5 数据结构
Python中有内建的数据结构——列表(list)、元组(tuple)、字典(dict)、集合(set)
5.1 列表
list是处理一组有序的数据结构,即你可以在一个列表中存储一个 序列 的数据,并且里面的值是能够被改变的。
列表的数据项不需要具有相同的类型。
列表中的项目应该包括在方括号中,这样Python就知道你是在指明一个列表。一旦你创建了一个列表,你可以添加、删除或是搜索列表中的项目。
[1,2,3,4] 逗号分割
由于你可以增加或删除项目,我们说列表是 可变的 数据类型,即这种类型是可以被改变的。
代码示例:
# 空列表
>>>type([])
<class 'list'>
>>>list1 = [1,2,"hainiu", [1,2,3]]
# 获取列表长度
# len() 底层调用的是 __len__()
>>>len(list1)
4
>>>list1.__len__()
4
# 获取列表元素用下标0开始,和java 数组一样。
>>>list1[0]
1
# 列表的元素可改变
>>>list1[0] = 10
>>>list1
[10, 2, 'hainiu', [1, 2, 3]]
# 遍历列表的每个元素
>>>for i in list1:
>>> print(i)
10
2
hainiu
[1, 2, 3]
# 用下标方式遍历列表的每个元素
>>>for i in range(0, len(list1)):
>>> print(list1[i])
10
2
hainiu
[1, 2, 3]
# 列表是可增加、修改、删除元素
# 在列表后面追加元素
>>>list1.append(123)
# 在列表指定下标插入元素
>>>list1.insert(0, -1)
>>>list1
[-1, 10, 2, 'hainiu', [1, 2, 3], 123]
# 在列表删除某个元素
>>>list1.remove(123)
# 从列表后面pop元素,并获取到该元素的值
>>>list1.pop()
[1, 2, 3]
# 删除列表的某个元素
>>>del(list1[0])
>>>list1
[10, 2, 'hainiu']
>>>list2 = [1,5,3,2,6,4]
# 修改自身的排序(默认升序)
>>>list2.sort()
>>>list2
[1, 2, 3, 4, 5, 6]
# 修改自身的排序,降序
>>>list2.sort(reverse=True)
>>>list2
[6, 5, 4, 3, 2, 1]
# 不修改自身的排序
>>>sorted(list2)
[1, 2, 3, 4, 5, 6]
>>>list2
[6, 5, 4, 3, 2, 1]
# 一些函数
>>>sum(list2)
21
>>>max(list2)
6
>>>min(list2)
15.2 元组
元组和列表十分类似,只不过元组和字符串一样是 不可变的 即你不能修改元组。
元组的数据项不需要具有相同的类型。
元组通过圆括号中用逗号分割的项目定义。元组通常用在使语句或用户定义的函数能够安全地采用一组值的时候,即被使用的元组的值不会改变。
代码示例:
# 空元组
>>>type(())
<class 'tuple'>
# int类型
>>>type((1))
<class 'int'>
# 元组内部得是序列
>>>type((1,))
<class 'tuple'>
>>>t1 = (1,2,"hainiu", [3,4,5], (6,7))
# 元组长度
>>>len(t1)
5
# 获取元组元素
>>>t1[0]
1
>>>t1[3][2]
5
# 元组不能修改,但可以产生新元组
>>>t1 = (1,2)
>>>t2 = (3,4)
# 两个元组相加产生新元组
# + 底层调用的是 __add__()
>>>t1 + t2
(1, 2, 3, 4)
>>>t1.__add__(t2)
(1, 2, 3, 4)
# 元组相乘产生新元组
>>>t1 * 2
(1, 2, 1, 2)元组结合打印语句
%s表示字符串或%d表示整数。元组必须按照相同的顺序来对应。
name = '(●—●)'
age = 10
print('%s,是治愈系' % name)
print('%s,%d years old.'% (name,age))
#-------输出------------------------------
(●—●),是治愈系
(●—●),10 years old.元组转列表:list(t1)
列表转元组:tuple(list1)
5.3 字典
字典类似于java的map;
使用不可变的对象(比如字符串)来作为字典的键,但是你可以把不可变或可变的对象作为字典的值。基本说来就是,你应该只使用简单的对象作为键。
字典的每个键值 key=>value 对用冒号 : 分割,每个键值对之间用逗号 , 分割,整个字典包括在花括号 {} 中 ,格式如下所示:
d = {key1 : value1, key2 : value2 } 字典中的键/值对是没有顺序的。
字典是dict类的实例对象。
代码示例:
# 空字典
>>>type({})
<class 'dict'>
>>>d1 = {'a':1, 'b':'bb', 'c': [1,2,3], 'd':(4,5)}
# 获取字典长度
>>>len(d1)
4
# 获取字典中key对应的value
>>>d1['a']
1
>>>d1['c']
[1, 2, 3]
# 字典的value可修改
>>>d1['a'] = 2
>>>d1
{'a': 2, 'b': 'bb', 'c': [1, 2, 3], 'd': (4, 5)}
# 如果key不存在,则报错
>>>d1['e']
Traceback (most recent call last):
File "<input>", line 1, in <module>
KeyError: 'e'
# 判断key是否在字典中存在
>>>d1.__contains__('e')
False
>>>d1['e'] if d1.__contains__('e') else 'default'
'default'
# 调用get方法,设置默认value值
>>>d1.get('e', 'default value')
'default value'
# 添加新元素
>>>d1['f'] = 'f'
>>>d1
{'a': 2, 'b': 'bb', 'c': [1, 2, 3], 'd': (4, 5), 'f': 'f'}
# 删除f键
>>>del(d1['f'])
>>>d1
{'a': 2, 'b': 'bb', 'c': [1, 2, 3], 'd': (4, 5)}
# 删除b键
>>>d1.pop('b')
'bb'
>>>d1
{'a': 2, 'c': [1, 2, 3], 'd': (4, 5)}
# 字典遍历
# 遍历key对应的value
>>>for k in d1.keys():
