
1 spark 概述
1.1 Spark产生的背景
MapReduce的局限性:
1)仅支持Map 和 Reduce 两种操作;
2)MapReduce多个任务的中间结果落地磁盘,不能充分利用内存,任务运行效率低;
3)适合批处理,不适合实时性要求高的场景;
4)程序编写过于复杂;
1.2 什么是Spark
Spark是一种通用的大数据计算框架,正如传统大数据技术Hadoop的MapReduce、Hive引擎,以及Storm流式实时计算引擎等。
Spark是加州大学伯克利分校AMP实验室(Algorithms, Machines, and People Lab)开发的通用内存并行计算框架,用于构建大型的、低延迟的数据分析应用程序。
Spark使用强大的Scala语言开发,它还提供了对Scala、Python、Java(支持Java 8)和R语言的支持。
Apache顶级项目,项目主页:http://spark.apache.org
1.3 Spark历史
2009年由Berkeley’s AMPLab开始编写最初的源代码
2010年开放源代码
2013年6月进入Apache孵化器项目
2014年2月成为Apache的顶级项目(8个月时间)
2014年5月底Spark1.0.0发布,打破Hadoop保持的基准排序纪录
2014年12月Spark1.2.0发布
2015年11月Spark1.5.2发布
2016年1月Spark1.6发布
2016年12月Spark2.1发布
1.4 为什么要用Spark
运行速度快:
使用DAG(全称 Directed Acyclic Graph, 中文为:有向无环图)执行引擎以支持循环数据流与内存计算(当然也有部分计算基于磁盘,比如shuffle);
易用性好:
支持使用Scala、Java、Python和R语言进行编程,可以通过Spark Shell进行交互式编程 ;
通用性强:
Spark提供了完整而强大的工具,包括SQL查询、流式计算、机器学习和图算法组件;
随处运行:
可运行于独立的集群模式中,可运行于Hadoop中,也可运行于Amazon EC2等云环境中,并且可以访问HDFS、Cassandra、HBase、Hive等多种数据源;
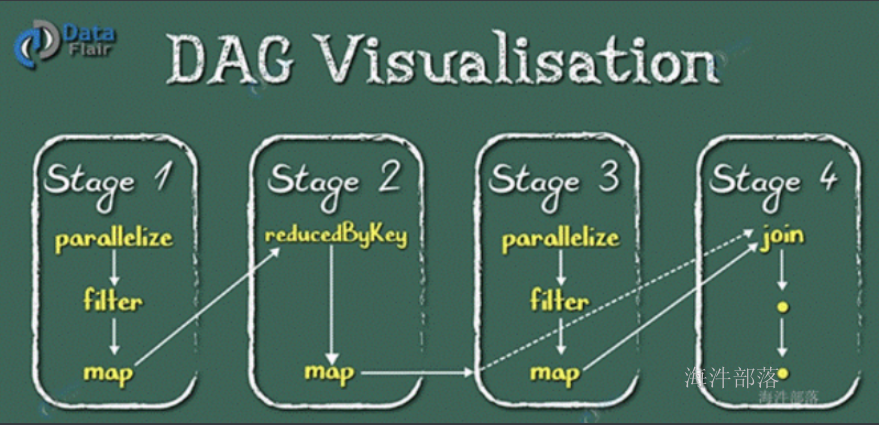
1.5 Spark 对比 Hadoop
