1 HDFS的shell命令
#查看hadoop 命令的脚本
#which查看可执行文件的位置
which hadoopfs命令调用的java类地址
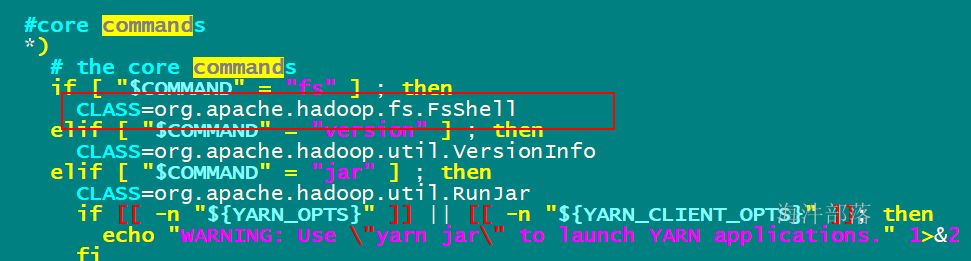
最后拼到可执行java命令里
2 HDFS的常用操作
hadoop fs 与 hdfs dfs 都调的FsShell 类
下面都用hadoop fs 命令来演示
2.1 列出文件列表 ls
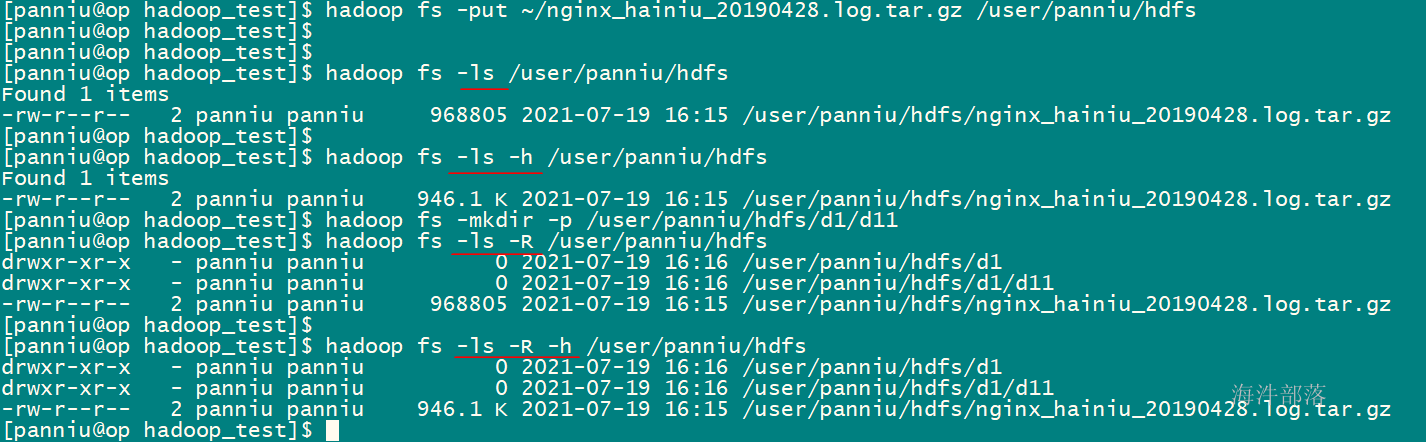
查看hdfs根目录
# 标准写法
hadoop fs -ls hdfs://ns1/
# 简写(推荐)
hadoop fs -ls /
# -h:文件大小显示为最大单位
hadoop fs -ls -h /
# -R:递归显示
hadoop fs -ls -R / 文件大小显示为最大单位

2.2 上传文件/目录 put
从主机本地系统到集群HDFS系统。
1)上传新文件
#标准写法:put 左面:是本地,右面是hdfs集群
hadoop fs -put /home/hadoop/test.txt hdfs://ns1/
#简写:右面默认找hdfs (推荐)
hadoop fs -put /home/hadoop/test.txt /
#当上传时要对文件进行重名
hadoop fs -put test.txt /t1.txt2)上传多个文件
#一次上传多个文件到HDFS路径
hadoop fs -put f1 f2 /data 3)上传目录
#上传并重命名目录
hadoop fs -put hadoop_op / 4)覆盖上传
#当上传时,hdfs存在同样的文件名时,会报文件已存在错误。
#可通过 -f 强制上传,并替换旧文件
hadoop fs -put -f test.txt /t1.txt[panniu@op hadoop_test]$ hadoop fs -ls -R -h /user/panniu/hdfs
drwxr-xr-x - panniu panniu 0 2021-07-19 16:16 /user/panniu/hdfs/d1
drwxr-xr-x - panniu panniu 0 2021-07-19 16:16 /user/panniu/hdfs/d1/d11
-rw-r--r-- 2 panniu panniu 946.1 K 2021-07-19 16:15 /user/panniu/hdfs/nginx_hainiu_20190428.log.tar.gz
# 上传
[panniu@op hadoop_test]$ hadoop fs -put ~/data.txt hdfs://ns1/user/panniu/hdfs
[panniu@op hadoop_test]$
[panniu@op hadoop_test]$ hadoop fs -ls /user/panniu/hdfs
Found 3 items
drwxr-xr-x - panniu panniu 0 2021-07-19 16:16 /user/panniu/hdfs/d1
-rw-r--r-- 2 panniu panniu 7703 2021-07-19 16:19 /user/panniu/hdfs/data.txt
-rw-r--r-- 2 panniu panniu 968805 2021-07-19 16:15 /user/panniu/hdfs/nginx_hainiu_20190428.log.tar.gz
[panniu@op hadoop_test]$
# 上传重命名
[panniu@op hadoop_test]$ hadoop fs -put ~/data.txt /user/panniu/hdfs/data2.txt
[panniu@op hadoop_test]$ hadoop fs -ls /user/panniu/hdfs
Found 4 items
drwxr-xr-x - panniu panniu 0 2021-07-19 16:16 /user/panniu/hdfs/d1
-rw-r--r-- 2 panniu panniu 7703 2021-07-19 16:19 /user/panniu/hdfs/data.txt
-rw-r--r-- 2 panniu panniu 7703 2021-07-19 16:21 /user/panniu/hdfs/data2.txt
-rw-r--r-- 2 panniu panniu 968805 2021-07-19 16:15 /user/panniu/hdfs/nginx_hainiu_20190428.log.tar.gz
[panniu@op hadoop_test]$
# 重复上传会报错
[panniu@op hadoop_test]$ hadoop fs -put ~/data.txt /user/panniu/hdfs
put: /user/panniu/hdfs/data.txt: File exists
[panniu@op hadoop_test]$
# 强制上传
[panniu@op hadoop_test]$ hadoop fs -put -f ~/data.txt /user/panniu/hdfs
[panniu@op hadoop_test]$
[panniu@op hadoop_test]$ hadoop fs -ls /user/panniu/hdfs
Found 4 items
drwxr-xr-x - panniu panniu 0 2021-07-19 16:16 /user/panniu/hdfs/d1
-rw-r--r-- 2 panniu panniu 7703 2021-07-19 16:22 /user/panniu/hdfs/data.txt
-rw-r--r-- 2 panniu panniu 7703 2021-07-19 16:21 /user/panniu/hdfs/data2.txt
-rw-r--r-- 2 panniu panniu 968805 2021-07-19 16:15 /user/panniu/hdfs/nginx_hainiu_20190428.log.tar.gz
# 多个文件同时上传
[panniu@op hadoop_test]$ touch f1
[panniu@op hadoop_test]$ touch f2
[panniu@op hadoop_test]$
[panniu@op hadoop_test]$ hadoop fs -put f1 f2 /user/panniu/hdfs
[panniu@op hadoop_test]$ hadoop fs -ls /user/panniu/hdfs
Found 6 items
drwxr-xr-x - panniu panniu 0 2021-07-19 16:16 /user/panniu/hdfs/d1
-rw-r--r-- 2 panniu panniu 7703 2021-07-19 16:22 /user/panniu/hdfs/data.txt
-rw-r--r-- 2 panniu panniu 7703 2021-07-19 16:21 /user/panniu/hdfs/data2.txt
-rw-r--r-- 2 panniu panniu 0 2021-07-19 16:26 /user/panniu/hdfs/f1
-rw-r--r-- 2 panniu panniu 0 2021-07-19 16:26 /user/panniu/hdfs/f2