>>> print(f'k:{k}, v:{d1[k]}')
k:a, v:2
k:c, v:[1, 2, 3]
k:d, v:(4, 5)
# 遍历key和value
>>>for k,v in d1.items():
>>> print(f'k:{k}, v:{v}')
k:a, v:2
k:c, v:[1, 2, 3]
k:d, v:(4, 5)
# 遍历value
>>>for v in d1.values():
>>> print(f'v:{v}')
v:2
v:[1, 2, 3]
v:(4, 5)5.4 集合set
集合(set)是一个无序的不重复元素序列。
# 空set集合
>>>type(set())
<class 'set'>
>>>set1 = set([1, "hainiu", (4,5)])
# 获取set长度
>>>len(set1)
3
# 添加元素
>>>set1.add(2)
# 判断元素是否在set中
>>>set1.__contains__(2)
True
set1
{(4, 5), 1, 2, 'hainiu'}
# 删除元素value
set1.remove(1)
>>>set1
{(4, 5), 2, 'hainiu'}
# 删除value元素,并获取
>>>set1.pop()
(4, 5)
>>>set1
{2, 'hainiu'}
# 遍历set
>>>set2 = set([1,2,3,4,5])
>>>for i in set2:
>>> print(i)
1
2
3
4
5set可以看成数学意义上的无序和无重复元素的集合,因此,两个set可以做数学意义上的交集、并集等操作:
>>>s1 = set([1,2,3])
>>>s2 = set([2,3,4])
# 交集
>>>s1 & s2
{2, 3}
# 并集
>>>s1 | s2
{1, 2, 3, 4}
# 差集
>>>s1 - s2
{1}
# 差集
>>>s2 - s1
{4}set集合存储的是不可变对象,如果是可变的对象,存入也不可变。
比如:
# 定义空类
class P1:
pass
# new对象
p = P1()
print(p)
# set集合里存储的对象时不可变的
s1 = set([1, 'aa', p])
print(s1)
print('改变p的内存指向')
p = P1()
print(p)
print(s1)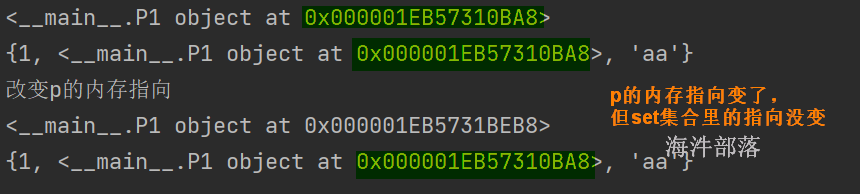
5.5 序列
列表、元组和字符串都可以看成一序列数据,序列的两个主要特点是索引操作符和切片操作符。
索引操作符让我们可以从序列中抓取一个特定项目。切片操作符让我们能够获取序列的一个切片,即一部分序列。
代码示例:
1)列表的索引操作
索引同样可以是负数,在那样的情况下,位置是从序列尾开始计算的
>>>list1 = ['aa', 'bb', 'cc', 'dd']
>>>list1[0]
'aa'
# 获取len()-1 下标元素
>>>list1[-1]
'dd'
# 获取len()-2 下标元素
>>>list1[-2]
'cc'2)列表切片
格式1:变量名[start : stop]
切片操作符是序列名后跟一个方括号,方括号中有一对可选的数字,并用冒号分割,数是可选的,而冒号是必须的。
切片操作符中的第一个数(冒号之前)表示切片开始的位置,第二个数(冒号之后)表示切片到哪里结束。
如果不指定第一个数,Python就从序列首开始。如果没有指定第二个数,则Python会停止在序列尾。注意,返回的序列从开始位置 开始 ,刚好在 结束 位置之前结束。即开始位置是包含在序列切片中的,而结束位置被排斥在切片外。
>>>list1[1:4]
[2, 3, 4]
>>>list1[:4]
[1, 2, 3, 4]
# 复制列表数据产生新列表
>>>list1[:]
[1, 2, 3, 4, 5, 6, 7, 8]格式2:变量名[start : stop : step]
3个参数分别是切片的起始下标,停止下标和步长;
方向由step确定,step为正时,从左往右切片,step为负时,从右往左切片;
start和stop的正值代表列表下标,负值代表列表从左往右数起,倒数第几个数据;
start 为空代表最左面,stop为空代表最右面,step为空代表步长默认1
>>>list1 = [1,2,3,4,5,6,7,8]
>>>list1[0:5:2]
[1, 3, 5]
>>>list1[1:6:2]
[2, 4, 6]
# 复制列表数据产生新列表
>>>list1[::]
[1, 2, 3, 4, 5, 6, 7, 8]
>>>list1[1::2]
[2, 4, 6, 8]
>>>list1[-1::-2]
[8, 6, 4, 2]3)字符串切片
字符串切片和list切片逻辑一致
name = 'one_world_one_dream'
print 'characters 4 to 9 is', name[4:9]
print 'characters 2 to end is', name[4:]
print 'characters 4 to -1 is', name[4:-1]
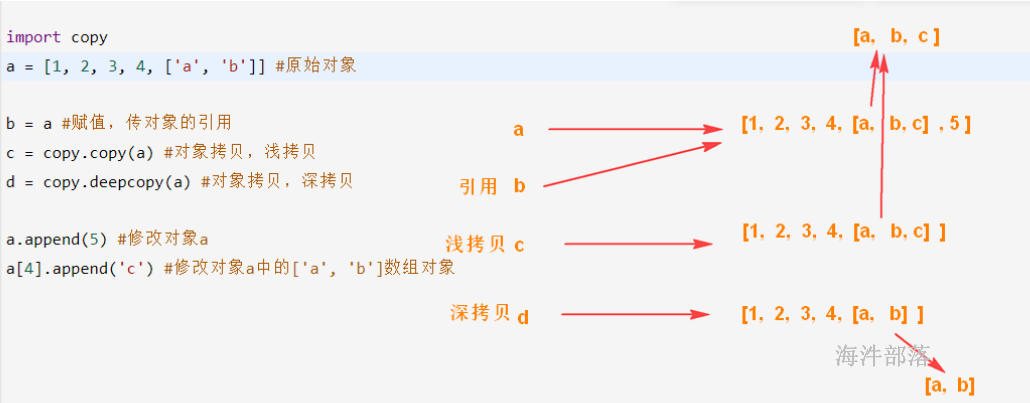
print 'characters start to end is', name[:]5.6 对象的引用、深拷贝与浅拷贝
引用:将一个对象赋给两个变量,那这两个变量指向同一内存地址;
浅拷贝:
集合内的基本类型--拷贝;
集合内的对象类型--引用指向;
深拷贝:
集合内的基本类型--拷贝;
集合内的对象类型--创建对象,拷贝数据;
代码示例
import copy
a = [1, 2, 3, 4, ['a', 'b']] #原始对象
b = a #赋值,传对象的引用
c = copy.copy(a) #对象拷贝,浅拷贝
d = copy.deepcopy(a) #对象拷贝,深拷贝
a.append(5) #修改对象a
a[4].append('c') #修改对象a中的['a', 'b']数组对象
print(f'a = {a}')
print(f'b = {b}')
print(f'c = {c}')
print(f'd = {d}')内存分配图:
5.6 常用字符串的操作
代码示例:
>>>s1 = 'aabbccddeeffggaa'
# find 查找子串的位置,如果子串不存在,返回-1
>>>s1.find('bb')
2
>>>s1.find('ff', 5)
10
>>>s1.find('mm')
-1
# index 查找子串的位置,如果子串不存在,抛异常
>>>s1.index('bb')
2
>>>s1.index('mm')
Traceback (most recent call last):
File "<input>", line 1, in <module>
