1 kylin概述
Apache Kylin™是一个开源的、分布式的分析型数据仓库,提供Hadoop/Spark 之上的 SQL 查询接口及多维分析(OLAP)能力以支持超大规模数据,最初由 eBay 开发并贡献至开源社区。它能在亚秒内查询巨大的表。
国内有个kylingence公司, 将Kylin 商业化,是对开源版本的优化。
Kylin 的核心思想:预计算 + 以空间换时间。
将要从hive查询的各种统计结果,先计算出来,将计算好的结果保存成Cube(数据立方体)并存储到hbase中,供查询时直接访问。把高复杂度的聚合运算,多表连接等操作转换成对预计算结果的查询。
Kylin令使用者仅需三步即可实现:
1)根据需求,确定事实表,确定事实表中要按照哪些维度来统计,统计哪些度量。
事实表:业务表,有多个维度组成。比如:用户安装应用表(维度:用户、国家、更新时间等)、用户访问表(维度:用户、时间、地区)。
维度:对业务表按照什么统计, 什么字段就是维度,相当于 group by 的字段
度量:统计的信息,比如 count, sum , max, count(distinct ) 等。
2)基于第一步,构建数据立方体cube,并进行预计算,将结果存入hbase
这步有点像 group by 里的 with cube, 比如有2个group by字段,那有4种组合,基于这4种组合,实现多维度统计。
3)使用标准 SQL 通过 ODBC、JDBC 或 RESTFUL API 进行查询,仅需亚秒级响应时间即可获得查询结果。
在kylin 写SQL查询,kylin去hbase中给你找算好的结果。
可用一些可视化工具写SQL给kylin, kylin去hbase中给你找算好的结果, 一些和kylin相关的可视化工具:Tableau,PowerBI ,starmtbi, superset。
2 kylin架构设计
-
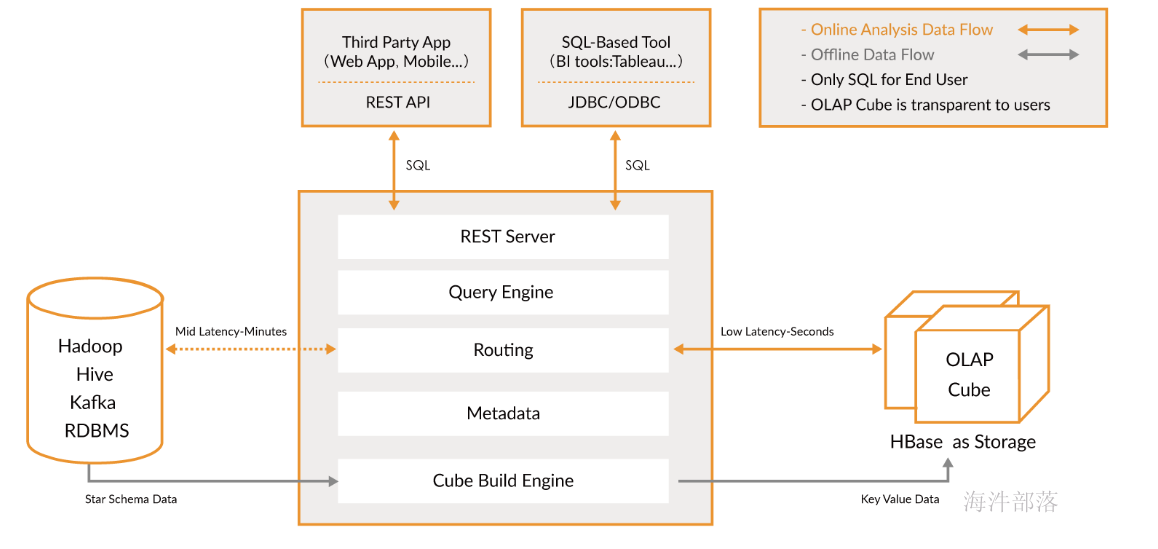
rest server
REST Server是一套面向应用程序开发的入口点,旨在实现针对Kylin平台的应用开发工作,此类应用程序可以提供查询、获取结果、触发cube构建任务、获取元数据以及获取用户权限等等,可以通过Restful接口实现SQL查询。
-
query engine
查询引擎获取并解析用户查询SQL,将查询结果返回。
-
routing
负责将解析的SQL生成的执行计划转换成cube缓存的查询,cube是通过预计算缓存在HBase中,这部分查询可以在秒级甚至毫秒级完成,还有一些操作使用过的原始数据(存储在Hadoop的hdfs中通过hive查询),这部分查询延迟较高。
-
metadata
元数据管理工具,Kylin是一款元数据驱动型应用程序,元数据管理工具是一大关键性组件,用于保存在Kylin当中的所有元数据进行管理,其中包括最为重要的cube元数据(包括cube的定义、模型的定义、job的信息、job的输出信息、维度的directory信息等),Kylin的元数据和cube都存储在HBase中。
-
cube build engine
用于处理所有离线任务,其中包括shell脚本、Java API以及MapReduce任务等等,任务引擎对Kylin当中的全部任务加以管理与协调,从而确保每一项任务都能得到切实执行并解决期间出现的障碍。
-
hbase as storage
管理底层存储,特别是cuboid,其以键值对的形式进行保存,存储引擎使用的是HBase,Kylin也可以通过扩展实现对其它键值系统的支持,例如Redis。
3 kylin基本概念
-
table
表,表定义在Hive中,是Data cube (数据立方体)的数据源。
在build cube之前,Hive表必须同步在Kylin中。
-
cardinality
维度基数,在cube设计中非常关键,是指一个数据集中一个维度下数据的个数(distinct dimension),当维度基数超过一百万则被称为超高基(Ultra High Cardinality, UHC)。
比如:用户安装应用表中,不同用户数(count(distinct aid)), 不同国家数(count(distinct country))
-
model
模型,用来定义一个Fact Table(事实表)和多个Lookup Table(查找表),及所包含的dimension(维度)列、Messures(度量)列、partition(分区)列和date(日期)格式。
