kudu为何应运而生
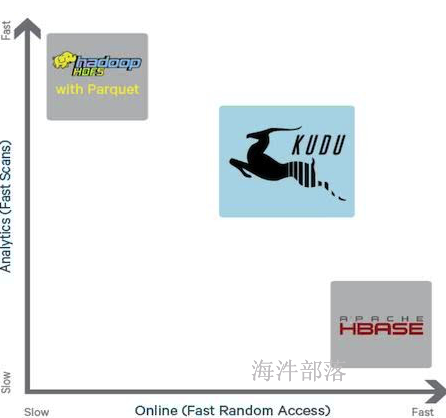
kudu 是一个针对 Apache Hadoop 平台而开发的列式存储管理器,kudu是介于hive与hbase中间的一个组件,解决了hive的随机读写问题,同时提高了hbase的读吞吐量与组合查询效率。
-
hive痛点
hive可以很高写吞吐量,但是不支持随机读写,支持组合条件查询,但是组合查询效率较低,需要全表扫或者按照分区表扫全部数据。
-
hbase痛点
hbase可以支持随机读写,并且随机读写性能很高,但是在组合查询的时候效率很低,需要全表扫描。
kudu的出现折中了hive与hbase的特性,取长补短,介于两者中间。
| hive | hbase | kudu | |
|---|---|---|---|
| 随机读写 | 不支持随机读写 | 支持随机读写,并且非常快 | 支持随机读写,但是没有hbase快 |
| 组合查询 | 支持,但是效率低下 | 支持filter过滤,但是效率非常低,与hive性能相仿,甚至不如hive的分区分桶表 | 支持组合查询,性能比hive高 |
| 分区设计 | 指定分区键或者分布键 | 按照rowkey分,采用的是range方式分区 | 支持hash、range以及hash与range组合分区 |
kudu架构
- kudu网络架构
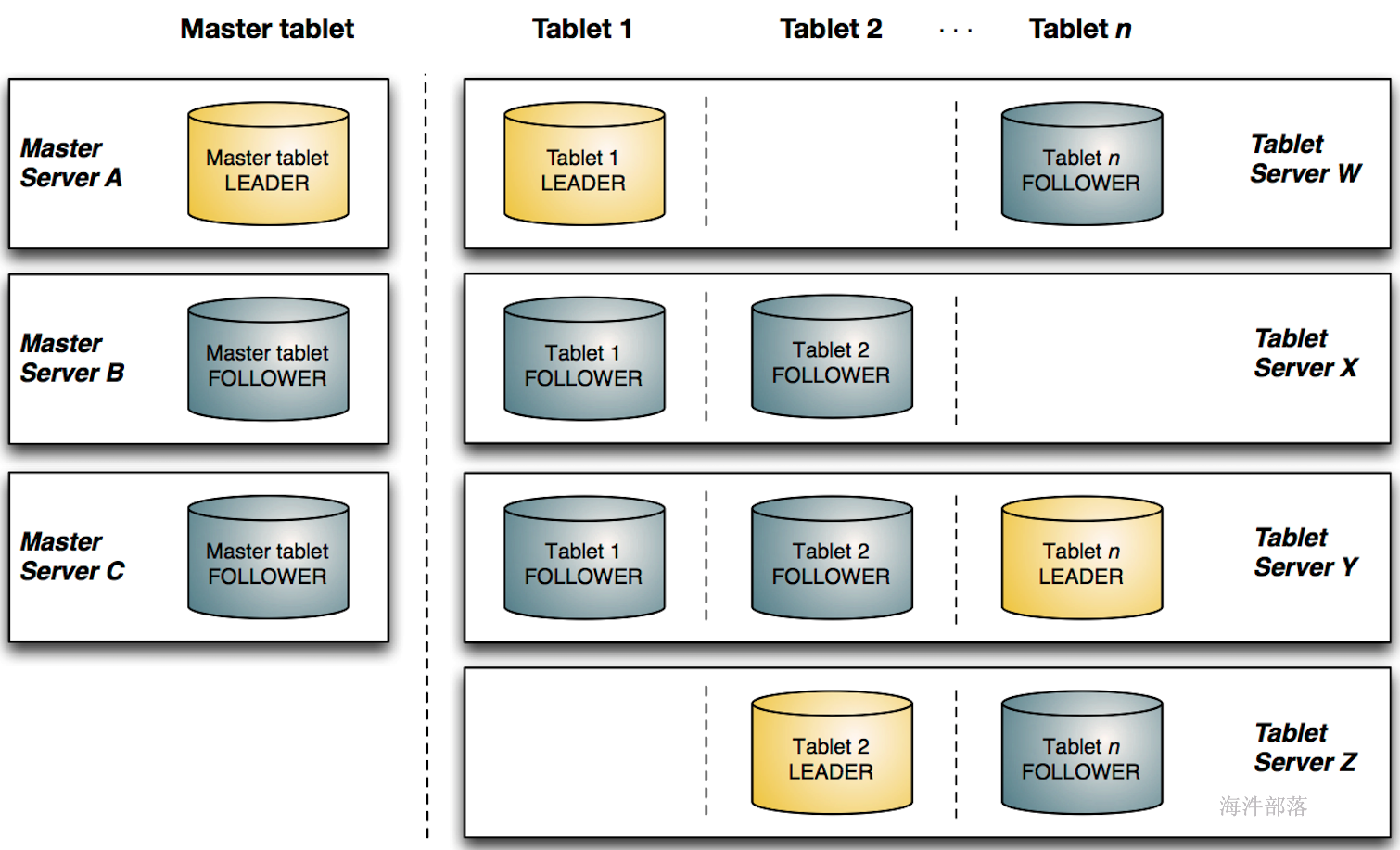
tablet分为leader与follower多副本机制,其中leader负责写服务,follower与leader一起提供读服务。
kudu由master server与tablet server两部分组成,master server负责集群管理、元数据管理等管理工作,tablet server提供数据存储、数据读写功能。
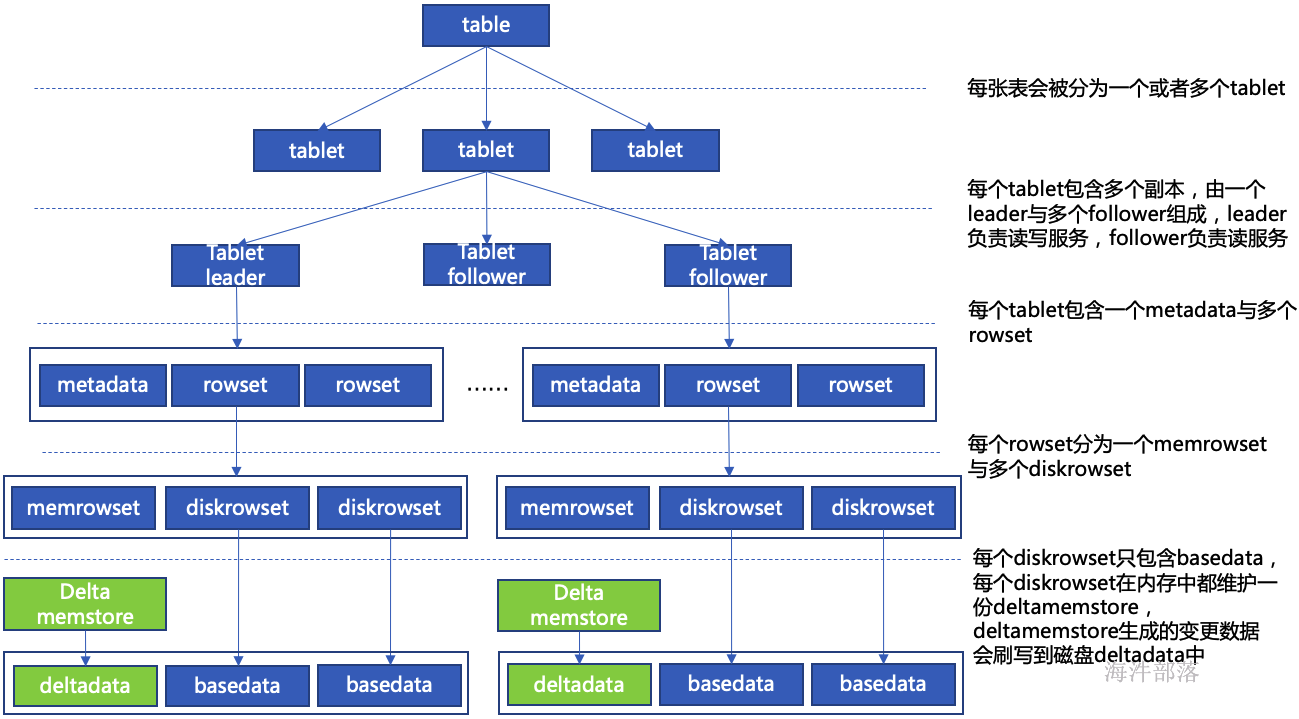