ValueError: substring not found
# 判断是否以子串开始
>>>s1.startswith('aa')
True
# 判断是否以子串结尾
>>>s1.endswith('aa')
True
# 去掉多余的前后空格
>>>s2 = ' aa bb cc '
>>>s2.strip()
'aa bb cc'
# 去掉多余的前空格
>>>s2.lstrip()
'aa bb cc '
# 去掉多余的后空格
>>>s2.rstrip()
' aa bb cc'
>>>s3 = 'aa bb cc'
# 按照子串分隔成列表
>>>list1 = s3.split(' ')
>>>list1
['aa', 'bb', 'cc']
# 将字符串列表用指定字符串连接成新字符串
>>>','.join(list1)
'aa,bb,cc'
>>>ids = ['1','2','3']
# 可用于拼接字符串
>>>idstr = ','.join(ids)
>>>f'select * from user where id in ({idstr})'
'select * from user where id in (1,2,3)'
# 字符串替换
>>>sql = 'select * from <table>;'
>>>sql = sql.replace('<table>', 'user')
>>>sql
'select * from user;'6 面向对象的编程
6.1 self等于java的this
类的方法与普通的函数只有一个特别的区别——它必须有一个额外的第一个参数名称,但是在调用这个方法的时候你不为这个参数赋值,Python会提供这个值。这个特别的变量指对象本身,按照惯例它的名称是self。
假如你有一个类称为MyClass和这个类的一个实例MyObject。当你调用这个对象的方法MyObject.method(arg1, arg2)的时候,这会由Python自动转为MyClass.method(MyObject, arg1,arg2)——这就是self的原理了。
当你调用这个对象的方法
这也意味着如果你有一个不需要参数的方法,你还是得给这个方法定义一个self参数。
6.2 创建一个类
代码示例:
1)创建一个空类
#创建类
class P0:
pass # An empty block
#创建类的实例
p = P0()2)创建一个带有方法的类
# 定义类
class P1:
# 定义无参无返回值方法
# 定义方法时,不管有参无参,self永远是第一个参数,代表当前对象,相当于java的this
def say(self):
print('say hello')
# 定义有参有返回值方法
def add(self, a, b):
return a + b
def say_hello(self):
# 方法内调用方法时,需要self.xxx
self.say()
# new 对象
p1 = P1()
# P1.say(self)
p1.say()
# P1.add(self, 1, 2)
print(p1.add(1,2))
p1.say_hello()6.3 __init__方法
__init__方法在类的一个对象被建立时,马上运行。这个方法可以用来对你的对象做一些你希望的 初始化 。注意,这个名称的开始和结尾都是双下划线。
类似于java的构造方法;
代码示例:
class P2:
# 给对象赋初始值
def __init__(self, name, age):
# self.xxx 代表当前对象的属性,每个对象有自己的
self.name = name
self.age = age
print('__init__')
p2 = P2('hainiu', 10)
print(p2.name)
print(p2.age)6.4 对象初始化过程
以上面代码为例:
# 对象初始化过程
# 1)先通过元类(type)创建类实例cls
# 2) 再通过__new__() 创建对象实例self
# 3) 最后通过__init__(),给对象实例初始化数据
class P2:
# 创建对象实例self
def __new__(cls, *args, **kwargs):
print('__new__')
return super(P2, cls).__new__(cls)
# 给对象赋初始值
def __init__(self, name, age):
# self.xxx 代表当前对象的属性,每个对象有自己的
self.name = name
self.age = age
print('__init__')
p2 = P2('hainiu', 10)
print(p2.name)
print(p2.age)当实例化一个类的时候,具体的执行逻辑是这样的:
1)p2 = P2('hainiu', 10)
2)首先执行P2类的__new_方法,这个__new\_方法会 返回P2类的一个实例(通常情况下是使用
super(P2, cls).__new__(cls) 这样的方式);
3)然后利用这个实例来调用类的init方法,上一步里面new产生的实例也就是 init里面的的 self;
__init 和 \new__ 最主要的区别:
1)init 通常用于初始化一个新实例,控制这个初始化的过程,比如添加一些属性, 做一些额外的操作,发生在类实例被创建完以后。它是实例级别的方法。
2)new 通常用于控制生成一个新实例的过程。它是类级别的方法。
6.5 类变量与对象的变量
有两种类型的域 ——类的变量和对象的变量,它们根据是类还是对象 拥有 这个变量而区分。
类的变量:由一个类的所有对象(实例)共享使用。只有一个类变量的拷贝,所以当某个对象对类的变量做了改动的时候,这个改动会反映到所有其他的实例上。
对象的变量:由类的每个对象/实例拥有,因此每个对象有自己对这个域的一份拷贝,即它们不是共享的。在同一个类的不同实例中,虽然对象的变量有相同的名称,但是是互不相关的。
代码示例:
class Person:
# 类变量: 类所有,所有对象共用
# 如果修改类变量: 类名.类变量
# 如果想获取类变量:类名.类变量、self.类变量、对象名.类变量
P_COUNT = 0
def __init__(self, name, age):
print('__init__()')
# 对象变量,每个对象有自己的
self.name = name
self.age = age
# 修改类变量: 类名.类变量
Person.P_COUNT += 1
# 相当于java的toString,返回字符串
def __str__(self):
return f"p_count:{self.P_COUNT}, name:{self.name}, age:{self.age}"
# 当对象销毁时调用
def __del__(self):
print('__del__()')
p1 = Person("hainiu1", 10)
print(p1)
print(p1.P_COUNT)
p2 = Person("hainiu2", 11)
print(p2)
print(p2.P_COUNT)
print(p1.P_COUNT)
# 主动销毁对象
del(p2)
print('----------程序结束,开始销毁-------------')其中:
1)P_COUNT属于Person类,因此是一个类的变量。name变量属于对象(它使用self赋值)因此是对象的变量。
2)可以用类名或对象名或self来访问 【类变量】,但是对象的变量和方法通常用对象名或self来访问;
#----访问类变量------------
#类名.类变量
Person.P_COUNT
#self.类变量
self.P_COUNT
#对象名.类变量
p1.name 3)我们还看到docstring对于类和方法同样有用。我们可以在运行时使用 Person.doc 和 Person.print_info.doc 来分别访问类与方法的文档字符串。
4)方法del,它在对象消逝的时候被调用。但是很难保证这个方法究竟在 什么时候 运行。如果你想要指明它的运行,你就得使用del语句。
6.6 私有属性和方法
Python中所有的类成员(包括数据成员)都是公共的,如果你使用的数据成员名称以 双下划线前缀 比如__privatevar,Python的名称,管理体系会有效地把它作为私有变量。
__private_attrs:两个下划线开头,声明该属性为私有,不能在类的外部被使用或直接访问。
__private_method:两个下划线开头,声明该方法为私有方法,只能在类的内部调用 ,不能在类的外部调用。
# 私有成员,类外不可访问
class Person:
# 类变量: 类所有,所有对象共用
# 如果修改类变量: 类名.类变量
# 如果想获取类变量:类名.类变量、self.类变量、对象名.类变量
# 私有是名称前加__, 就是私有
__P_COUNT = 0
def __init__(self, name, age):
print('__init__()')
# 对象变量,每个对象有自己的
self.name = name
self.__age = age
# 修改类变量: 类名.类变量
Person.__P_COUNT += 1
# 相当于java的toString,返回字符串
def __str__(self):
return f"p_count:{self.__P_COUNT}, name:{self.name}, age:{self.__age}"
# 当对象销毁时调用
def __del__(self):
print('__del__()')
# 私有方法
def __say(self):
print("__say hello")
def pub_say(self):
self.__say()
p1 = Person("hainiu1", 10)
print(p1)
# 私有类外不可访问
# print(p1.__P_COUNT)
# print(p1.__age)
# p1.__say()
p1.pub_say()
p2 = Person("hainiu2", 11)
print(p2)
# print(p2.__P_COUNT)
# print(p1.__P_COUNT)
# 主动销毁对象
del(p2)
print('----------程序结束,开始销毁-------------')6.7 继承
面向对象的编程带来的主要好处之一是代码的重用,实现这种重用的方法之一是通过继承机制。
通过继承创建的新类称为子类或派生类,被继承的类称为基类、父类或超类。
继承语法:
class 派生类名(基类名):
...6.7.1 子类继承父类构造方法
1)如果在子类中需要父类的构造方法就需要显示的调用父类的构造方法,或者不重写父类的构造方法。子类不重写 __init__,实例化子类时,会自动调用父类定义的 __init__。
示例:
# 定义父类
class Person:
def __init__(self, name):
self.name = name
# 定义子类
class Teacher(Person):
def print_info(self):
print(f'name:{self.name}')
# 当子类继承父类时,没有重写__init__(),那就调用父类的
t1 = Teacher("liu")
t1.print_info()2)如果重写了__init__时,实例化子类,就不会调用父类已经定义的 __init__;
示例:
# 定义父类
class Person:
def __init__(self, name):
print('Person#__init__')
self.name = name
# 定义子类
class Teacher(Person):
def __init__(self, name):
print('Teacher#__init__')
self.name = name
def print_info(self):
print('name:%s' % self.name)
# 当子类继承父类时,重写__init__(),那就调用子类的
t1 = Teacher("liu")
t1.print_info()3)如果重写了__init__时,要继承父类的构造方法,可以使用下面两种方式
1) 父类名称.__init__(self,参数1,参数2,...)
# 第二种方法不需要指定具体的父类,调用super()会自动找父类的构造方法
2) super(子类,self).__init__(参数1,参数2,....)例如:
# 定义父类
class Person:
def __init__(self, name):
print('Person#__init__')
self.name = name
# 定义子类
class Teacher(Person):
def __init__(self, name, age):
# 调用父类的__init__()
# 方式1:
# Person.__init__(self,name)
# 方式2:
# super(Teacher, self).__init__(name)
# 方式3:在方式2基础上改造的通用方法
super(self.__class__, self).__init__(name)
print('Teacher#__init__')
self.age = age
def print_info(self):
print(f'name:{self.name},age:{self.age}')
# 当子类继承父类时,重写__init__(),如果想调用父类的__init__(),需要主动调用
t1 = Teacher("liu", 18)
t1.print_info()6.7.2 子类继承父类的方法
子类继承父类后,如果想调用父类的方法,也可以通过这两种方式
1) 父类名称.方法名(参数1,参数2,....)