-rw-r--r-- 2 panniu panniu 968805 2021-07-19 16:15 /user/panniu/hdfs/nginx_hainiu_20190428.log.tar.gz2.3 下载文件/目录 get
从集群HDFS到本地文件系统,默认左面是hdfs,右面是linux本地
#1)下载hdfs文件到本地目录
hadoop fs -get /test.txt /home/hadoop
#2)下载hdfs文件到本地目录并重命名
hadoop fs -get /test.txt /home/hadoop/test2.txt# 下载hdfs文件到本地目录
[panniu@op hadoop_test]$ hadoop fs -get /user/panniu/hdfs/d1 ./
[panniu@op hadoop_test]$ ll
总用量 0
drwxrwxr-x 3 panniu panniu 25 7月 19 16:27 d1
-rw-rw-r-- 1 panniu panniu 0 7月 19 16:26 f1
-rw-rw-r-- 1 panniu panniu 0 7月 19 16:26 f2
# 下载hdfs文件到本地目录并重命名
[panniu@op hadoop_test]$ hadoop fs -get /user/panniu/hdfs/d1 ./d1_1
[panniu@op hadoop_test]$ ll
总用量 0
drwxrwxr-x 3 panniu panniu 25 7月 19 16:27 d1
drwxrwxr-x 3 panniu panniu 25 7月 19 16:28 d1_1
-rw-rw-r-- 1 panniu panniu 0 7月 19 16:26 f1
-rw-rw-r-- 1 panniu panniu 0 7月 19 16:26 f22.4 拷贝文件/目录 cp
1)从本地到HDFS,同put,【此种方式推荐用put】
如果是本地文件,要以绝对路径表示,本地路径需要加file:
hadoop fs -cp file:/home/hadoop/test/f2 /test_f2
2)从HDFS到HDFS
# 如果是不同hdfs集群间copy用标准写法
hadoop fs -cp hdfs://ns1/haha.sh hdfs://ns1/test
hadoop fs -cp hdfs:/exe.sh hdfs:/test
# 如果是同集群,用简写
hadoop fs -cp /haha.sh /data
# 同put一样的cp linux ---> hdfs
[panniu@op hadoop_test]$ hadoop fs -cp file:/home/panniu/hadoop_test/f1 /user/panniu/hdfs/d1
[panniu@op hadoop_test]$ hadoop fs -ls /user/panniu/hdfs/d1
Found 2 items
drwxr-xr-x - panniu panniu 0 2021-07-19 16:16 /user/panniu/hdfs/d1/d11
-rw-r--r-- 2 panniu panniu 0 2021-07-19 16:31 /user/panniu/hdfs/d1/f1
[panniu@op hadoop_test]$ hadoop fs -ls /user/panniu/hdfs
Found 6 items
drwxr-xr-x - panniu panniu 0 2021-07-19 16:31 /user/panniu/hdfs/d1
-rw-r--r-- 2 panniu panniu 7703 2021-07-19 16:22 /user/panniu/hdfs/data.txt
-rw-r--r-- 2 panniu panniu 7703 2021-07-19 16:21 /user/panniu/hdfs/data2.txt
-rw-r--r-- 2 panniu panniu 0 2021-07-19 16:26 /user/panniu/hdfs/f1
-rw-r--r-- 2 panniu panniu 0 2021-07-19 16:26 /user/panniu/hdfs/f2
-rw-r--r-- 2 panniu panniu 968805 2021-07-19 16:15 /user/panniu/hdfs/nginx_hainiu_20190428.log.tar.gz
# hdfs --> hdfs 可以 copy文件、目录
[panniu@op hadoop_test]$ hadoop fs -cp /user/panniu/hdfs/d1 /user/panniu/hdfs/d1_copy
[panniu@op hadoop_test]$ hadoop fs -ls /user/panniu/hdfs
Found 7 items
drwxr-xr-x - panniu panniu 0 2021-07-19 16:31 /user/panniu/hdfs/d1
drwxr-xr-x - panniu panniu 0 2021-07-19 16:32 /user/panniu/hdfs/d1_copy
-rw-r--r-- 2 panniu panniu 7703 2021-07-19 16:22 /user/panniu/hdfs/data.txt
-rw-r--r-- 2 panniu panniu 7703 2021-07-19 16:21 /user/panniu/hdfs/data2.txt
-rw-r--r-- 2 panniu panniu 0 2021-07-19 16:26 /user/panniu/hdfs/f1
-rw-r--r-- 2 panniu panniu 0 2021-07-19 16:26 /user/panniu/hdfs/f2
-rw-r--r-- 2 panniu panniu 968805 2021-07-19 16:15 /user/panniu/hdfs/nginx_hainiu_20190428.log.tar.gz
[panniu@op hadoop_test]$ hadoop fs -ls /user/panniu/hdfs/d1_copy
Found 2 items
drwxr-xr-x - panniu panniu 0 2021-07-19 16:32 /user/panniu/hdfs/d1_copy/d11
-rw-r--r-- 2 panniu panniu 0 2021-07-19 16:32 /user/panniu/hdfs/d1_copy/f12.5 移动文件 mv
hadoop fs -mv /test_f2 /test
# hdfs ---> hdfs 目录文件均可
[panniu@op hadoop_test]$ hadoop fs -mv /user/panniu/hdfs/d1_copy /user/panniu/hdfs/d1_mv
[panniu@op hadoop_test]$ hadoop fs -ls /user/panniu/hdfs
Found 7 items
drwxr-xr-x - panniu panniu 0 2021-07-19 16:31 /user/panniu/hdfs/d1
drwxr-xr-x - panniu panniu 0 2021-07-19 16:32 /user/panniu/hdfs/d1_mv
-rw-r--r-- 2 panniu panniu 7703 2021-07-19 16:22 /user/panniu/hdfs/data.txt
-rw-r--r-- 2 panniu panniu 7703 2021-07-19 16:21 /user/panniu/hdfs/data2.txt
-rw-r--r-- 2 panniu panniu 0 2021-07-19 16:26 /user/panniu/hdfs/f1
-rw-r--r-- 2 panniu panniu 0 2021-07-19 16:26 /user/panniu/hdfs/f2
-rw-r--r-- 2 panniu panniu 968805 2021-07-19 16:15 /user/panniu/hdfs/nginx_hainiu_20190428.log.tar.gz
[panniu@op hadoop_test]$ 2.6 删除文件/目录 rm
执行-rm 命令后,默认是把文件移动到 user/hadoop/.Trash/Current 下,会根据配置文件配置的清理周期定期清理。
1)删除指定文件
hadoop fs -rm /a.txt
2)删除全部txt文件
hadoop fs -rm /*.txt
[panniu@op hadoop_test]$ hadoop fs -ls /user/panniu/hdfs
Found 7 items
drwxr-xr-x - panniu panniu 0 2021-07-19 16:31 /user/panniu/hdfs/d1
drwxr-xr-x - panniu panniu 0 2021-07-19 16:32 /user/panniu/hdfs/d1_mv
-rw-r--r-- 2 panniu panniu 7703 2021-07-19 16:22 /user/panniu/hdfs/data.txt
-rw-r--r-- 2 panniu panniu 7703 2021-07-19 16:21 /user/panniu/hdfs/data2.txt
-rw-r--r-- 2 panniu panniu 0 2021-07-19 16:26 /user/panniu/hdfs/f1
-rw-r--r-- 2 panniu panniu 0 2021-07-19 16:26 /user/panniu/hdfs/f2
-rw-r--r-- 2 panniu panniu 968805 2021-07-19 16:15 /user/panniu/hdfs/nginx_hainiu_20190428.log.tar.gz
[panniu@op hadoop_test]$
# 删除 hdfs 文件, 其实是mv到hdfs的回收站: hdfs://ns1/user/xxx/.Trash/Current
[panniu@op hadoop_test]$ hadoop fs -rm /user/panniu/hdfs/f1
21/07/19 16:37:19 INFO fs.TrashPolicyDefault: Namenode trash configuration: Deletion interval = 2880 minutes, Emptier interval = 0 minutes.
Moved: 'hdfs://ns1/user/panniu/hdfs/f1' to trash at: hdfs://ns1/user/panniu/.Trash/Current
# 在回收站查看
[panniu@op hadoop_test]$ hadoop fs -ls hdfs://ns1/user/panniu/.Trash/Current
Found 1 items
drwx------ - panniu panniu 0 2021-07-19 00:00 hdfs://ns1/user/panniu/.Trash/Current/user
[panniu@op hadoop_test]$ hadoop fs -ls hdfs://ns1/user/panniu/.Trash/Current/user/panniu/hdfs
Found 1 items
-rw-r--r-- 2 panniu panniu 0 2021-07-19 16:26 hdfs://ns1/user/panniu/.Trash/Current/user/panniu/hdfs/f1
[panniu@op hadoop_test]$
# 文件缺失进入回收站了
[panniu@op hadoop_test]$ hadoop fs -ls /user/panniu/hdfs
Found 6 items
drwxr-xr-x - panniu panniu 0 2021-07-19 16:31 /user/panniu/hdfs/d1
drwxr-xr-x - panniu panniu 0 2021-07-19 16:32 /user/panniu/hdfs/d1_mv
-rw-r--r-- 2 panniu panniu 7703 2021-07-19 16:22 /user/panniu/hdfs/data.txt
-rw-r--r-- 2 panniu panniu 7703 2021-07-19 16:21 /user/panniu/hdfs/data2.txt
-rw-r--r-- 2 panniu panniu 0 2021-07-19 16:26 /user/panniu/hdfs/f2
-rw-r--r-- 2 panniu panniu 968805 2021-07-19 16:15 /user/panniu/hdfs/nginx_hainiu_20190428.log.tar.gz
[panniu@op hadoop_test]$
# 从回收站恢复
[panniu@op hadoop_test]$ hadoop fs -mv hdfs://ns1/user/panniu/.Trash/Current/user/panniu/hdfs/f1 /user/panniu/hdfs
[panniu@op hadoop_test]$ hadoop fs -ls /user/panniu/hdfs
Found 7 items
drwxr-xr-x - panniu panniu 0 2021-07-19 16:31 /user/panniu/hdfs/d1
drwxr-xr-x - panniu panniu 0 2021-07-19 16:32 /user/panniu/hdfs/d1_mv
-rw-r--r-- 2 panniu panniu 7703 2021-07-19 16:22 /user/panniu/hdfs/data.txt
-rw-r--r-- 2 panniu panniu 7703 2021-07-19 16:21 /user/panniu/hdfs/data2.txt
-rw-r--r-- 2 panniu panniu 0 2021-07-19 16:26 /user/panniu/hdfs/f1
-rw-r--r-- 2 panniu panniu 0 2021-07-19 16:26 /user/panniu/hdfs/f2
-rw-r--r-- 2 panniu panniu 968805 2021-07-19 16:15 /user/panniu/hdfs/nginx_hainiu_20190428.log.tar.gz
# 支持模糊删除
[panniu@op hadoop_test]$ hadoop fs -rm /user/panniu/hdfs/f*
21/07/19 16:41:41 INFO fs.TrashPolicyDefault: Namenode trash configuration: Deletion interval = 2880 minutes, Emptier interval = 0 minutes.
Moved: 'hdfs://ns1/user/panniu/hdfs/f1' to trash at: hdfs://ns1/user/panniu/.Trash/Current
21/07/19 16:41:41 INFO fs.TrashPolicyDefault: Namenode trash configuration: Deletion interval = 2880 minutes, Emptier interval = 0 minutes.
Moved: 'hdfs://ns1/user/panniu/hdfs/f2' to trash at: hdfs://ns1/user/panniu/.Trash/Current
[panniu@op hadoop_test]$ hadoop fs -ls /user/panniu/hdfs
Found 5 items
drwxr-xr-x - panniu panniu 0 2021-07-19 16:31 /user/panniu/hdfs/d1
drwxr-xr-x - panniu panniu 0 2021-07-19 16:32 /user/panniu/hdfs/d1_mv
-rw-r--r-- 2 panniu panniu 7703 2021-07-19 16:22 /user/panniu/hdfs/data.txt
-rw-r--r-- 2 panniu panniu 7703 2021-07-19 16:21 /user/panniu/hdfs/data2.txt
-rw-r--r-- 2 panniu panniu 968805 2021-07-19 16:15 /user/panniu/hdfs/nginx_hainiu_20190428.log.tar.gz3)递归删除全部文件和目录
hadoop fs -rmr /dir/
hadoop fs -rm -r /dir/
[panniu@op hadoop_test]$ hadoop fs -rm /user/panniu/hdfs/d1
rm: `/user/panniu/hdfs/d1': Is a directory
[panniu@op hadoop_test]$
[panniu@op hadoop_test]$ hadoop fs -rm -r /user/panniu/hdfs/d1
21/07/19 16:42:51 INFO fs.TrashPolicyDefault: Namenode trash configuration: Deletion interval = 2880 minutes, Emptier interval = 0 minutes.
Moved: 'hdfs://ns1/user/panniu/hdfs/d1' to trash at: hdfs://ns1/user/panniu/.Trash/Current
[panniu@op hadoop_test]$ hadoop fs -rmr /user/panniu/hdfs/d1_mv
rmr: DEPRECATED: Please use 'rm -r' instead.
21/07/19 16:43:03 INFO fs.TrashPolicyDefault: Namenode trash configuration: Deletion interval = 2880 minutes, Emptier interval = 0 minutes.
Moved: 'hdfs://ns1/user/panniu/hdfs/d1_mv' to trash at: hdfs://ns1/user/panniu/.Trash/Current4)删除之后不放到回收站
hadoop fs -rm -skipTrash /dir
Moved: 'hdfs://ns1/user/panniu/hdfs/d1_mv' to trash at: hdfs://ns1/user/panniu/.Trash/Current
[panniu@op hadoop_test]$ hadoop fs -rm -skipTrash /user/panniu/hdfs/data2.txt
Deleted /user/panniu/hdfs/data2.txt
[panniu@op hadoop_test]$ hadoop fs -ls -R /user/panniu/.Trash/Current/user/panniu/hdfs
drwxr-xr-x - panniu panniu 0 2021-07-19 16:31 /user/panniu/.Trash/Current/user/panniu/hdfs/d1
drwxr-xr-x - panniu panniu 0 2021-07-19 16:16 /user/panniu/.Trash/Current/user/panniu/hdfs/d1/d11
-rw-r--r-- 2 panniu panniu 0 2021-07-19 16:31 /user/panniu/.Trash/Current/user/panniu/hdfs/d1/f1
drwxr-xr-x - panniu panniu 0 2021-07-19 16:32 /user/panniu/.Trash/Current/user/panniu/hdfs/d1_mv
drwxr-xr-x - panniu panniu 0 2021-07-19 16:32 /user/panniu/.Trash/Current/user/panniu/hdfs/d1_mv/d11
-rw-r--r-- 2 panniu panniu 0 2021-07-19 16:32 /user/panniu/.Trash/Current/user/panniu/hdfs/d1_mv/f1
-rw-r--r-- 2 panniu panniu 0 2021-07-19 16:26 /user/panniu/.Trash/Current/user/panniu/hdfs/f1
-rw-r--r-- 2 panniu panniu 0 2021-07-19 16:26 /user/panniu/.Trash/Current/user/panniu/hdfs/f22.7 读取文件 cat
查看文件内容,如果文件超过一屏幕,那不建议用
hadoop fs -cat /test.txt
2.8 读取文件尾部 tail
查看尾部1K字节
hadoop fs -tail /test.txt
2.9 创建空文件 touchz
hadoop fs - touchz /newfile.txt
2.10 追加写入文件 appendToFile
hadoop fs -appendToFile file:/test.txt hdfs:/newfile.txt #读取本地文件内容追加到HDFS文件
[panniu@op hadoop_test]$ hadoop fs -touchz /user/panniu/hdfs/f3
[panniu@op hadoop_test]$ hadoop fs -ls /user/panniu/hdfs
Found 3 items
-rw-r--r-- 2 panniu panniu 7703 2021-07-19 16:22 /user/panniu/hdfs/data.txt
-rw-r--r-- 2 panniu panniu 0 2021-07-19 17:05 /user/panniu/hdfs/f3
-rw-r--r-- 2 panniu panniu 968805 2021-07-19 16:15 /user/panniu/hdfs/nginx_hainiu_20190428.log.tar.gz
[panniu@op hadoop_test]$ hadoop fs -appendFile ~/data.txt /user/panniu/hdfs/f3
-appendFile: Unknown command
[panniu@op hadoop_test]$ hadoop fs -appendToFile ~/data.txt /user/panniu/hdfs/f3
[panniu@op hadoop_test]$ hadoop fs -ls /user/panniu/hdfs
Found 3 items
-rw-r--r-- 2 panniu panniu 7703 2021-07-19 16:22 /user/panniu/hdfs/data.txt
-rw-r--r-- 2 panniu panniu 7703 2021-07-19 17:06 /user/panniu/hdfs/f3
-rw-r--r-- 2 panniu panniu 968805 2021-07-19 16:15 /user/panniu/hdfs/nginx_hainiu_20190428.log.tar.gz2.11 创建目录 mkdir
#可以同时创建多个目录
hadoop fs -mkdir /newdir /newdir2
#同时创建父级目录
hadoop fs -mkdir -p /newpkg/newpkg2/newpkg3[panniu@op hadoop_test]$ hadoop fs -mkdir -p /user/panniu/hdfs/dd1/dd2/dd3
[panniu@op hadoop_test]$ hadoop fs -ls -R /user/panniu/hdfs/dd1
drwxr-xr-x - panniu panniu 0 2021-07-19 17:07 /user/panniu/hdfs/dd1/dd2
drwxr-xr-x - panniu panniu 0 2021-07-19 17:07 /user/panniu/hdfs/dd1/dd2/dd32.12 改变文件副本数 setrep
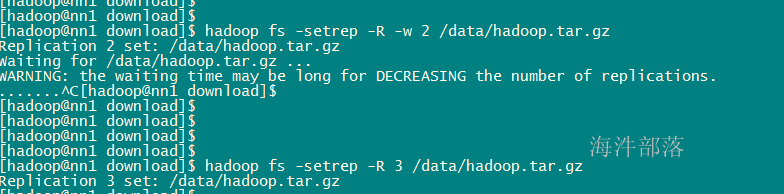
hadoop fs -setrep -R -w 2 /test.txt
-R 递归改变目录下所有文件的副本数。
-w 等待副本数调整完毕后返回。可理解为加了这个参数就是阻塞式的了。

如果想修改块大小,修改配置hdfs-site.xml dfs.blocksize 属性
2.13 获取逻辑空间文件/目录大小 du
#显示HDFS根目录中各文件和文件夹大小
hadoop fs - du /
#以最大单位显示HDFS根目录中各文件和文件夹大小
hadoop fs -du -h /
#仅显示HDFS根目录大小。即各文件和文件夹大小之和
hadoop fs -du -s /[panniu@op ~]$ hadoop fs -du /user/panniu/hdfs
7703 /user/panniu/hdfs/data.txt
0 /user/panniu/hdfs/dd1
7703 /user/panniu/hdfs/f3
968805 /user/panniu/hdfs/nginx_hainiu_20190428.log.tar.gz
[panniu@op ~]$ hadoop fs -du -s /user/panniu/hdfs
984211 /user/panniu/hdfs
[panniu@op ~]$
[panniu@op ~]$ hadoop fs -du -s -h /user/panniu/hdfs
961.1 K /user/panniu/hdfs
[panniu@op ~]$ hadoop fs -du -s -h /user/panniu
28.1 G /user/panniu3 管理工具hadoop dfsadmin
hdfs dfsadmin
例如:hadoop dfsadmin -report
dfsadmin命令详解
1) -report:
查看文件系统的基本信息和统计信息。
2)-safemode :
安全模式命令。安全模式是NameNode的一种状态,在这种状态下,NameNode不接受对名字空间的更改(只读);不复制或删除块。NameNode在启动时自动进入安全模式,当配置块的最小百分数满足最小副本数的条件时,会自动离开安全模式。enter是进入,leave是离开。
#进入安全模式
hdfs dfsadmin -safemode enter
#离开安全模式
hdfs dfsadmin -safemode leave
#获取安全模式信息
hdfs dfsadmin -safemode get3) -refreshNodes:
重新读取hosts和exclude文件,使新的节点或需要退出集群的节点能够被NameNode重新识别。这个命令在新增节点或注销节点时用到。
如何动态增加节点?
新增一台s4
1)s4 机器基础环境必须搞好(host、ssh、免密登录root),简单方式直接从s3 克隆一台,注意:要把s4机器上的/data/dfs 目录删掉,因为在启动datanode 节点时会自动在/data/目录下创建dfs目录。
将当前开启的窗口平铺
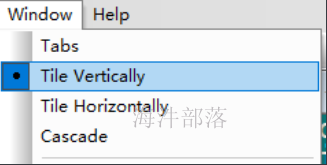

这样所有开启的窗口,一起执行命令echo "192.168.142.165 s4.hadoop" >> /etc/hosts
2)在 etc/hadoop/slave 文件中追加 s4 的主机名
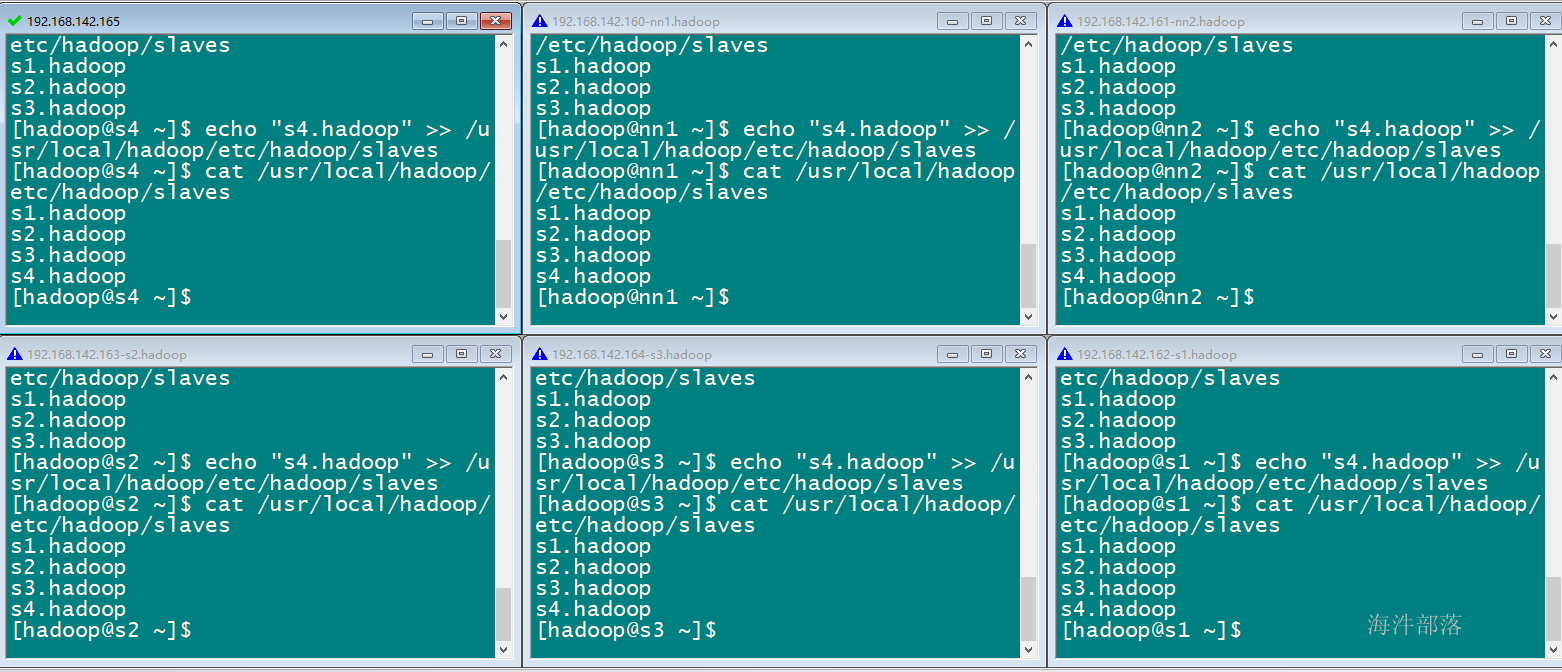
3)在s4 机器上用 hadoop-daemon.sh star datanode 启动s4机器上的datanode
5)用 hdfs dfsadmin -refreshNodes
6)先让nn1.hadoop 记录 s4.hadoop 的ssh 信息:在nn1.hadoop上用hadoop用户执行: ssh s4.hadoop
如何动态删除节点?
1)在hdfs-site.xml 追加属性dfs.hosts.exclude, 该属性配置的参数是配置要删除节点机器的主机名。
<property>
<name>dfs.hosts.exclude</name>
<value>/usr/local/hadoop/etc/hadoop/excludes</value>
</property>2)在excludes文件中配置要删除节点的主机名
3)分发hdfs-site.xml 和 exludes 文件
4)执行命令 hdfs dfsadmin -refreshNodes,查看WEBUI,节点状态在Decommission In Progress,在将退役节点的数据往其他机器迁移
5)当所有的要退役的节点都报告为Decommissioned,数据迁移工作已经完成
注意:【退役后的节点数要≥ 设置的副本数,否则会一直留在退役中】。
解释:
① 设置hdfs副本数为2
② 上传数据到hdfs,会有两个副本
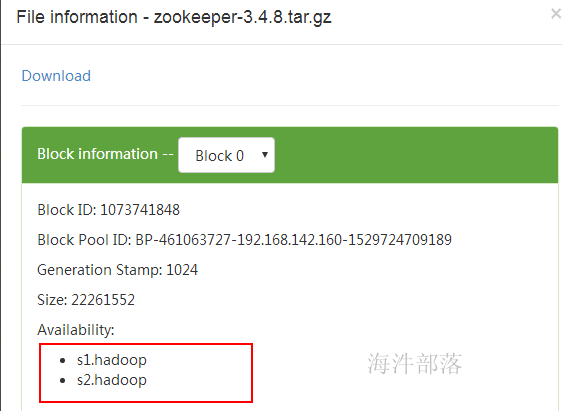
③ 将三个datanode机器的s2.hadoop 退役,webUI显示s2.hadoop 正在退役,在退役时,会复制该节点数据到其他节点
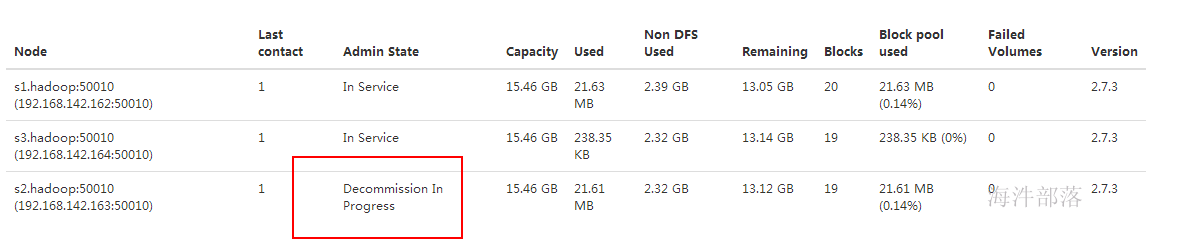
④ 已经将s2.hadoop 数据复制到了s3.hadoop上,当复制完成后,就变成已退役状态。

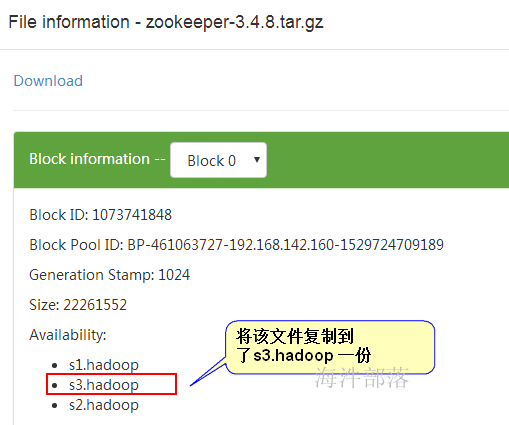
⑤ 查看 /zookeeper-3.4.8.tar.gz 文件块位置
4) -metasave filename:
保存NameNode的主要数据结构到hadoop.log.dir属性指定的目录下的 文件中。
#在hadoop日志目录下创建namenode的数据结构信息
hdfs dfsadmin -metasave namenode_data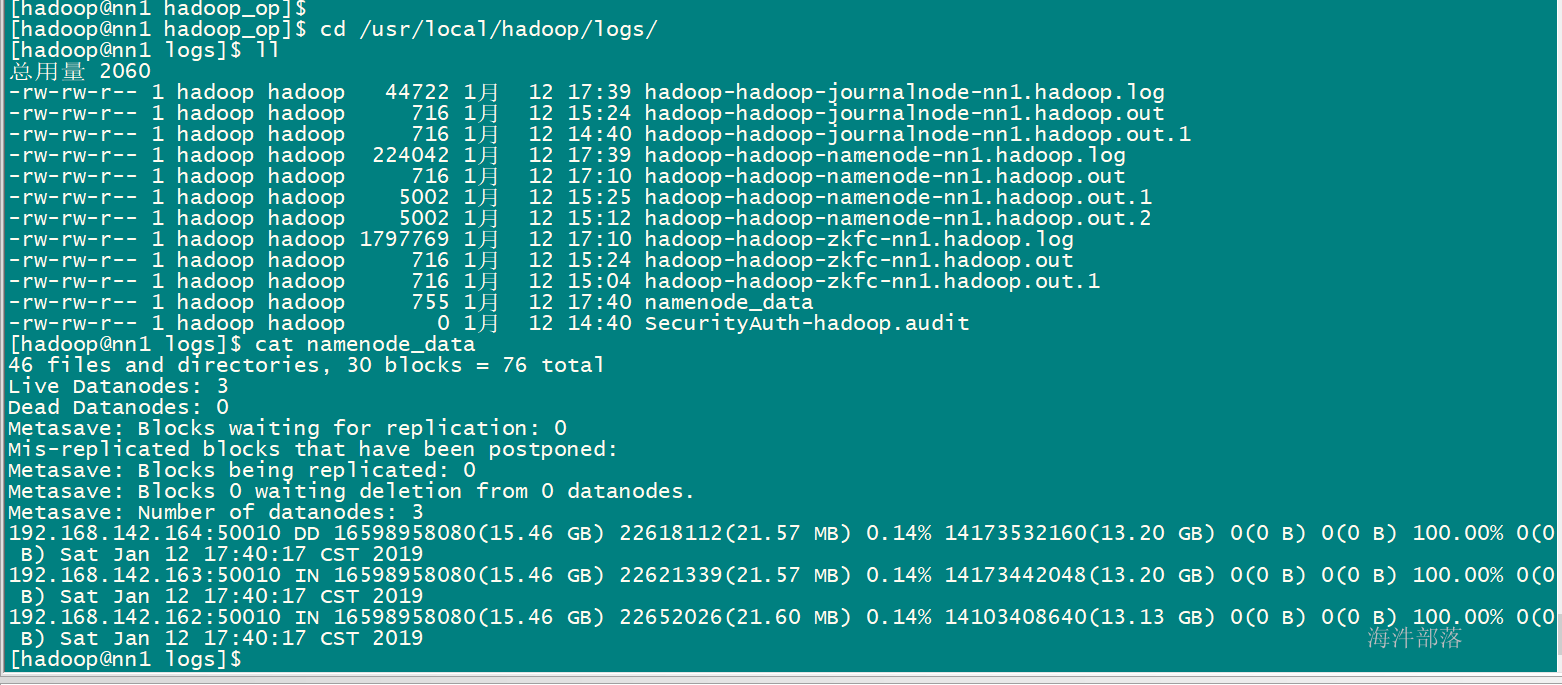
4 HDFS 负载均衡
4.1 HDFS负载均衡概述
Hadoop的HDFS集群非常容易出现机器与机器之间磁盘利用率不平衡的情况,例如:当集群内新增、删除节点,或者某个节点机器内硬盘存储达到饱和值。当数据不平衡时,Map任务可能会分配到没有存储数据的机器,这将导致网络带宽的消耗,也无法很好的进行本地计算。
当HDFS负载不均衡时,需要对HDFS进行数据的负载均衡调整,即对各节点机器上数据的存储分布进行调整。从而,让数据均匀的分布在各个DataNode上,均衡IO性能,防止热点的发生。进行数据的负载均衡调整,必须要满足如下原则:
- 数据平衡不能导致数据块减少,数据块备份丢失
- 管理员可以中止数据平衡进程
- 每次移动的数据量以及占用的网络资源,必须是可控的
- 数据均衡过程,不能影响namenode的正常工作
4.2 HDFS 数据自动平衡脚本使用方法
在Hadoop中,包含一个 start-balancer.sh 脚本,通过运行这个工具,启动HDFS数据均衡服务。该工具可以做到热插拔,即无须重启计算机和 Hadoop 服务。
启动命令为:‘Hadoop_home/sbin/start-balancer.sh –threshold`
影响Balancer的参数:
- -threshold
- 默认设置:10,参数取值范围:1-100
- 参数含义:datanode间磁盘使用率相差阈值。理论上,该参数设置的越小,整个集群就越平衡。
比如:
#启动数据均衡,默认阈值为 10%
$Hadoop_home/sbin/start-balancer.sh
#启动数据均衡,阈值 5%
$Hadoop_home/sbin/start-balancer.sh -threshold 5
#停止数据均衡
$Hadoop_home/bin/stop-balancer.sh也可以在hdfs-site.xml文件中设置数据均衡占用的网络带宽限制
<property>
<name>dfs.balance.bandwidthPerSec</name>
<value>1048576</value>
<description>根据每秒字节数指定每个数据节点可用于平衡的最大带宽,默认 1M/S</description>
</property>5 理论详细分析
5.1 NameNode 详解
1)NameNode是整个HDFS集群的中心
a 负责管理 DataNode 节点;
b 负责安排管理集群中数据的存储并记录存储文件的元数据;
c 负责客户端对文件的访问;
2)在运行时把所有的元数据都保存到namenode机器的内存中,所以整个HDFS可存储的文件数受限于namenode的内存大小。一个元数据是150字节。
3)NameNode 也记录着每个文件中各个block块所在的DataNode信息,但它并不永久保存其block块的位置信息,因为这些信息会在系统启动时由DataNode上报给NameNode。
4)Namenode 除了内存存储元数据外,磁盘也存储,主要维护两个文件,一个是 fsimage**,一个是editlog**。
editlog(简称edits):
操作日志文件,记录了NameNode所要执行的操作;
fsimage:
元数据镜像文件。存储某NameNode元数据信息,并不是实时同步内存中的数据。
一般而言,fsimage中的元数据是落后于内存中的元数据的;
当有写请求时,NameNode会首先写该操作先写到磁盘上的edits文件中,当edits文件写成功后才会修改NameNode内存的元数据,内存 修改成功后向客户端返回成功信号。
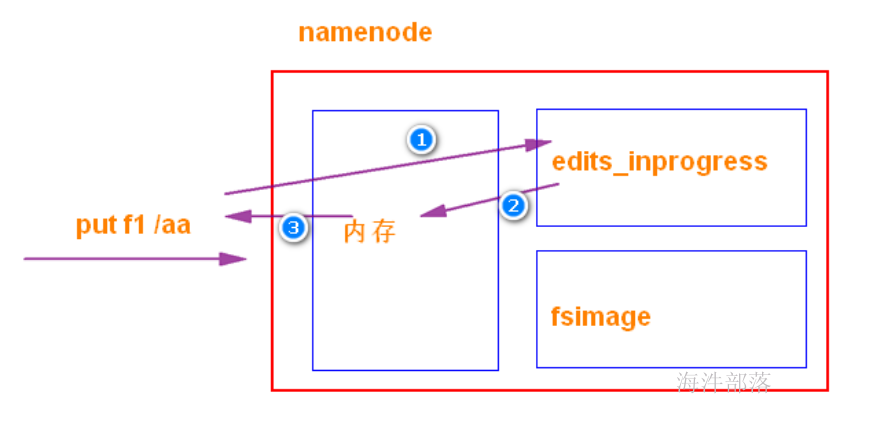
设计的目的:
一旦namenode挂了,内存数据丢失,可以通过 fsimage + edits 恢复。
journalnode 同步数据方式:通过edits
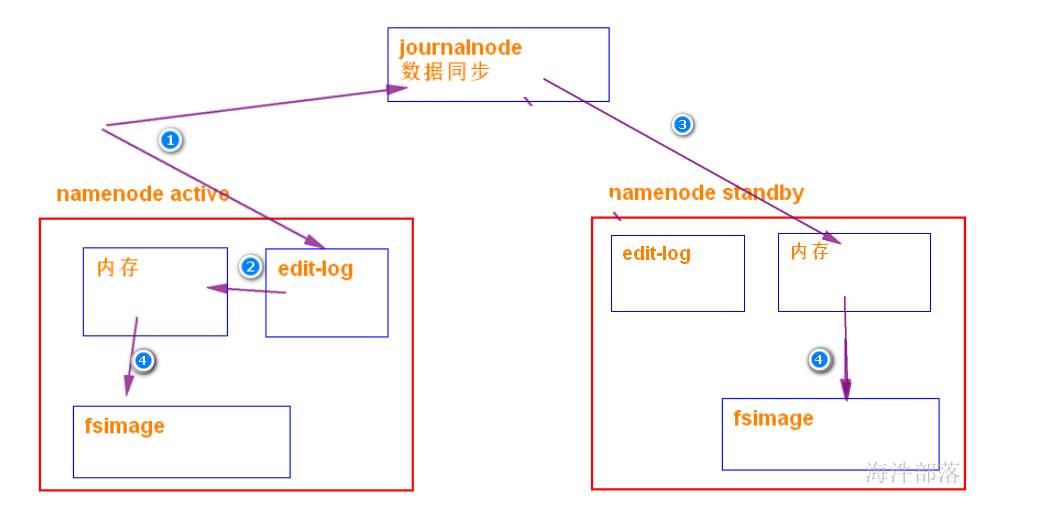
7) fsimage 和 edits 合并
随着时间的推移,hdfs 存储越来越多,元数据越来越多,导致 edits 文件也越来越多、越来越大。导致namenode 在启动加载edits 时会很慢,所以需要对edits和fsimage进行合并。
所谓合并,就是将edits和fsimage加载到内存中,照着edits中的操作一步步执行,最终形成新的fsimage,其实这个过程叫 checkpoint机制。
checkpoint机制:
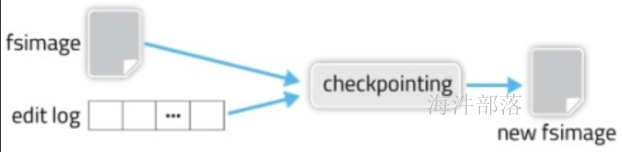
其实这个合并过程是一个很耗I/O与CPU的操作,并且在进行合并的过程中肯定也会有其他应用继续访问和修改hdfs文件。
如果HDFS没有做HA的话,checkpoint由SecondNameNode进程(一般SecondNameNode单独起在另一台机器上)来进行。
在HA模式下,checkpoint则由StandBy状态的NameNode来进行。
大概执行过程:
如果满足checkpoint需求,standby NameNode 拉取Active NameNode的fsimage镜像文件,和 同步过来的 edits 合并成新的 fsimage,然后再返回给Active NameNode。
什么时候checkpoint 由两个参数决定:
a. 每隔一小时执行一次(定时执行)
<property>
<name>dfs.namenode.checkpoint.period</name>
<value>3600</value>
</property > b. 一分钟检查一次操作次数,当操作次数达到1百万时,执行一次(定量执行)
<property>
<name>dfs.namenode.checkpoint.txns</name>
<value>1000000</value>
<description>操作动作次数</description>
</property>
<property>
<name>dfs.namenode.checkpoint.check.period</name>
<value>60</value>
<description> 1分钟检查一次操作次数</description>
</property>5.2 数据块副本的存储规则
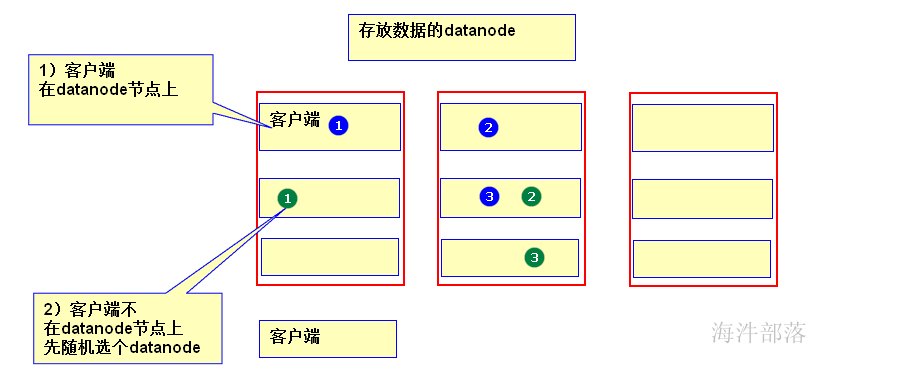
1)若client为DataNode节点,那存储block时,规则为:
副本1,同client的节点上;
副本2,不同机架节点上;
副本3,同第二个副本机架的另一个节点上;
其他副本随机挑选。
2)若client不为DataNode节点,那存储block时,规则为:
副本1,随机选择一个节点上;
副本2,不同机架节点上;
副本3,同第二个副本机架的另一个节点上;
其他副本随机挑选。
5.3 机架感知策略的实现机制
默认情况下,Hadoop机架感知是没有启用的,需要在NameNode机器的hadoop-site.xml里配置一个选项,例如:
<property>
<name>topology.script.file.name</name>
<value>/path/to/script</value>
</property>其中:
这个配置选项的 value 指定为一个可执行程序,通常为一个脚本,该脚本接受一个参数,输出一个值。
接受的参数通常为 datanode 机器的 ip 地址,而输出的值通常为该ip地址对应的 datanode 所在的rackID,例如”/rack1”。
Namenode 启动时,会判断该配置选项是否为空,如果非空,则表示已经启用机架感知的配置,此时 namenode 会根据配置寻找该脚本,并在接收到每一个 datanode 的 heartbeat 时,将该 datanode 的ip地址作为参数传给该脚本运行,并将得到的输出作为该datanode 所属的机架,保存到内存的一个map中。
至于脚本的编写,就需要将真实的网络拓朴和机架信息了解清楚后,通过该脚本能够将机器的ip地址正确的映射到相应的机架上去。
当没有配置机架信息时,所有的datanode,hadoop都默认在同一个名为 “/default-rack”机架下。


