1 集群操作
1.1 查看集群健康情况
GET /_cat/health?v
1.2 查看索引状态
GET /_cat/indices?v
集群健康值通过颜色分辨

2 索引操作
RESTful接口URL的格式:http://worker-1:9200///[]
其中index、type是必须提供的,id可选
使用index/type/id 定位到具体的数据
index:索引(可以理解为数据库)
type:类型(理解为数据表)
id:唯一主键,可选的,不提供es会自动生成。(相当于数据库表中记录的主键,是唯一的)
ES Restful API GET、POST、PUT、DELETE 含义:
1)GET:获取请求对象的当前状态。
2)POST:改变对象的当前状态。
3)PUT:创建一个对象。
4)DELETE:销毁对象
2.1 创建和删除索引
# 创建索引
PUT /hainiu1
# 删除索引
DELETE /hainiu1
2.2 创建索引并制定mapping映射
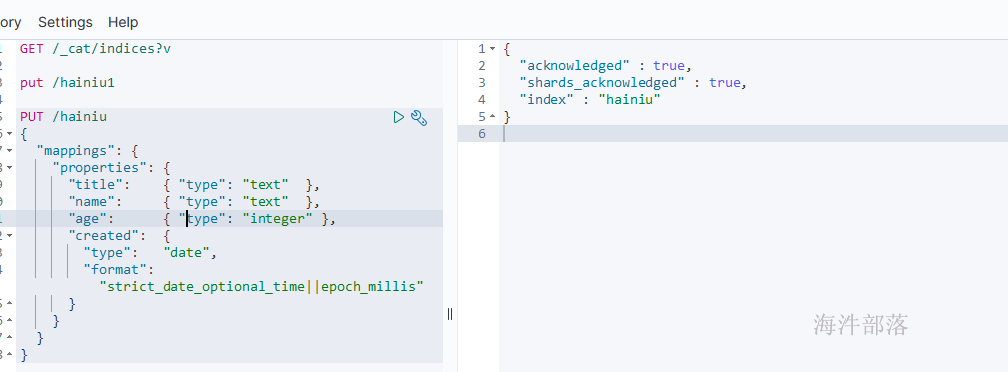
# 创建hainiu索引, 并设置mappings, 里面有 title、name、age、created 四个字段
PUT /hainiu
{
"mappings": {
"properties": {
"title": { "type": "text" },
"name": { "type": "text" },
"age": { "type": "integer" },
"created": {
"type": "date",
"format": "strict_date_optional_time||epoch_millis"
}
}
}
}
2.3 查看mapping
GET /hainiu/_mapping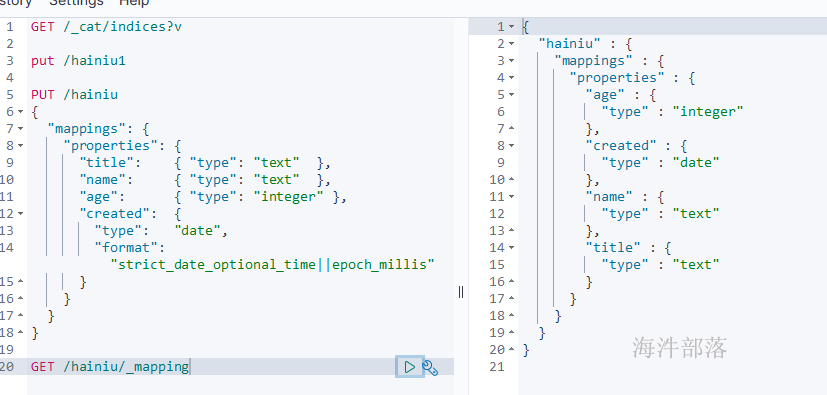
2.4 插入数据
2.4.1 不指定id插入
# 不指定id
POST /hainiu/_doc
{
"name":"ls",
"title":"李四",
"age":28,
"created":"2021-06-04"
}
2.4.2 指定id插入
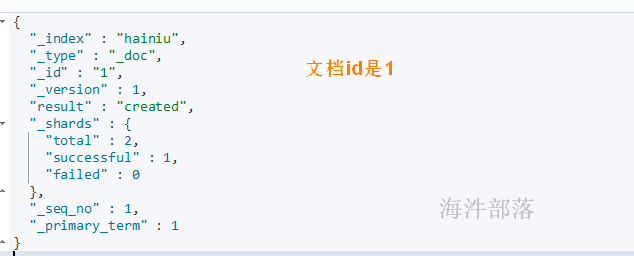
# 指定id插入
POST /hainiu/_doc/1
{
"name":"ls",
"title":"李四",
"age":28,
"created":"2021-06-04"
}
2.5 查询文档
# 获取索引中文档id=1的数据
GET /hainiu/_doc/1
# 获取索引中文档id=1中title字段数据
GET /hainiu/_doc/1?_source=title
# 获取索引中文档id=1中name、title字段数据
GET /hainiu/_doc/1?_source=name,title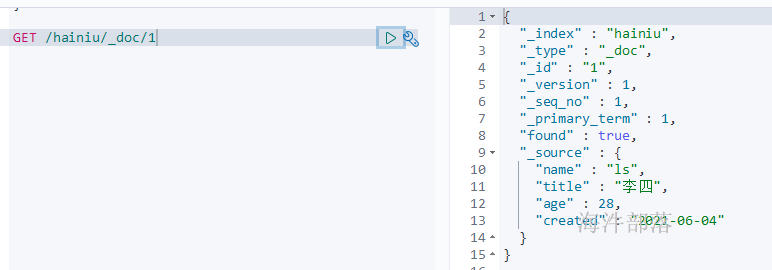
2.6 修改文档内容
# 修改文档id=1的name和title
PUT /hainiu/_doc/1
{
"name":"lls",
"title":"李老四"
}
# 查看
GET /hainiu/_doc/1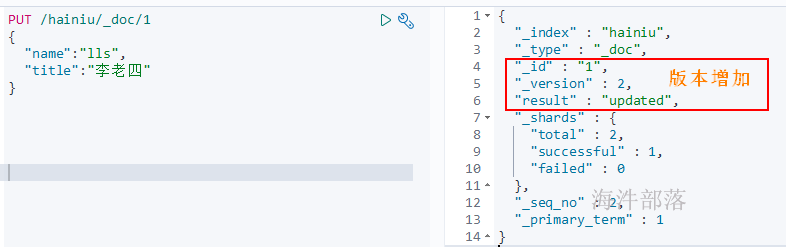
2.7 删除文档内容
DELETE /hainiu/_doc/1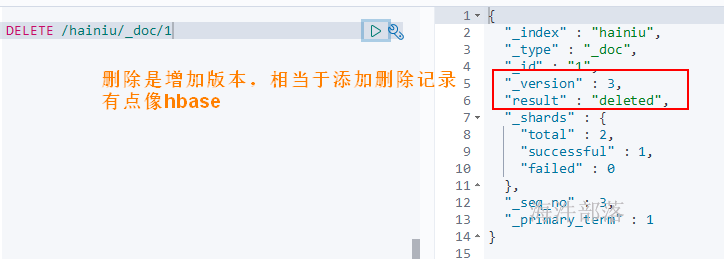
2.8 批量操作(bulk)
有哪些类型的操作可以执行呢?
(1)delete:删除一个文档;
(2)create:如果数据存在,使用create操作失败,会提示文档已经存在;
(3)index:如果数据存在,使用index则可以成功执行;
(4)update:更新
# 使用_bulk方式批量插入
# "index":{} --> 文档id自动生成
# "index": { "_id": "2" }
POST /hainiu/_doc/_bulk
{"index":{}}
{"name":"xiaoy1","title":"肖云1","age":18,"created":"2021-06-05"}
{"index":{ "_id": "2" }}
{"name":"xiaoy2","title":"肖云2","age":25,"created":"2021-06-05"}
{"index":{ "_id": "3" }}
{"name":"xiaoy3","title":"肖云3","age":25,"created":"2021-06-05"}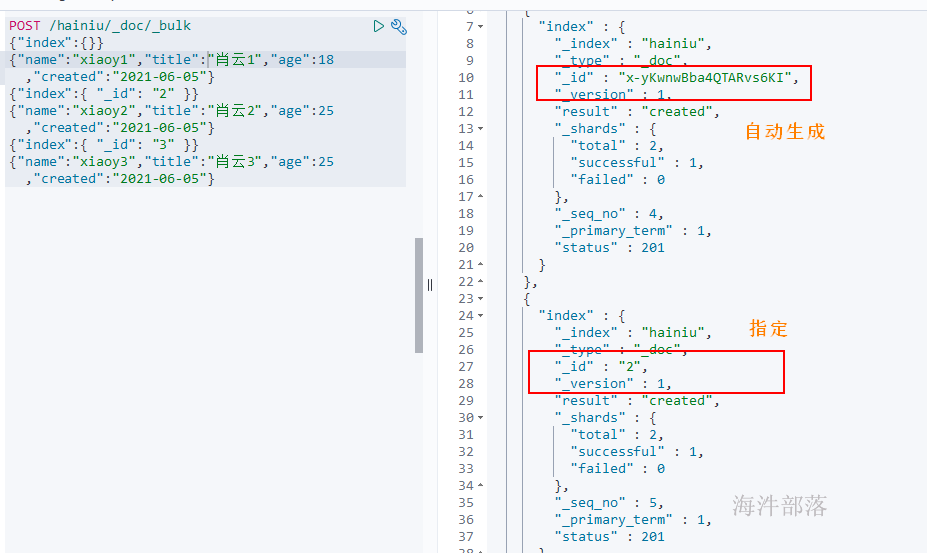
# 查询hainiu库的所有文档
GET /hainiu/_doc/_search
{
"query":{
"match_all": {}
}
}bulk size 大小设置
bulk request会加载到内存里,如果太大的话,性能反而会下降,因此需要反复尝试一个最佳的bulk size。一般从1000~5000条数据开始,尝试逐渐增加。另外,如果看大小的话,最好是在5~15MB之间。
3 搜索篇
批量插入(指定id)
# 批量插入测试数据
# hainiu3索引库 user 表
POST /hainiu3/user/_bulk
{"index":{"_id":1}}
{"name":"laoli","realname":"老李","age":28,"birthday":"2012-11-17","salary":20000.0,"address":"北京市昌平区"}
{"index":{"_id":2}}
{"name":"laozhang","realname":"老张","age":20,"birthday":"2012-12-21","salary":2000.0,"address":"北京市朝阳区"}
{"index":{"_id":3}}
{"name":"laowang","realname":"老王","age":25,"birthday":"2015-06-16","salary":3300.0,"address":"北京市海淀区"}
{"index":{"_id":4}}
{"name":"laosun","realname":"老孙","age":20,"birthday":"2006-06-16","salary":15300.0,"address":"北京市海淀区中关村软件园"}
{"index":{"_id":5}}
{"name":"laozhao","realname":"老赵","age":35,"birthday":"2011-06-16","salary":1303.0,"address":"北京市海淀区西二旗"}3.1 查询索引库所有数据
GET /hainiu3/user/_search
{
"query":{
"match_all": {}
}
}3.2 查询所有数据并排序
# 查询按照age降序排序
GET /hainiu3/user/_search
{
"query":{
"match_all": {}
},
"sort":{
"age":"desc"
}
}查询结果:
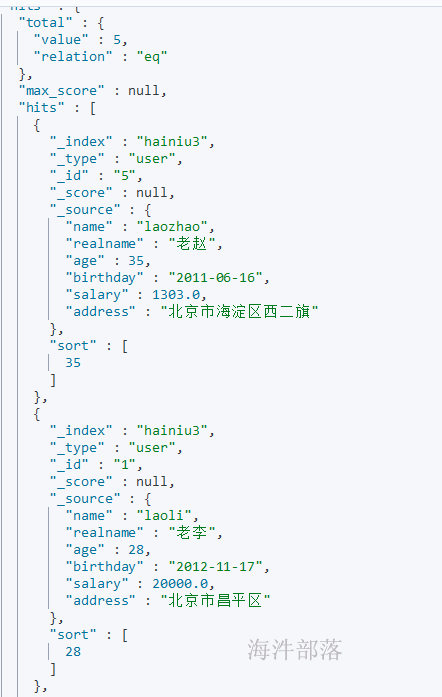


3.3 分页查询
# 查询按照age降序排序,从第1个查询2个
GET /hainiu3/user/_search
{
"query":{
"match_all": {}
},
"sort":{
"age":"desc"
},
"from":0,
"size":2
}
# 通过调整from的参数来实现分页查询查询结果:

3.4 匹配查询
# 根据分词(默认中文一个字一个词)情况用or组合
GET /hainiu3/user/_search
{
"query":{
"match": {
"address": "西昌"
}
}
}
3.5 精确查询
# 添加一行文档
POST /hainiu3/_doc/6
{"name":"laoli2","realname":"老李2","age":29,"birthday":"2012-11-17","salary":20000.0,"address":"北京市昌平区"}
# 精确查询
# 不分词查询
GET /hainiu3/user/_search
{
"query":{
"term": {
"name": {
"value": "laoli"
}
}
}
}3.6 范围查询
# age 通过 mapping 查看 是 long类型, 可以用range
GET /hainiu3/user/_search
{
"query":{
"range": {
"age": {"gte": 15,"lte": 24}
}
}
}3.7 组合查询
# 类似的,Elasticsearch也有 and, or, not这样的组合条件的查询方式
# 格式如下:
# {
# "bool" : {
# "must" : [],
# "should" : [],
# "must_not" : [],
# }
# }
#
# must: 条件必须满足,相当于 and
# should: 条件可以满足也可以不满足,相当于 or
# must_not: 条件不需要满足,相当于 not
# select * from hainiu3 where age=20 and salary>=5000
GET /hainiu3/user/_search
{
"query":{
"bool":{
"must":[
{"term":{"age":20}},
{"range":{"salary":{"gte":5000}}}
]
}
}
}
# select * from hainiu3 where age=20 or salary>=20000
GET /hainiu3/user/_search
{
"query":{
"bool":{
"should":[
{"term":{"age":20}},
{"range":{"salary":{"gte":20000}}}
]
}
}
}
4 es 集成ik分词器插件实现中文分词
es的底层是Lucene, Lucene 自带的分词器对英文的支持是非常好的。
一般分词经过的流程:
1)切分关键词
2)去除停用词
3)把英文单词转为小写
但是老外写的分词器对中文分词一般都是单字分词,分词的效果不好。
4.1 安装ik分词器
下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases/tag/v7.12.1
# 目前ik分词器最高版本为7.13.0,而我们的es版本是7.13.1,暂时不安装,也可以换个低版本的es。
# 官方目前最新的包是elasticsearch-analysis-ik-7.zip,但是最高只支持到7.13.0,下面是部署方式,等官方出了新的支持7.13.1的ik包吧,如果部署其他版本的es和ik,部署方式和下面的一致,只不过要换下ik分词器的包
mkdir /opt/elasticsearch-7.12.1/plugins/ik
cd /opt
# 如果没有安装 zip unzip
yum install -y zip unzip
# 上传ik安装包至ik目录、解压
unzip elasticsearch-analysis-ik-7.12.1.zip -d /opt/elasticsearch-7.12.1/plugins/ik
chown -R es:es /opt/elasticsearch-7.12.1/plugins/ik/
# 重启es
ps -aux | grep elasticsearch |grep -v grep| awk '{print "kill " $2}'|sh
/opt/elasticsearch-7.12.1/bin/elasticsearch -d4.2 ik分词器使用
4.2.1 ik分词器核心配置
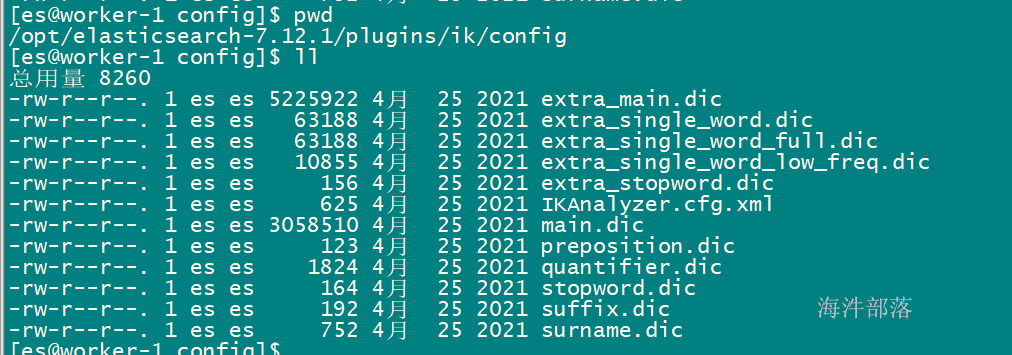
其中:
main.dic:主词库
extra_main.dic:扩展词库
IKAnalyzer.cfg.xml:核心配置
preposition.dic:介词词库
quantifier.dic:量词词库
stopword.dic:停止词词库,屏蔽词
4.2.2 用下面的例子测试分词器是否安装成功
#IK分词器有两种分词模式:ik_max_word 和 ik_smart模式
#ik_max_word:最细粒度的分
#ik_smart:最粗粒度的分
GET /_analyze?pretty
{"text":"海牛大数据",
"analyzer":"ik_max_word"
}
GET /_analyze?pretty
{"text":"海牛大数据",
"analyzer":"ik_smart"
}
ik_max_word :

ik_smart:

分词例子:
# 创建索引
PUT /news
{
"mappings": {
"properties": {
"content": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word"
}
}
}
}
# 添加数据
POST /news/_doc/1
{"content":"美国留给伊拉克的是个烂摊子吗"}
POST /news/_doc/2
{"content":"公安部:各地校车将享最高路权"}
POST /news/_doc/3
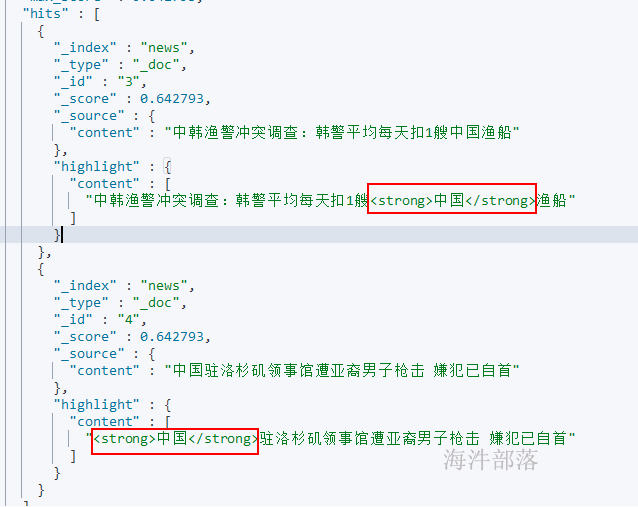
{"content":"中韩渔警冲突调查:韩警平均每天扣1艘中国渔船"}
POST /news/_doc/4
{"content":"中国驻洛杉矶领事馆遭亚裔男子枪击 嫌犯已自首"}
# 高亮查询
# 查询content 中包含中国的结果,并对中国词汇高亮
POST /news/_doc/_search
{
"query" : { "match" : { "content" : "中国" }},
"highlight" : {
"pre_tags" : ["<strong>", "<tag>"],
"post_tags" : ["</strong>", "</tag>"],
"fields" : {
"content" : {}
}
}
}
4.2.3 如何扩展词库
扩展前添加记录和搜索:
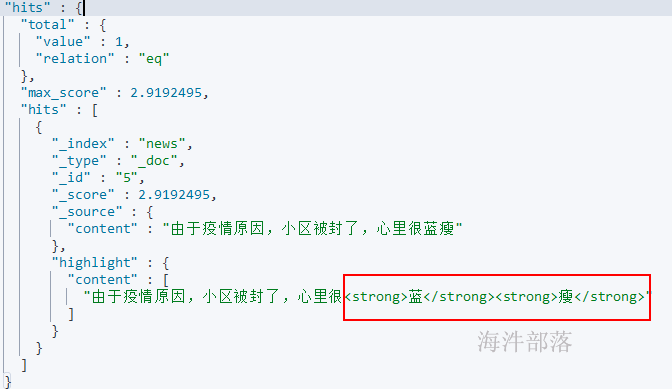
# 添加记录, 里面有个新词: 蓝瘦
POST /news/_doc/5