2) super(子类,self).方法名(参数1,参数2,....)例如:
class Person:
def print_info(self):
print('Person#print_info')
class Teacher(Person):
def print_info(self):
super(self.__class__, self).print_info()
print('Teacher#print_info')
t1 = Teacher()
t1.print_info()6.7.3 多重继承
Python支持类的多继承,即在元组中写多个父类。
class 派生类名(基类名1,基类名2,...):
...例如:
class A:
def __init__(self):
print("A")
class B1(A):
def __init__(self):
A.__init__(self)
print("B1")
class B2(A):
def __init__(self):
A.__init__(self)
print("B2")
class C(B1,B2):
def __init__(self):
B1.__init__(self)
B2.__init__(self)
print("C")
c = C()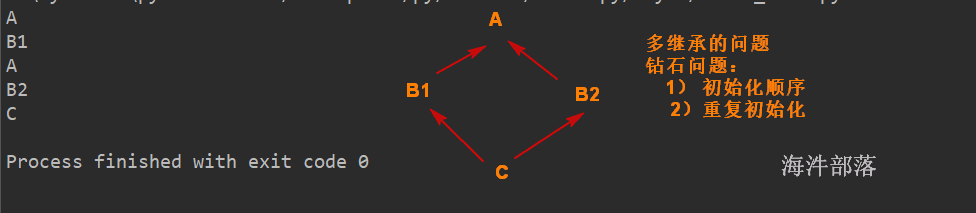
解决方法:
class A:
def __init__(self):
print("A")
class B1(A):
def __init__(self):
super(B1, self).__init__()
print("B1")
class B2(A):
def __init__(self):
super(B2, self).__init__()
print("B2")
class C(B1,B2):
def __init__(self):
super(C, self).__init__()
print("C")
c = C()
# 通过mro算法将复杂的图结构,变成线性结构
# 这样解决了初始化顺序和重复初始化问题
print(C.mro())
7 输入/输出
1)你必须先用Python内置的open()函数打开一个文件,创建一个file对象;
2)分别使用file类 的read() 、readline() 或 write() 方法来恰当地读写文件,文件的读写能力依赖于你在打开文件时指定的模式。
3)最后,当你完成对文件的操作的时候,你调用close方法来告诉Python我们完成了对文件的使用。
7.1 打开和关闭文件
1)打开文件——open()
语法:
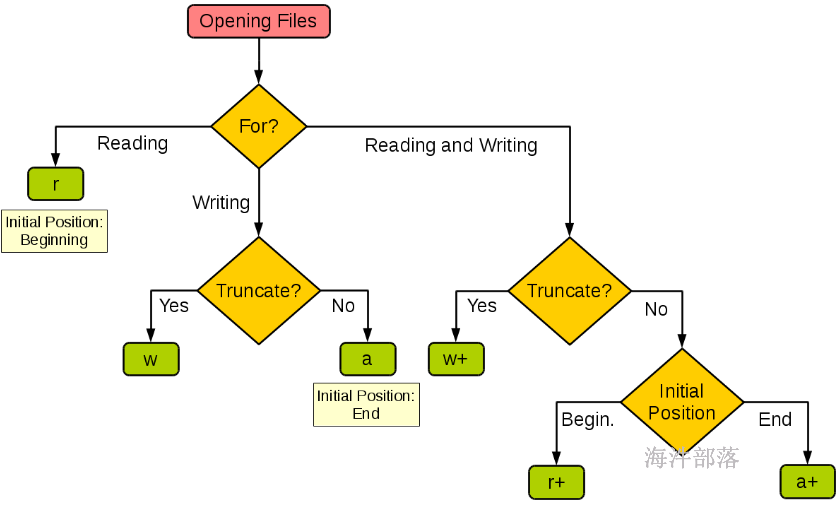
file object = open(file_name [, access_mode][, buffering])各个参数的细节如下:
file_name:file_name变量是一个包含了你要访问的文件名称的字符串值。
access_mode:access_mode决定了打开文件的模式:只读,写入,追加等。所有可取值见如下的完全列表。这个参数是非强制的,默认文件访问模式为只读(r)。
buffering:访问文件所采用的缓冲方式。
◆ 如果buffering的值被设为0,不缓冲。
◆ 如果buffering的值取1,缓冲一行。
◆ 如果将buffering的值设为大于1的整数,表明该值就是缓冲区大小。
◆ 如果取负值,使用系统默认缓冲机制,一般情况下使用系统默认缓冲机制。
文件对象访问模式
| 文件模式 | 描述 |
|---|---|
| r | 打开只读文件,该文件必须存在,否则报错 |
| r+ | 打开可读写的文件,该文件必须存在,否则报错 |
| w | 打开只写文件 若文件存在则文件长度清为0,原有文件内容消失; 若文件不存在则创建该文件。 |
| w+ | 打开可读写文件 若文件存在则文件长度清为0,原有文件内容消失;若文件不存在则创建该文件。 |
| a | 以附加的方式打开只写文件 若文件不存在,则会创建该文件;如果文件存在,写入的数据会被加到文件尾 |
| a+ | 以附加方式打开可读写的文件 若文件不存在,则会建立该文件,如果文件存在,写入的数据会被加到文件尾 |
| 上述的形态字符串都可以再加一个b字符, 如rb、w+b或ab+等组合 | 加入b 字符用来告诉函数库打开的文件为二进制文件,而非纯文字文件 |
下图很好的总结了这几种模式:
2)关闭文件——close()
File 对象的 close() 方法刷新缓冲区里任何还没写入的信息,并关闭该文件,这之后便不能再进行写入。
当一个文件对象的引用被重新指定给另一个文件时,Python 会关闭之前的文件。用 close() 方法关闭文件是一个很好的习惯。
语法:
fileObject.close()7.2 write() 和 read()
1)write() 方法
write()方法可将任何字符串写入一个打开的文件。需要重点注意的是,Python字符串可以是二进制数据,而不是仅仅是文字。
write()方法不会在字符串的结尾添加换行符('\n'):
语法:
fileObject.write(string)2)read() 方法
read() 方法从一个打开的文件中读取一个字符串。需要重点注意的是,Python字符串可以是二进制数据,而不是仅仅是文字。
语法:
fileObject.read([count]) 在这里,被传递的参数是要从已打开文件中读取的字节计数。该方法从文件的开头开始读入,如果没有传入count,它会尝试尽可能多地读取更多的内容,很可能是直到文件的末尾。
示例:
content = '''\
good good study
day day up
fighting fighting fighting
oh yeah!
'''
#将上面的内容写到content.txt 文件中
f = open('content.txt', 'w')
f.write(content)
f.close()
#以只读方式打开content.txt
f = open('content.txt')
# while True:
# # 读取一行
# line = f.readline()
# if len(line) == 0: # Zero length indicates EOF
# break
# #因为从文件读到的内容已经以换行符结尾,所以我们在print语句上使用逗号来消除自动换行
# print(line[:len(line)-1])
# 读多行
lines = f.readlines()
for line in lines:
print(line[:len(line)-1])
f.close()
#----------输出-------------------------
good good study
day day up
fighting fighting fighting
oh yeah!7.3 自动关闭文件——with open
由于文件读写时都有可能产生IOError,一旦出错,后面的f.close()就不会调用,为了保证无论是否出错都能正确地关闭文件,Python引入了with语句来自动帮我们调用close()方法。
with open('/path/to/file', 'r') as f:
print(f.read())
.....示例:
content = '''\
good good study
day day up
fighting fighting fighting
oh yeah!
'''
#将上面的内容写到content.txt 文件中
with open('content.txt', 'w') as f:
f.write(content)
#以只读方式打开content.txt
with open('content.txt') as f:
lines = f.readlines()
for line in lines:
print(line[:len(line) - 1])7.4 对象序列化与反序列化
在Python中的序列化(把变量从内存中变成可存储或传输的过程)叫 pickling。将序列化的内容重新读取到内存称作反序列化,Python中反序列化(将序列化的内容重新读取到内存)叫做 unpickling。
Python的序列化主流有两种方式,一种是使用pickle模块,一种是使用JSON格式。
pickle和json方式区别?
json :用于(不同平台和多语言)字符串和python数据类型进行转换;
pickle:用于python特有的类型和python的数据类型间进行转换(所有python数据类型);
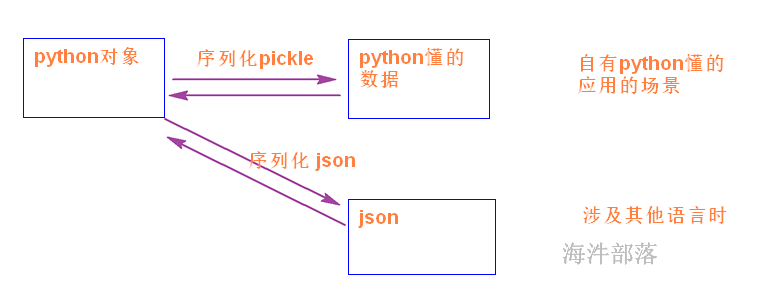
json模块提供了四个功能:dumps dump loads load;
pickle模块提供了四个功能:dumps dump loads load;
| 调用方法 | pickle模块 | json模块 |
|---|---|---|
| dumps() | 以字节对象形式返回封装的对象,不需要写入文件 | 将对象的数据转换成json,不需要写入文件 |
| dump() | 将对象的数据以字节形式写入文件中 | 将对象的数据转换成json写入文件 |
| loads() | 从字节对象中读取被封装的对象,并返回 | 将json 字符串转换成对象 |
| load() | 从文件中将字节数据转换成对象 | 读取文件,将文件中的json转换成对象 |
pickle 示例:
import pickle
list1 = ['aa', 'bb', 'cc']
print('--不写入文件的序列化和反序列化--')
data = pickle.dumps(list1)
print(data)
list2 = pickle.loads(data)
print(type(list2))
print(list2)
print('--写入文件的序列化和反序列化--')
with open('py_data', 'wb') as f:
pickle.dump(list1, f)
with open('py_data', 'rb') as f:
list3 = pickle.load(f)
print(type(list3))
print(list3)
print('--不写入文件的序列化和反序列化(自定义对象)--')
class Person:
def __init__(self, name):
self.name = name
def __str__(self):
return f"name:{self.name}"
p1 = Person("hainiu")
data = pickle.dumps(p1)
p2 = pickle.loads(data)
print(p2)
# 弱类型语言的缺点, 由于只有运行时才知道p2是什么类型,所以只能硬编码
print(p2.name)json 示例:
import json
list1 = ['aa', 'bb', 'cc']
print('--不写入文件的序列化和反序列化--')
data = json.dumps(list1)
print(data)
list2 = json.loads(data)
print(type(list2))
print(list2)
print('--写入文件的序列化和反序列化--')
with open('json_data', 'w') as f:
json.dump(list1, f)
with open('json_data') as f:
list3 = json.load(f)
print(type(list3))
print(list3)
print('--不写入文件的序列化和反序列化(自定义对象)--')
class Person:
def __init__(self, name):
self.name = name
def __str__(self):
return f"name:{self.name}"
# 定义person对象转字典函数
def person2dict(p):
return {'name': p.name}
# 定义字典转person对象
def dict2person(d):
return Person(d['name'])
p1 = Person("海牛")
# 不能直接将person对象序列化成json,需要先通过函数将person对象转成字典,然后再转成json
data_json = json.dumps(p1, default=person2dict)
# 不能直接将json反序列化成person对象,需要先将json转成字典,再通过函数将字典转成person对象
p2 = json.loads(data_json, object_hook=dict2person)
print(p2)8 异常
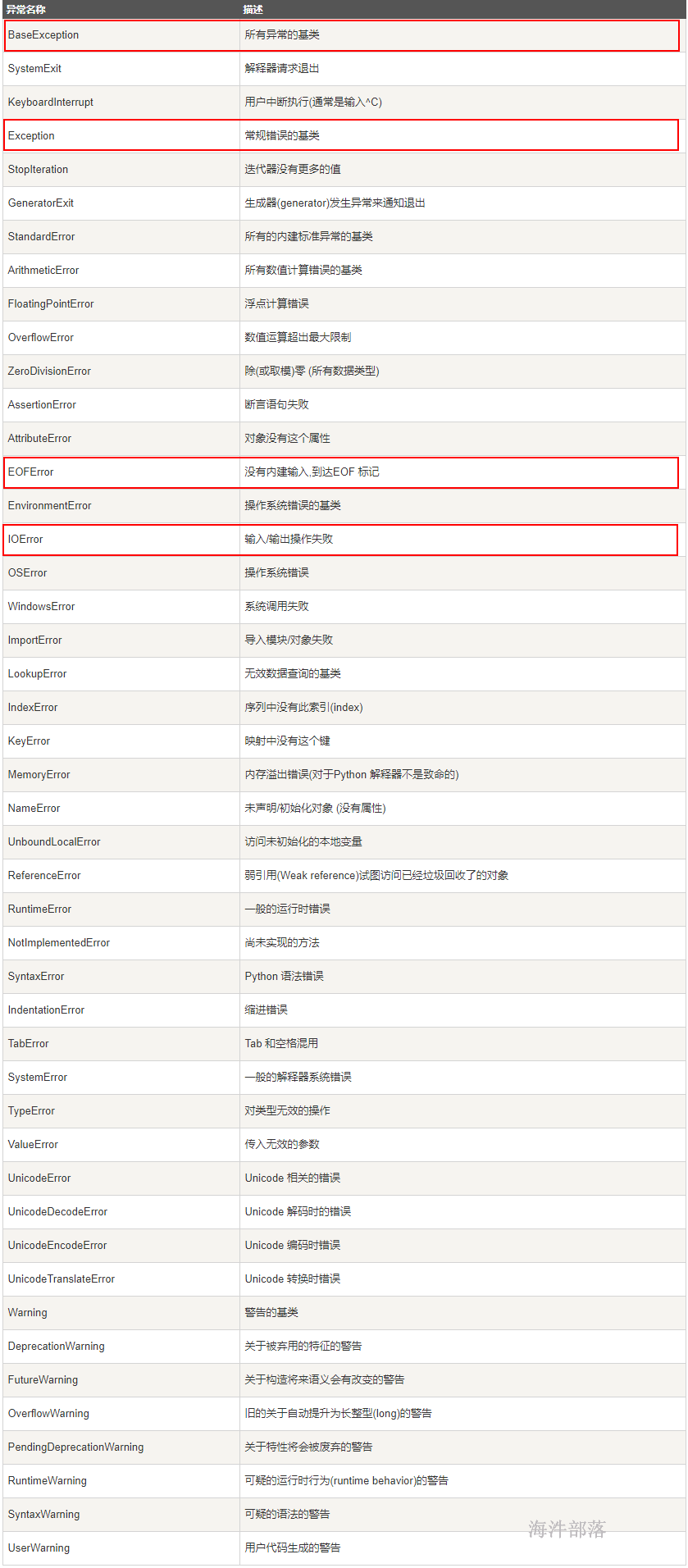
8.1 标准异常
8.2 异常处理
下面对比着java来学习python。
| java | python | |
|---|---|---|
| 捕获异常 | try{ 业务代码 }catch(Exception1 e){ 异常处理逻辑1 }catch(Exception2 e2){ 异常处理逻辑2 }finally{ 无论如何都执行 } |
import traceback try: 业务代码 except (Exception1, Exception2,...) as err: 异常处理逻辑 traceback.print_exc() else: 业务代码执行成功时,执行else 从句 finally: 无论如何都执行 |
| 抛异常 | throws: 方法上声明 throw:抛异常 | raise |
8.2.1 捕获异常
try/except 语句用来检测 try 语句块中的错误,从而让 except 语句捕获异常信息并处理。
以下为简单的try....except...else的语法:
try:
<语句> #运行别的代码
except(<异常1>, <异常2>, ...) as <异常信息>:
<语句> #如果在try部份引发了异常执行
else:
<语句> #如果没有异常发生执行
finally:
<语句> #无论如何都执行 示例:
import traceback
try:
#随机输入数据,如果直接按ctrl+d,结束,会报EOFError
s = input('Enter something --> ')
with open("content.txtt", "r") as f:
print(f.read())
except (IOError,EOFError):
# 打印异常栈信息
traceback.print_exc()
else:
print("读取文件成功")
finally:
print('无论如何都执行')8.2.2 引发异常
你可以使用raise语句引发异常。你还得指明错误/异常的名称和伴随异常触发的异常对象。你可以引发的错误或异常应该分别是一个Error或Exception类的直接或间接导子类。
raise [Exception [, args]]代码示例
import traceback
def op(num1, num2):
if num2 == 0:
# 抛异常
raise Exception("分母不能为0")
return num1/num2
try:
print(op(100, 0))
except Exception:
traceback.print_exc()
else:
print('执行了else从句')
finally:
print('无论如何都执行')8.2.3 用户自定义异常
通过创建一个新的异常类,程序可以命名它们自己的异常。异常应该是典型的继承自Exception类,通过直接或间接的方式。
代码示例:
将上面例子中的Exception 换成自定义的ZeroException
import traceback
# 定义自定义异常类
class ZeroException(Exception):
def __init__(self, err_code, err_msg):
"""
:param err_code: 错误码
:param err_msg: 错误说明
:return:
"""
self.err_code = err_code
self.err_msg = err_msg
def op(num1, num2):
if num2 == 0:
# 抛异常
raise ZeroException("err001","分母不能为0")
return num1/num2
try:
print(op(100, 0))
except ZeroException as e:
traceback.print_exc()
print(f'errcode:{e.err_code},err_msg:{e.err_msg}')
else:
print('执行了else从句')
finally:
print('无论如何都执行')8.3 断言异常
Python assert(断言)用于判断一个表达式,在表达式条件为 false 的时候触发异常。
常用于单元测试中测试极值,比如:测试列表下标越界。
list1 = [1,2,3]
assert len(list1) == 3
list1.pop()
assert len(list1) == 39 python常用的标准库
9.1 sys模块
sys.argv 命令行参数
sys.exit() 退出python程序
sys.version/version_info Python的版本信息
sys.stdin、sys.stdout和sys.stderr它们分别对应你的程序的标准输入、标准输出和标准错误流
sys.path python的"classpath"
import sys
print(sys.argv)
print(sys.path)
print(sys.version)
print(sys.version_info)
# 输出重定向到控制台,和print()一样
# sys.stdout.write("hello world")
# 输出重定向到文件
# sys.stdout = open('content.txt', 'w')
# sys.stdout.write("hello world")
# 输入重定向到控制台
# print(sys.stdin.readline())
# 输入重定向到文件
sys.stdin = open('content.txt', 'r')
print(sys.stdin.readline())9.2 os模块
这个模块包含普遍的操作系统功能。如果你希望你的程序能够与平台无关的话,这个模块是尤为重要的。即它允许一个程序在编写后不需要任何改动,也不会发生任何问题,就可以在Linux和Windows下运行。一个例子就是使用os.sep可以取代操作系统特定的路径分割符。
下面列出了一些在os模块中比较有用的部分。它们中的大多数都简单明了。
● os.name:字符串指示你正在使用的平台。比如对于Windows,它是'nt',而对于Linux/Unix用户,它是'posix'。
● os.getcwd():得到当前工作目录,即当前Python脚本工作的目录路径。
● os.getenv()和os.putenv():分别用来读取和设置环境变量。
● os.listdir():返回指定目录下的所有文件和目录名。
● os.remove():用来删除一个文件。
● os.system():用来运行shell命令。比如os.system("ls -all /")
● os.linesep:字符串给出当前平台使用的行终止符。例如,Windows使用'\r\n',Linux使用'\n'。
● os.path.split():返回一个路径的目录名和文件名。
>>> os.path.split('/home/swaroop/byte/code/poem.txt')
('/home/swaroop/byte/code', 'poem.txt')
● os.path.isfile()和os.path.isdir():分别检验给出的路径是一个文件还是目录。
● os.path.exists():用来检验给出的路径是否真地存在。
10 补充内容
10.1 特殊的方法
| 名称 | 说明 |
|---|---|
| __init__(self,...) | 这个方法在新建对象恰好要被返回使用之前被调用。 |
| __del__(self) | 恰好在对象要被删除之前调用。 |
| __str__(self) | 在我们对对象使用print语句或是使用str()的时候调用。 |
| __lt__(self,other) | 当使用 小于 运算符(<)的时候调用。类似地,对于所有的运算符 (+,>等等)都有特殊的方法。 |
| __getitem__(self,key) | 使用x[key]索引操作符的时候调用。 |
| __len__(self) | 对序列对象使用内建的len()函数的时候调用。 |
10.2 列表推导式
需求:在range(1,9) 的列表中获取偶数的平方,并返回新列表。
普通实现:
list2 = []
for i in range(1, 9):
if i % 2 == 0:
list2.append(i * i)
print(list2)推导式实现:
# for列表推导式实现
# 步骤:
# 1)遍历每个元素,筛选符合条件的元素留下
# 2)对符合条件的元素执行 i * i 得到新元素
# 3)将得到的新元素用[] 括起来,产生新列表
list2 = [i * i for i in range(1, 9) if i % 2 == 0]
print(list2)10.3 在函数中接收元组和字典
当要使函数接收元组或字典形式的参数的时候,有一种特殊的方法,它分别使用*和**前缀。这种方法在函数需要获取可变数量的参数的时候特别有用。
代码示例:
在变量前有*前缀,所有多余的函数参数都会作为一个元组存储在变量中。
# 在定义函数时,末尾参数可以是*变量名
# 当调用时,额外传过来的参数值组合成了元组
def func1(a, b, *c):
print(f'a:{a},b:{b}')
print(type(c))
print(c)
print(c[0])
func1(1,2,3)
func1(1,2,3,4,5,6,6,7,8)如果使用的是**前缀,多余的参数则会被认为是一个字典的键/值对。
# 在定义函数时,末尾参数可以是**变量名
# 当调用时,额外传过来的参数值组合成了字典
def func1(a, b, **c):
print(f'a:{a},b:{b}')
print(type(c))
print(c)
print(c['d'])
# 传递实参时,必须是关键参数
func1(1,2,d=3,e=4,f=5)10.4 exec和eval语
exec:
动态执行python代码,可以执行复杂的python代码;
eval:
将字符串str当成有效的表达式来求值并返回计算结果。它要执行的python代码只能是单个运算表达式(不支持任意形式的赋值操作),而不能是复杂的代码逻辑。
eval()函数与exec()函数的区别:
eval() 函数只能计算单个表达式的值,而 exec() 函数可以动态运行代码段;
eval() 函数有返回值;
# 动态执行字符串
# exec: 可执行多个语句,但没有返回值
exec("a=1;b=2;c=a+b;print(c)")
# eval:只能执行一个语句,但有返回值
a = 1
b = 2
def add(a,b):
return a + b
print(eval("a + b"))
print(eval("add(a,b)"))
# 可以创建对象
list2 = eval("[1,2,3,4]")
print(type(list2))
print(list2)
class Person:
def __init__(self, name):
self.name = name
# 给用户看的
def __str__(self):
return f"name:{self.name}"
p2 = eval("Person('hainiu')")
print(p2.name)
print(p2)

