1 概述
在大数据的应用场景中,hbase常用在实时读写。
写入 HBase 的方法大致有以下几种:
1)Java 调用 HBase 原生 API,HTable.add(List(Put))。
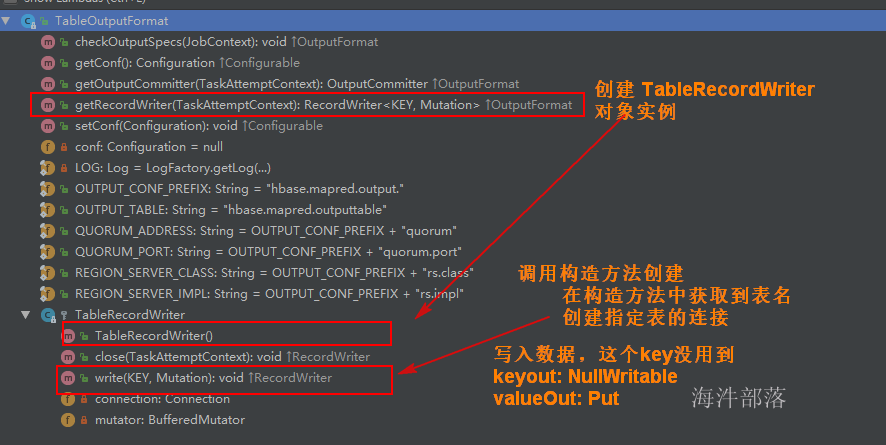
2)使用 TableOutputFormat 作为输出。
3)Bulk Load,先将数据按照 HBase 的内部数据格式生成持久化的 HFile 文件,然后复制到合适的位置并通知 RegionServer ,即完成海量数据的入库。其中生成 Hfile 这一步可以选择 MapReduce 或 Spark。
其中:
前两种适合实时写入hbase。
第三种适合将大批量的数据一次性的导入hbase。
spark没有读写hbase的api,如果想用spark操作hbase表,需要参考java和MapReduce操作hbase的api。
2 Java 调用 HBase 原生 API
用表操作对象的put(list) 批量插入数据
package com.hainiu.sparkhbase
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.hbase.client.{Connection, ConnectionFactory, HTable, Put}
import org.apache.hadoop.hbase.util.Bytes
import org.apache.hadoop.hbase.{HBaseConfiguration, TableName}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object SparkHbaseTablePuts {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkHbaseTablePuts")
val sc: SparkContext = new SparkContext(conf)
val rdd: RDD[Int] = sc.parallelize(20 until 30, 2)
// 一个分区创建一个hbase连接,批量写入,效率高
rdd.foreachPartition(it =>{
// 把每个Int 转成 Put对象
val puts: Iterator[Put] = it.map(f => {
// 创建Put对象
val put: Put = new Put(Bytes.toBytes(s"spark_puts_${f}"))
put.addColumn(Bytes.toBytes("cf"), Bytes.toBytes("count"), Bytes.toBytes(s"${f}"))
put
})
val hbaseConf: Configuration = HBaseConfiguration.create()
var conn: Connection = null
var table: HTable = null
try{
// 创建hbase连接
conn = ConnectionFactory.createConnection(hbaseConf)
// 创建表操作对象
table = conn.getTable(TableName.valueOf("panniu:spark_user")).asInstanceOf[HTable]
// 通过隐式转换,将scala的List转成javaList
import scala.collection.convert.wrapAsJava.seqAsJavaList
// 一个分区的数据批量写入
table.put(puts.toList)
}catch {
case e:Exception => e.printStackTrace()
}finally {
table.close()
conn.close()
}
})
}
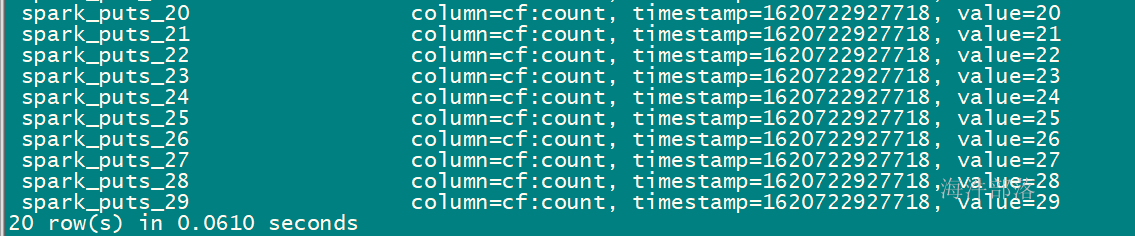
}建hbase表:

写入后查询:
3 使用 TableOutputFormat 作为输出
用TableOutputFormat 来实现写入数据
package com.hainiu.sparkhbase
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.hbase.client.{Connection, ConnectionFactory, HTable, Put}
import org.apache.hadoop.hbase.mapreduce.TableOutputFormat
import org.apache.hadoop.hbase.util.Bytes
import org.apache.hadoop.hbase.{HBaseConfiguration, TableName}
import org.apache.hadoop.io.NullWritable
import org.apache.hadoop.mapreduce.Job
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object SparkHbaseTableWrite {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkHbaseTableWrite")
val sc: SparkContext = new SparkContext(conf)
val rdd: RDD[Int] = sc.parallelize(30 until 40, 2)
// Int --> (NullWritable, Put)
val hbaseWriteRdd: RDD[(NullWritable, Put)] = rdd.map(f => {
// 创建Put对象
val put: Put = new Put(Bytes.toBytes(s"spark_write_${f}"))
put.addColumn(Bytes.toBytes("cf"), Bytes.toBytes("count"), Bytes.toBytes(s"${f}"))
(NullWritable.get(), put)
})
// 创建带有hbase连接的Hadoop Configuration对象
val hbaseConf: Configuration = HBaseConfiguration.create()
// 设置写入hbase的表名
hbaseConf.set(TableOutputFormat.OUTPUT_TABLE, "panniu:spark_user")
// 借助于mapreduce的Job对象添加参数配置
val job: Job = Job.getInstance(hbaseConf)
job.setOutputFormatClass(classOf[TableOutputFormat[NullWritable]])
job.setOutputKeyClass(classOf[NullWritable])
job.setOutputValueClass(classOf[Put])
// 当输出数据没有输出目录时,用这个api
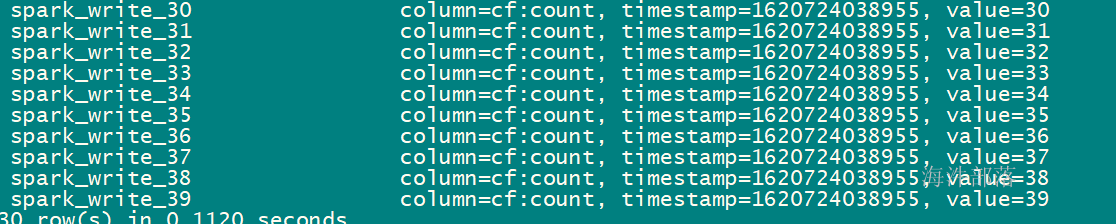
hbaseWriteRdd.saveAsNewAPIHadoopDataset(job.getConfiguration)
}
}
4 BulkLoad
先把数据转成 hfile 文件, 导入到 hbase 表。