{"content":"由于疫情原因,小区被封了,心里很蓝瘦"}
# 搜索,由于ik分词器词库没有该词,查询时不会按照一个词来查询
POST /news/_doc/_search
{
"query" : { "match" : { "content" : "蓝瘦" }},
"highlight" : {
"pre_tags" : ["<strong>", "<tag>"],
"post_tags" : ["</strong>", "</tag>"],
"fields" : {
"content" : {}
}
}
}
修改/opt/elasticsearch-7.12.1/plugins/ik/config/main.dic 增加 “蓝瘦” 词汇
分发main.dic 到es的节点上,重新启动es(本例只有一个节点,重启节点es即可)。
# 重启es
su - es
ps -aux | grep elasticsearch |grep -v grep| awk '{print "kill " $2}'|sh
/opt/elasticsearch-7.12.1/bin/elasticsearch -d重启es后,查找之前文档发现找不到了,原因是现在找的是“蓝瘦”这个词,而之前的文档是一个字一个词。

需要重新添加新文档,才能按照“蓝瘦”这个词分词
# 添加记录, 里面有个新词: 蓝瘦
POST /news/_doc/6
{"content":"看到其他同学已经找到工作,心里很蓝瘦"}
# 搜索,由于ik分词器词库没有该词,查询时不会按照一个词来查询
POST /news/_doc/_search
{
"query" : { "match" : { "content" : "蓝瘦" }},
"highlight" : {
"pre_tags" : ["<strong>", "<tag>"],
"post_tags" : ["</strong>", "</tag>"],
"fields" : {
"content" : {}
}
}
}
如果想让添加新词前的分档也可以分词,需要进行索引重建。
5 es 索引重建
Elasticsearch的索引一旦创建是不可变更的,如果我们要修改索引的Setting,Mapping,这时就需要重建索引。
5.1 Reindex在其他索引上重建索引
Reindex API是在其他索引上重建索引, 即将一个索引的数据复制到另一个索引中。 Reindex APi 要求Mapping中的_source属性设置为enable(默认就是enable), 且Reindex只会复制数据, 不会复制Mapping, Setting结构。
# 创建新索引 news2
PUT /news2
{
"mappings" : {
"properties" : {
"content" : {
"type" : "text",
"analyzer" : "ik_max_word"
}
}
}
}
# 将 news的数据复制到news2中
#Reindex常用属性
#(1) version_type
#乐观版本控制机制, 值有四种, 分别是:
# internal:默认. 将数据复制到另一个索引的过程中, 如果遇到相同的文档id, 直接覆盖.
# external:将数据复制到另一个索引的过程中, 如果遇到相同的文档id, 只有版本号更大才会覆盖.
# external_gt:同external.
# external_gte:版本号大于等于才会覆盖.
#(2) op_type
# index:默认, 如果遇到相同文档id的数据, 则覆盖.
# create:遇到相同文档id的数据则报错.
#(3) conflicts