Hadoop**:**
可以用普通硬件搭建Hadoop集群,用于解决存储和计算问题;
1)解决存储:HDFS
2)解决计算:MapReduce
3)资源管理:YARN
Spark**:**
Spark是在借鉴了MapReduce之上发展而来的,继承了其分布式并行计算的优点并改进了MapReduce明显的缺陷;
Spark不能代替Hadoop,但可能代替MapReduce。
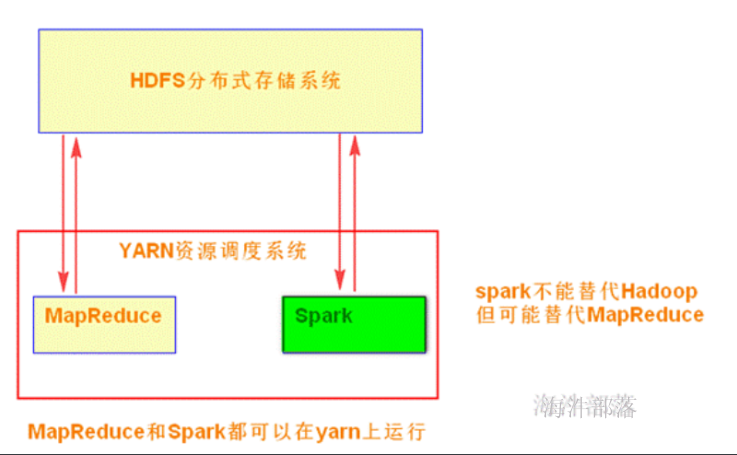
现状:
Spark主要用于大数据的计算,而Hadoop主要用于大数据的存储(HDFS),以及资源调度(Yarn)。Spark+Hadoop的组合,是未来大据领域最热门的组合,也是最有前景的组合! 当然spark也有自己的集群模式。
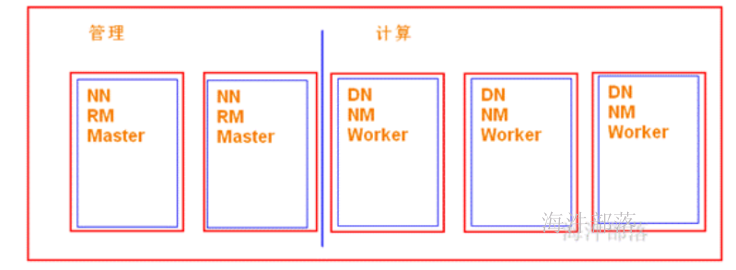
通过yarn队列去管理mr 和 spark任务的资源。
1.6 Spark 对比 MapReduce
1)spark可以把多次使用的数据放到内存中
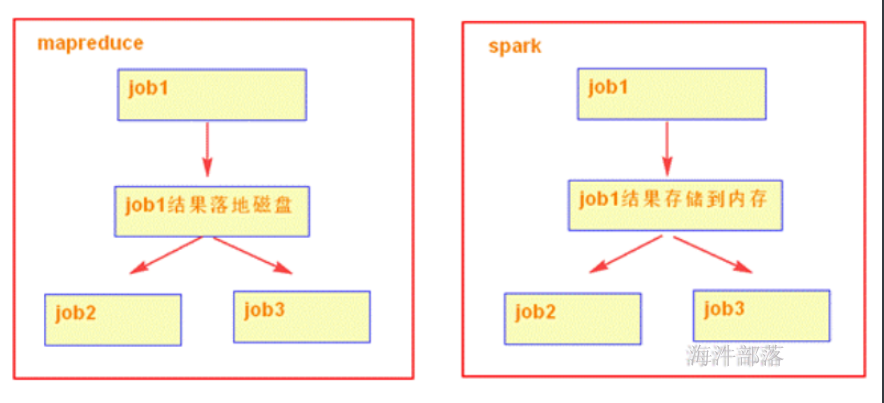
