区里面,再按照age进行排序
select
id,
name,
age,
count() over (partition by age order by age) as n
from wt1;
1 a1 10 3
2 a2 10 3
3 a3 10 3
4 a4 20 4
5 a5 20 4
6 a6 20 4
7 a7 20 4
8 a8 30 1
----------------------------------
-- 窗口范围是表下按照age进行分区
-- 在分区里面,再按照id进行降序排序
select
id,
name,
age,
count() over (partition by age order by id desc) as n
from wt1;
3 a1 10 1
2 a2 10 2
1 a3 10 3
7 a4 20 1
6 a5 20 2
5 a6 20 3
4 a7 20 4
8 a8 30 1
--------------------------------------

2.2 序列函数
row_number:会对所有数值,输出不同的序号,序号唯一且连续,如:1、2、3、4、5。
rank:会对相同数值,输出相同的序号,而且下一个序号间断,如:1、1、3、3、5。
dense_rank:会对相同数值,输出相同的序号,但下一个序号不间断,如:1、1、2、2、3。
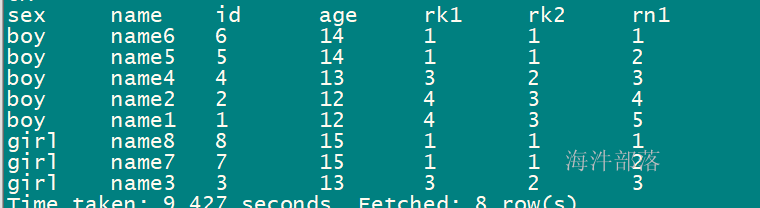
2.1.1 三个函数的结果比对
-- 按照性别分组,再按照年龄降序排序
set hive.cli.print.header=true;
select sex,name,id,age,
rank() over(partition by sex order by age desc) as rk1,
dense_rank() over(partition by sex order by age desc) as rk2,
row_number() over(partition by sex order by age desc) as rn1
from student_grouping;查询结果
2.2.2 ROW_NUMBER()
row_number() OVER (PARTITION BY COL1 ORDER BY COL2) 表示根据COL1分组,在分组内部根据 COL2排序,而此函数计算的值就表示每组内部排序后的顺序编号(组内连续的唯一的)。
示例
-- rn_id 按照性别分组,按照id 降序排序
select sex,name,id,
row_number() over(partition by sex order by id desc) as rn_id
from student_grouping;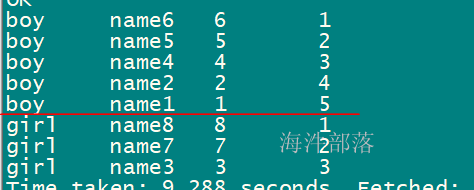
在上面的数据集结果里,能查询出来每个性别的最大id用户数据
select t1.sex,t1.name,t1.id from
(
select sex,name,id,
row_number() over(partition by sex order by id desc) as rn_id
from student_grouping
) t1 where t1.rn_id=1;
应用场景:求按照班级分组,统计最大的或最小的成绩对应的学生信息;
求按照班级分组,统计成绩前几名的学生信息;(分组后 top N)
求按照用户分组,统计每个用户最新的访问记录;
一个查询语句,有两个row_number(),并且两个分组一样,但排序不一样,查询出来的数据会跟着哪个走?
-- rn_id 按照性别分组,按照id排序
-- rn_age 按照性别分组,按照age 排序
set hive.cli.print.header=true;
select sex,name,id,age,
row_number() over(partition by sex order by id desc) as rn_id,
row_number() over(partition by sex order by age desc) as rn_age
from student_grouping;查询结果:

根据结果,可以看出,查询的数据是按照rn_age 来排序的。
这样写有什么作用呢?
可以将查询结果放到一个表里,按照不同的排序方式获取不同的数据。
over中partition by和distribute by区别
1)partition by [key..] order by [key..]只能在窗口函数中使用,而distribute by [key...] sort by [key...]在窗口函数和select中都可以使用。
2)窗口函数中两者是没有区别的
3)where后面不能用partition by
示例
-- 不在窗口函数中使用,报错
select * from student_grouping partition by sex order by age;
-- 不在窗口函数中使用,不报错
select * from student_grouping distribute by sex sort by age;
-- distribute 可以在窗口函数中使用
select
id,name,age,sex,
row_number() over (distribute by sex sort by id desc) as rn_id
from student_grouping;
2.3 Window 函数
ROWS窗口函数中的行选择器
rows between
[n|unbounded preceding]|[n|unbounded following]|[current row]
an d
[n|unbounded preceding]|[n|unbounded following]|[current row]
参数解释:
n行数
unbounded不限行数
preceding在前N行
following在后N行
current row当前行组合出的结果:
-- 前无限行到当前行
rows between unbounded preceding and current row
-- 前2 行到当前行
rows between 2 preceding and current row
-- 当前行到后2行
rows between current row and 2 following
-- 前无限行到后无限行
rows between unbounded preceding and unbounded following应用场景:
1)查询当月销售额和近三个月的销售额
2)查询当月销售额和今年年初到当月的销售额
示例:
年份 月份 销售额
2017 01 1000
2017 02 1000
2017 03 3000
2017 04 3000
2017 05 5000
2017 06 5000
2017 07 1000
2017 08 1000
2017 09 3000
2017 10 3000
2017 11 5000
2017 12 5000
2018 01 1000
2018 02 2000
2018 03 3000
2018 04 4000
2018 05 5000
2018 06 6000建表导入数据
CREATE TABLE sale_table(
y string,
m string,
sales int
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';查询
-- 查询当月销售额和近三个月的销售额
select
y,
m,
sales,
sum(sales) over(order by y,m rows between 2 preceding and current row) as last3sales
from sale_table;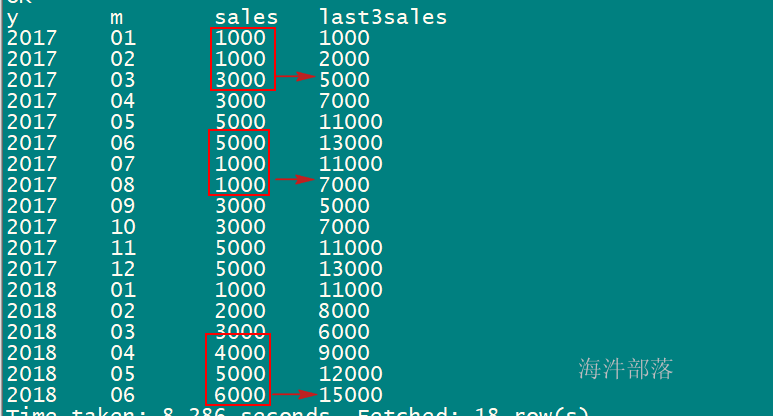
---------------------------------------------------------------------------------------------------------
-- 查询当月销售额和年初到当月的销售额
select
y,
m,
sales,
sum(sales) over(partition by y order by y,m rows between unbounded preceding and current row) as sales2
from sale_table;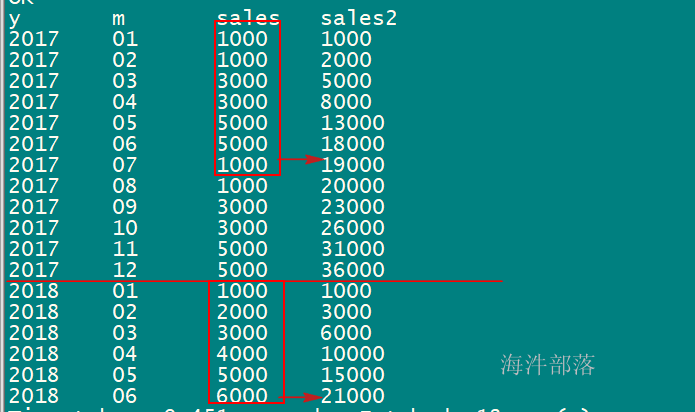
3.在ieda上运行hive
3.1 查看运行hive的jar包和主类
通过sh -x /usr/local/hive/bin/hive查看执行了哪个类

查看日志的最后一页

3.2 在工程添加hive-cli 的maven 依赖
发现是执行的hive的cli,在阿里云上搜索hive-cli
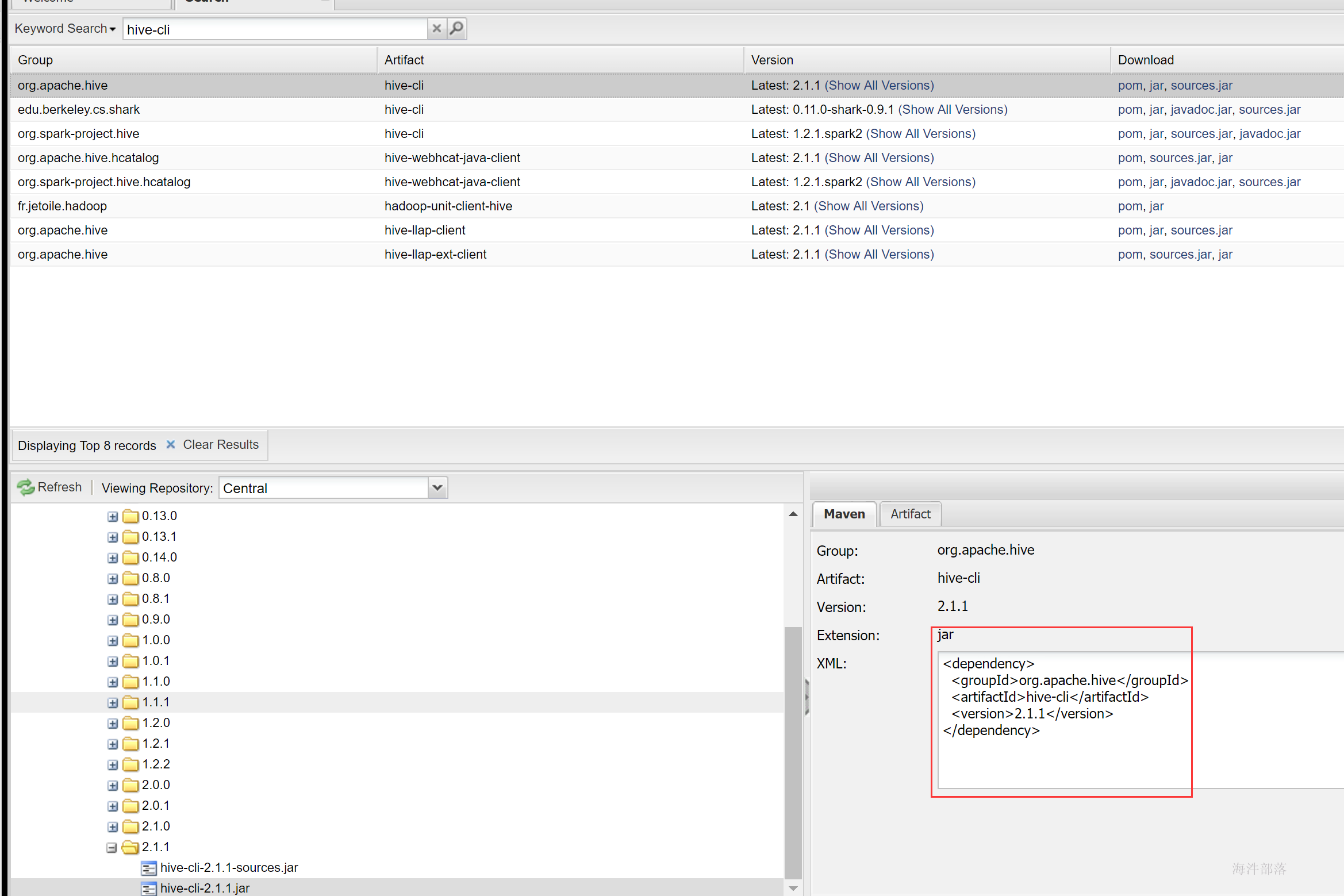
新建maven项目,并添加hive-cli的pom
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-cli</artifactId>
<version>2.1.1</version>
</dependency>找到org.apache.hadoop.hive.cli.CliDriver类的main方法
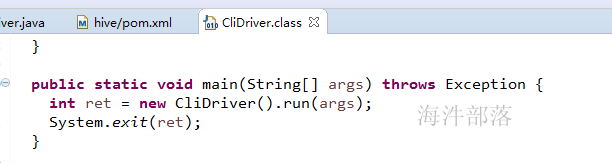
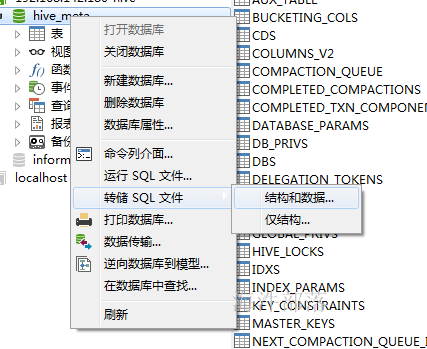
3.3 在本地导入从虚拟机导出的元数据
导出虚拟机上的mysql库的元数据
在本机的mysql上安装hive元库,在navicat中按F6调出mysql控制台
-- 在本地创建hive用户
CREATE USER 'hive'@'%' IDENTIFIED BY '12345678';
-- 在本地创建 hive_meta 库
create database hive_meta default charset utf8 collate utf8_general_ci;
-- 赋权限
grant all privileges on hive_meta.* to 'hive'@'%' identified by '12345678';
flush privileges;
-- 注意:
-- 如果报hive权限不够可以再增加hive本地用户权限
grant all privileges on hive_meta.* to 'hive'@'localhost' identified by '12345678';
flush privileges; 导入刚才在虚拟机上导出的hive元数据,刷新一下数据库查看表是否导入完成
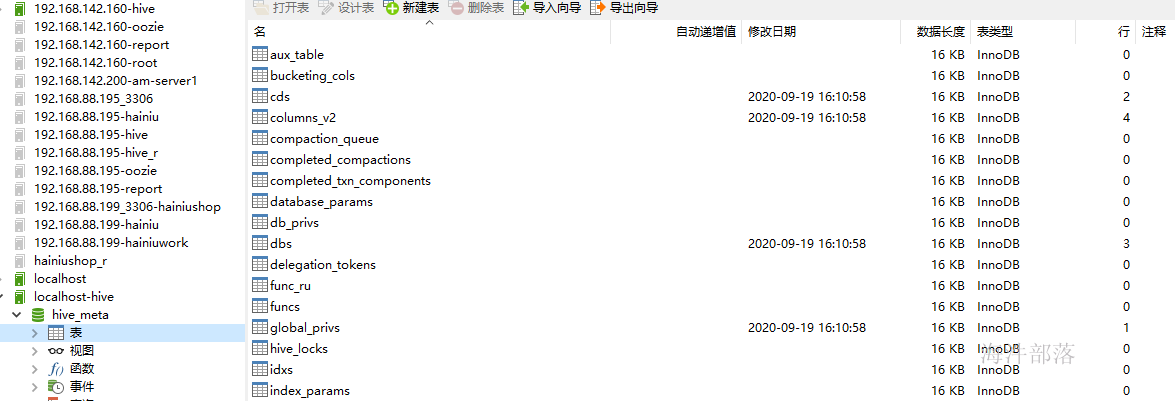
3.4 在pom里面加上mysql连接驱动
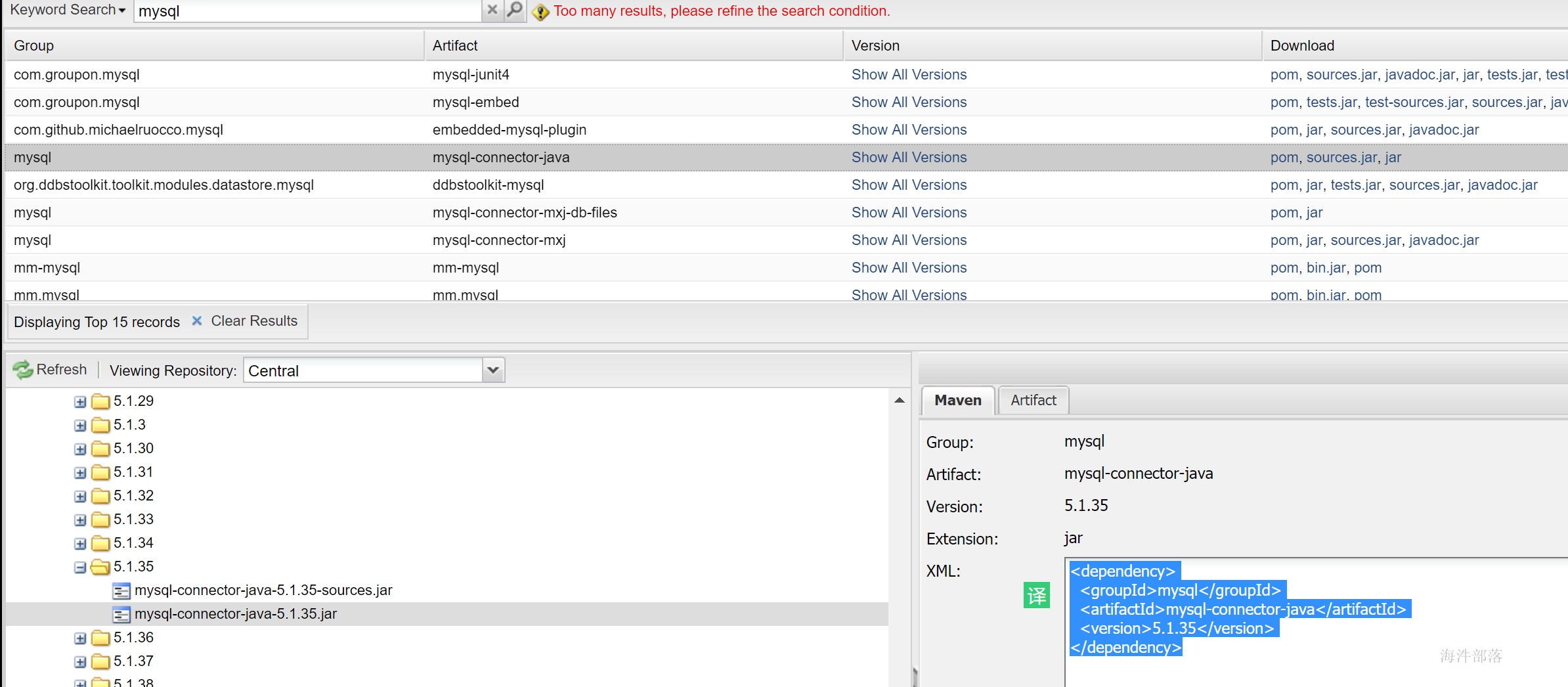
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.35</version>
</dependency>3.5 获取hive的两个配置文件,并放到工程中
在虚拟机上获得这两个配置

复制在项目的resource目录
修改hive-site.xml,让你的eclipse中的hive连接自己windows上的数据库
<configuration>
<!-- 数据库 start -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive_meta</value>
<description>mysql连接</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>mysql驱动</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
<description>数据库使用用户名</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>12345678</value>
<description>数据库密码</description>
</property>
<!-- 数据库 end -->
<!-- HDFS start -->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/tmp/hive/warehouse</value>
<description>hive使用的windows目录</description>
</property>
<!-- HDFS end -->
<!-- metastore start 在客户端使用时,mysql连接和metastore同时出现在配置文件中,客户端会选择使用metastore -->
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
<!-- 其它 end -->
</configuration>3.6 运行hive
然后运行CliDriver的main方法,启动eclipse上的hive
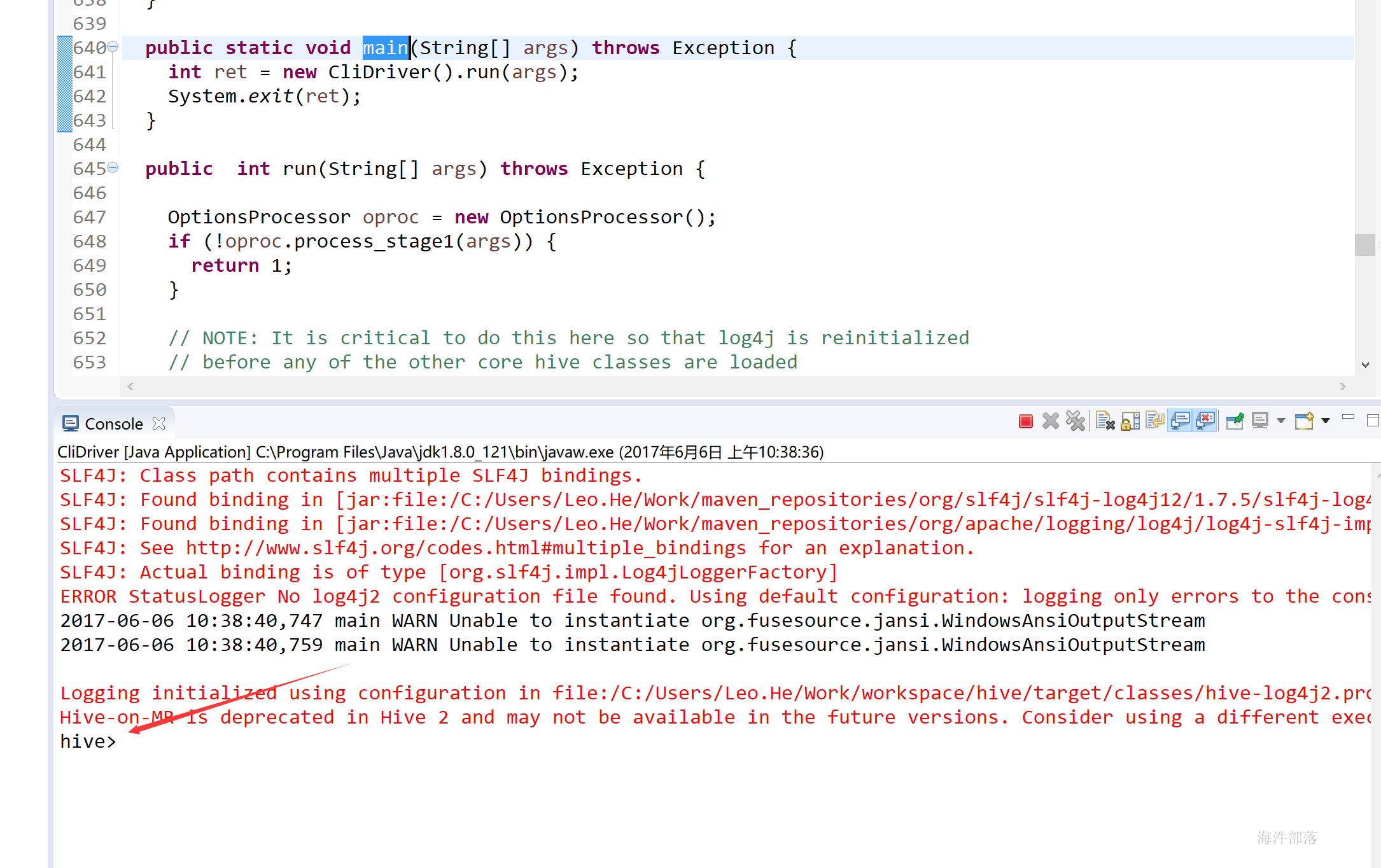
发现输入的命令不好使,是因为hive使用的是jline接受输入命令
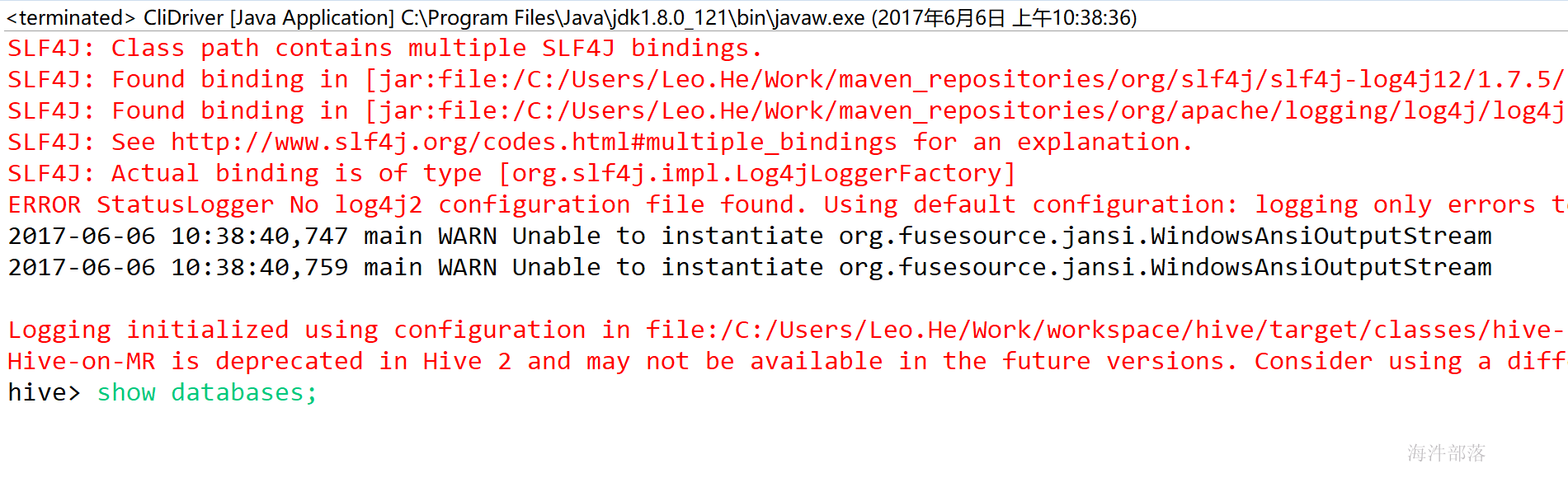
自己写一个类把clidriver中的main方法拷贝到自己类中的main方法中并加上让jline使用system.in做控制台的输入
System.setProperty("jline.WindowsTerminal.directConsole", "false");

然后运行自己类中的main方法在eclipse上启动hive
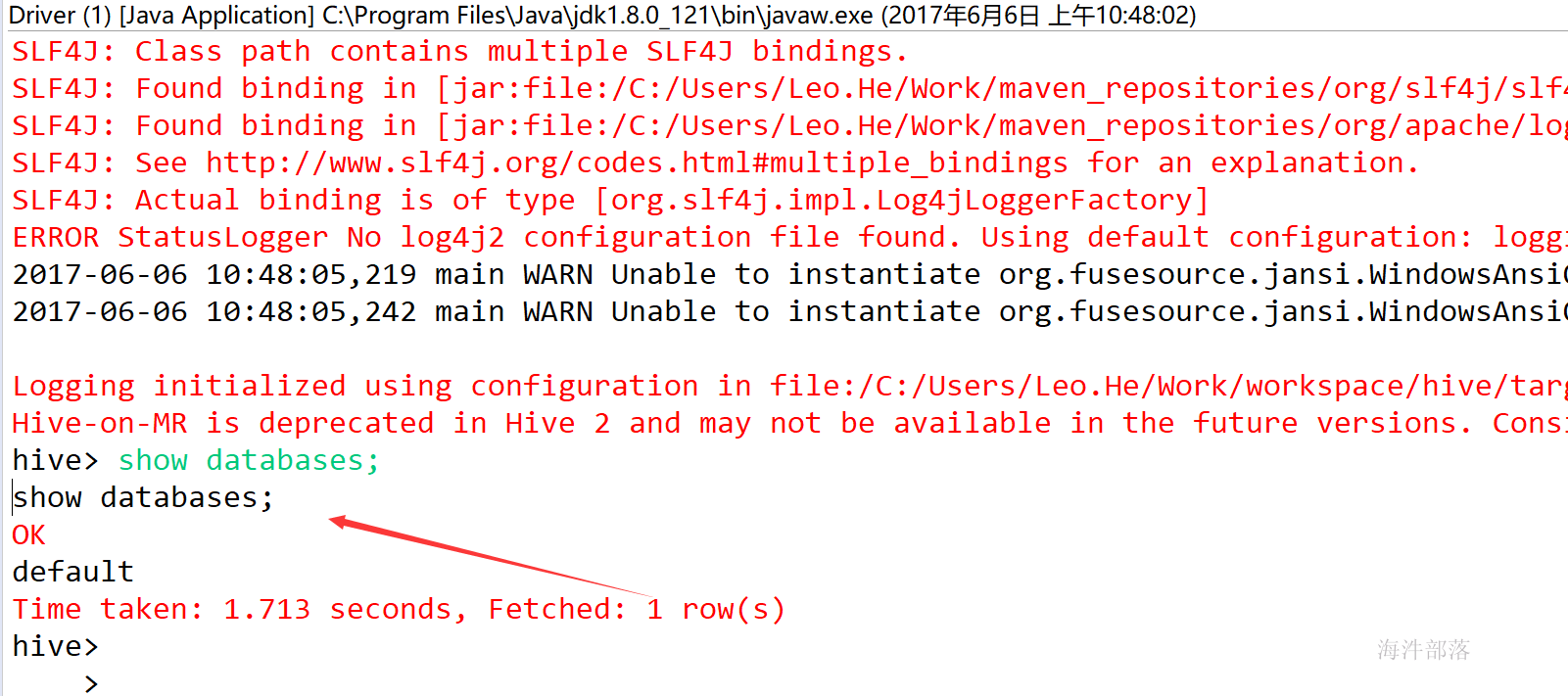
由于修改了jline的系统属性,所以在自己的类中运行的hive是能接受输入信息的。
注意:
由于我们用的hive元数据是集群的hive的元数据,集群hive元数据是写入hdfs目录,在本地执行hive是写入windows目录,所以需要重新创建新的数据库,在新创建的数据库中建表。
创建内部表:
-- 内部表
CREATE TABLE `user_inner`(
`aid` string COMMENT 'from deserializer',
`pkgname` string COMMENT 'from deserializer',
`uptime` bigint COMMENT 'from deserializer',
`type` int COMMENT 'from deserializer',
`country` string COMMENT 'from deserializer',
`gpcategory` string COMMENT 'from deserializer')
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';验证:
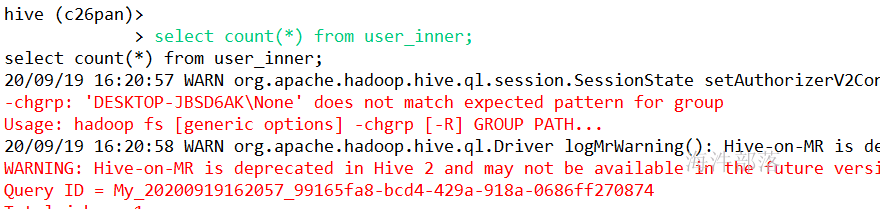
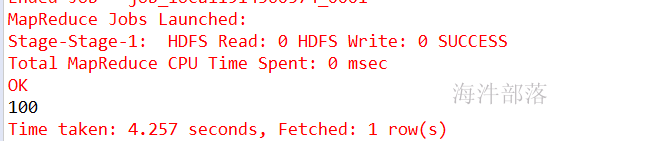
创建外部表:
-- 外部表
CREATE external TABLE `user_ext`(
`aid` string COMMENT 'from deserializer',
`pkgname` string COMMENT 'from deserializer',
`uptime` bigint COMMENT 'from deserializer',
`type` int COMMENT 'from deserializer',
`country` string COMMENT 'from deserializer',
`gpcategory` string COMMENT 'from deserializer')
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'
LOCATION '/tmp/hive_data/user_ext';验证:
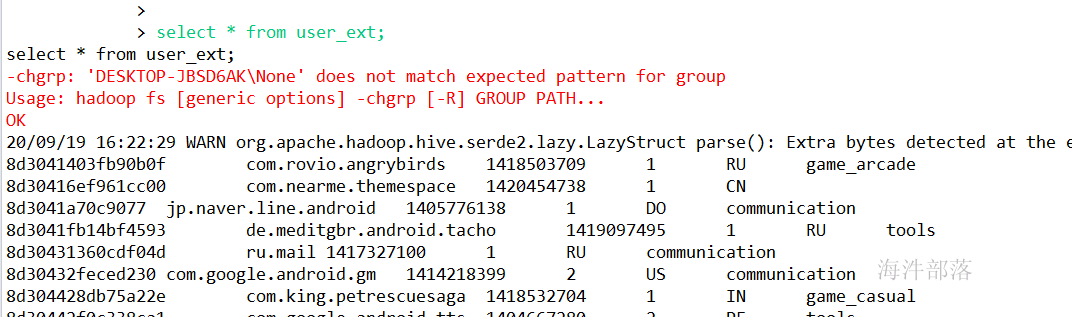
4 UDF函数
UDF的全称为user-defined function,用户定义函数,为什么有它的存在呢?有的时候 你要写的查询无法轻松地使用Hive提供的内置函数来表示,通过写UDF,Hive就可以方便地插入用户写的处理代码并在查询中使用它们,相当于在HQL(Hive SQL)中自定义一些函数。
UDF、UDAF、UDTF区别
UDF (user defined function) 用户自定义函数:对单行记录进行处理;
UDAF (user defined aggregation function) 用户自定义聚合函数,多行记录汇总成一行,常用于聚合函数;
UDTF:单行记录转换成多行记录;
注意UDF函数名不是大小写敏感的
新建function包,所有的自定义函数写在这个包的下面
5 UDF
用户自定义函数:对单行记录进行处理
5.1创建使用函数流程
1)自定义一个Java类
2)继承类 GenericUDF
3)重写继承的方法
4)在hive执行创建模板函数
5)hql中使用
5.2 实现需求,能将国家编码转成中文国家名的UDF函数
1)首先上传code对应名称的数据

放到resource目录下
2)创建自定义UDF类并继承hive的GenericUDF 类
首先把数据读到缓存里,然后选择性实现 5个 方法。
//可选,该方法中可以通过context.getJobConf()获取job执行时候的Configuration;
//可以通过Configuration传递参数值
public void configure(MapredContext context) {}
//必选,该方法用于函数初始化操作,并定义函数的返回值类型,判断传入参数的类型;
public ObjectInspector initialize(ObjectInspector[] arguments)
//必选,函数处理的核心方法,用途和UDF中的evaluate一样,每一行都调用一次;
public Object evaluate(DeferredObject[] args){}
//必选,显示函数的帮助信息
public String getDisplayString(String[] children)
//可选,map完成后,执行关闭操作
public void close(){}3) hive加载并使用自定义函数
hive加载自定义函数的方法
CREATE TEMPORARY FUNCTION [function_name ] AS 'class_path';
-- 加载自定义函数
CREATE TEMPORARY FUNCTION code2name AS 'com.hainiu.hive.function.CountryCode2CountryNameUDF';
--使用自定义函数
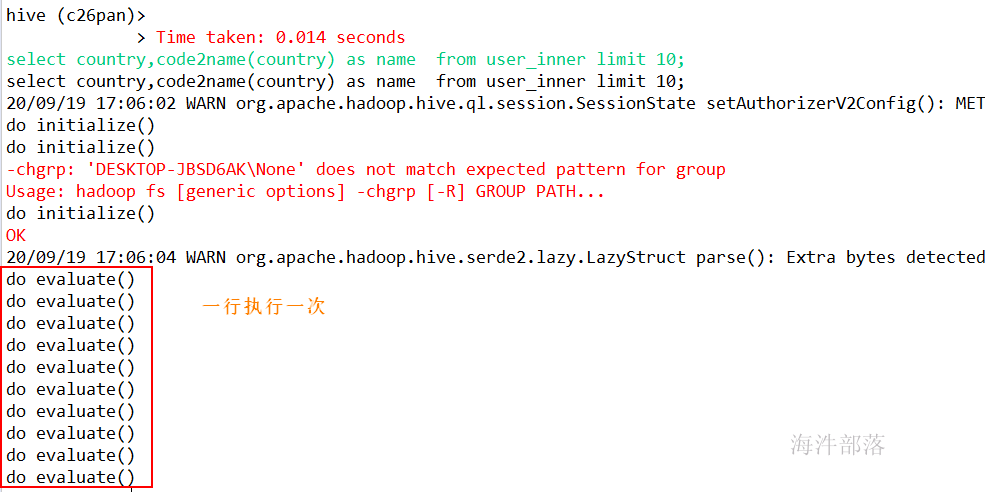
select country,code2name(country) as name from user_inner limit 10;运行结果


package com.hainiu.function;
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.util.Arrays;
import java.util.HashMap;
import java.util.Map;
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDF;
import org.apache.hadoop.hive.serde2.lazy.LazyString;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.PrimitiveObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
import org.apache.hadoop.io.Text;
/**
* 实现国家码转国家名称的UDF函数
* code2name(CN) --> 中国
* @author 潘牛
* @Date 2021年5月31日
*/
public class CountryCode2CountryNameUDF extends GenericUDF{
static Map<String,String> countryMap = new HashMap<String,String>();
static{
// 将 字典文件数据写入内存
try(
InputStream is = CountryCode2CountryNameUDF.class.getResourceAsStream("/country_dict.txt");
BufferedReader reader = new BufferedReader(new InputStreamReader(is, "utf-8"));
){
String line = null;
while((line = reader.readLine()) != null){
String[] arr = line.split("\t");
String code = arr[0];
String name = arr[1];
countryMap.put(code, name);
}
System.out.println("countryMap.size: " + countryMap.size());
}catch(Exception e){
e.printStackTrace();
}
}
@Override
public ObjectInspector initialize(ObjectInspector[] arguments) throws UDFArgumentException {
System.out.println("initialize");
// 校验函数输入参数和 设置函数返回值类型
// 1) 校验入参个数
if(arguments.length != 1){
throw new UDFArgumentException("input params must one");
}
ObjectInspector inspector = arguments[0];
// 2) 校验参数的大类
// 大类有: PRIMITIVE(基本类型), LIST, MAP, STRUCT, UNION
if(! inspector.getCategory().equals(ObjectInspector.Category.PRIMITIVE)){
throw new UDFArgumentException("input params Category must PRIMITIVE");
}
// 3) 校验参数的小类
// VOID, BOOLEAN, BYTE, SHORT, INT, LONG, FLOAT, DOUBLE, STRING,
// DATE, TIMESTAMP, BINARY, DECIMAL, VARCHAR, CHAR, INTERVAL_YEAR_MONTH, INTERVAL_DAY_TIME,
// UNKNOWN
if(! inspector.getTypeName().equalsIgnoreCase(PrimitiveObjectInspector.PrimitiveCategory.STRING.name())){
throw new UDFArgumentException("input params PRIMITIVE Category type must STRING");
}
// 4) 设置函数返回值类型
// writableStringObjectInspector 里面有 Text, Text 里面有String类型
return PrimitiveObjectInspectorFactory.writableStringObjectInspector;
}
/**
* 定义函数输出对象
*/
Text output = new Text();
@Override
public Object evaluate(DeferredObject[] arguments) throws HiveException {
System.out.println("evaluate");
// 核心算法, 一行调用一次
// 获取入参数据
Object obj = arguments[0].get();
String code = null;
if(obj instanceof LazyString){
LazyString lz = (LazyString)obj;
Text t = lz.getWritableObject();
code = t.toString();
}else if(obj instanceof Text){
Text t = (Text)obj;
code = t.toString();
}else{
code = (String)obj;
}
// 翻译国家码
String countryName = countryMap.get(code);
countryName = countryName == null ? "某个小国" : countryName;
output.set(countryName);
return output;
}
@Override
public String getDisplayString(String[] children) {
// 报错说明
return Arrays.toString(children);
}
}6 hive优化
hive性能优化时,把HiveQL当做M/R程序来读,即从M/R的运行角度来考虑优化性能,从更底层思考如何优化运算性能,而不仅仅局限于逻辑代码的替换层面。
6.1 列裁剪
Hive 在读数据的时候,可以只读取查询中所需要用到的列,而忽略其它列。
6.2 分区裁剪
可以在查询的过程中减少不必要的分区,不用扫描全表。
6.3 合理设置reduce的数量
reduce个数的设定极大影响任务执行效率,在设置reduce个数的时候需要考虑这两个原则:使大数据量利用合适的reduce数;使单个reduce任务处理合适的数据量。
在不指定reduce个数的情况下,Hive会猜测确定一个reduce个数,基于以下,两个设定:
参数1:hive.exec.reducers.bytes.per.reducer(每个reduce任务处理的数据量,在Hive 0.14.0及更高版本中默认为256M)
参数2:hive.exec.reducers.max(每个任务最大的reduce数,在Hive 0.14.0及更高版本中默认为1009)
计算reducer数的公式: N = min( 参数2,总输入数据量 / 参数1 )
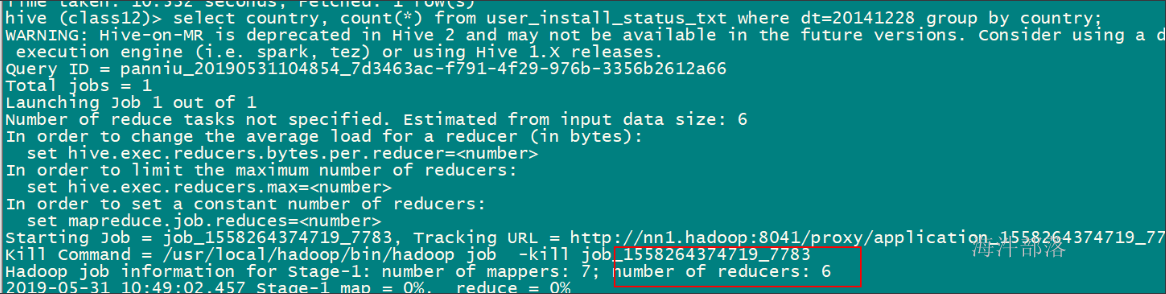
-- 设置每个reduce处理的数据量为500M,查看reduce个数;
set hive.exec.reducers.bytes.per.reducer=524288000;
select country, count(*) from user_install_status_txt where dt=20141228 group by country;
默认情况,执行6个reduce
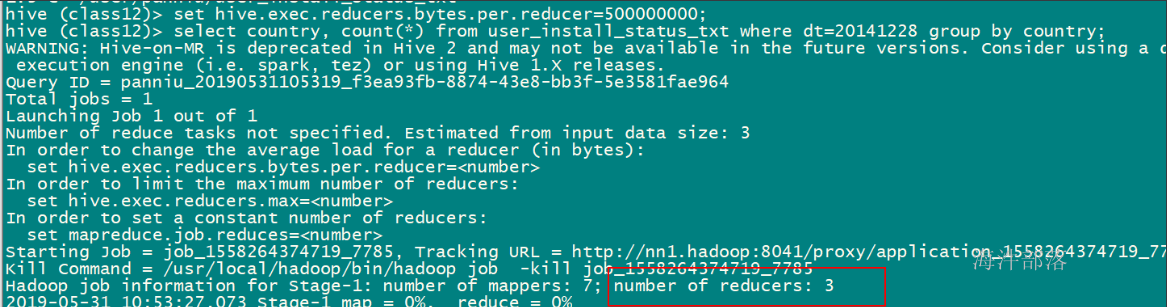
-- 设置每个reduce处理的数据量为500M,查看reduce个数;
set hive.exec.reducers.bytes.per.reducer=500000000;
select country, count(*) from user_install_status_txt where dt=20141228 group by country;
也可以通过直接通过参数来设置reduce个数。
mapred.reduce.tasks (默认是-1,代表hive自动根据输入数据设置reduce个数)
reduce个数并不是越多越好,启动和初始化reduce会消耗时间和资源;另外,有多少个reduce,就会有多少个输出文件,如果生成了很多个小文件,那么如果这些小文件作为下一个任务的输入,则也会出现小文件过多的问题。
6.4 job并行运行设置
带有子查询的hql,如果子查询间没有依赖关系,可以开启任务并行,设置任务并行最大线程数。
hive.exec.parallel (默认是false, true:开启并行运行)
hive.exec.parallel.thread.number (最多可以并行执行多少个作业, 默认是 8)
6.5 小文件的问题优化
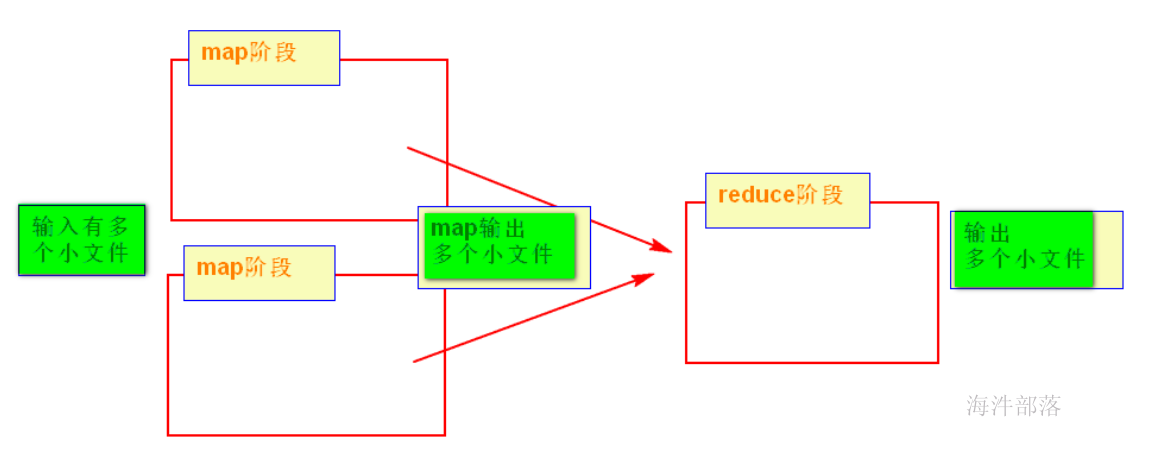
如果小文件多,在map输入时,一个小文件产生一个map任务,这样会产生多个map任务;启动和初始化多个map会消耗时间和资源,所以hive默认是将小文件合并成大文件。
set hive.input.format=org.apache.hadoop.hive.ql.io.CombineHiveInputFormat; (默认)
set hive.input.format=org.apache.hadoop.hive.ql.io.HiveInputFormat;(关闭小文件合并大文件)
如果map输出的小文件过多,hive 默认是开启map 输出合并。
set hive.merge.mapfiles=true (默认是 true)
hive.merge.size.per.task(合并文件的大小,默认 256M)
hive.merge.smallfiles.avgsize(文件的平均大小小于该值时,会启动一个MR任务执行merge,默认16M )
如果reduce输出的小文件过多,hive需要手动设置开启reduce输出合并。
set hive.merge.mapredfiles=true (默认是 false)
hive.merge.size.per.task(合并文件的大小,默认 256M)
hive.merge.smallfiles.avgsize(文件的平均大小小于该值时,会启动一个MR任务执行merge,默认16M )
6.6 join 操作优化
多表join,如果join字段一样,只生成一个job 任务;
Join 的字段类型要一致。
MAP JOIN操作
如果你有一张表非常非常小,而另一张关联的表非常非常大的时候,你可以使用mapjoin此Join 操作在 Map 阶段完成,不再需要Reduce,hive默认开启mapjoin。
-- 将小表刷入内存中,默认是true
set hive.auto.convert.join=true;
set hive.ignore.mapjoin.hint=true;
-- 刷入内存表的大小(字节),根据自己的数据集加大
set hive.mapjoin.smalltable.filesize=2500000;
-- 也可以手动设置 /*+mapjoin(c)+*/SortMergeBucket join
大表和大表join可以优化
6.7 hive的数据倾斜优化
对于mapreduce 计算框架,数据量大不是问题,数据倾斜是个问题。
6.7.1 数据倾斜的原因
1)key分布不均匀
2)业务数据本身的特性
3)某些SQL语句本身就有数据倾斜
| 关键词 | 情形 | 后果 |
|---|---|---|
| Join | 其中一个表较小,但是key集中 | 分发到某一个或几个Reduce上的数据远高于平均值 |
| 大表与大表,但是分桶的判断字段0值或空值过多 | 这些空值都由一个reduce处理,非常慢 | |
| group by | group by 维度过小,某值的数量过多 | 处理某值的reduce非常耗时 |
| Count Distinct | 某特殊值过多 | 处理此特殊值的reduce耗时 |
6.7.2 数据倾斜的表现
任务进度长时间维持在99%(或100%),查看任务监控页面,发现只有少量(1个或几个)reduce子任务未完成。因为其处理的数据量和其他reduce差异过大。
单一reduce的记录数与平均记录数差异过大,通常可能达到3倍甚至更多。 最长时长远大于平均时长。
6.7.3 通用解决方案——参数调节
对于group by 产生倾斜的问题
set hive.map.aggr=true; (默认是 true)
开启map端combiner,减少reduce 拉取的数据量。
set hive.groupby.skewindata=true; (默认是 false)
有数据倾斜的时候进行负载均衡,当选项设定为 true,生成的查询计划会有两个 MR Job。第一个 MR Job 中,Map 的输出结果集合会随机分布到 Reduce 中,每个 Reduce 做部分聚合操作,并输出结果,这样处理的结果是相同的 Group By Key 有可能被分发到不同的 Reduce 中,从而达到负载均衡的目的;第二个 MR Job 再根据预处理的数据结果按照 Group By Key 分布到 Reduce 中(这个过程可以保证相同的 Group By Key 被分布到同一个 Reduce 中),最后完成最终的聚合操作。
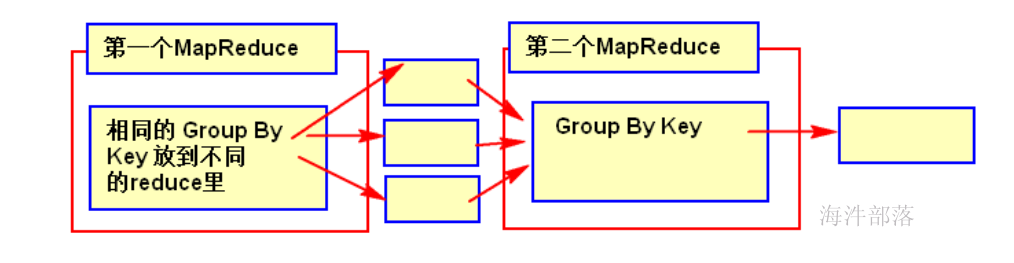
如果开启负载均衡:
执行:
set mapred.reduce.tasks=3;
set hive.groupby.skewindata=true;
select sum(1) as n from
( select country from xinniu.user_install_status group by country) t ;
会有3个MapReduce任务
第一个:select country from user_install_status group by country, 将key放到不同的reduce里
第二个:将第一个任务生成的临时文件,按照key 进行group by,此时,会将数据放到一个reduce里。
第三个:用group by 的中间结果,进行sum。
--------------------------------------------------
通过查看执行计划
1)设置了负载均衡
set hive.groupby.skewindata=true;
explain select sum(1) as n from
( select country from user_install_status_other group by country) t ;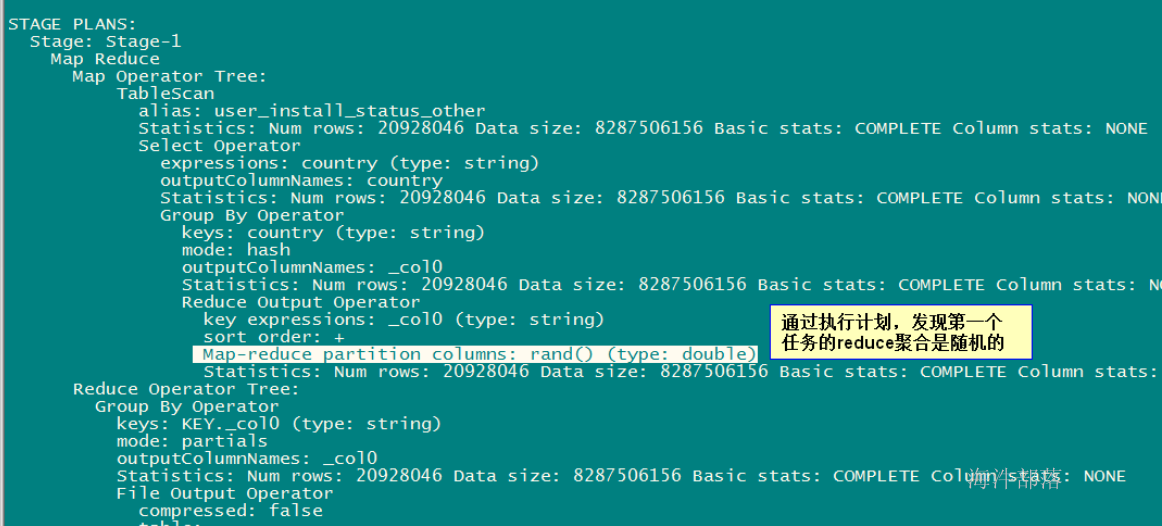
2) 没设置负载均衡
set hive.groupby.skewindata=false;
explain select sum(1) as n from
( select country from user_install_status_other group by country) t ;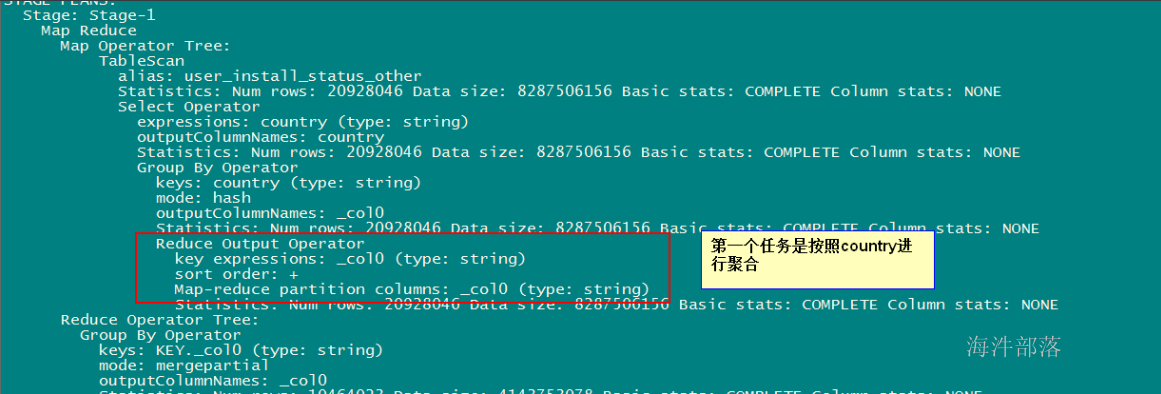
6.7.4 SQL 语句调节
1)大表Join大表:
非法数据太多,比如null。
假设:有表test_a, test_b, 需要执行test_a left join test_b, test_a 表id字段有大量null值。
test_a:总记录数:700多万, id is null 记录数:700万
test_b:总记录数:3条
-- 关闭mapjoin
set hive.auto.convert.join=false;
set hive.ignore.mapjoin.hint=false;
set mapred.reduce.tasks=3;
insert overwrite local directory '/home/xinniu/hive_test/06/output1'
SELECT * FROM test_a a
left JOIN test_b b
ON a.id=b.id 上面的SQL会将所有的null值分到一个reduce里。
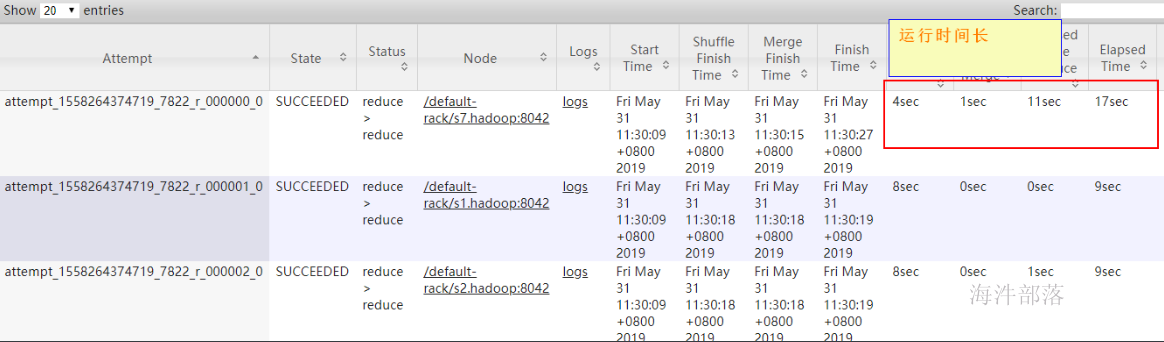
也可以通过导出的文件判断

下面有两种解决方案:
1)假如null值没有用处的话,可以将null值先过滤掉,再进行 union

set hive.auto.convert.join=false;
set hive.ignore.mapjoin.hint=false;
set mapred.reduce.tasks=3;
insert overwrite local directory '/home/xinniu/cz45/outputdemo2'
select t.id aid,t.name aname, b.id bid,b.name bname from
(select * from test_a a where a.id is not null) t
left join test_b b
on t.id = b.id
UNION All
SELECT a1.id aid, a1.name aname,null bid,null bname FROM test_a a1 WHERE a1.id IS NULL;执行该SQL时,要多生成null 的id,这样在reduce运行时间能看出来某个reduce运行时间过长
运行两个任务, 第一个任务: 刨除 id is not null 和 test_b join
第二个任务: 把id is null 的部分和 第一个任务的结果进行union all
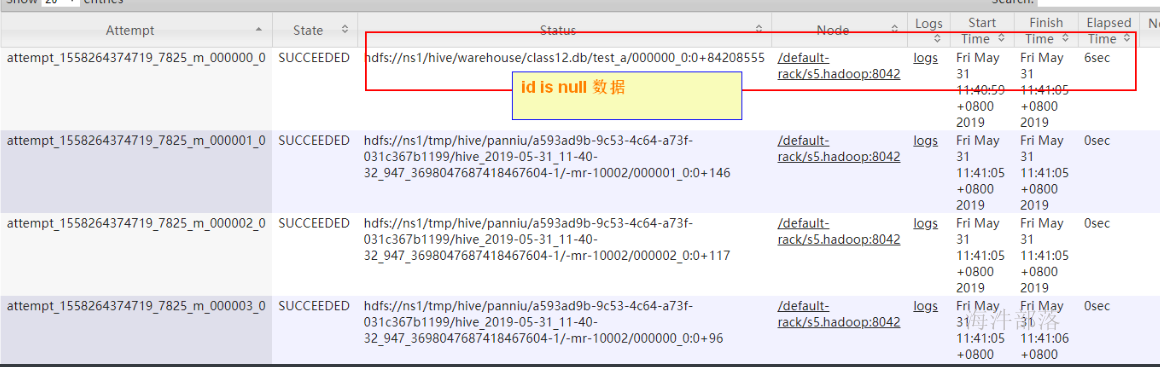
2)把空值的key变成一随机数(随机值类型需要跟key的类型一致),把倾斜的数据分到不同的reduce上,由于null值关联不上,处理后并不影响最终结果。
set hive.auto.convert.join=false;
set hive.ignore.mapjoin.hint=false;
set mapred.reduce.tasks=3;
insert overwrite local directory '/home/xinniu/cz45/outputdemo3'
SELECT * FROM test_a a
LEFT JOIN
test_b b
ON
CASE WHEN a.id IS NULL THEN ceiling(rand() * 100 + 100) ELSE a.id END =b.id;
mr 自定义partition(mr的)
分reduce按照 hash(ceiling(rand() * 100 + 100)) % reduce个数, 直接把 null 分到对应的reduce里
注意事项:
随机生成的值 不能 和 b.id join上。reduce执行时间相对平均
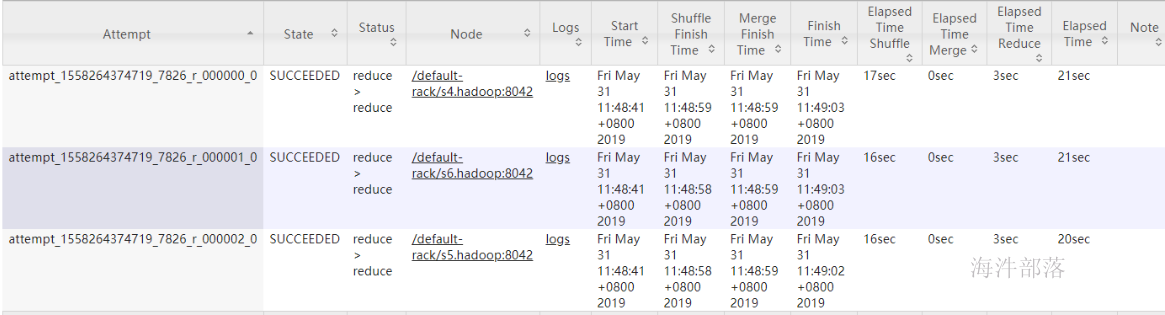
通过产生的文件数据,reduce处理的数据也比较均衡

注意:join的字段类型一定要一致,否则数据不会分到不同的reduce上。
ceiling(rand() * 100) ----------> CONCAT('hainiu',RAND())
set hive.auto.convert.join=false;
set hive.ignore.mapjoin.hint=false;
set mapred.reduce.tasks=3;
insert overwrite local directory '/home/xinniu/cz45/outputdemo4'
SELECT * FROM test_a a
LEFT JOIN
test_b b
ON
CASE WHEN a.id IS NULL THEN CONCAT('hainiu',RAND()) ELSE a.id END =b.id; 由于join字段类型不同,导致数据不会分到不同的reduce上。


解决方法2比解决方法1效果更好,不但IO少了,而且作业数也少了。解决方法1中test_a读取两次,job 数为2。解决方法2中 job 数是1。这个优化适合无效 id(比如-99、 ‘’,null 等)产生的倾斜问题。把空值的 key 变成一个字符串加上随机数,就能把倾斜的 数据分到不同的Reduce上,从而解决数据倾斜问题。
2)count distinct 数据倾斜
在执行下面的SQL时,即使设置了reduce个数也没用,它会忽略设置的reduce个数,而强制使用1。这唯一的Reduce Task需要Shuffle大量的数据,并且进行排序聚合等处理,这使得它成为整个作业的IO和运算瓶颈。
set mapred.reduce.tasks=3;
-- 关闭负载均衡
set hive.groupby.skewindata=false;
select count (distinct country) from user_install_status_limit;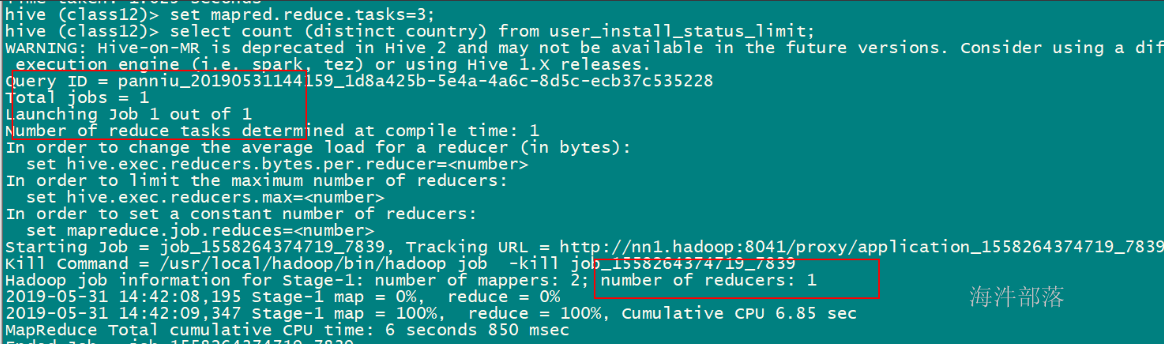
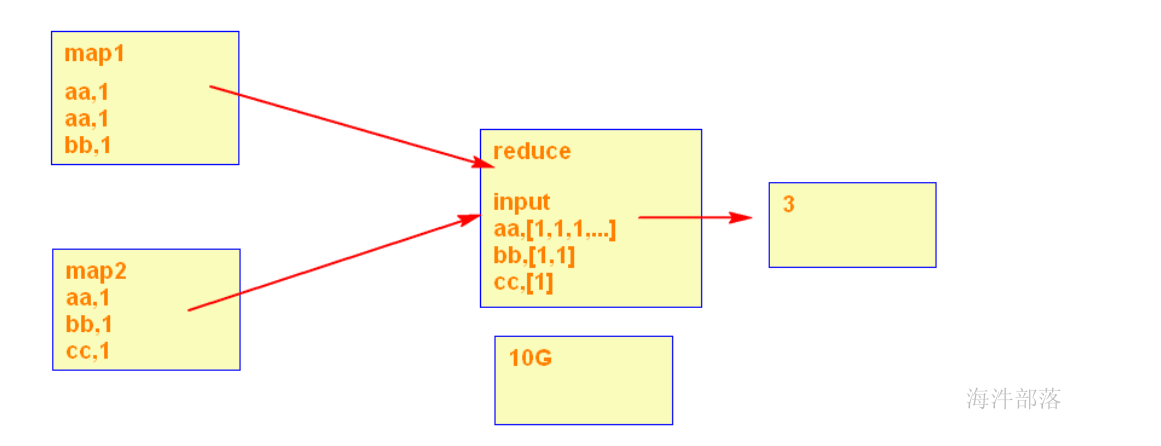
优化方案:
设置多个reduce时,在reduce阶段可以多个reduce处理数据,而不是只有一个reduce处理数据。
set mapred.reduce.tasks=3;
select count(*) from (select country from user_install_status_limit group by country)t;
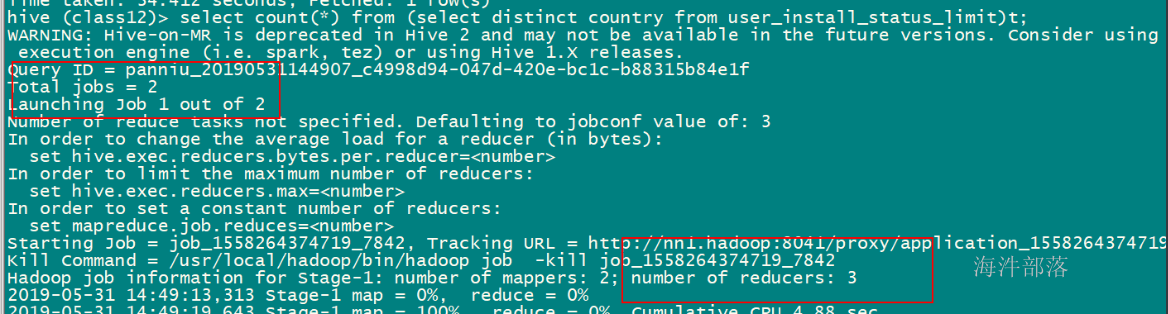
或
select count(*) from (select distinct country from user_install_status_limit)t;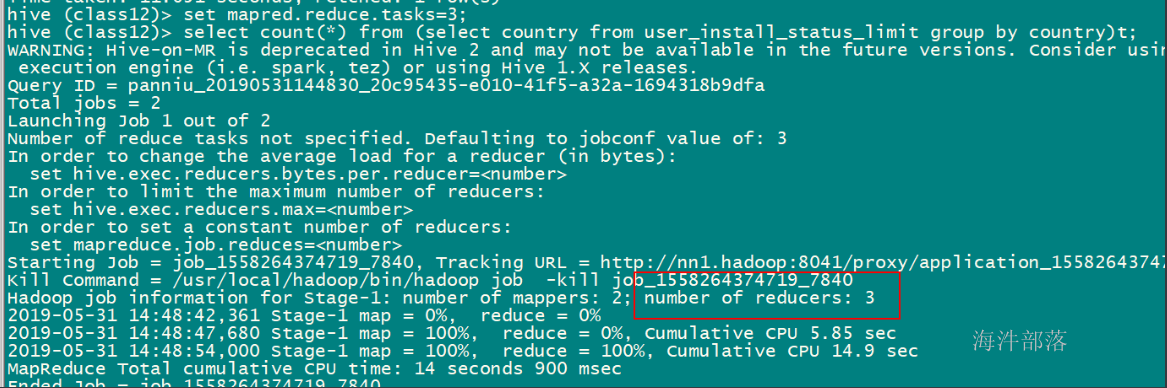
多个count distinct 优化
-- 优化前
set mapred.reduce.tasks=3;
select count(distinct country), count(distinct pkgname) from user_install_status_limit;
--优化后
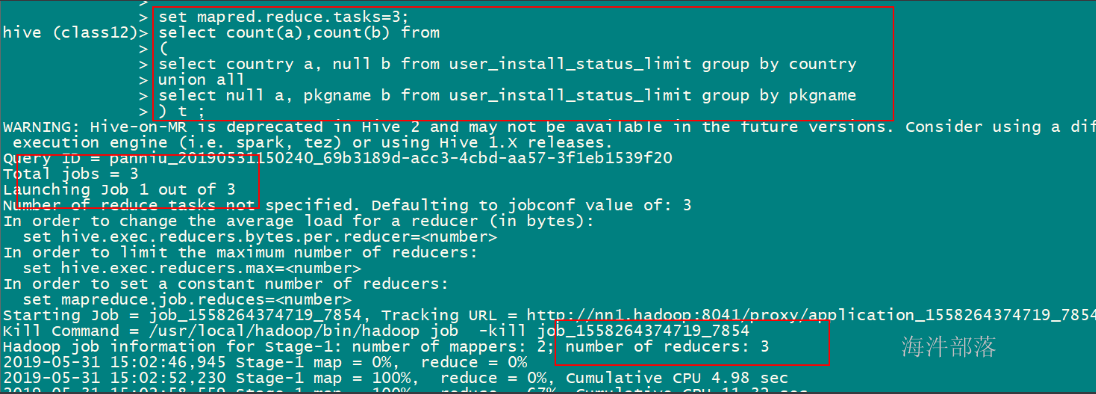
set mapred.reduce.tasks=3;
select count(a),count(b) from
(
select country a, null b from user_install_status_limit group by country
union all
select null a, pkgname b from user_install_status_limit group by pkgname
) t ;
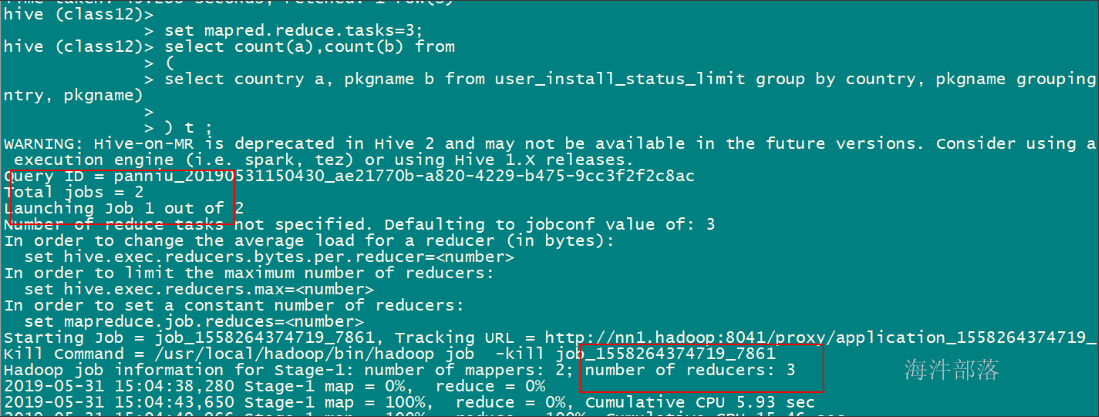
-- 通过grouping sets 替换union
-- 要想使用grouping sets,要开启hive的map端combiner(hive默认开启)
set hive.map.aggr=true;
set mapred.reduce.tasks=3;
select count(a), count(b) from
(select country a,pkgname b from user_install_status_limit group by country,pkgname grouping sets(country, pkgname))
t;优化后SQL的逻辑
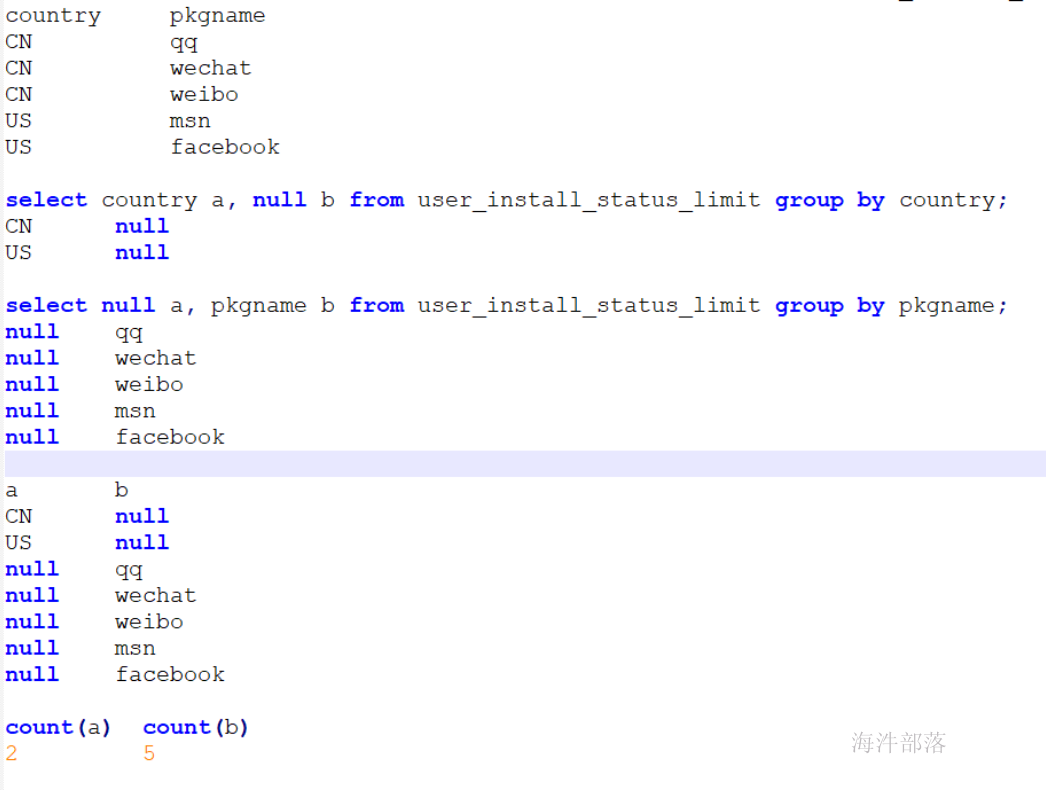
设置3reduce,生成3个reduce
----------------------------
用grouping sets 优化后,设置3reduce,生成3个reduce,减少了任务数
7 集群运行模式
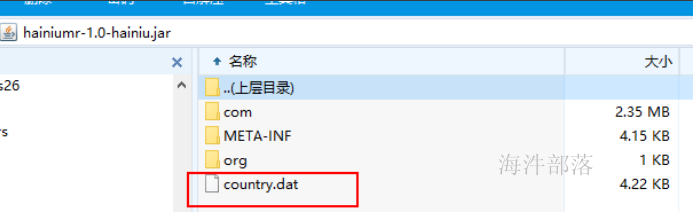
1)首先给项目打成jar包;
打包时,要把国家码翻译成国家名的文件加进去,放在jar包的根目录下
2)进入hive控制台,然后使用add jar把刚才打的jar包添加进去;
#格式
add jar [local_jar_path];
#实例
add jar /home/hadoop/hive_function/hive-1.0-hainiu.jar;

3)加载并使用自定义函数
如果上传的jar包运行时报错,当你修改完再次上传时,要重启hive客户端,再重新添加jar,运行。
在集群上同时测试自己定义的UDF和UDAF。
--先上传jar包,然后在hive控制台执行下面语句
add jar /home/xinniu/hive_test/06/hainiumr-1.0-hainiu.jar;
-- 创建国家码转国家名称的函数
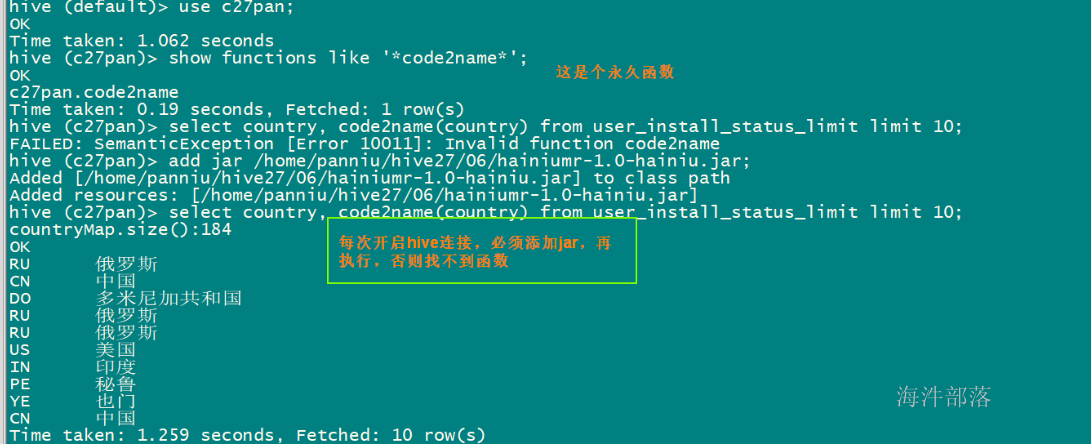
CREATE TEMPORARY FUNCTION code2name AS 'com.hainiu.hive.function.CountryCode2CountryNameUDF';
-- 查询验证
select country, code2name(country) name from user_install_status_limit limit 10;
-- 创建 自定义suma 函数
CREATE TEMPORARY FUNCTION suma AS 'com.hainiu.hive.function.SumUDAF';
-- 查询验证
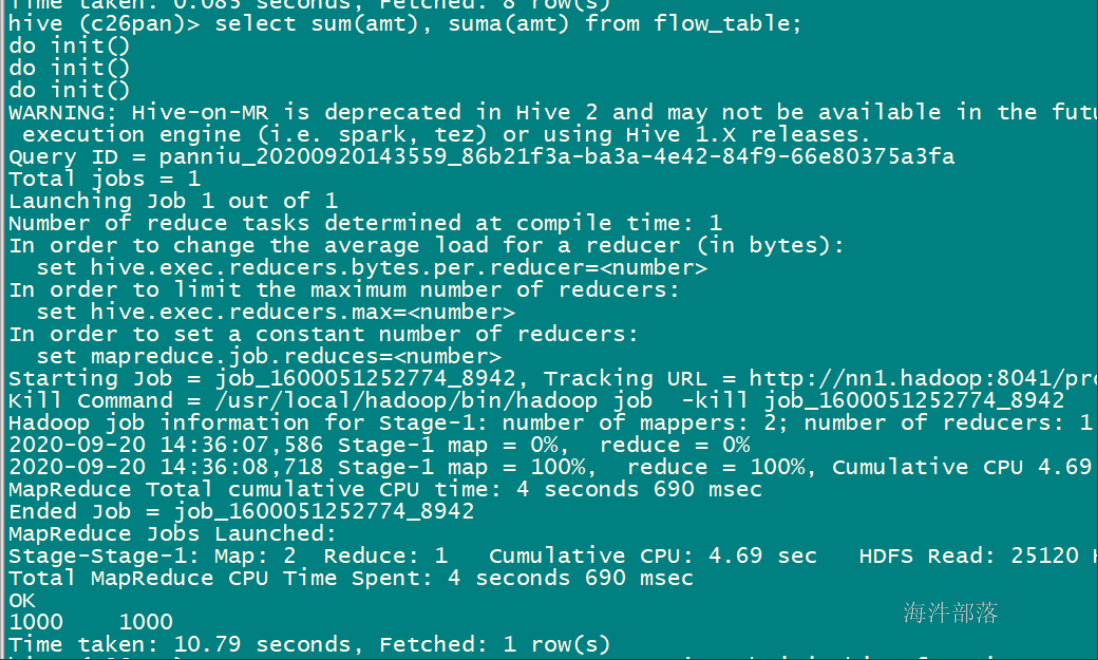
select suma(amt), sum(amt) from flow_table;
-- 创建 自定义 avg 函数
CREATE TEMPORARY FUNCTION avga AS 'com.hainiu.hive.function.AvgUDAF';
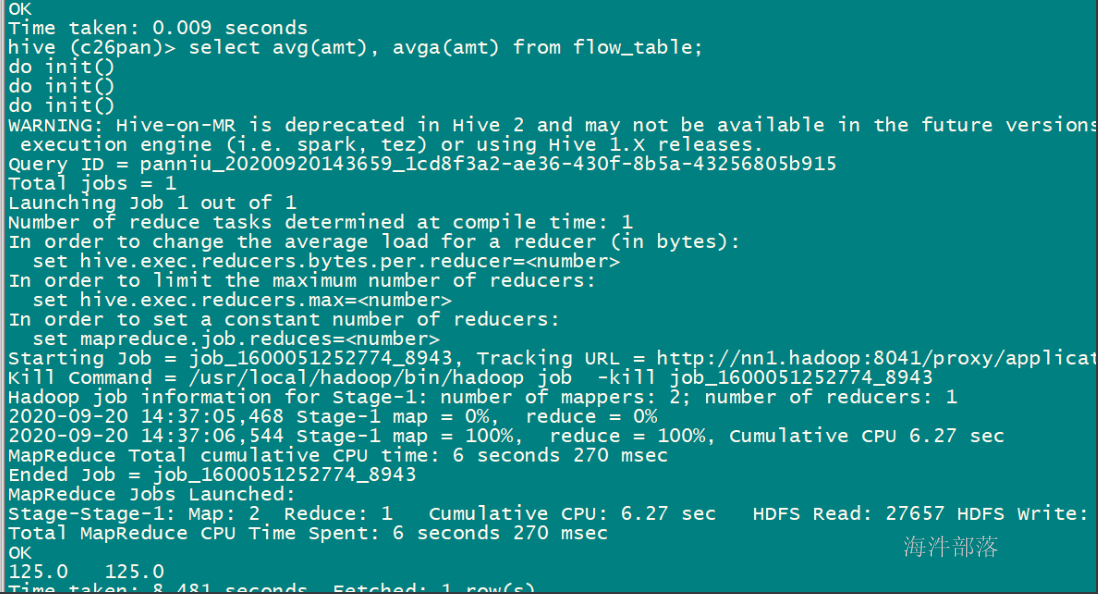
-- 查询验证
select avga(amt), avg(amt) from flow_table;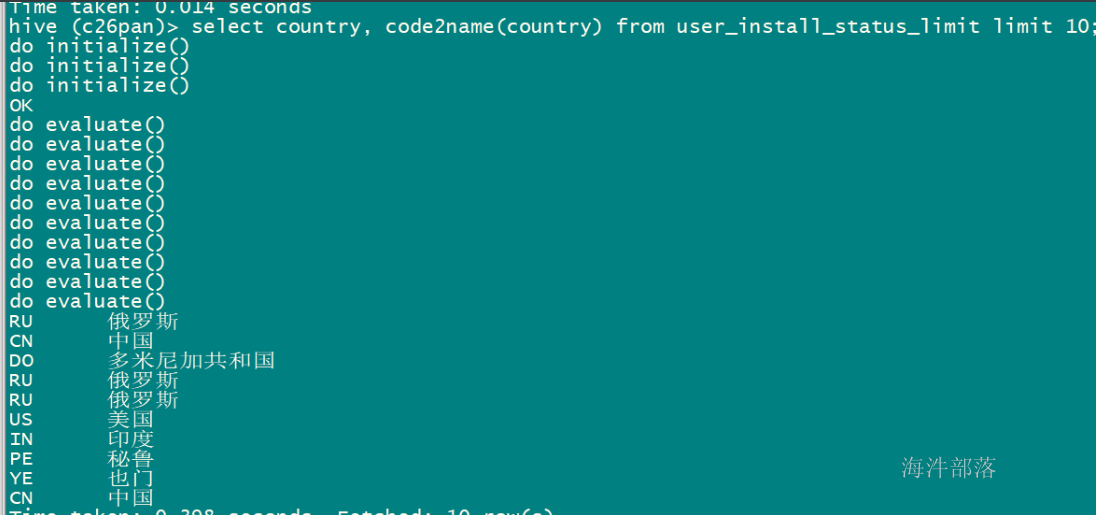
注意: