1 Lucene
1.1 Lucene介绍
Lucene是apache软件基金会 jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎。Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。Lucene是一套用于全文检索和搜寻的开源程式库,由Apache软件基金会支持和提供。Lucene提供了一个简单却强大的应用程式接口,能够做全文索引和搜寻。在Java开发环境里Lucene是一个成熟的免费开源工具。就其本身而言,Lucene是当前以及最近几年最受欢迎的免费Java信息检索程序库。人们经常提到信息检索程序库,虽然与搜索引擎有关,但不应该将信息检索程序库与搜索引擎相混淆。
Lucene 最初是由Doug Cutting开发的。
Lucene 只支持英文分词,中文分词一个字一个词。1.2 Lucene原理—倒排索引
1.2.1 什么是倒排索引?
倒排索引源于实际应用中需要根据属性的值来查找记录,lucene是基于倒排索引实现的。
这种索引表中的每一项都包括一个属性值和具有该属性值的各记录的地址。
由于不是由记录来确定属性值(正排索引),而是由属性值来确定记录的位置,因而称为倒排索引(inverted index)。
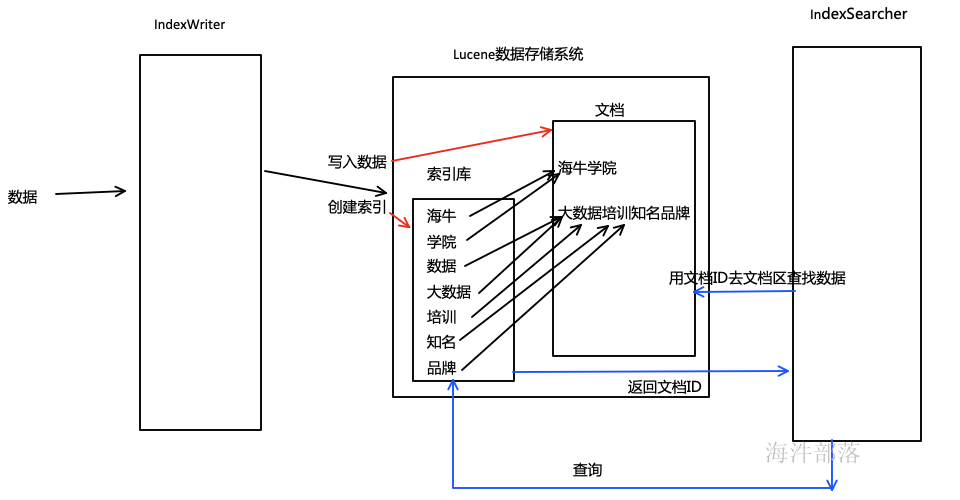
1.2.2 正排索引与倒排索引
-
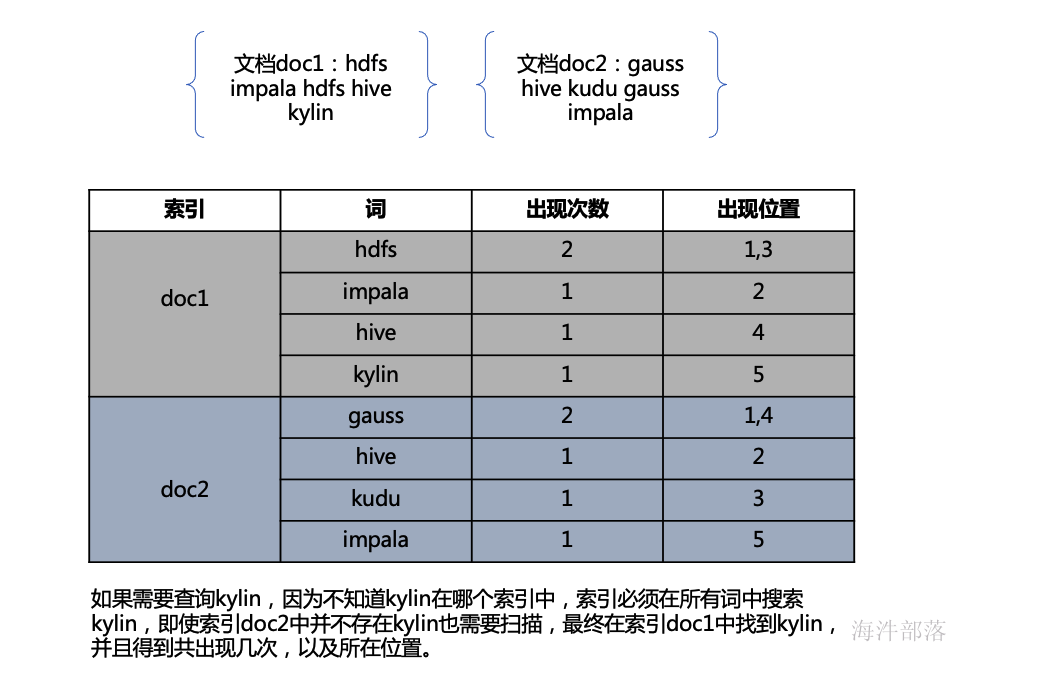
正排索引
正排索引使用文档ID作为索引,记录每个词出现的次数与在该文档中的位置,优点是构建索引时较快,缺点是查询时较慢。
-
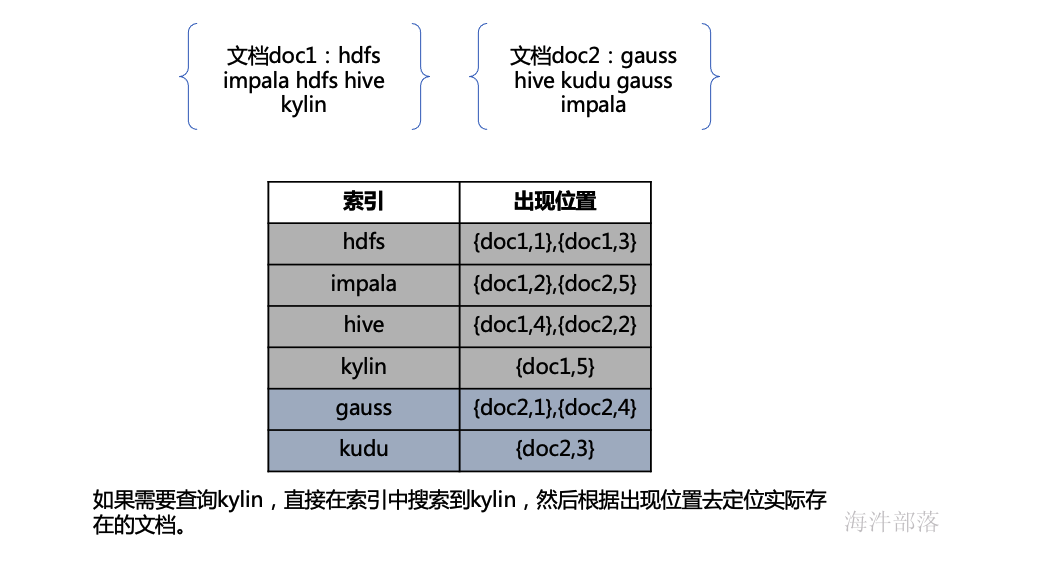
倒排索引
倒排索引使用文档中的词作为索引,记录每个词在哪个文档的哪个位置,优点是查询非常快,缺点是构建索引较慢。
2 elasticsearch
2.1 elasticsearch 简介
Elasticsearch(简称ES)是一个开源的高扩展的分布式全文检索引擎,它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB级别的数据。
根据DB-Engines的排名显示,Elasticsearch是最受欢迎的企业搜索引擎,其次是Apache Solr,也是基于Lucene。
Elasticsearch也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。
Elasticsearch 的实现原理主要分为以下几个步骤:
1)首先用户将数据提交到Elasticsearch 数据库中。
2)再通过分词控制器去将对应的语句分词,将其权重和分词结果一并存入数据。
3)当用户搜索数据时候,再根据权重将结果排名,打分,再将返回结果呈现给用户。
Elasticsearch可以用于搜索各种文档。”Elasticsearch是分布式的,索引有多个分片(可扩展),每个分片可以有0个或多个副本(可靠)。每个节点托管一个或多个分片,并充当协调器将操作委托给正确的分片。再平衡和路由是自动完成的。“相关数据通常存储在同一个索引中,该索引由一个或多个主分片和零个或多个复制分片组成。一旦创建了索引,就不能更改主分片的数量。
2.2 elasticsearch solr 对比
当单纯的对已有数据进行搜索时,Solr更快;
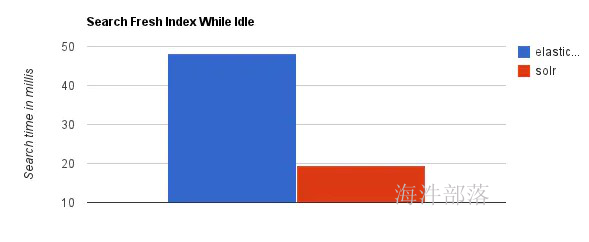
当实时建立索引时, Solr会产生io阻塞,查询性能较差
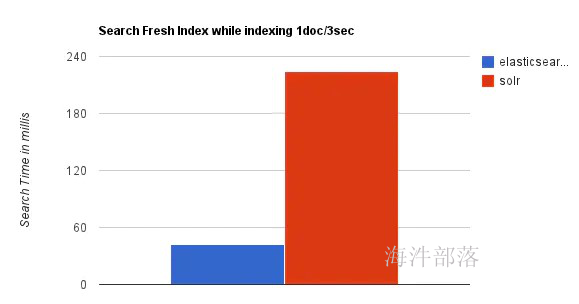
随着数据量的增加,Solr的搜索效率会变得更低,而Elasticsearch却没有明显的变化
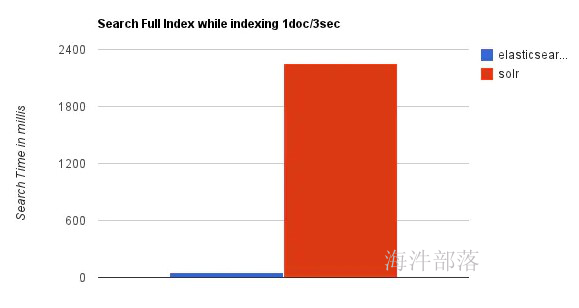
综上所述,Solr的架构不适合实时搜索的应用。
2.3 ELK生态体系
ELK=elasticsearch+Logstash+kibana
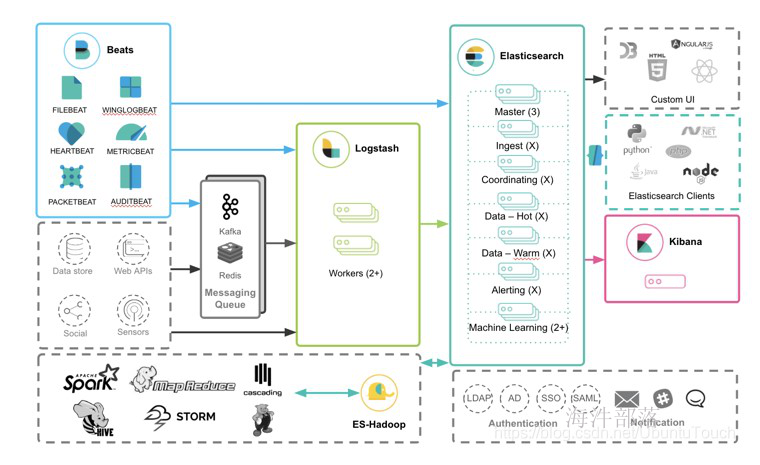
elasticsearch:后台分布式存储以及全文检索 ;
logstash: 是用来日志的搜集、分析、过滤日志的工具,支持大量的数据获取方式。
kibana:数据可视化展示。
ELK架构为数据分布式存储、可视化查询和日志解析创建了一个功能强大的管理链。 三者相互配合,取长补短,共同完成分布式大数据处理工作。
2.4 为什么使用elasticsearch
Elasticsearch 很快。由于 Elasticsearch 是在 Lucene 基础上构建而成的,所以在全文本搜索方面表现十分出色。Elasticsearch 同时还是一个近实时的搜索平台,这意味着从文档索引操作到文档变为可搜索状态之间的延时很短,一般只有一秒。因此,Elasticsearch 非常适用于对时间有严苛要求的用例,例如安全分析和基础设施监测。
Elasticsearch 具有分布式的本质特征。Elasticsearch 中存储的文档分布在不同的容器中,这些容器称为分片,可以进行复制以提供数据冗余副本,以防发生硬件故障。Elasticsearch 的分布式特性使得它可以扩展至数百台(甚至数千台)服务器,并处理 PB 量级的数据。
Elasticsearch 包含一系列广泛的功能。除了速度、可扩展性和弹性等优势以外,Elasticsearch 还有大量强大的内置功能(例如数据汇总和索引生命周期管理),可以方便用户更加高效地存储和搜索数据。
Elastic Stack 简化了数据采集、可视化和报告过程。通过与 Beats 和 Logstash 进行集成,用户能够在向 Elasticsearch 中索引数据之前轻松地处理数据。同时,Kibana 不仅可针对 Elasticsearch 数据提供实时可视化,同时还提供 UI 以便用户快速访问应用程序性能监测 (APM)、日志和基础设施指标等数据。
2.5 es在大数据中的常见应用
-
数据中台
使用es作为中台数据库,凭借es高速的检索查询效率,以及restful接口,极大方便了中台的搭建。
-
二级索引
在大数据领域中的重点应用,多用于一些对实时查询效率要求较高的场景,我们知道hbase用rowkey查询效率非常高,无出其右,但是如果rowkey不能满足查询条件,则需要使用filter进行查询,此时hbase的查询效率就非常低,此时就需要借助二级索引来实现组合查询,通过二级索引做组合查询,返回rowkey,再通过rowkey去hbase中查询,es此时就可以作为hbase的二级索引,全量数据存在hbase中,es只存储一些必要的查询条件列以及hbase的rowkey,利用es的倒排索引,快速定位到要取的数据的rowkey。相比solr,es作为二级索引在数据同步的时候略显复杂,并且在写入的时候经常达到es瓶颈,写入效率不高。当es一个index达到int最大值21亿条的时候需要新增index。