- kudu内部架构
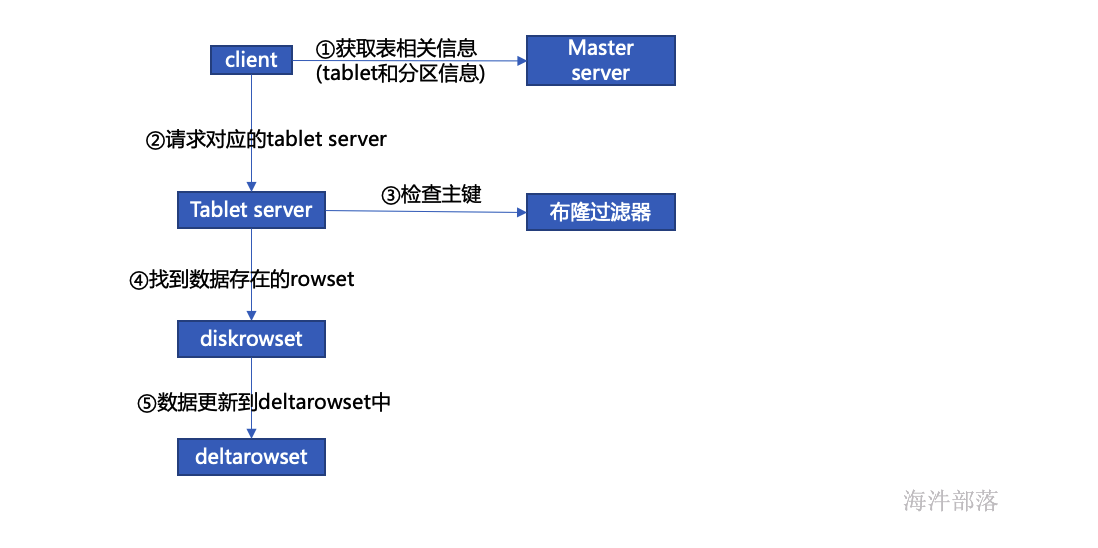
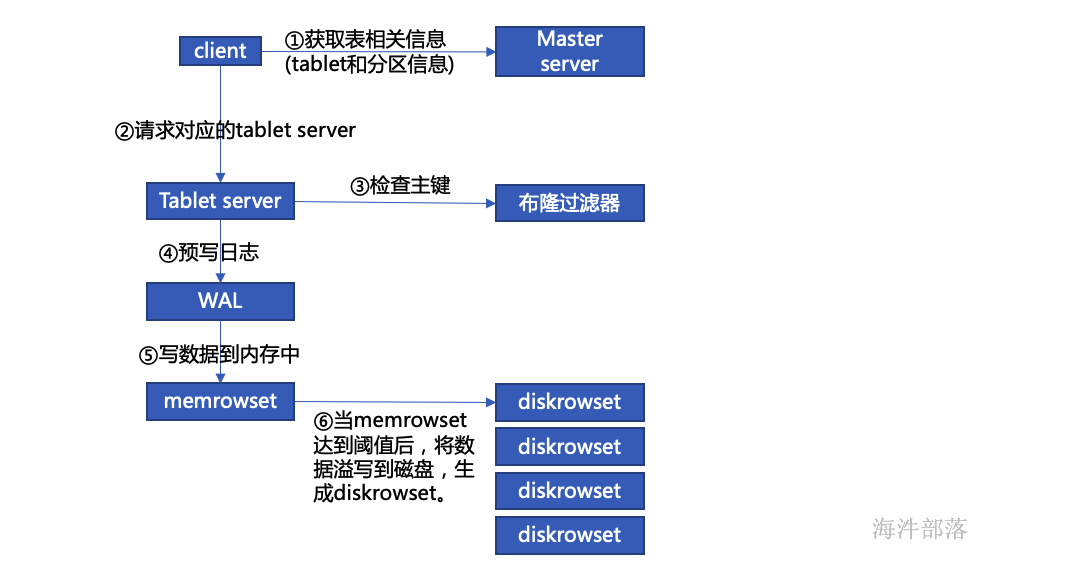
kudu写数据流程
-
检查主键
-
主键范围索引:记录本 diskrowset 中主键的范围,用于粗粒度过滤一些主键范围,使用最小和最大主键确定是否在改rowset中。
-
布隆过滤器:通过主键的布隆过滤器来实现不存在数据的过滤,布隆过滤器存在误判,但是只出现在本来不存在被误判为存在。
- 主键索引:要精确定位一个主键是否存在,以及具体在diskrowset中的位置(即:row_offset),通过以 B-树为数据结构的主键索引来快速查找。
-
-
溢写磁盘
随着持续数据写入,kudu 中的小文件会越来越多,主要包括各个diskrowset 中的basedata,还有若干份deltafile,小文件的增多会影响 kudu 的性能,特别是deltafile 中还有很多重复的数据,为了提高性能,会进行定期 compaction,compaction 主要包括两部分:
-
deltafile compaction:过多的 deltafile 影响读性能,定期将 deltafile 合并回basedata可以提升性能。在大部分业务场景,频繁变更的字段是集中在少数几个字段中的,而kudu是列式存储的,因此 kudu 还在 deltafile compaction 时做了优化,文件合并时只合并部分变更列到basedata 中对应的列。
- diskrowset compaction:除deltafile外,还定期将diskrowset 合并,原因是合并时可以将被删除的数据彻底的删除,而且可以减少同样key范围内数据的文件数,提升索引的效率。
-
kudu读数据流程
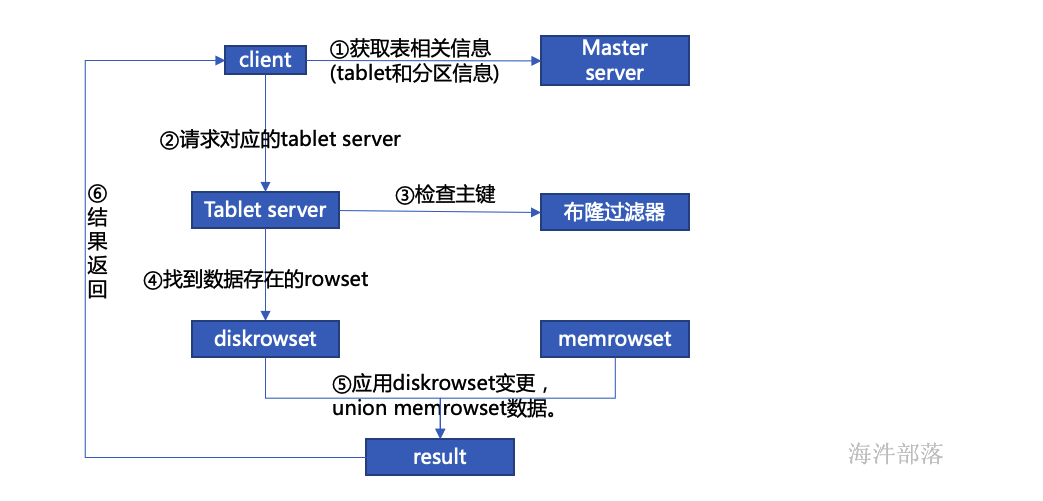
kudu更新数据流程