-
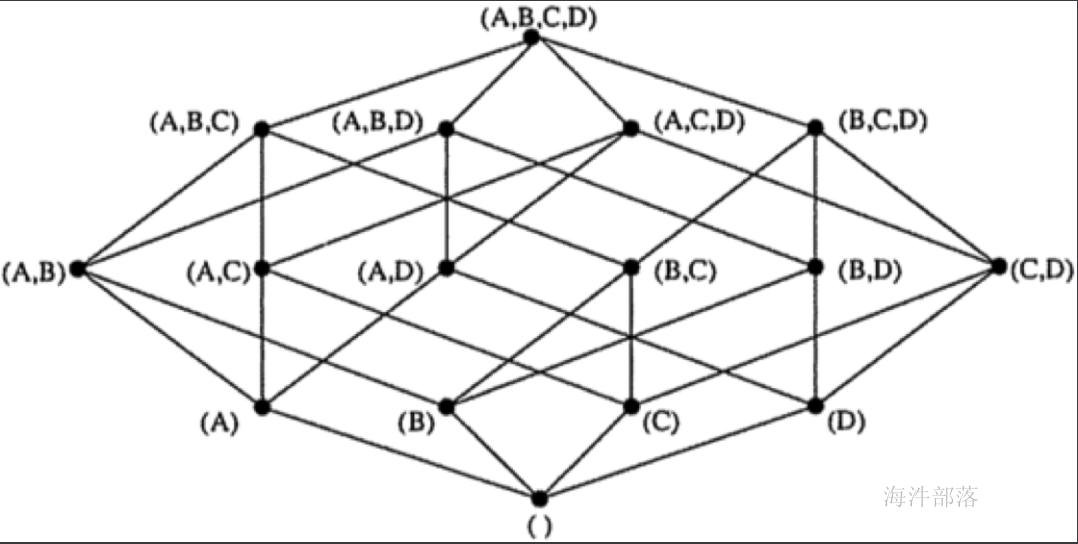
cube
数据立方体,这里面会包含所有的组合可能。
定义了使用的模型、模型中的表的维度(dimensions)、度量(messures)、如何对段分区( segments partitions)、合并段(segments auto-merge)等的规则。
1个cube --- N个cuboid
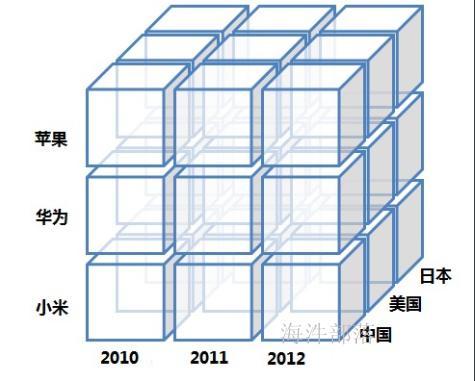
如上就为一个cube,这个cube共分为三个维度,分别为品牌、年份、国家,如果我们计算的是市场销量,那么就可以组合出各种情况的销量,如,2011年华为手机在美国的销售情况。
-
cube segments
它是cube构建后的数据载体,一个segment映射HBase中的一张表,cube实例构建后,会产生一个Segment。
-
dimension
维度,是用来描述实体的,一般是group by的字段,比如用户安装应用表中的用户、国家、时间字段。
-
measures
度量,度量就是被聚合的统计值,也是聚合运算的结果,一般指聚合函数。
比如:sum, max, count, count(distinct), topN等。
-
fact table
事实表,业务表,有多个维度组成。其列一般有两种,分别为包含事实数据的列,包含维度主键列。
比如:用户安装应用表(维度:用户、国家、时间等)、用户访问表(维度:用户、时间、地区)。
-
lookup table
查找表,是对事实表中个别列的额外描述(不是必须的)。
比如:国家字典表,可以和 用户安装应用表的国家码join。
-
dimension table
维度表,由Fact table和Lookup table抽象出来的表,包含了多个相关的列,以提供对数据不同维度的观察,其中每列的值的数目称为Cardinatily。
比如:用户安装应用表 join 国家字典表 后, 得到的结果集, 可以计算安装国家名称的统计信息。
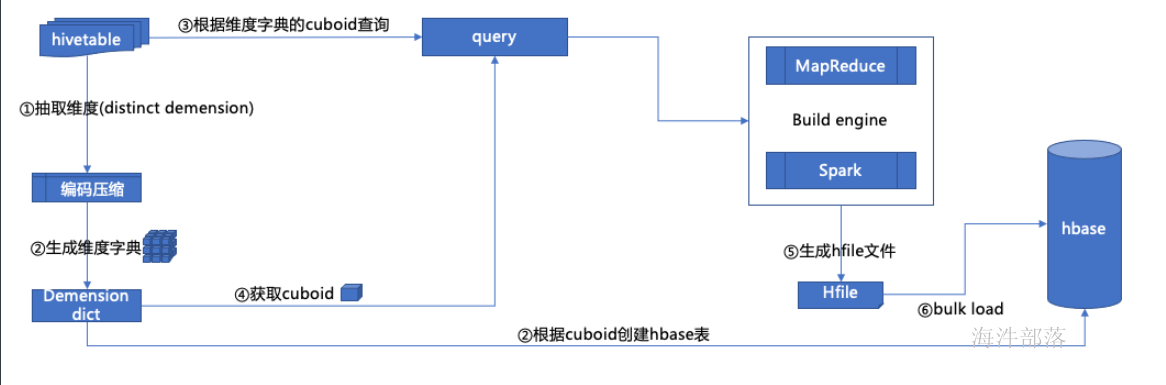
4 cube构建流程