2)spark 会的算法多,方便处理数据
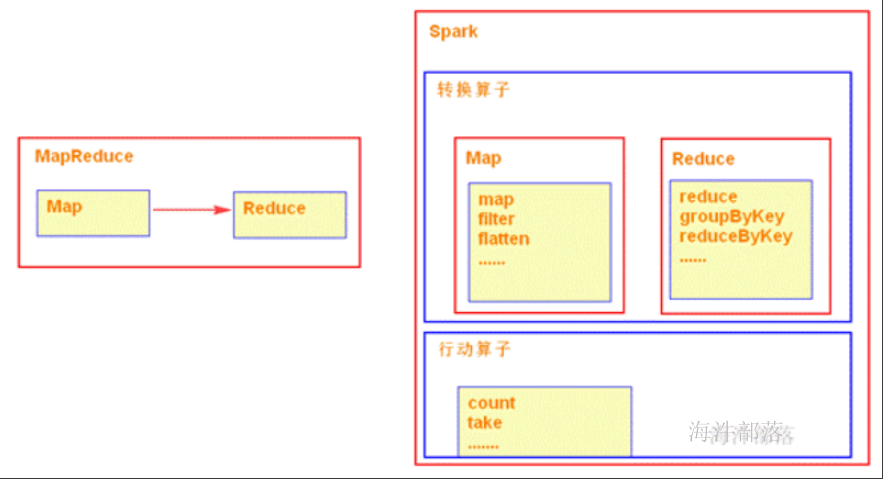
3)spark大部分算子都没有shuffle阶段,不会频繁落地磁盘,降低磁盘IO;同时这些算子可以不需要排序,省略排序的步骤。
4)在代码编写方面,不需要写那么复杂的MapReduce逻辑。
缺点:
过度依赖内存,内存不够用了就很难堪

2 spark生态
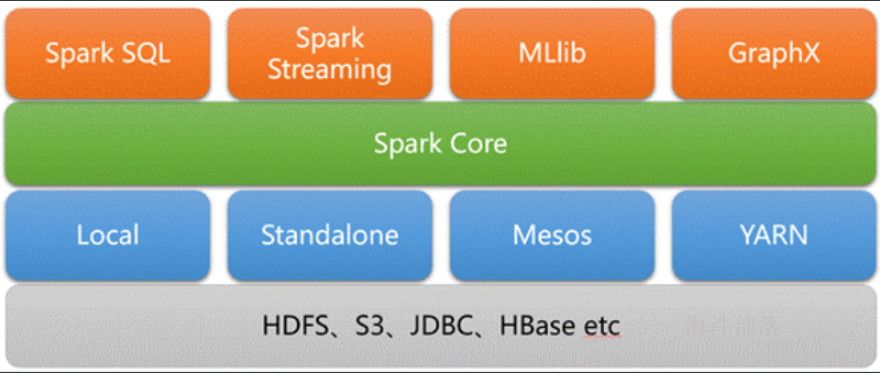
spark core**:**
实现了spark的基本功能、包括任务调度、内存管理、错误恢复与存储系统交互等模块。spark core中还包含了对弹性分布式数据集(resileent distributed dataset)的定义;
spark sql**:**
是spark用来操作结构化数据的程序,通过SPARK SQL,我们可以使用SQL或者HIVE(HQL)来查询数据,支持多种数据源,比如HIVE表就是JSON等,除了提供SQL查询接口,还支持将SQL和传统的RDD结合,开发者可以在一个应用中同时使用SQL和编程的方式(API)进行数据的查询分析,SPARK SQL是在1.0中被引入的;