# abort:重建索引过程中出现报错时终止重建索引.
# proceed:重建索引过程中出现报错时跳过, 继续重建索引.
POST /_reindex
{
"source": {
"index": "news"
},
"dest": {
"index": "news2",
"version_type": "internal",
"op_type": "index"
},
"conflicts": "proceed"
}
# 查询,发现把添加词库前的文档也查询出来了
POST /news2/_doc/_search
{
"query" : { "match" : { "content" : "蓝瘦" }},
"highlight" : {
"pre_tags" : ["<strong>", "<tag>"],
"post_tags" : ["</strong>", "</tag>"],
"fields" : {
"content" : {}
}
}
}

结论:
此种方式虽然可以实现将添加词库前的文档用新词库分词,但客户端用的时候还要切换索引库。
5.2 使用_alias实现不停机重建索引
在实际场景中,当我们修改了某个索引的Mapping或Setting需要重建索引时,我们可以使用_alias来实现不停机重建索引,即在重建索引的过程中,旧索引仍然对外提供服务。
# 给 news索引 设置别名 news_v1
PUT /news/_alias/news_v1
# 通过别名操作索引,查询出索引news 的数据
POST /news_v1/_doc/_search
{
"query" : { "match" : { "content" : "蓝瘦" }},
"highlight" : {
"pre_tags" : ["<strong>", "<tag>"],
"post_tags" : ["</strong>", "</tag>"],
"fields" : {
"content" : {}
}
}
}
# 创建新索引 news3
PUT /news3
{
"mappings": {
"properties": {
"content": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_max_word"
}
}
}
}
# 将news索引数据复制到 news3 索引中
POST /_reindex
{
"source": {
"index": "news"
},
"dest": {
"index": "news3",
"version_type": "internal",
"op_type": "index"
},
"conflicts": "proceed"
}
# 重建索引之后再切换别名
POST /_aliases
{
"actions": [
{
"remove": {
"index": "news",
"alias": "news_v1"
}
},
{
"add": {
"index": "news3",
"alias": "news_v1"
}
}
]
}
# 通过别名操作索引,,查询出索引news_new3 的数据
POST /news_v1/_doc/_search
{
"query" : { "match" : { "content" : "蓝瘦" }},
"highlight" : {
"pre_tags" : ["<strong>", "<tag>"],
"post_tags" : ["</strong>", "</tag>"],
"fields" : {
"content" : {}
}
}
}
# 删除 news 索引库
DELETE /news