基于下面代码实现的,通过调用这个方法,给 job 对象里面的配置对象设置了生成 hfile 文件的参数。
HFileOutputFormat2.configureIncrementalLoad(job, table.getTableDescriptor(), table.getRegionLocator()); 查看 configureIncrementalLoad() 的底层代码

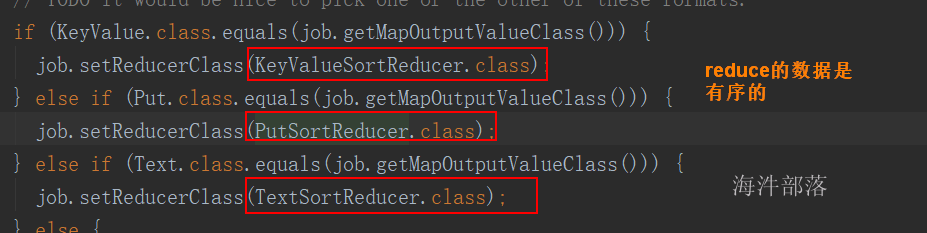
查看 PutSortReducer 类, 发现输出的key和value都是有序的。
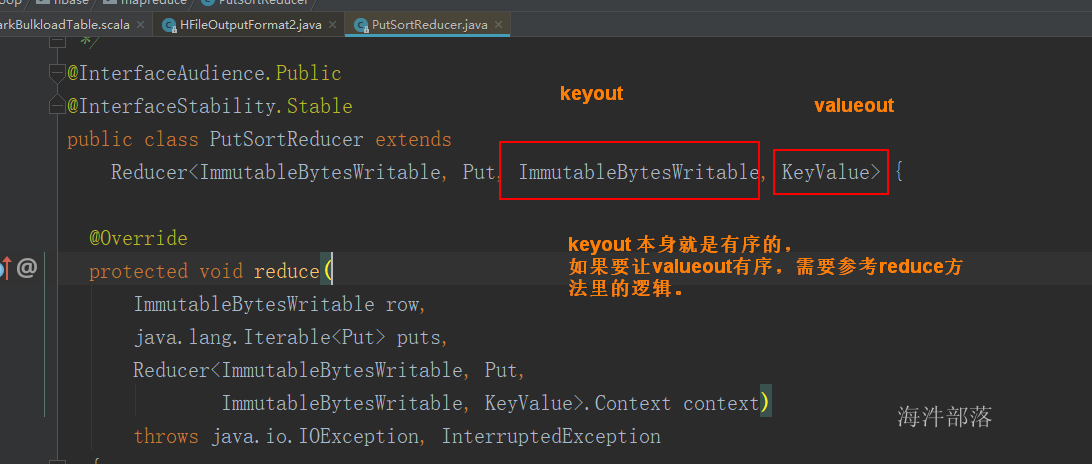
对于Spark来说,就比较直接, 直接输出 最终格式
keyout : ImmutableBytesWritable 有序
valueout:KeyValue 有序
创建hbase表:

程序:
package com.hainiu.sparkhbase
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.hbase.client.{Connection, ConnectionFactory, HTable}
import org.apache.hadoop.hbase.{HBaseConfiguration, KeyValue, TableName}
import org.apache.hadoop.hbase.io.ImmutableBytesWritable
import org.apache.hadoop.hbase.mapreduce.HFileOutputFormat2
import org.apache.hadoop.hbase.util.Bytes
import org.apache.hadoop.mapreduce.Job
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
import scala.collection.mutable.ListBuffer
object SparkHbaseBulkload {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkHbaseBulkload")
// 开启Kryo序列化
conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
val sc: SparkContext = new SparkContext(conf)
val hbaseTableName:String = "panniu:spark_load"
val rdd: RDD[Int] = sc.parallelize(10 until 50, 2)
// rdd[Int] --> rdd[(HbaseSortKey, KeyValue)]
val rdd2: RDD[(HbaseSortKey, KeyValue)] = rdd.mapPartitions(it => {
val list = new ListBuffer[(HbaseSortKey, KeyValue)]
it.foreach(f => {
val rowkey: String = s"spark_load_${f}"
val w: ImmutableBytesWritable = new ImmutableBytesWritable(Bytes.toBytes(rowkey))
val kv1: KeyValue = new KeyValue(Bytes.toBytes(rowkey), Bytes.toBytes("cf"), Bytes.toBytes("count"), Bytes.toBytes(s"${f}"))