Spark Streaming**:**
是Spark提供的对实时数据进行流式计算的组件,比如网页服务器日志,或者是消息队列都是数据流。
MLLib**:**
是Spark中提供常见的机器学习功能的程序库,包括很多机器学习算法,比如分类、回归、聚类、协同过滤等。
GraphX**:**
是用于图计算的比如社交网络的朋友关系图。
Spark安装
CDH6.x自带spark2.4无需升级
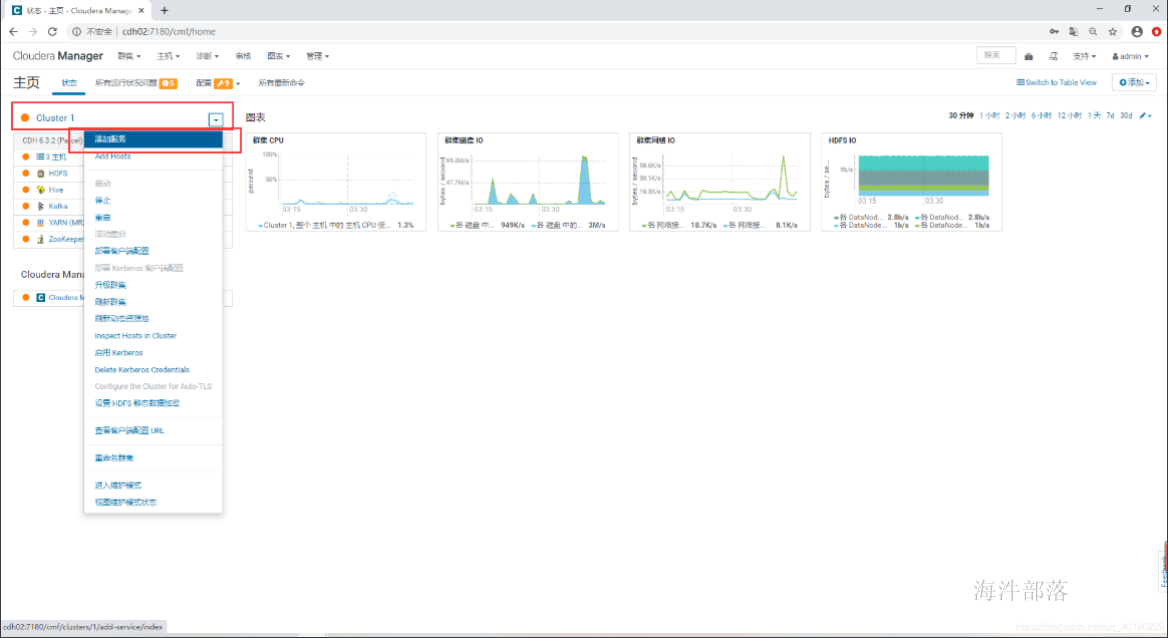
- 添加服务
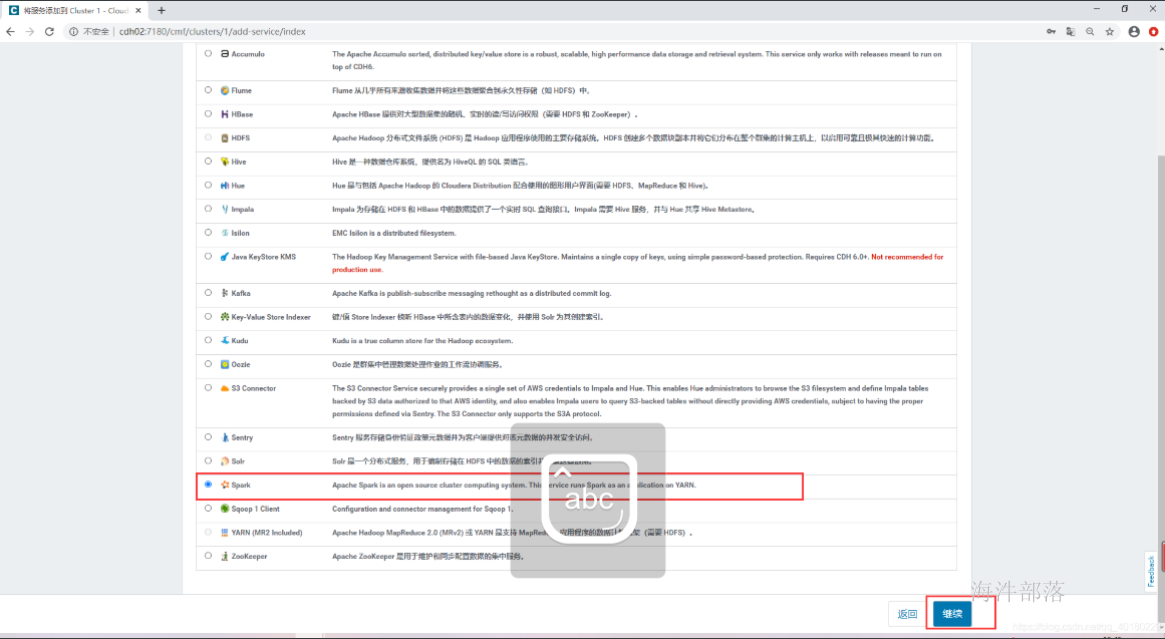
\2. 添加Spark服务
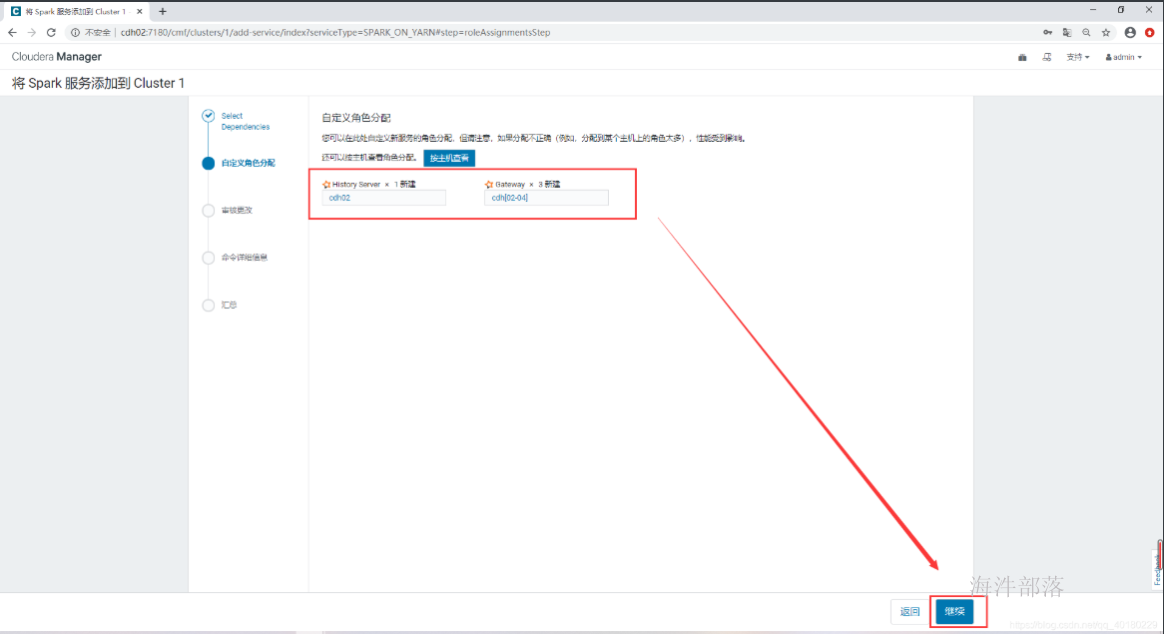
- 自定义角色分配
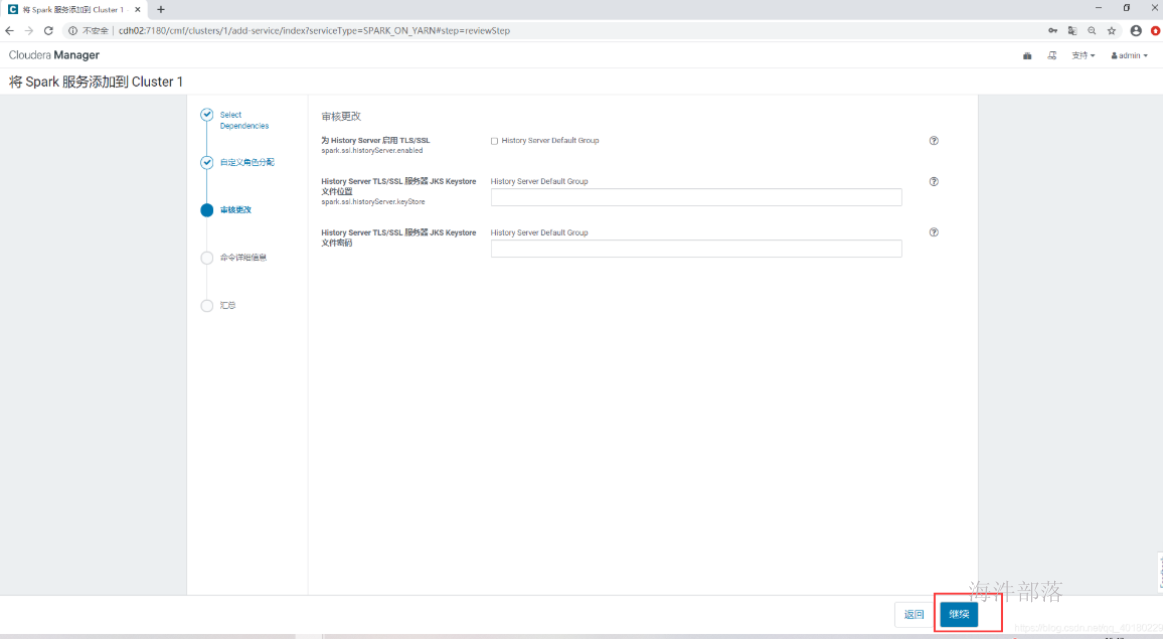
- 审核更改
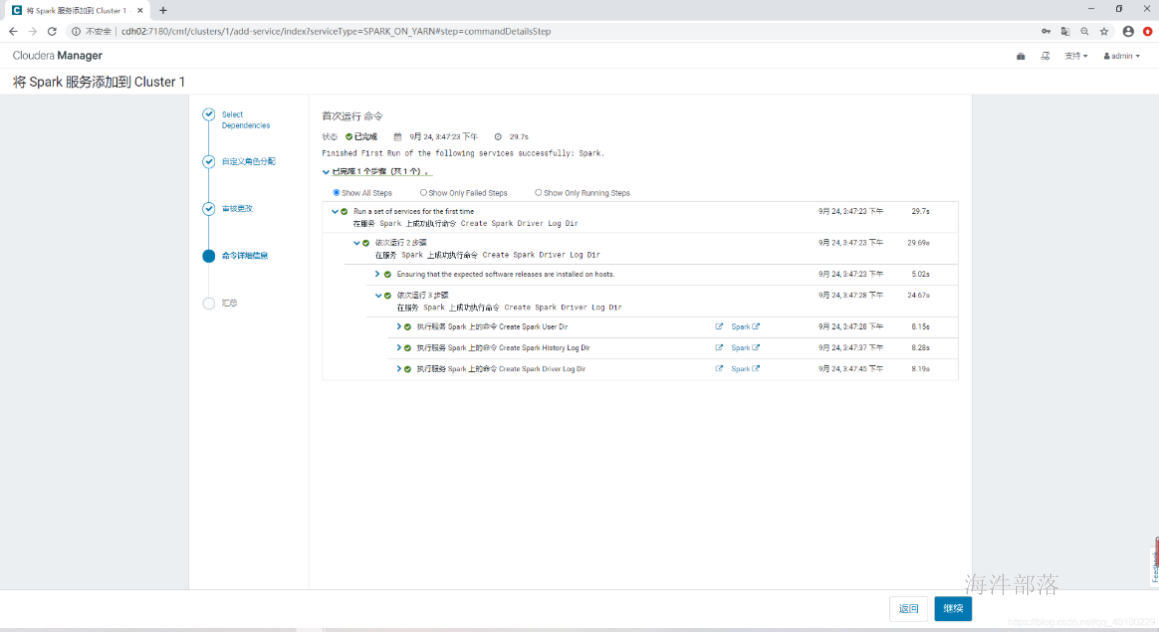
- 命令详细信息
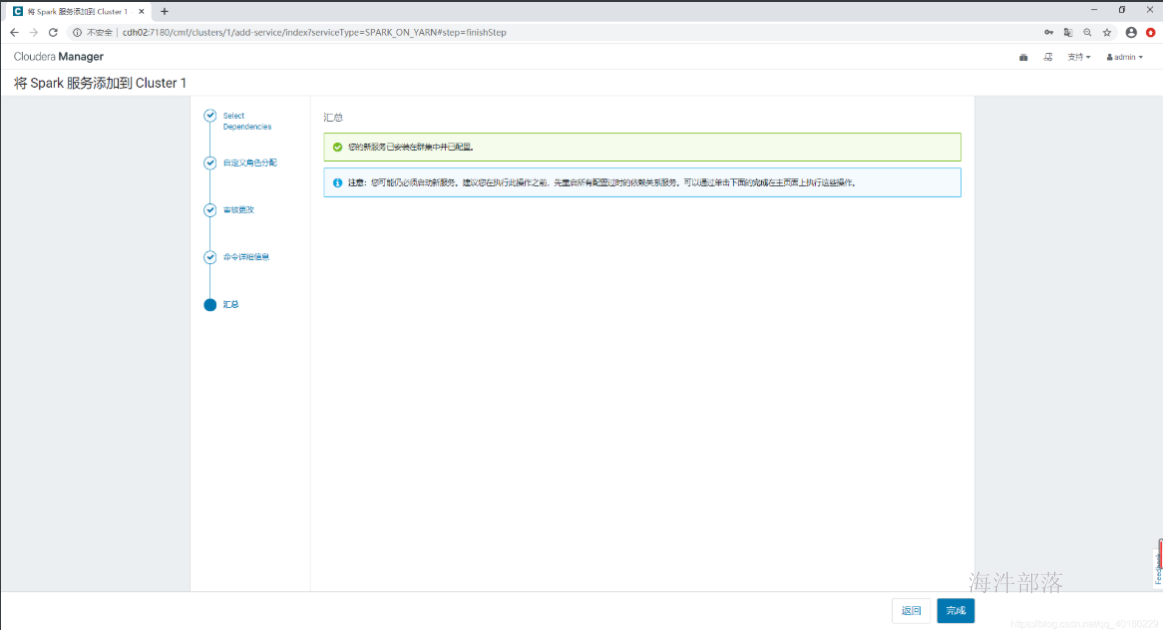
- 汇总
过期配置
添加spark主体和keytab文件
spark-submit --principal spark@HAINIU.COM --master yarn \
--keytab /data/spark.keytab \
--executor-memory 1G \
--total-executor-cores 2 \
--class org.apache.spark.examples.SparkPi \
/opt/cloudera/parcels/CDH/lib/spark/examples/jars/spark-examples_2.11-2.4.0-cdh6.3.2.jar 100
spark-shell --master yarn\
sc.textFile("hdfs://worker-1/data/xinniu/words.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).saveAsTextFile("hdfs://worker-1:/data/xinniu/wcresult")


