1 MapJoin
/**
* 缓存形式的mr任务,将一个数据放入到自己的缓存中(小数据)
* 大文件使用mapper任务读取数据,读一次就和自己的缓存数据比对一下
* 大,小 文件join的时候可以尽量的避免shuffle流程带来的损耗,mapjoin
*/
public class CacheJoinMR extends Configured implements Tool{
public static class CJMapper extends Mapper<LongWritable, Text, Text, NullWritable>{
Map<String,String> map = new HashMap<String,String>();
//为了方便查寻数据 map --> key=id value=name+price
@Override
protected void setup(Mapper<LongWritable, Text, Text, NullWritable>.Context context)
throws IOException, InterruptedException {
//进入mapper任务之前先将数据缓存起来(本地)
URI[] cacheFiles = context.getCacheFiles();
String path = cacheFiles[0].getPath();
/tmp/demo01/hello/goods.txt
String name = path.substring(path.lastIndexOf("/")+1);
FileInputStream is = new FileInputStream(name);
BufferedReader bf = new BufferedReader(new InputStreamReader(is));
String line = null;
while((line = bf.readLine())!=null) {
String[] split = line.split(",");
map.put(split[0], split[1]);
}
bf.close();
is.close();
}
// 1 zhangsan 001 8 seaniu
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, NullWritable>.Context context)
throws IOException, InterruptedException {
String[] split = value.toString().split(" ");
String id = split[2];
String nameAndPrice=map.get(id);
if(nameAndPrice != null)
return;
context.write(value, NullWritable.get());
// split[2] = nameAndPrice;
// StringBuilder sb = new StringBuilder();
// for(String s:split) {
// sb.append(s==null?"":s).append(" ");
// }
// String substring = sb.substring(0, sb.length()-1);
// context.write(new Text(substring), NullWritable.get());
// if(nameAndPrice == null)
// return;
// split[2] = nameAndPrice;
// StringBuilder sb = new StringBuilder();
// for(String s:split) {
// sb.append(s).append(" ");
// }
// String substring = sb.substring(0, sb.length()-1);
// context.write(new Text(substring), NullWritable.get());
}
}
public static void main(String[] args) throws Exception{
ToolRunner.run(new CacheJoinMR(), args);
}
@Override
public int run(String[] args) throws Exception {
Path in = new Path("join/order.txt");
Path out = new Path("joinres");
Configuration conf = getConf();
FileSystem fs = FileSystem.getLocal(conf);
if(fs.exists(out))
fs.delete(out);
Job job = Job.getInstance(conf);
for(String arg:args) {
System.out.println(arg);
}
job.addCacheFile(new URI("file:///D://txt/join/goods.txt"));
job.setJarByClass(CacheJoinMR.class);
job.setMapperClass(CJMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(NullWritable.class);
TextInputFormat.addInputPath(job, in);
job.setNumReduceTasks(0);
FileOutputFormat.setOutputPath(job, out);
boolean success = job.waitForCompletion(true);
return success?0:1;
}
}2 自定义序列化类
-
在Hadoop的集群工作过程中,一般是利用RPC来进行集群节点之间的通信和消息的传输,所以要求MapReduce处理的对象必须可以进行序列化/反序列操作。
-
Hadoop并没有使用Java原生的序列化,而是利用的是Avro实现的序列化和反序列,并且在其基础上进行了更好的封装,提供了便捷的API
-
在Hadoop中要求被序列化的对象对应的类必须实现Writable接口
-
序列化过程中要求属性值不能为null
自定义序列化类 求每个人花费的总流量 -flow.txt package cn.tedu.flow; import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; import org.apache.hadoop.io.Writable; //--hadoop要求传输的javabean对象必须要经过序列化 //--hadoop针对序列化已经做好了封装底层用的是avro public class Flow implements Writable{ private String phone=""; private String address=""; private String name=""; private int flow; //--添加构造方法 public Flow() { super(); } public Flow(String phone, String address, String name, int flow) { super(); this.phone = phone; this.address = address; this.name = name; this.flow = flow; } //--添加get和set方法 alt+shift+s public String getPhone() { return phone; } public void setPhone(String phone) { this.phone = phone; } public String getAddress() { return address; } public void setAddress(String address) { this.address = address; } public String getName() { return name; } public void setName(String name) { this.name = name; } public int getFlow() { return flow; } public void setFlow(int flow) { this.flow = flow; } //--添加toString方法 @Override public String toString() { return "Flow [phone=" + phone + ", address=" + address + ", name=" + name + ", flow=" + flow + "]"; } @Override //--反序列化 public void readFields(DataInput in) throws IOException { this.phone=in.readUTF(); this.address=in.readUTF(); this.name=in.readUTF(); this.flow=in.readInt(); } @Override //--序列化 public void write(DataOutput out) throws IOException { out.writeUTF(phone); out.writeUTF(address); out.writeUTF(name); out.writeInt(flow); } } package cn.tedu.flow; import java.io.IOException; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; public class FlowMapper extends Mapper<LongWritable, Text, Text, Flow> { public void map(LongWritable ikey, Text ivalue, Context context) throws IOException, InterruptedException { //--拿到行数据切分后封装成javabean对象13877779999 bj zs 2145 String[] datas = ivalue.toString().split(" "); Flow f=new Flow(); f.setPhone(datas[0]); f.setAddress(datas[1]); f.setName(datas[2]); f.setFlow(Integer.parseInt(datas[3])); context.write(new Text(datas[0]), f); } } package cn.tedu.flow; import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; public class Flowreducer extends Reducer<Text, Flow, Text, IntWritable> { public void reduce(Text _key, Iterable<Flow> values, Context context) throws IOException, InterruptedException { //--定义变量统计总流量 int sum=0; Flow f = null; for (Flow val : values) { sum+=val.getFlow(); f=val; } context.write(new Text(f.getName()), new IntWritable(sum)); } } package cn.tedu.flow; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class FlowDriver { public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); Job job = Job.getInstance(conf, "JobName"); job.setJarByClass(cn.tedu.flow.FlowDriver.class); // TODO: specify a mapper job.setMapperClass(FlowMapper.class); // TODO: specify a reducer job.setReducerClass(Flowreducer.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(Flow.class); // TODO: specify output types job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); //--设置分区规则 job.setPartitionerClass(AddressPartitioner.class); //--设置reducetask的数量 规则:分区的数量等于reducetask的数量 job.setNumReduceTasks(3); // TODO: specify input and output DIRECTORIES (not files) FileInputFormat.setInputPaths(job, new Path("hdfs://10.5.24.244:9000/txt/flow.txt")); FileOutputFormat.setOutputPath(job, new Path("hdfs://10.5.24.244:9000/flowcount")); if (!job.waitForCompletion(true)) return; } }
3 自定义分区
一、概述
-
分区操作是shuffle操作中的一个重要过程,作用就是将map的结果按照规则分发到不同reduce中进行处理,从而按照分区得到多个输出结果。
-
Partitioner是分区的基类,如果需要定制partitioner也需要继承该类
-
HashPartitioner是MapReduce的默认partitioner。计算方法是:which reducer=(key.hashCode() & Integer.MAX_VALUE) % numReduceTasks
-
默认情况下,reduceTask数量为1
-
很多时候MapReduce自带的分区规则并不能满足业务需求,为了实现特定的效果,可以需要自己来定义分区规则
-
如果定义了几个分区,则需要定义对应数量的ReduceTask
改造如上统计流量案例,根据不同地区分区存放数据 public class FlowPartitioner extends Partitioner<Text, Flow> { // 用于进行分区的方法 @Override public int getPartition(Text key, Flow value, int numReduceTasks) { String addr = value.getAddr(); if (addr.equals("bj")) return 0; else if (addr.equals("sh")) return 1; else return 2; } } // 在任务调度代码中,增加Partitioner配置 //设置Partitioner类 job.setPartitionerClass(DCPartitioner.class); //指定Reducer的数量,此处通过main方法参数获取,方便测试 job.setNumReduceTasks(3);
4 排序
- Map执行过后,在数据进入reduce操作之前,数据将会按照输出的Key进行排序,利用这个特性可以实现大数据场景下排序的需求
- 要排序的对象对应类实现WritableComparable接口,根据返回值的正负决定排序顺序
- 如果比较的结果一致,则会将相同的结果舍弃 //忽略
- 如果对类中的多个属性进行比较,则此时的排序称之为叫二次排序
5 打包上集群运行
\4 maven的assembly的打包方法\在项目中的pom文件中增加assembly插件maven-assembly-plugin 就是用来帮助打包用的,比如说打出一个什么类型的包,包里包括哪些内容等等
**
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.hainiuxy</groupId>
<artifactId>hainiumr</artifactId>
<version>1.0</version>
<packaging>jar</packaging>
<name>hainiu_mr</name>
<url>http://maven.apache.org</url>
<properties>
<!-- 项目编码 -->
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<!-- 编译及输出的时候应用那个版本的jdk -->
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<!-- 【修改点】运行的Driver类,是打包运行的主类-->
<mainClass>com.hainiu.hadoop.mapreduce.mrrun.Driver</mainClass>
</properties>
<dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-client -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.3</version>
<!--已提供范围的依赖在编译classpath (不是运行时)可用。它们不是传递性的,也不会被打包 -->
<scope>provided</scope>
</dependency>
</dependencies>
<build>
<resources>
<resource>
<!-- 加载源码的位置 -->
<directory>src/main/resources</directory>
</resource>
</resources>
<plugins>
<plugin>
<!-- 加载打包插件 -->
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<!-- 指定配置文件 -->
<descriptors>
<descriptor>src/main/resources/assembly.xml</descriptor>
</descriptors>
<archive>
<manifest>
<!-- 加载主要运行类 -->
<mainClass>${mainClass}</mainClass>
</manifest>
</archive>
</configuration>
<executions>
<!-- 配置执行器 -->
<execution>
<id>make-assembly</id>
<!-- 绑定到package生命周期阶段上 -->
<phase>package</phase>
<goals>
<!-- 只运行一次 -->
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<!-- 配置跳过单元测试 -->
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.12</version>
<configuration>
<skip>true</skip>
<forkMode>once</forkMode>
<excludes>
<exclude>**/**</exclude>
</excludes>
</configuration>
</plugin>
</plugins>
</build>
</project>把assembly配置文件放到/src/main/resources目录中,如果没有则创建一个
在assembly.xml中配置好打包时需要包含的文件,和需要排除的文件
<assembly xmlns="http://maven.apache.org/plugins/maven-assembly-plugin/assembly/1.1.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/plugins/maven-assembly-plugin/assembly/1.1.0 http://maven.apache.org/xsd/assembly-1.1.0.xsd">
<!-- TODO: a jarjar format would be better -->
<!-- 添加到生成文件名称的后缀符 -->
<id>hainiu</id>
<!-- 打包类型 -->
<formats>
<format>jar</format>
</formats>
<!-- 指定是否包含打包层目录 -->
<includeBaseDirectory>false</includeBaseDirectory>
<!-- 指定要包含的文件集 -->
<fileSets>
<fileSet>
<!-- 指定目录 -->
<directory>${project.build.directory}/classes</directory>
<!-- 指定文件集合的输出目录,该目录是相对于根目录 -->
<outputDirectory>/</outputDirectory>
<!-- 排除文件 -->
<excludes>
<exclude>*.xml</exclude>
<exclude>*.properties</exclude>
</excludes>
</fileSet>
</fileSets>
<!-- 用来定制工程依赖 jar 包的打包方式 -->
<dependencySets>
<dependencySet>
<!-- 指定包依赖目录,该目录是相对于根目录 -->
<outputDirectory>/</outputDirectory>
<!-- 当前项目构件是否包含在这个依赖集合里 -->
<useProjectArtifact>false</useProjectArtifact>
<!-- 是否将第三方jar包解压到该依赖中 false 直接引入jar包 true解压引入 -->
<unpack>true</unpack>
<!-- 将scope为runtime的依赖包打包到lib目录下。 -->
<scope>runtime</scope>
</dependencySet>
</dependencySets>
</assembly>**
打包之前,先检查代码是否有问题打包方法1:1)先执行clean2)再执行build3)最后执行assembly
建议先清理再打包,之后会在项目的target目录下生成jar包,包后缀名使用的是assembly.xml配置的id
打包注意事项: 把那些调试程序的控制台输出代码,都给注释掉,因为集群运行时,需要把控制台输出的数据写入磁盘,如果数据量大,会对mapreduce任务运行性能影响很大。

2)在hdfs上创建数据目录和任务输入目录**
hadoop fs -mkdir /user/panniu/mr/input_score在刚才创建的数据目录上传测试数据
hadoop fs -put f1 /user/panniu/mr/input_score
hadoop fs -put f2 /user/panniu/mr/input_score然后提交集群运行hadoop jar ./hainiumr-1.0-hainiu.jar 类全名 输入 输出
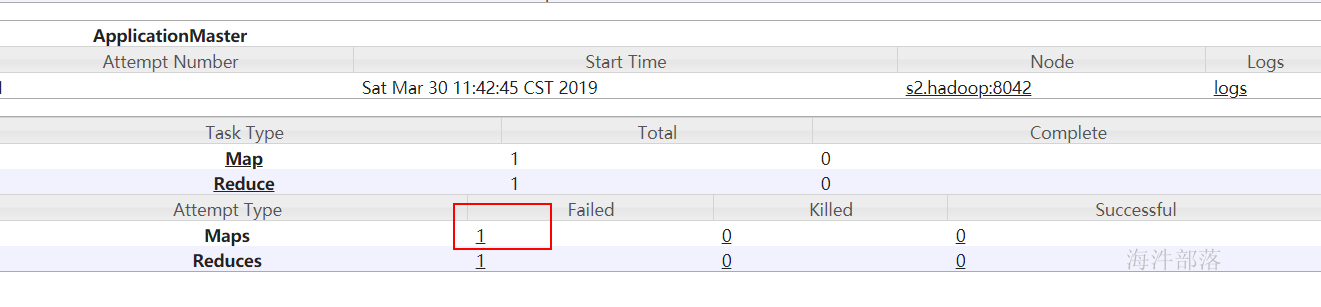
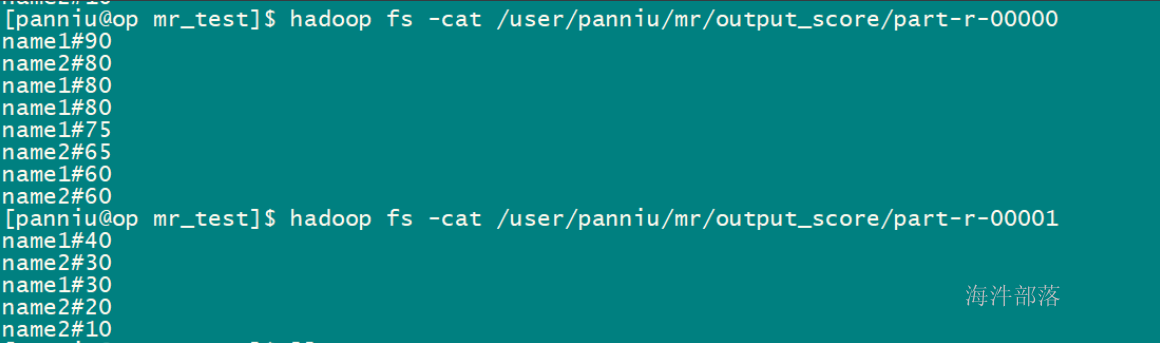
hadoop jar hainiumr-1.0-hainiu.jar com.hainiu.day03.ScoreSort /user/panniu/mr/input_score /user/panniu/mr/output_score


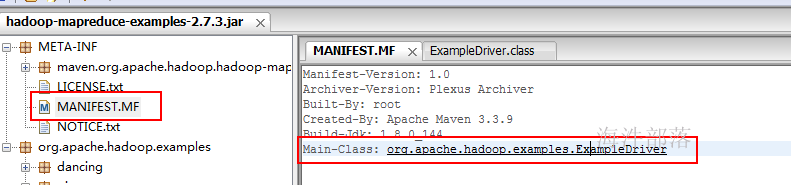
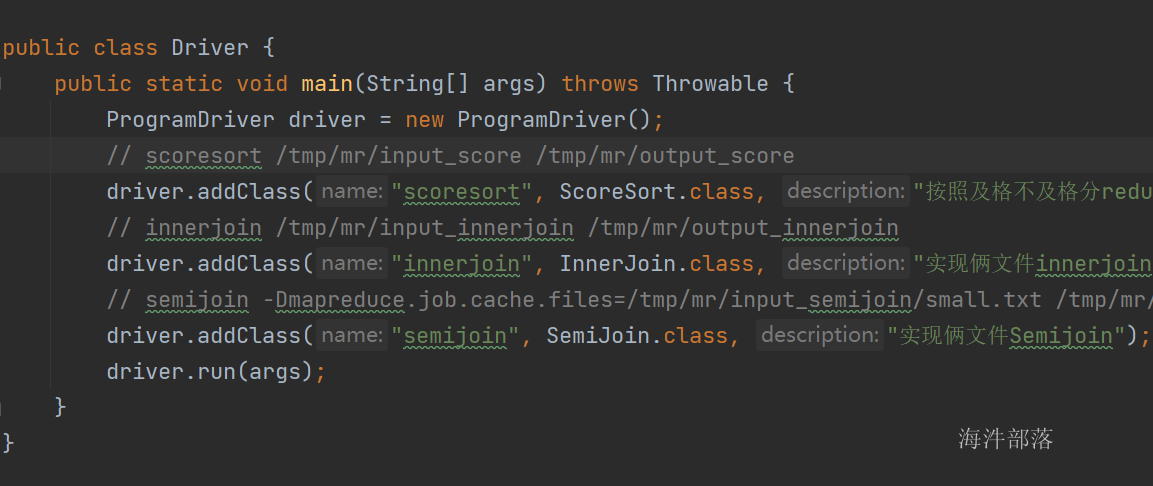
修改maven项目的pom文件指定maven assembly插件使用的mainClass,这样生成的jar包就有了默认的主类,并且不在接受输入类地址调用其它的类。
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.hainiu.hadoop</groupId>
<artifactId>mapreduce</artifactId>
<version>1.0</version>
<packaging>jar</packaging>
<name>mapreduce</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<!-- 编译及输出的时候应用那个版本的jdk -->
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<!-- 【修改点】运行的Driver类,是打包运行的主类-->
<mainClass>com.hainiu.hadoop.mapreduce.mrrun.Driver</mainClass>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.3</version>
<scope>provided</scope>
</dependency>
</dependencies>
<build>
<resources>
<resource>
<directory>src/main/resources</directory>
</resource>
</resources>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptors>
<descriptor>src/assembly/assembly.xml</descriptor>
</descriptors>
<archive>
<manifest>
<mainClass>${mainClass}</mainClass>
</manifest>
</archive>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.12</version>
<configuration>
<skip>true</skip>
<forkMode>once</forkMode>
<excludes>
<exclude>**/**</exclude>
</excludes>
</configuration>
</plugin>
</plugins>
</build>
</project>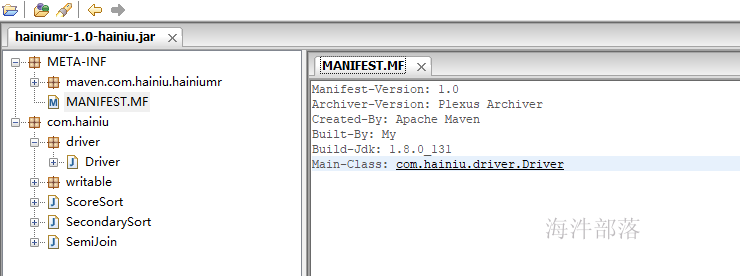
6.2 打包上集群运行1)在Driver上配置