val kv2: KeyValue = new KeyValue(Bytes.toBytes(rowkey), Bytes.toBytes("cf"), Bytes.toBytes("name"), Bytes.toBytes(s"name${f}"))
list += ((new HbaseSortKey(w, kv1), kv1))
list += ((new HbaseSortKey(w, kv2), kv2))
})
list.iterator
})
// 通过 PutSortReducer 分析发现 输出的 (ImmutableBytesWritable, KeyValue)都需要排序,
// 所以就搞个二次排序key HbaseSortKey 实现二次排序逻辑
// rdd[(HbaseSortKey, KeyValue)].sortByKey
val writeHfileRdd: RDD[(ImmutableBytesWritable, KeyValue)] = rdd2.sortByKey().map(f =>(f._1.rowkey, f._2))
// 写入文件
val outputPath:String = "/tmp/spark/hbase_bulk_output"
import com.hainiu.util.MyPredef.string2HdfsUtil
outputPath.deleteHdfs
// 创建带有Hbase配置的Configuration对象
val hbaseConf: Configuration = HBaseConfiguration.create()
// 用job来设置参数
val job: Job = Job.getInstance(hbaseConf)
val conn: Connection = ConnectionFactory.createConnection(hbaseConf)
val table: HTable = conn.getTable(TableName.valueOf(hbaseTableName)).asInstanceOf[HTable]
// 通过调用这个方法,给job对象里面的配置对象设置了生成hfile文件的参数
HFileOutputFormat2.configureIncrementalLoad(job, table.getTableDescriptor, table.getRegionLocator)
// 写入hfile文件
writeHfileRdd.saveAsNewAPIHadoopFile(outputPath,
classOf[ImmutableBytesWritable],
classOf[KeyValue],
classOf[HFileOutputFormat2],
job.getConfiguration)
}
}
// 要实现二次排序的key
class HbaseSortKey(val rowkey:ImmutableBytesWritable, val kv: KeyValue) extends Ordered[HbaseSortKey]{
override def compare(that: HbaseSortKey): Int = {
if(this.rowkey.compareTo(that.rowkey) == 0){
KeyValue.COMPARATOR.compare(this.kv, that.kv)
}else{
this.rowkey.compareTo(that.rowkey)
}
}
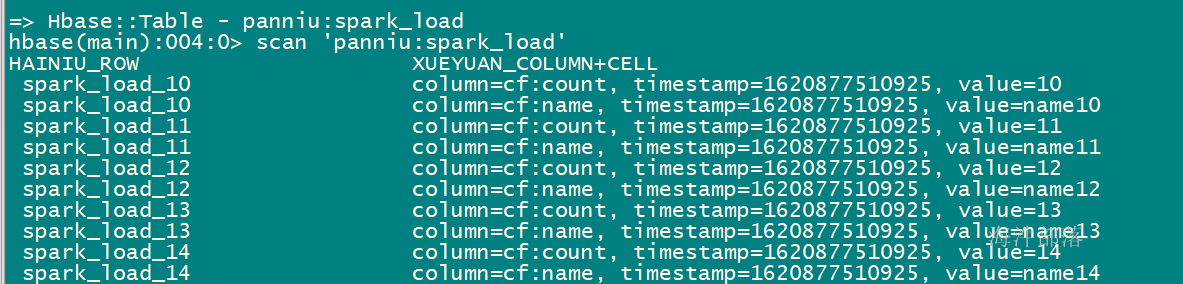
}生成hfile文件:
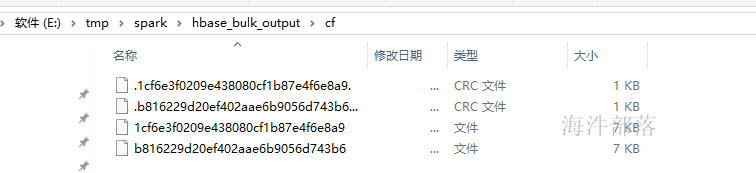
将hfile文件上传到hdfs上,并执行hbase导入

导入后查看: