1 mapreduce 概述
1.1mapreduce介绍
- MapReduce是一种分布式计算模型
- 由谷歌提出,基于GFS进行设计,主要用于搜索领域中解决海量数据的计算问题
- Doug Cutting根据《MapReduce: Simplified Data Processing on Large Clusters》设计实现了Hadoop中基于HDFS的MapReduce
- MapReduce是由两个阶段组成:Map和Reduce,用户只需要实现map以及reduce两个函数,即可实现分布式计算,这样做的目的是简化分布式程序的开发和调试周期
- JobTracker/ResourceManager:任务调度者,管理多个TaskTracker。ResourceManager是Hadoop2.0版本之后引入Yarn之后用于替代JobTracke部分功能的机制
- TaskTracker/NodeManager:任务执行者
1.2为什么需要mapreduce?
1)海量数据在单机上处理因为硬件资源限制,无法胜任;
2)将单机版程序扩展到集群来分布式运行,极大增加程序的复杂度和开发难度;
3)引入 MapReduce 框架后,开发人员可以将绝大部分工作集中在业务逻辑的开发上,而将 分布式计算中的复杂性交由框架来处理;
1.3 mapreduce是做什么的?
mapreduce的核心思想:\化大为小,**分而治之。**
mapreduce 的主要组成部分:Mapper 和 Reducer。
Mapper: 负责“分”,即把复杂的任务分解为若干个“简单的任务”来处理。
Reducer: 负责对map阶段的结果进行汇总。
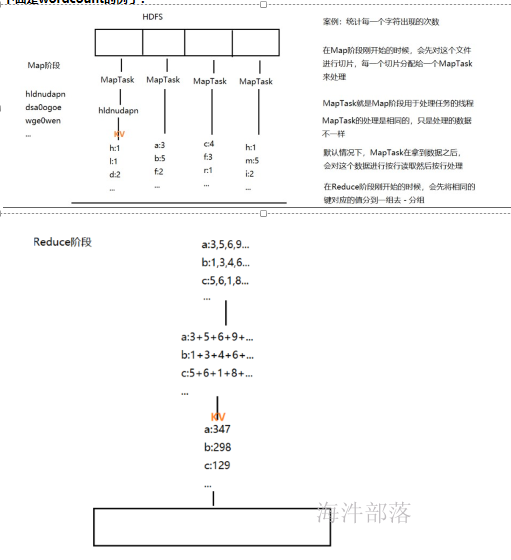
1.4 mapper和reducer阶段分别解决什么样的问题?
mapper阶段:
是把输入变成Key,Value结果,用于reducer的输入。 mapper内部是局部有序;
reducer 阶段:
把多个Mapper输出的数据汇总的Reducer,并按照Mapper输出的key分组进行汇总,全局有序(一个reduce的情况) 。
下面是单词wordcount的例子:
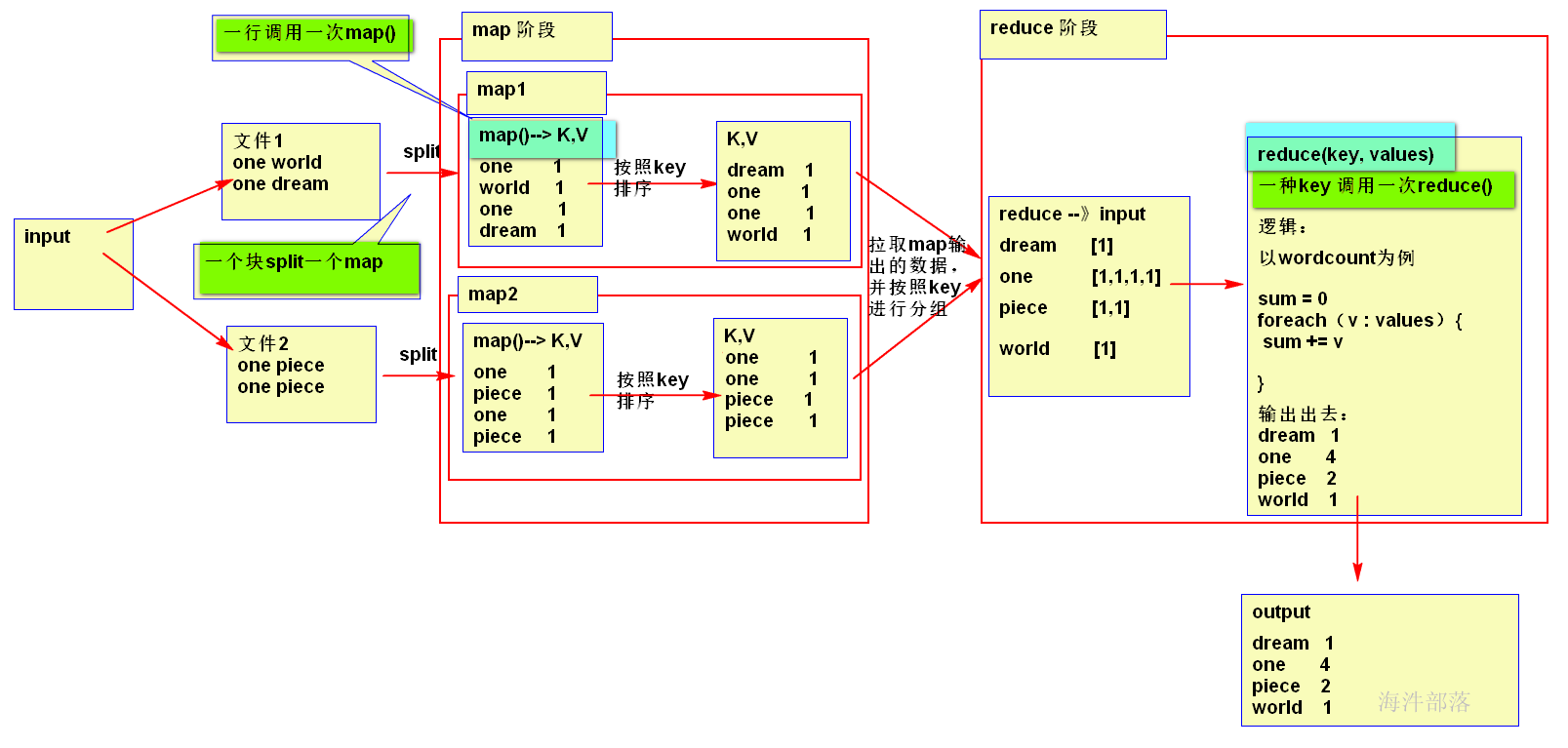
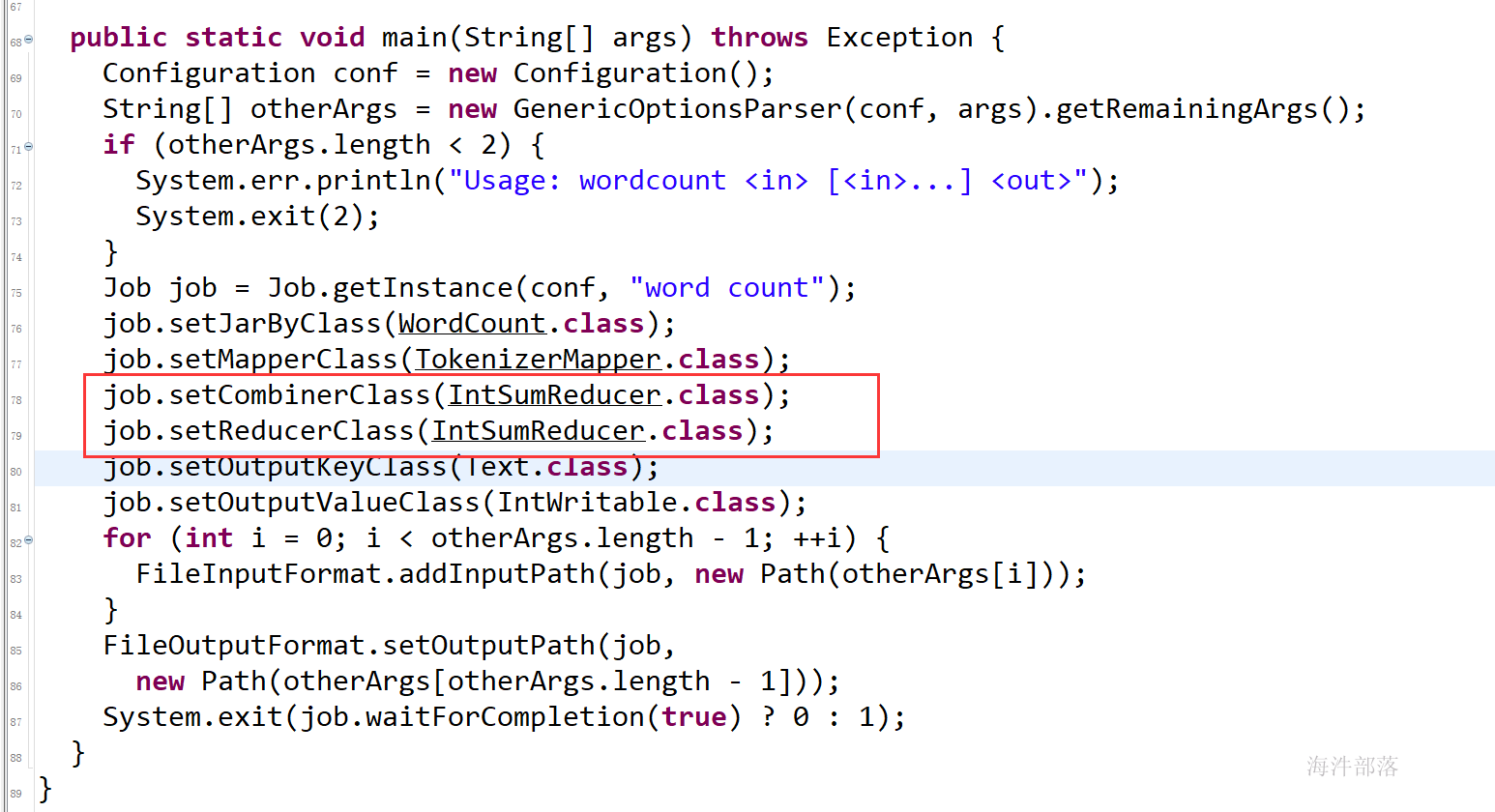
2 写mapreduce程序实现上面的wordcount
2.1安装软件、配置开发环境
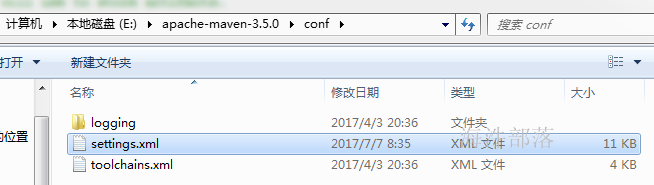
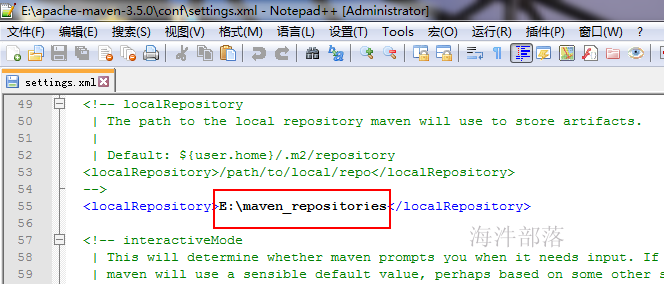
2.1.1 修改maven配置使用阿里提供的maven源
替换settings.xml为阿里maven源,并修改其maven仓库地址
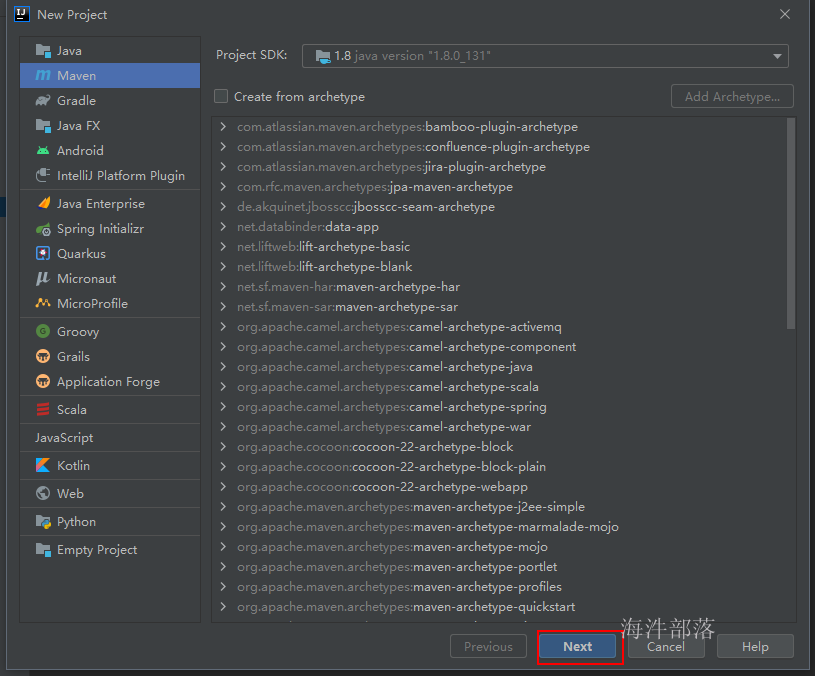
2.1.2 创建maven工程
选择maven工程,配置jdk,点next
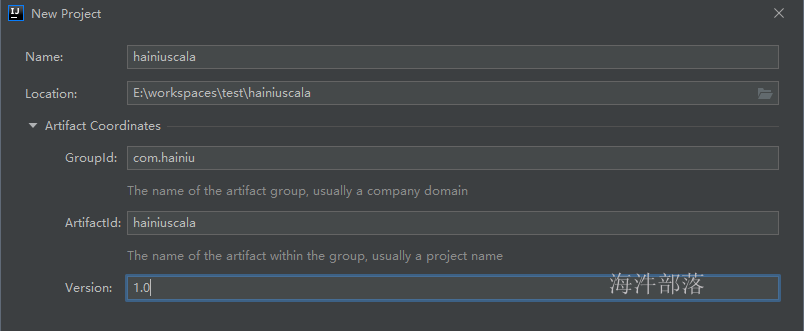
点击 finish 完成工程创建。
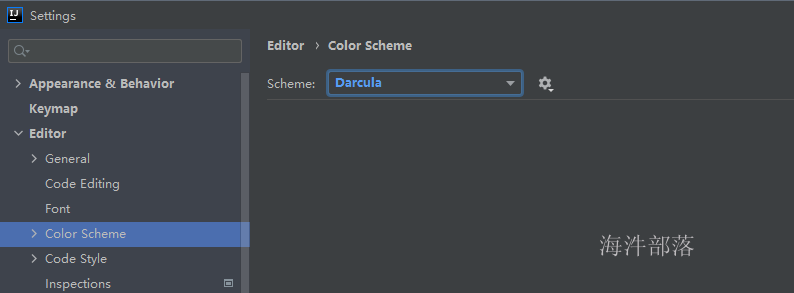
2.1.3 修改idea 主题样式和字体样式
修改idea 主题样式
修改字体样式
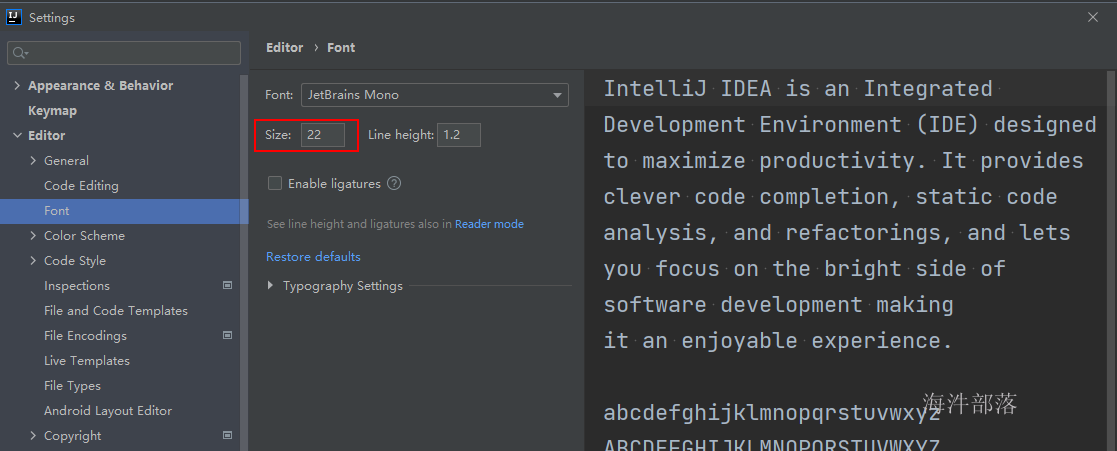
2.1.4 配置maven
2.1.5 修改快捷键
可根据自己喜好更改。
2.1.6 创建代码目录
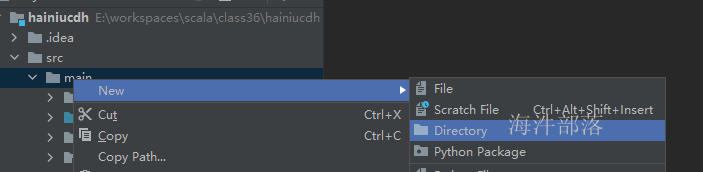
新建的目录,只是一个纯粹的目录,还需要修改成代码目录,修改方式如下
1)右键要修改的目录 → Mark directory as → Sources Root
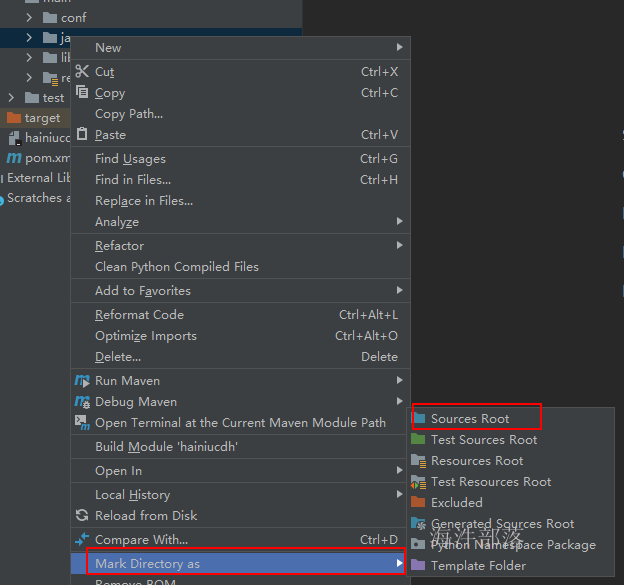
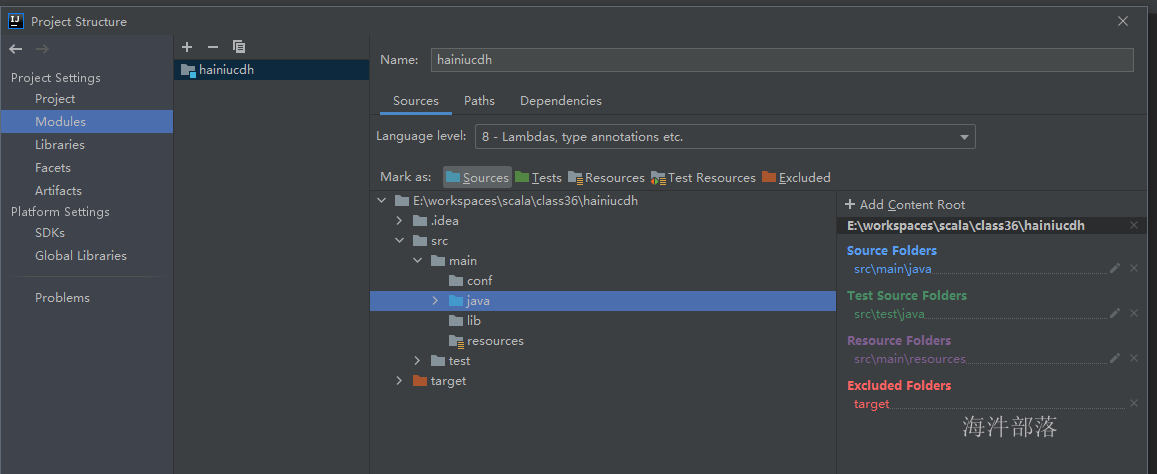
2)File → Project Structure... → Modules
或 右键工程 → Open Module Settings
2.1.7 通过maven增加hadoop-client
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.3</version>
</dependency>2.2 写MapReduce程序
2.2.1 写mapreduce程序的顺序
1)自定义的mapreduce类
2)继承Mapper类,实现map函数
3)继承Reducer类,实现reduce函数
4)main()中设置Job相关信息 和 提交Job运行
2.2.2 引用类时要注意
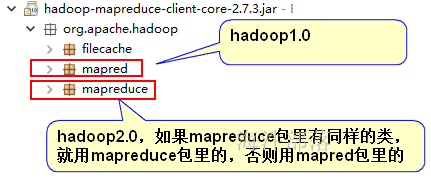
2.2.3 程序代码
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import java.io.IOException;
public class WordCount {
/*
* KEYIN, VALUEIN
* 用来读文件的,一行一行读,
* one world---》 0, one world
* one dream---》11, one dream
*
* KEYIN:行字节偏移量---》 long类型存 -----》 Hadoop自带的 LongWritable, 里面是long类型
* VALUEIN: 一行的字符串 ----》String类型-----》 Hadoop自带的Text, 里面是String类型
*
* KEYOUT, VALUEOUT
* mapper输出啥取决于业务需求
* 需求:按照单词统计数量
* 按照什么,什么就是mapper输出的key
* 统计的数量是什么,什么就是mapper输出的value(但也不是绝对的)
*
* KEYOUT:单词 ----》String类型-----》 Hadoop自带的Text, 里面是String类型
* VALUEOUT:数值 ---》 long类型存 -----》 Hadoop自带的 LongWritable, 里面是long类型
*
*/
public static class WordCountMapper extends Mapper<LongWritable, Text, Text, LongWritable> {
/**
* 单词
*/
Text keyOut = new Text();
/**
* 数值
*/
LongWritable valueOut = new LongWritable();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
System.out.println("mapper input==>" + key.get() + ", " + value.toString());
// 获取一行的字符串
// one world
String line = value.toString();
// one, world
String[] arr = line.split("\t");
for(String word : arr){
keyOut.set(word);
valueOut.set(1);
// 通过该方法输出数据 one,1
context.write(keyOut, valueOut);
System.out.println("mapper output==>" + keyOut.toString() + ", " + valueOut.get());
}
}
}
/*
* reducer的KEYIN, VALUEIN 和 mapper输出的 KEYOUT, VALUEOUT 类型一致
* KEYIN:单词 ----》String类型-----》 Hadoop自带的Text, 里面是String类型
* VALUEIN:数值 ---》 long类型存 -----》 Hadoop自带的 LongWritable, 里面是long类型
*
*
* KEYOUT, VALUEOUT
* reducer输出啥取决于业务需求
* 统计单词的数量
* KEYOUT:单词 ----》String类型-----》 Hadoop自带的Text, 里面是String类型
* VALUEOUT:数值---》 long类型存 -----》 Hadoop自带的 LongWritable, 里面是long类型
*
*/
public static class WordCountReducer extends Reducer<Text, LongWritable, Text, LongWritable> {
LongWritable valueOut = new LongWritable();
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context)
throws IOException, InterruptedException {
// one, [1,1,1,1] ---> one,4
long sum = 0L;
StringBuilder sb = new StringBuilder("reducer input==>");
sb.append(key).append(", [");
for(LongWritable w : values){
sb.append(w.get()).append(",");
sum += w.get();
}
sb.deleteCharAt(sb.length()-1).append("]");
System.out.println(sb.toString());
valueOut.set(sum);
context.write(key, valueOut);
System.out.println("reducer output==>" + key + ", " + sum);
}
}
// /tmp/mr/input /tmp/mr/output
public static void main(String[] args) throws Exception {
// 加载 core-default.xml 和 core-site.xml
Configuration conf = new Configuration();
// 创建运行mapreduce任务的Job对象
Job job = Job.getInstance(conf, "wordcount");
// 设置运行的类(linux 运行用)
job.setJarByClass(WordCount.class);
// 设置mapperclass
job.setMapperClass(WordCountMapper.class);
// 设置reducerclass
job.setReducerClass(WordCountReducer.class);
// 设置reducer个数, 不设置默认是1
job.setNumReduceTasks(1);
// 设置mapper输出keyclass
job.setMapOutputKeyClass(Text.class);
// 设置mapper输出valueclass
job.setMapOutputValueClass(LongWritable.class);
// 设置reducer输出keyclass
job.setOutputKeyClass(Text.class);
// 设置reducer输出的valueclass
job.setOutputValueClass(LongWritable.class);
// 设置读取的输入文件的inputformatclass,默认是文本,可以不设置
job.setInputFormatClass(TextInputFormat.class);
// 设置写入文件的outputformatclass,默认是文本,可以不设置
job.setOutputFormatClass(TextOutputFormat.class);
// 设置输入目录
FileInputFormat.addInputPath(job, new Path(args[0]));
Path outputPath = new Path(args[1]);
// 设置输出目录
FileOutputFormat.setOutputPath(job, outputPath);
// 自动删除输出目录
FileSystem fs = FileSystem.get(conf);
// 如果输出目录存在,就递归删除输出目录
if(fs.exists(outputPath)){
// 递归删除输出目录
fs.delete(outputPath, true);
System.out.println("delete outputPath==> 【" + outputPath.toString() + "】 success!");
}
// 提交job
boolean status = job.waitForCompletion(false);
System.exit(status ? 0 : 1);
}
}2.2.4 运行任务查看任务结果
输入数据:
f1.txt:

f2.txt:

设置程序执行参数
# 如果你的工程和测试数据在同一个盘符
/tmp/mr/input /tmp/mr/output
# 如果你的工程和测试数据不在同一个盘符
e:/tmp/mr/input e:/tmp/mr/output
file:/e:/tmp/mr/input file:/e:/tmp/mr/outputrun ---> Edit Configurations. 进入设置参数界面
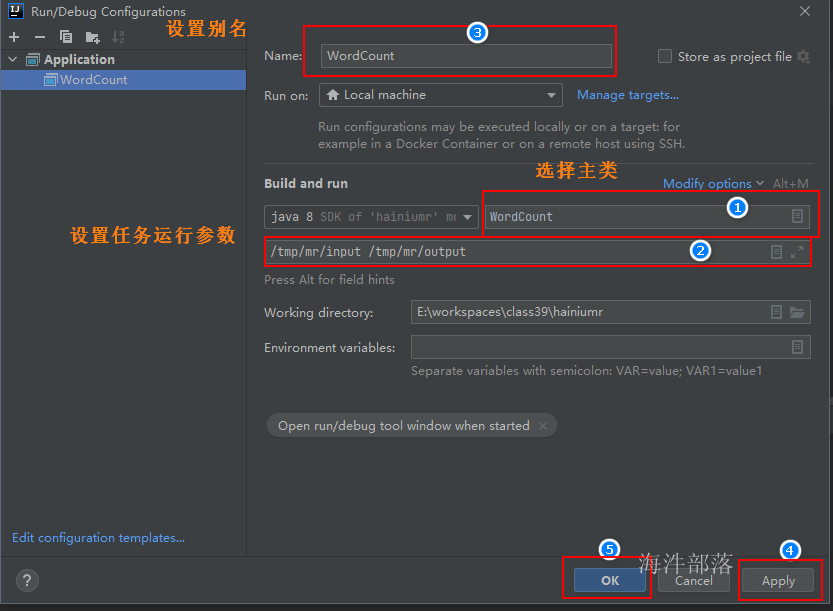
注意: 输出目录一定要写指定具体路径。
输出目录:
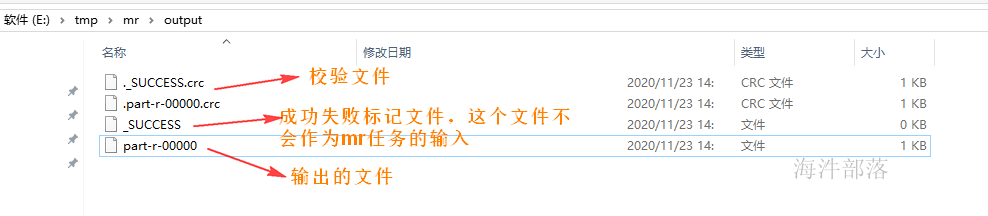
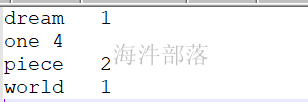
输出数据:
2.2.5 增加\自动删除目录方法****


注意:
由于在mapredue任务执行前需要删除输出目录,设置输出目录参数时,一定要慎重。
2.2.6 增加log4j支持
拷贝下面的log4j.properties文件到新建的resources资源文件夹里
#设定控制台和指定目录日志都按照info级别来打印输出
log4j.rootLogger=info,console,HFILE1
#日志输出到指定目录
log4j.appender.HFILE=org.apache.log4j.RollingFileAppender
#输出路径自己设置
log4j.appender.HFILE.File=/opt/hainiu_hadoop_logs/log.log
log4j.appender.HFILE.MaxFileSize=30mb
log4j.appender.HFILE.MaxBackupIndex=20
log4j.appender.HFILE.layout=org.apache.log4j.PatternLayout
log4j.appender.HFILE.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss} %p %l %t %r %c: %m%n
#日志输出到控制台
log4j.appender.console=org.apache.log4j.ConsoleAppender
log4j.appender.console.target=System.out
log4j.appender.console.layout=org.apache.log4j.PatternLayout
log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c %M(): %m%n如何debug:
F3: 进入类、方法里面
F6: 执行一行语句
F8: 一直运行,直到遇到断点停下;如果没有断点,就一直运行到程序结束;
3 Mapreduce 原理
3.1 map任务的输入文件是怎么分割的
为什么要讲这个知识点?
mapreduce中生成多少个MapTask是由输入文件的输入分片决定的,有多少输入分片,就会生成多少MapTask。
输入文件分片方法:
1)首先查看输入文件的压缩格式是否支持split,如果不支持,则一个文件对应一个split;
2)如果支持split,会默认按照一个hdfs块大小对应一个split。
3)如果文件剩余块大小/分块大小>1.1,那会生成两个split;
如果文件剩余大小/splitsize<=1.1,剩余的部分作为一个split。
MapReduce 通过 org.apache.hadoop.mapreduce.InputSplit 类提供数据切片方法(抽象类)。
1)文件个数
2)文件是否支持split
3)hdfs块大小
4)1.1 的系数
在 org.apache.hadoop.mapreduce.lib.input.FileInputFormat 这个类中有一个神奇的参数 :
private static final double SPLIT_SLOP = 1.1; // 10% slop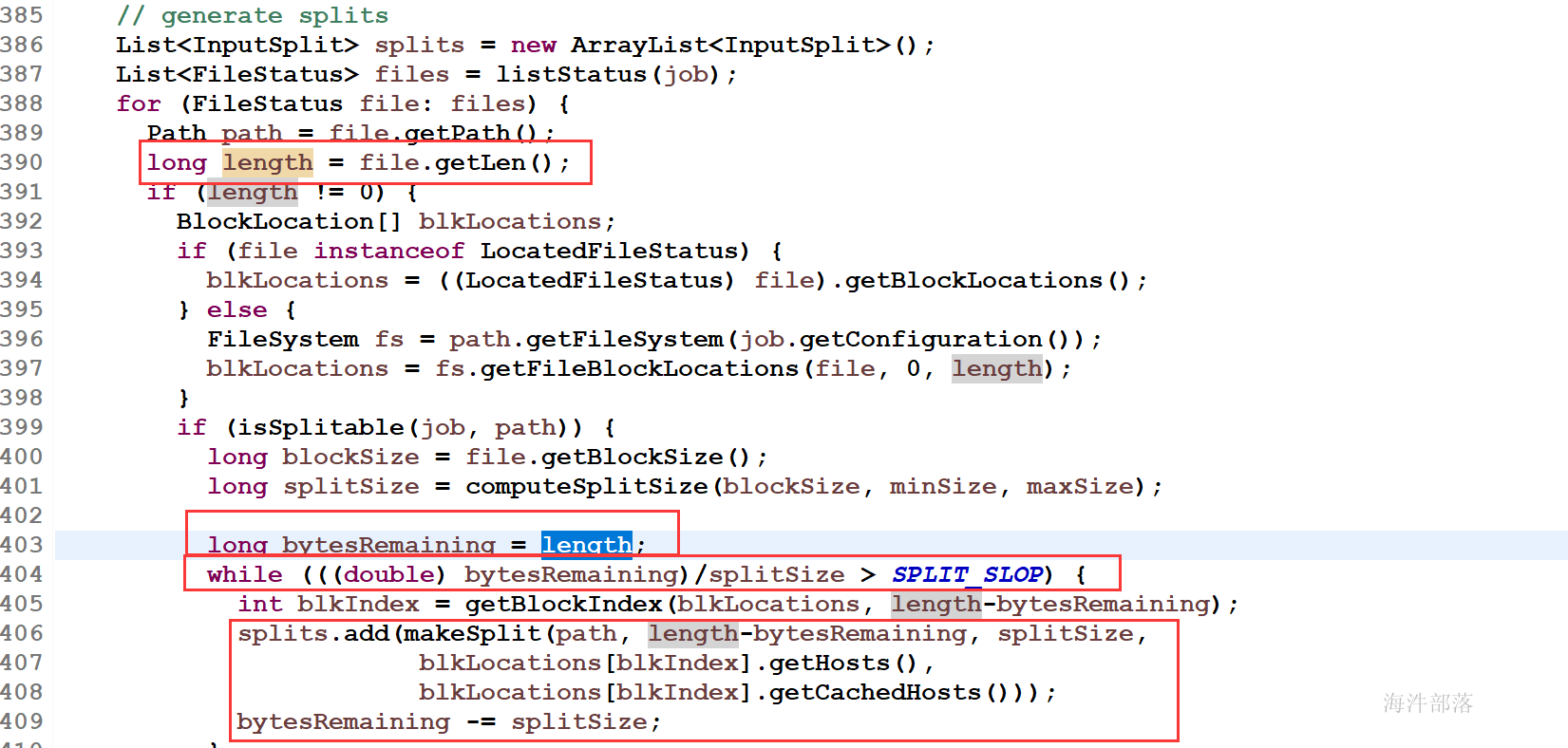
一个练习分片的例子:
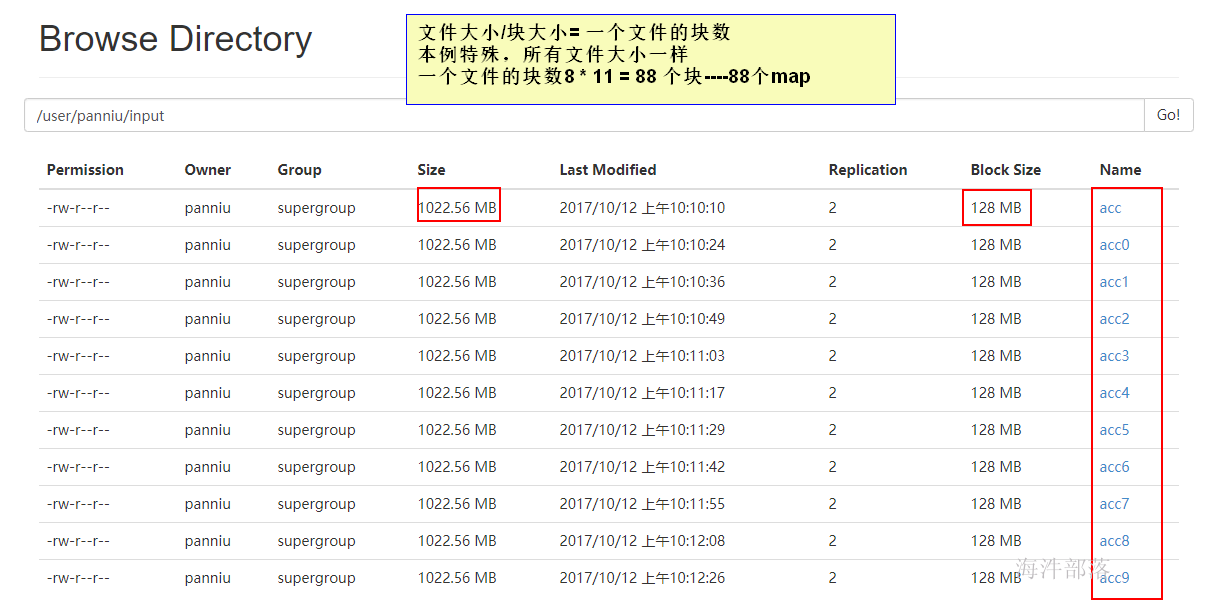
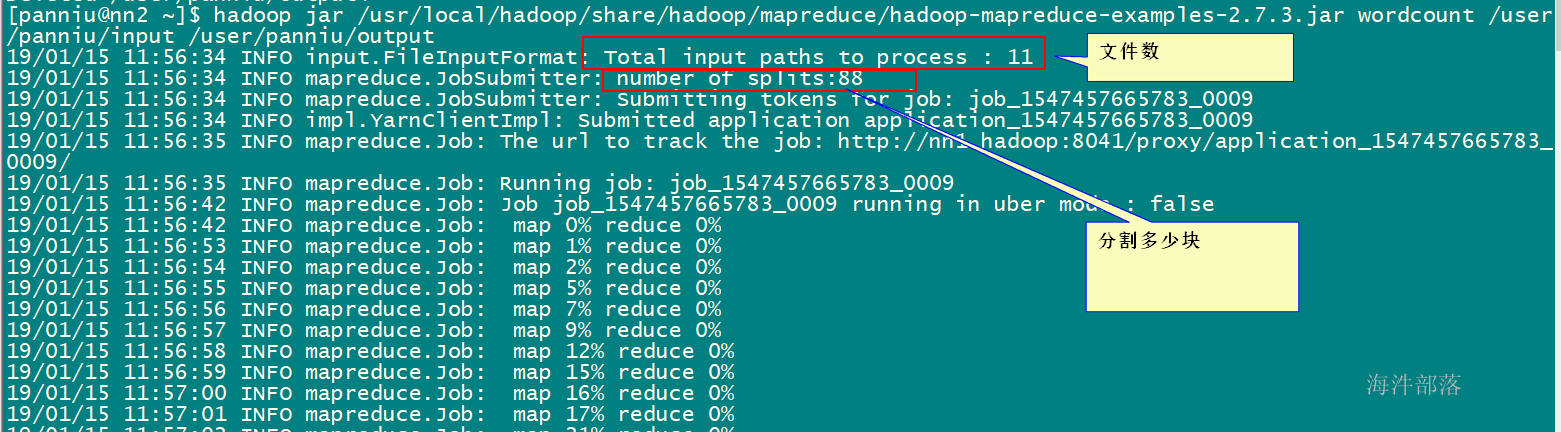
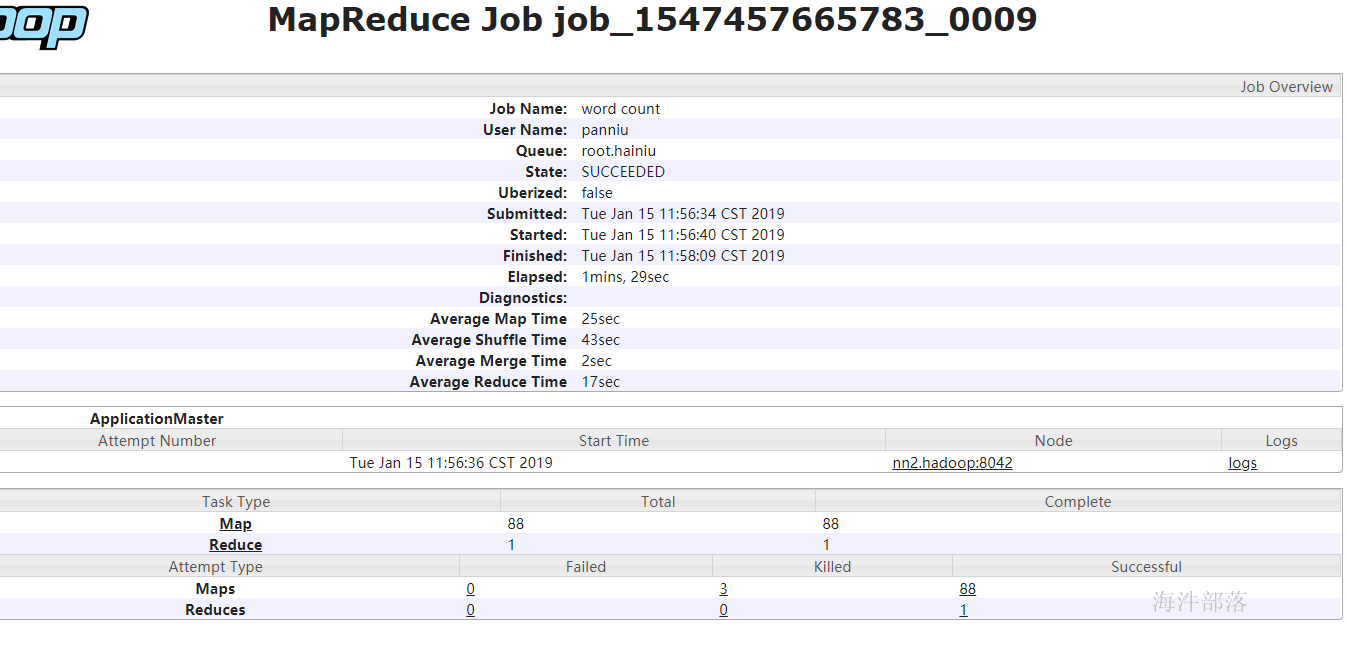
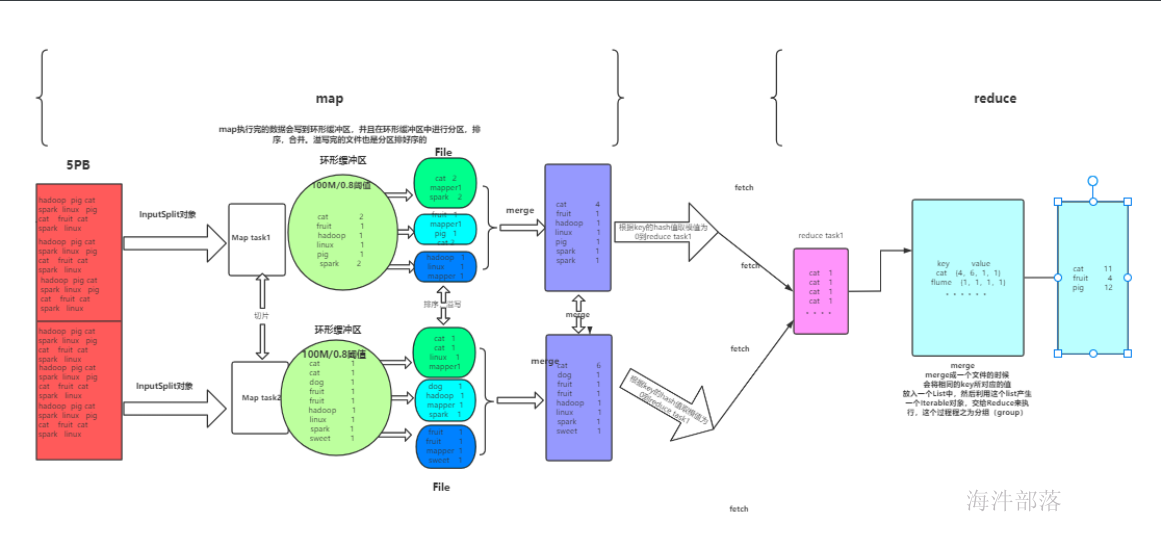
3.2 shuffle 过程
一个Reducer的情况
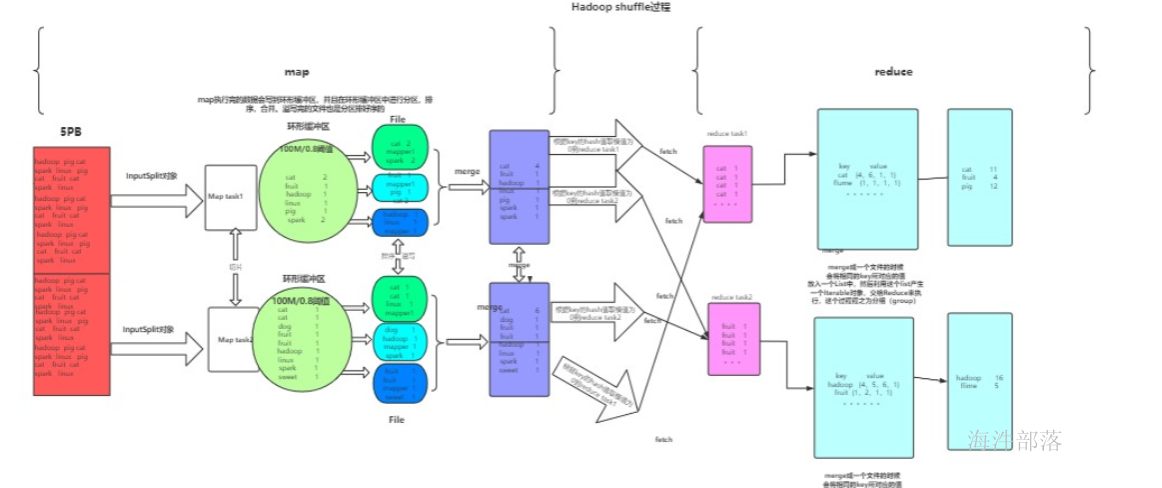
多个Reducer的情况(2个为例)
3.3 Partition的问题
3.3.1 partition的个数是怎么决定的
partition的数量是通过reducer的数量决定的。
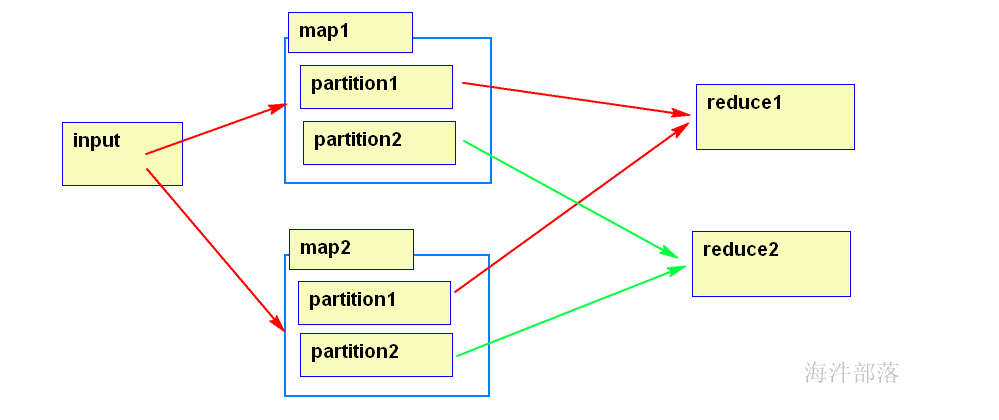
3.3.2 如何确定哪些数据写入哪个Partition?
按照map()输出的 key 的 hash 值 % reducer数量 来分,也就是默认使用的是HashPartitioner,可根据业务自行实现partition。
默认的HashPartitioner

假设:reduce数量是2
partitionId = key的hash值% reduce的数量
partitionA = key的hash值尾数是0
partitionB = key的hash值尾数是1
如果reduce数量是3
partitionA = key的hash值尾数是0
partitionB = key的hash值尾数是1
partitionC = key的hash值尾数是2
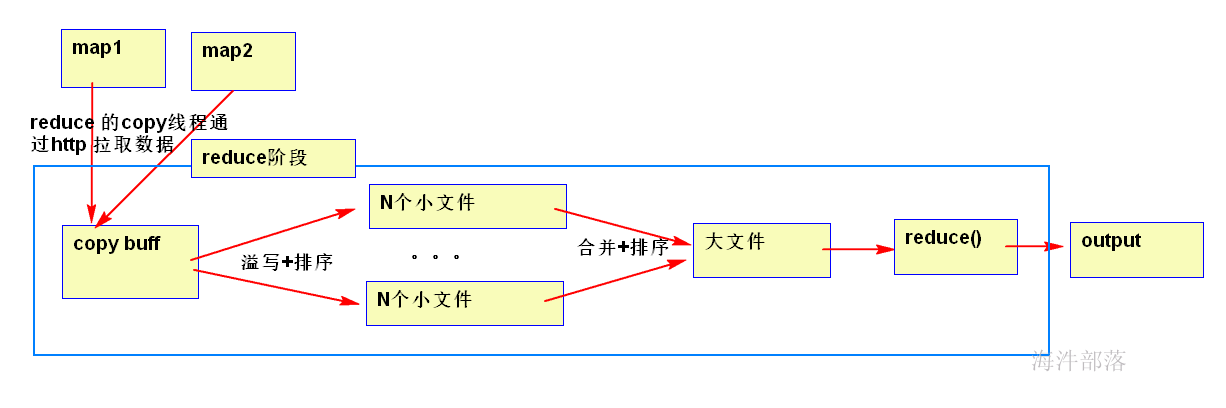
3.4 Reducer 阶段做了什么
一个reducer情况
多个reducer情况:2个为例
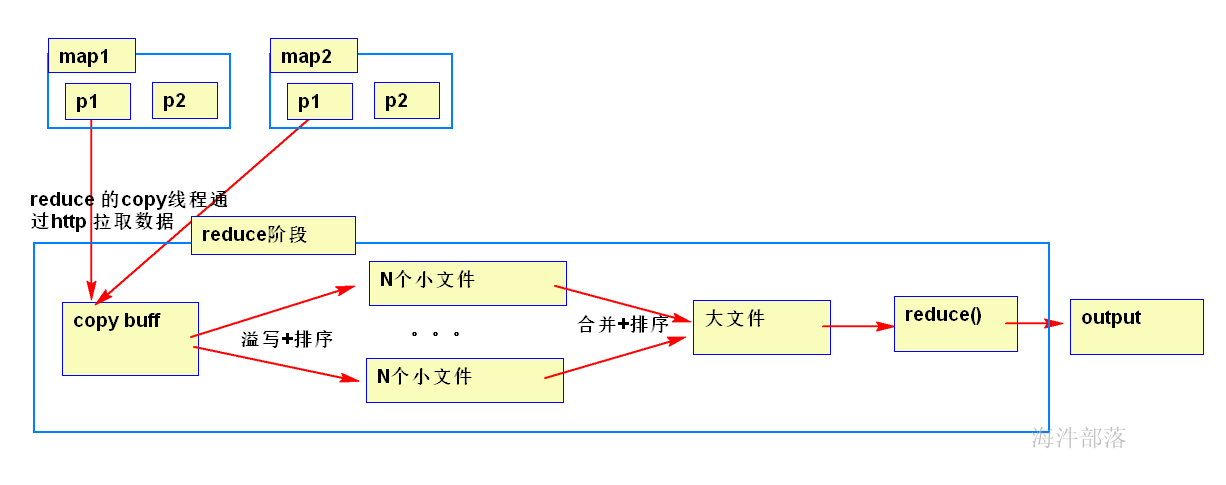
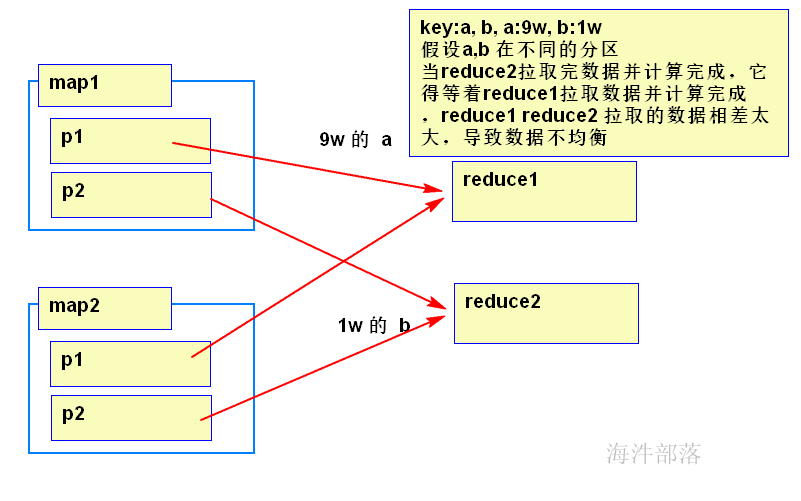
copy merge 占整个reducer运行进度的33%,但可能因为map阶段文件分布不均导致该阶段耗费50-70%的时间。
mapreduce 不怕数据量大,但怕数据倾斜,后面课程会涉及如何优化。
3.5 怎么减少reducer从map拉取的数据量
1)将map数据进行压缩
2)combiner:在map阶段将球分两个筐,然后分的时候就统计出每筐每种球有多少个,在reduce阶段,直接用每筐每种球的数量这个数据,直接统计每种球的数量。
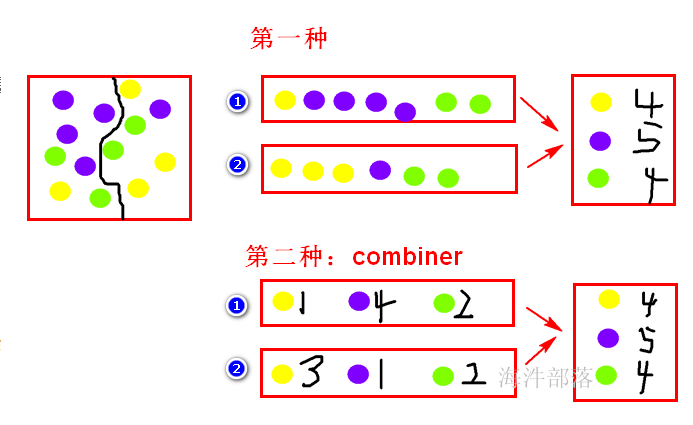
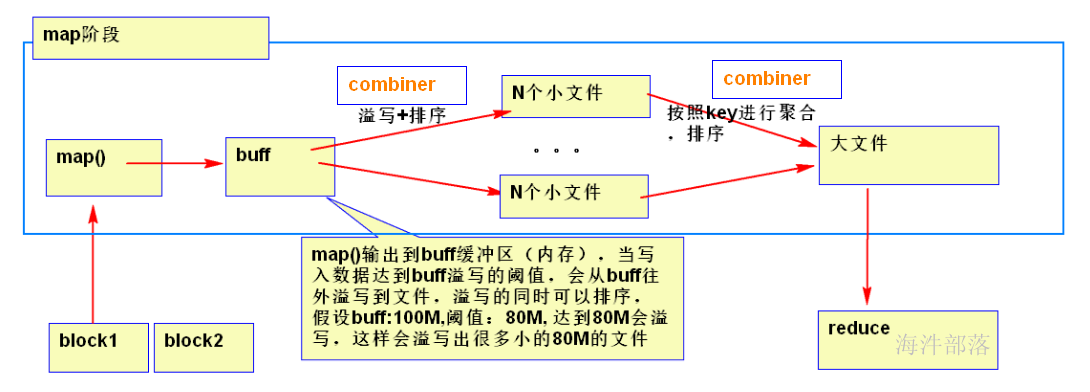
使用combiner可以减少reducer的输入数据量